Back to the Future - Decapsulation

When running program modules that store a large amount of data in RAM, the way they are stored has a strong effect on memory consumption and speed. One way to speed up the system and save resources may be to use more primitive data structures — structures instead of classes and primitive types instead of structures. Of course, this approach breaks down the OOP and returns to the use of "old" programming methods. However, in some cases, such primitization can solve many problems. A simple test showed the possibility of reducing memory consumption by more than three times.
Issues covered:
- The impact of software architecture on memory consumption and performance;
- Differences when working in 32 and 64 bit modes;
- Differences between pointers and array indices;
- The impact of data alignment within classes / structures;
- The effect of processor cache on performance;
- Estimate the cost of supporting the PLO in high-level languages;
- Recognition of the need to take into account the low-level features of the platform, even when developing in high-level languages.
Practical task
For the first time, I applied this technique when developing a search for the optimal path for the portal www.GoMap.Az . The new algorithm used more RAM and, when installed on the test server, the application started to jam seriously. Updating the hardware in this case required several days, and its solution by optimizing data structures made it possible to quickly solve the problem. To share my experience, I decided to describe in a simple way what was done and what benefits were gained.
The organization of storage of a large number of data structures and access to them is an integral task for information systems working with cartographic data. Similar problems are also increasingly emerging when creating other types of modern information systems.
')
Consider data storage and access to them on the example of roads - the edges of the graph. In simplified form, the road can be represented by the Road class, while the road storage is represented by the RoadsContainer class. In addition, there is the Node class of the network node. Regarding Node, we just need to know that this is a class. We take into account that our data structures do not contain methods and do not participate in inheritance, etc., that is, they are used only for storing and manipulating data.
We will consider the implementation of the method in C #, although it was originally applied in C ++. Strictly speaking, the problem and its solution is somewhat in the field of system programming. However, this study also shows how high the cost of supporting the OOP can be in high-level programming. C # can best show these hidden costs without being a system programming language.
// – Road public class Road { public float Length; public byte Lines ; // - Node Road // public Node NodeFrom; public Node NodeTo; // } // public class RoadsContainer { // // , public Road[] getRoads(float X1, float Y1, float X1, float Y1) { // } // } Memory and performance
When assessing memory consumption and performance, you should consider the impact of the platform architecture features, including:
- Data alignment Alignment of data is performed for correct and fast access of the central processor to the memory cells. Depending on the capacity of the system, the arrangement of classes / structures in memory can begin with addresses that are multiples of 32 or 64 bits. Inside the classes / structures themselves, fields can also be aligned along 32, 16, or 8 bits (for example, the Lines field of the Road class may take in memory not 1 byte, but 4). At the same time there are unused memory spaces, which increases its loss .;
- CPU cache As you know, the task of the cache is to speed up access to the most frequently used memory cells. The size of the cache is very small, since it is the most expensive memory. When processing classes / structures, unused memory spaces resulting from data alignment also end up in the processor’s cache and clog it up because they do not carry any useful information. As a result, a decrease in caching efficiency.
- Size pointers . In 32-bit systems, a pointer to an object in memory is also usually 32-bit, which limits the ability to work with RAM more than 4GB. 64-bit systems allow addressing significantly large amounts of memory, but use 64-bit pointers. Objects always have pointers to them (otherwise it will be lost memory or an object to be deleted by the garbage collector). In our example, the NodeFrom and NodeTo fields in the Road class will occupy 8 bytes each in a 64-bit system and 4 bytes in a 32-bit one.
Usually compilers try to create the most efficient code, however, to achieve significant performance efficiency can only software and architectural solutions.
Object arrays

Data can be stored in various containers - lists, hash tables, etc. Storage in the form of an array is probably the easiest and most understandable way, so we will focus on the consideration of this method. Other containers can be analyzed similarly.
In C #, arrays of objects in reality store references to objects, while each object occupies its own address space on the heap. In this case, it is very convenient to manipulate sets of objects, since in reality you have to work with pointers, and not with the objects as a whole. For example, in our example, the getRoads function of the RoadsContainer class transfers a set of specific objects of the Road class — not copies of objects, but links. This behavior occurs because objects in C # are reference data types.
The disadvantages of storing data in the form of arrays of objects are primarily the cost of storing the pointers themselves and aligning the objects on the heap. On 64-bit systems, each pointer takes 8 bytes of memory and each object is aligned at a multiple of 8 bytes.
Arrays of structures

Classes of storage of roads and network nodes can be converted into structures (as mentioned in our example, there are no restrictions on the part of OOP). Instead of pointers to them, integer indices can be used. The code that turns out can be:
public struct Road { public float Length; byte Lines ; Int32 NodeFrom; Int32 NodeTo; // } public class RoadsContainer { // // , Road[] Roads; // , public Int32[] getRoads(float X1, float Y1, float X1, float Y1) { // } // public Road getRoad(Int32 Index) { return Roads[Index]; } // } // // public class NodesContainer { // Node []Nodes; // public Node getNode (Int32 Index) { return Nodes[Index]; } // } What did it give us? Consider in detail.
Road data structures are already stored as program structures (structs in C #), and not as objects. The Roads array in the RoadsContainer class is used to store them. To access individual structures, use the getRoad function of the same class. The 32-bit integer index assumes the role of a pointer to the data structure of a particular road. In the same way, nodes are transformed and a fragment of the NodesContainer node storage class is presented.
Using a 32-bit index instead of a 64-bit pointer facilitates both the memory it uses and the manipulation of it. Using indexes to refer to the NodeFrom and NodeTo nodes in the Road structure reduces the size of memory it uses by 8 bytes (when aligned to 32, 16, or 8 bits).
Memory allocation (by calling the operator new) for storing roads occurs at one time. In this case, only an array of Road structures is reserved in which all structures are created at a time. In the case of storing references to objects, each object must be created separately. The creation of a separate object not only takes time, but also consumes a certain amount of service memory for leveling, registering an object on the heap and the garbage collection system.
The lack of using structures instead of objects is strictly speaking the impossibility of using pointers to a structure (structure is a type “by value”, and a class is type “by reference”). This fact leads to a restriction of the ability to manipulate sets of objects. Because of this, the getRoads function of the RoadsContainer class now returns the indices of the corresponding structures in the array. At the same time, the structure itself can be obtained using the getRoad function. However, this function will cause the entire structure to be returned to be copied, which will consume memory and processor time.
Primitive data arrays

Arrays of structures can be converted into separate arrays of fields of this structure. In other words, structures can be decapsulated and abolished. For example, after decapsulating and canceling the Road structure, we get the following code:
public class RoadsContainer { // // Road float[] Lengths; byte[] Lines; Int32[] NodesFrom; Int32[] NodesTo; // // , public Int32[] getRoads(float X1, float Y1, float X1, float Y1) { // } // public float getRoadLengt(Int32 Index) { return Lengths[Index]; } // public byte getRoadLines(Int32 Index) { return Lines[Index]; } // public Int32 getRoadNodeFrom(Int32 Index) { return NodesFrom[Index]; } // public Int32 getRoadNodeTo(Int32 Index) { return NodesTo[Index]; } // } What did we get? Consider in detail.
Instead of storing program structures in a single array, the fields of this structure are stored separately in different arrays. Access to the fields is also made separately by index.
Empty memory consumption for alignment of fields inside the structure is eliminated, since the fields of the structure of primitive types are stored close to each other. Memory is requested from the system not by one large piece for storing all the structures at once, but in several pieces for storing the field arrays, respectively. In a sense, such a partition is useful, since it is often easier for a system to provide several relatively small continuous chunks of memory than one large continuous chunk.
Accessing each field requires an index each time, while accessing the entire structure requires using the index only once. In reality, this feature can be considered both as a disadvantage and as an advantage. The fact is that by accessing only part of the fields, for example, only three fields Lengths, NodesFrom and NodesTo of the Road structure, if they are located in separate arrays, you can get a more optimal use of the processor cache. Using all the advantages of the cache depends on the data access algorithm, but in any case, the gain can be noticeable.
Garbage collection and memory management

This issue is related to memory management technologies. After all, the speed of access to them depends on the location of objects in the memory. Currently, there are a huge number of ways to organize memory management, including automatic garbage collection systems. These automatic systems not only monitor the cleaning of memory, but also carry out defragmentation (like a file system).
Memory management systems generally work with pointers to objects located on the heap. In the case of using arrays of structures or fields, the memory management systems will not be able to work with the elements of these arrays and all the work of creating and destroying them will fall on the programmer’s shoulders. Thus, the use of arrays of structures or fields in a certain sense deactivates the garbage collector for them. Depending on the task, this limitation can be considered as an advantage (if resources are required) or as a disadvantage (if a programmer’s staff and labor are required).
Measurements

As you can see the most wasteful for storage is an array of objects. At the same time, on a 64-bit system, storage costs increase dramatically. Storage in the form of arrays of structures or fields as a whole is equally expensive for 32 and 64-bit mode. Storage in the form of fields has some gain in the amount of memory taken, but this gain is not critical. This gain includes the costs of aligning the data within the structures.
Memory
Occupied memory, 32 bit mode
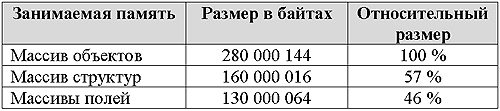
Occupied memory, 64 bit mode

As you can see the most wasteful for storage is an array of objects. At the same time, on a 64-bit system, storage costs increase dramatically. Storage in the form of arrays of structures or fields as a whole is equally expensive for 32 and 64-bit mode. Storage in the form of fields has some gain in the amount of memory taken, but this gain is not critical. This gain includes the costs of aligning the data within the structures.
Access time
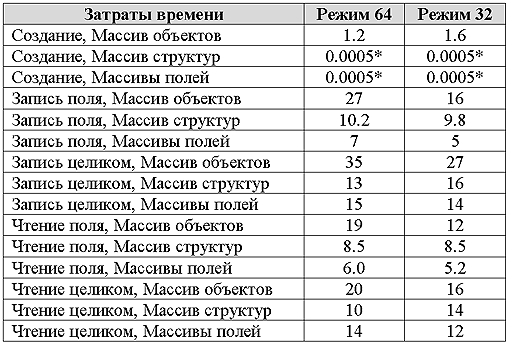
Notes:
* - the number is too small in comparison with the accuracy of the test.
The time to access data structures when stored in an array of objects shows the highest cost of time. Also, there is a faster access to the fields if they are located in separate arrays. This acceleration is the result of more efficient use of the processor cache. It should be mentioned that in the test access is carried out by sequential enumeration of the elements of the array and in this case, the use of the cache is close to optimal.
Results
This small review allows you to create an idea of the problem and draw the first conclusions:
- Failure to use OOP in working with large amounts of data can lead to 3-fold savings in RAM on 64-bit systems and 2-fold savings on 32-bit systems. This problem arises due to the peculiarities of the hardware architecture; therefore, to one degree or another, it is relevant for all programming languages.
- The access time in C # to data structures by means of an array index is significantly less than the access time by means of a pointer.
- Raising the level of programming technology requires resources. Low level (system level) and work with primitive data (obtained after decapsulating classes / structures) uses the least resources, but require more lines of source code and programmer time.
- The transition to working with primitive types is the stage of code optimization. Therefore, this architecture can be used not as an initial design, but as a measure in case of need to reduce resource consumption.
- In C ++, many of the problems described can be solved transparently, while in C #, much is hidden in the underlying implementation. In addition, when studying C #, the influence of the platform is far from being considered at first.
- When developing in C # where possible, structures should be used, not classes.
References:
Sources of tests on GitHub
An example of successful commercial use of the technique is GoMap.Az portal
Difference Between Structures and Objects (MSDN)
Good article on Mastering C # structs
An article on a similar issue “Keep 300 Million Objects in the CLR Process”
Source: https://habr.com/ru/post/264063/
All Articles