"All Tolstoy in one click": how we did it

Some time ago we organized the digitization of the 90-volume collected works of Leo Tolstoy, and more than 3 thousand volunteers helped us with this. There were a lot of publications about this crowdsourcing project, but none of them dealt with the technical part - it is about her that this article will be discussed.
So, we were faced with the task of translating the most complete works of Tolstoy into PDF formats (ePub, fb2, html, mobi), and also into PDF with a text layer. It was produced for 30 years: from 1928 to 1958, each volume was issued in an edition of 5 thousand copies. Before the release of the electronic edition, this collection of works was not republished and has already become an inaccessible rarity. The 90-volume edition includes: works of art (1–45 volumes), diaries and notebooks (46–58 volumes), letters (59–90 volumes). There was also a secret 91th volume, which consisted entirely of pointers and, therefore, gave our editors many
')
Digitizing anything nowadays is not a problem when you have the right technologies at hand, but to subtract such large amounts of text and correct all inaccuracies in recognition is a huge job that requires either an unlimited resource of time
The collected works were scanned by the Russian State Library in 2006, and we got to work PDF files (only images, without a text layer), one volume (and this is from 400 to 600 pages) - one file. Files together occupied only 4 GB.
Since the volunteers had to verify the texts, we decided to divide the files into small parts (“packages”) - so that the work does not seem difficult and laborious for people, so that it is interesting and not boring. It seemed to us that a package of 20 pages fully satisfies these conditions. So, all PDF-files were automatically “cut” into parts using ABBYY Recognition Server , from each volume about 20 files came out - depending on the initial number of pages, the format was still PDF. When splitting volumes with no other conditions than the number of pages, we were not guided - so, in one package could end up one work and the beginning of another.
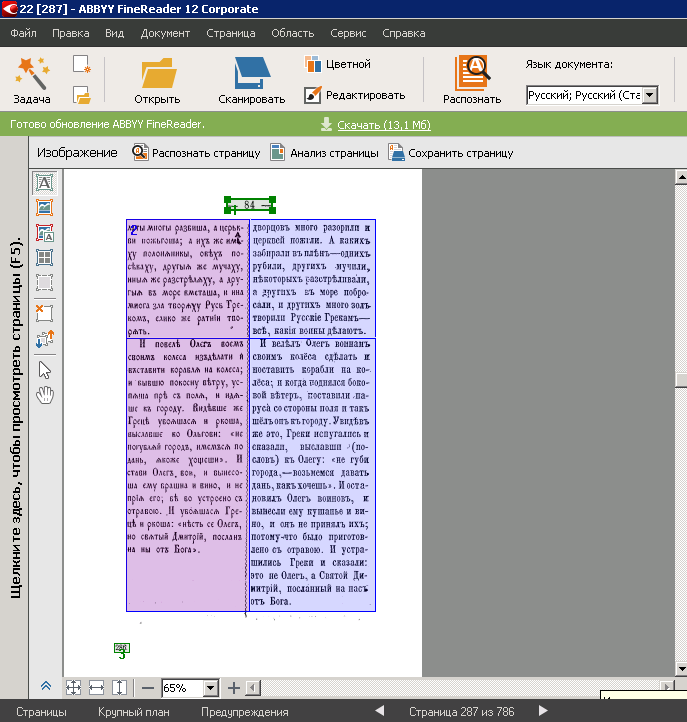
Next, the resulting packages needed to be recognized - this was done by our employee using ABBYY FineReader (version 11 was used). Typically, the recognition of documents consists of several stages. First, you scan the document (or open the finished scan in the program, as it was in our case), then the program analyzes the document and marks the areas - images (they are not recognized, that is, the text is not extracted from them), text, tables, footnotes. Then the program recognizes everything that it needs to recognize, then we have the opportunity to check whether everything worked out correctly (compare the scan with the result of recognition).
So, our employee "chased" scans through FineReader and worked with the marking of areas (volunteers were to check the recognition accuracy). Here began the most
The cover of one of the volumes (standard markup FineReader: the area "image" is highlighted in red, "text" - green, "table" - purple)
Tolstoy's handwritten notes
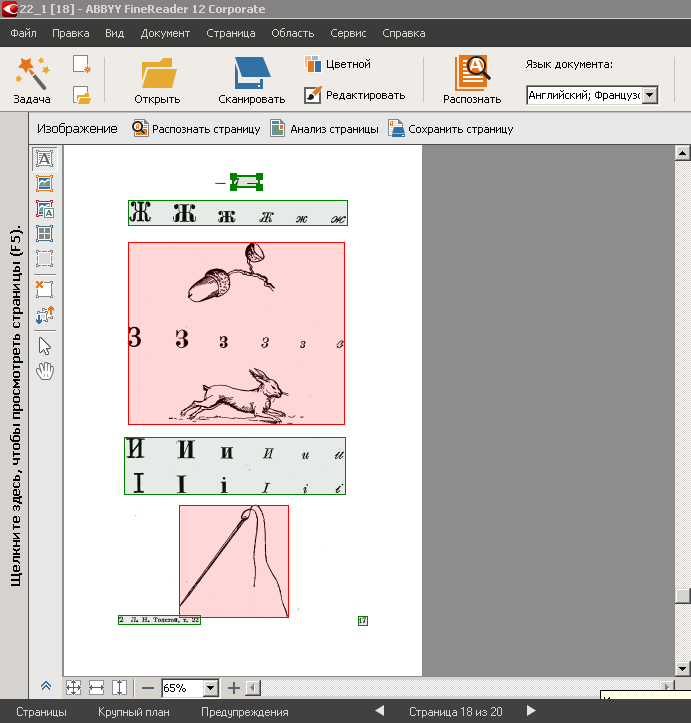
In some works, for example, in the ABC, there were a lot of pictures and very little text - we decided that most of the content of the pages would be left with pictures. So automatically labeled FineReader areas:
And so it was convenient for us:
In the output of some volumes, some names are circled - these places are also marked as images. For further work with the texts it was convenient that the page numbers were marked with a “footer” area. In one of the volumes of Tolstoy are excerpts from the Tale of Bygone Years and other works in the Old Russian language. FineReader does not recognize this language, so we initially prepared a table, where such fragments are defined as images.
Thus marked and recognized pages were saved in the own format of the document (or package) FineReader. Such a document represents a folder containing a bunch of files. So that volunteers could download the package in one file from the site, the document was archived in zip. When the packages were ready, they were uploaded to a specially created project site, from where volunteers could download them for verification. Briefly about how the site itself was done, those interested can read under the spoiler.
Crowdsourcing platform
Crowdsourcing platform
It was necessary to make a platform for collaboration of a large number of people (volunteers) in a very short time - we only had about a month to develop the platform.
The platform was written on Ruby in conjunction with the MySQL DBMS, and the BitBucket system was used as a repository and development management. Components of the platform:
1. information part (consists of static pages about the project, news, FAQ, etc.)
2. application (manages users, books, packages and processes)
3. file storage in the original, as well as in all intermediate states of book fragments.
For reliable operation of the entire project as a whole, an architecture based on Amazon cloud storage with scalability was used.
According to the results of the project, such technical statistics gathered here:
• peak load - 6 requests per second, on average 2-3
• peak - 9600 unique visitors in the first week of the project, 3000 on the third day (June 20)
• maximum attendance 12.00-18.00, minimum 4-6 am.
It was necessary to make a platform for collaboration of a large number of people (volunteers) in a very short time - we only had about a month to develop the platform.
The platform was written on Ruby in conjunction with the MySQL DBMS, and the BitBucket system was used as a repository and development management. Components of the platform:
1. information part (consists of static pages about the project, news, FAQ, etc.)
2. application (manages users, books, packages and processes)
3. file storage in the original, as well as in all intermediate states of book fragments.
For reliable operation of the entire project as a whole, an architecture based on Amazon cloud storage with scalability was used.
According to the results of the project, such technical statistics gathered here:
• peak load - 6 requests per second, on average 2-3
• peak - 9600 unique visitors in the first week of the project, 3000 on the third day (June 20)
• maximum attendance 12.00-18.00, minimum 4-6 am.
The mechanics of the process looked like this: the volunteer registered on the site www.readingtolstoy.ru , went into a private office, where he could take one package of 20 pages for verification. Packages were issued to users in the order they appear in the volume — so that entire volumes are collected more quickly.
All participants received a license to ABBYY FineReader 11 Professional Edition, valid until the end of 2013. The program has already been configured recognition languages that are found in Tolstoy - Old Russian spelling, English, French, German, Greek, etc.
Before volunteers two tasks were set. The first is to check the correct area marking. An attentive reader will say - after all, this has already been done at the last stage. But when recognizing, the correct marking of the areas is about half the success, so the volunteers also had to make sure that the document was correctly marked. The second is to check inaccurately recognized characters, compare the result of recognition with the original and correct errors. Errors were of two types: incorrectly recognized characters in the text (where the quality of the scan was bad) and in the location of the paragraphs — paragraphs were sometimes glued together or, on the contrary, were broken where there was no need.
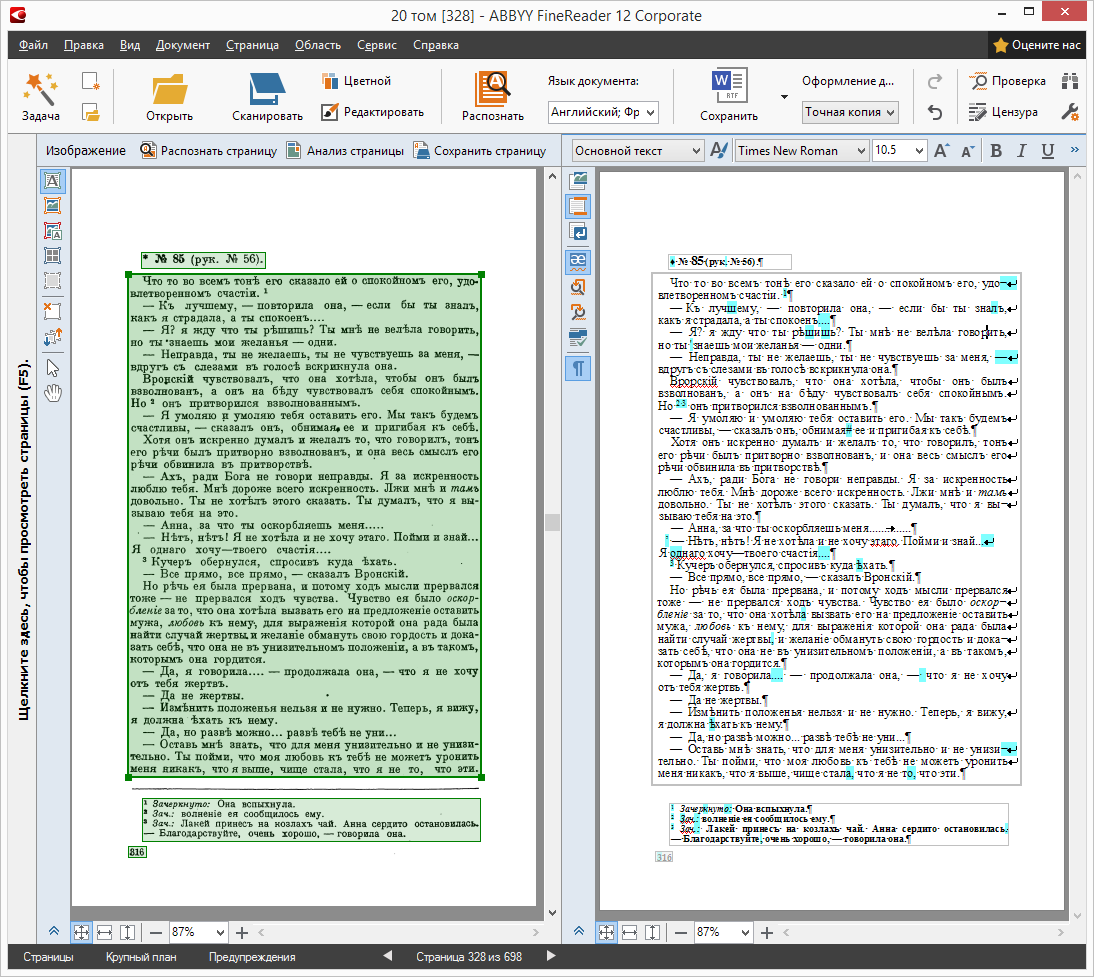
Still, people had to correct the page breakdown - in the case of transferring a word from one page to another, it was necessary to “glue” the word and leave it entirely on one of the pages. Detailed instructions were given to help volunteers.
The package had to be checked and returned to the site within 48 hours. As we remember, the participant downloaded the archived file and in the same form had to upload it back to the site. If the package did not return, he got into the issue a second time. Points were awarded for verified packages, the most active participants received prizes - Onyx e-books, ABBYY FineReader programs and other gifts. And the main characters went on a two-day excursion to the museum-estate "Yasnaya Polyana", where they could personally communicate with the great-granddaughter of the writer Thekla Tolstoy and other organizers of the project.
To tell the truth, we didn’t think that our initiative would receive such an active response among Tolstoy’s readers, but people started registering themselves during a press conference devoted to the opening of the project’s website, and checked the entire collection of works in just two weeks.

The first phase of the project attracted 1600 participants.
When we began to check the packages, the quality of work turned out to be heterogeneous. Most volunteers approached the matter responsibly, but there were mistakes. After checking most of the packages, the second round began - checking the same packages by the so-called “auditors”.
Auditors could be as participants of the first round, did a good job, and new volunteers. All applicants had to pass a test that included questions related to the verification of texts. The auditors checked the finished packages, corrected errors and gave additional assessment to the participants of the first round, which the organizers later paid attention to.
After that, the packages came in a special database on the site. When all the packages from one volume were ready, the project administrator saw this, downloaded all the volume packages from the site and collected them back into a single document (still in FineReader format) using a special utility, which was written by our developers. Then our employee checked whether the volume was going correctly, whether page numbers, etc. were not shot down. After that, the finished volume was passed back to the administrator.
Although the quality of the work of the auditors was beyond praise, we still wanted to play it safe and arranged a third round of text verification - this time in whole volumes. From among the volunteers, we ourselves selected 30 people who had proven themselves well in the early stages — they became “editors”; in addition, at this stage a small number of new volunteers joined us — linguists and professional editors.
The editor could take the volume only in its entirety, one week was given for checking, after which the person had to upload the document back to the site. If the editor did not have time to check the entire volume, he indicated the number of verified pages and uploaded the volume to the site. In this project tour, volunteers worked so well that they even found factual mistakes made in the paper edition — for example, the initials of one of the editors were incorrectly indicated in the output of one of the volumes.
After the third stage of the check, the administrator exported the volumes in MS Word format and they were sent for review to our staff editors. The editors read the files again, the corrections were made both in the Word file and in the FineReader source package (to facilitate later saving from it to other formats).
As a result of the project, we needed to get these types of files:
1. PDF with text layer
2. Html, as well as FB2, epub, mobi files for e-books (at this stage, our partners from WEXLER were involved in the work, who were converting the files we received into e-book formats. For more information about this work, see the head of the article software development company WEXLER Sattar Gyulmamedova.
Well, a little about the outcome. 3249 volunteers from 49 countries took part in the project. In total, the results of the work resulted in 670 books, of which 91 are identical to the volumes of the original collected works and 579 works “extracted” from the volumes. In total it is 2084 files. For the 91st volume, only the html-version was made, since this index will not be interesting in the form of an electronic book, and for 9 works they did not begin to make a fb2-version due to some format restrictions.
All e-books are posted on the official portal dedicated to Tolstoy. And on the project's website www.readingtolstoy.ru an interactive map is now available, where everyone who downloaded the work of Leo Tolstoy can mark himself - as a result, rather interesting statistics are obtained on the most popular works among users and on countries and regions with active readers themselves.

Of course, the main purpose of digitizing Tolstoy’s collected works is to provide access to the reader’s legacy to all readers, but that’s not the end of it. Texts of Tolstoy in electronic form are of great interest for researchers-linguists. We hope to tell you about one of these studies in one of the following articles.
Source: https://habr.com/ru/post/264119/
All Articles