How we spent a couple of days working on Perl acceleration
This is a story about the significant optimization of the Perl interpreter, about dealing with the complexities of the code, and about how we wanted to “eat the cake so that we have it left” [English proverb “You can't have your cake and eat it” achieving two opposite goals].
On the recent Booking.com hackathon, we had the opportunity to work on accelerating the function of placing integers in the Perl interpreter. If successful, this will help speed up almost all the programs that work in our project. It turned out that a banal implementation of the idea could work, but this would increase the complexity of maintaining the code. Our research has led us to force preprocessor C to improve the quality of the code, while at the same time making it possible to speed up the execution of programs.
In perlguts and PerlGuts Illustrated , it is written that the representation of variables in Perl usually consists of two parts - the header and the body (represented as a struct). The header contains the data necessary for processing variables that do not depend on its type, including a pointer to a possible body.
')
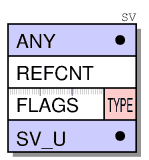
The structure of the body can vary greatly, depending on the type of variable. The simplest variable is SvNULL, which represents undef and does not require a body.
At the line (PV - “pointer value”) the body has the type XPV:
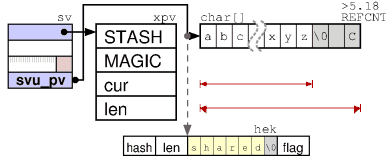
The structure of the PV body is different from the PVNV body. PVNV can contain a floating-point number and a string representation of the same value.
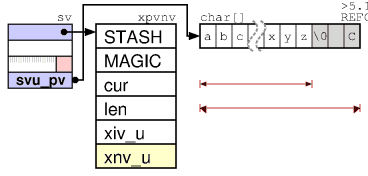
The advantage of this design is that all variable references lead to a heading. Perl is free to change where the body is stored, and this does not require updating all other pointers.
Perl has an internal type conversion function - this is sv_upgrade (“scalar value upgrade”). If we have a variable, say, an integer, and we need to refer to it as a variable of another type (let's say, like a string), sv_upgrade converts the type of the variable (say, to a type that contains both integer and string values). This may require replacing the current body with a larger volume.
To find out how sv_upgrade is implemented, look at the Perl_sv_upgrade function in sv.c. It can be seen that the function is quite complicated, in the code there are many comments describing various implementation features. This is not surprising since it can take a scalar value of any type and convert it into a form that any other type can represent.
At the beginning of the function there is a switch , working depending on the current type of the variable, which determines what needs to be done for the new type. Soon after it there is a second switch , which deals with the new type. In its second block, there are many if {} blocks that do different things depending on the old type. And at the end, after defining the struct for the new body and filling the struct for the header with the correct flags, the memory that was occupied by the old body is freed.
Do not fall asleep yet?
The sv_upgrade function is called from a set of places — not only from the output of integers as strings, but also when an integer is assigned to a variable that was previously set to zero.
A zero variable is always undef, which has no body. sv_upgrade in this case is called to correctly configure the body of the new variable. This is the right decision, which reduces certain work with variables in one place and does not multiply the essence. But this decision affects the performance due to the implementation of some common, and in this case, redundant code.
Assignment of an integer number to a zero variable occurs so often that it would seem possible to duplicate part of the code in order to obtain an improvement in performance. We decided to calculate what it would cost. It turned out that in this case, you can generally get rid of the sv_upgrade call, if you duplicate only two lines of code from it. But they are not in vain not duplicated in the code. Here are the two lines.
First, since we know that this is a new type, it will be simple:
The second is more difficult:
It is described in Illustrated perlguts as follows:
After 15 minutes with a pencil and paper, I made sure that this line does exactly what is described in the comment. After that, the chart from Illustrated Perl Guts became clearer:
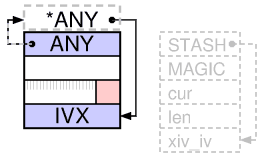
In addition, I realized that all this complexity exists in order to avoid the if call, which otherwise would occur every time the value is retrieved.
It turned out that we can speed things up, but by putting complex expressions into another part of the code. The complexity of maintaining such a code would increase as a result.
We wanted to encapsulate this complex piece of code, but without degrading the performance. In dealing with C, we turned to the preprocessor to push it all into a macro — in other languages it would look like hiding a complex code behind a well-named function or method:
The advantage of using a macro is that the fee for speed is charged only during compilation, and it does not suffer from execution.
And how did this change our situation? When using a macro, the two rendered lines become simpler. As a result, the patch only needed to replace the call.
On these two lines:
As a result, due to the removal of a relatively uncomplicated code, we must get an increase in speed. But will we get it? What will be the real gain from this?
Our benchmark is quite specific, but at the same time it is a fairly frequent case.
And here are the results of the work. Before optimization:
After optimization:
An increase of 18%. Success.
We have demonstrated the need for this optimization, the complexity of which tends to zero. In some places, the Perl code has become a bit more complicated, but the insides of the sv_upgrade function have become simpler. Acting in this way, we found several more places where optimization could be achieved using similar methods. As a result, we made five patches to the Perl code:
With the release of Perl 5.22, including thanks to this work, many programs will work faster.
On the recent Booking.com hackathon, we had the opportunity to work on accelerating the function of placing integers in the Perl interpreter. If successful, this will help speed up almost all the programs that work in our project. It turned out that a banal implementation of the idea could work, but this would increase the complexity of maintaining the code. Our research has led us to force preprocessor C to improve the quality of the code, while at the same time making it possible to speed up the execution of programs.
Prehistory
In perlguts and PerlGuts Illustrated , it is written that the representation of variables in Perl usually consists of two parts - the header and the body (represented as a struct). The header contains the data necessary for processing variables that do not depend on its type, including a pointer to a possible body.
')
The structure of the body can vary greatly, depending on the type of variable. The simplest variable is SvNULL, which represents undef and does not require a body.
At the line (PV - “pointer value”) the body has the type XPV:
The structure of the PV body is different from the PVNV body. PVNV can contain a floating-point number and a string representation of the same value.
The advantage of this design is that all variable references lead to a heading. Perl is free to change where the body is stored, and this does not require updating all other pointers.
Changing types
Perl has an internal type conversion function - this is sv_upgrade (“scalar value upgrade”). If we have a variable, say, an integer, and we need to refer to it as a variable of another type (let's say, like a string), sv_upgrade converts the type of the variable (say, to a type that contains both integer and string values). This may require replacing the current body with a larger volume.
To find out how sv_upgrade is implemented, look at the Perl_sv_upgrade function in sv.c. It can be seen that the function is quite complicated, in the code there are many comments describing various implementation features. This is not surprising since it can take a scalar value of any type and convert it into a form that any other type can represent.
At the beginning of the function there is a switch , working depending on the current type of the variable, which determines what needs to be done for the new type. Soon after it there is a second switch , which deals with the new type. In its second block, there are many if {} blocks that do different things depending on the old type. And at the end, after defining the struct for the new body and filling the struct for the header with the correct flags, the memory that was occupied by the old body is freed.
Do not fall asleep yet?
Naive approach
The sv_upgrade function is called from a set of places — not only from the output of integers as strings, but also when an integer is assigned to a variable that was previously set to zero.
A zero variable is always undef, which has no body. sv_upgrade in this case is called to correctly configure the body of the new variable. This is the right decision, which reduces certain work with variables in one place and does not multiply the essence. But this decision affects the performance due to the implementation of some common, and in this case, redundant code.
Assignment of an integer number to a zero variable occurs so often that it would seem possible to duplicate part of the code in order to obtain an improvement in performance. We decided to calculate what it would cost. It turned out that in this case, you can generally get rid of the sv_upgrade call, if you duplicate only two lines of code from it. But they are not in vain not duplicated in the code. Here are the two lines.
First, since we know that this is a new type, it will be simple:
SvFLAGS(sv) |= new_type; The second is more difficult:
SvANY(sv) = (XPVIV*)((char*)&(sv->sv_u.svu_iv) - STRUCT_OFFSET(XPVIV, xiv_iv)); It is described in Illustrated perlguts as follows:
Starting from version 5.10, for pure IV (without PV), the IVX slot is inside HEAD, and no memory is allocated for the xpviv struct ("body"). The SvIVX macro uses SvANY pointer arithmetic to indicate a negative offset, which is calculated at compile time, from HEAD-1 to sv_u.svu_iv, so that PVIV and IV can use the same SvIVX macro.
After 15 minutes with a pencil and paper, I made sure that this line does exactly what is described in the comment. After that, the chart from Illustrated Perl Guts became clearer:
In addition, I realized that all this complexity exists in order to avoid the if call, which otherwise would occur every time the value is retrieved.
It turned out that we can speed things up, but by putting complex expressions into another part of the code. The complexity of maintaining such a code would increase as a result.
How to eat a cake so that you have it left
We wanted to encapsulate this complex piece of code, but without degrading the performance. In dealing with C, we turned to the preprocessor to push it all into a macro — in other languages it would look like hiding a complex code behind a well-named function or method:
#define SET_SVANY_FOR_BODYLESS_IV(sv) \ SvANY(sv) = (XPVIV*)((char*)&(sv->sv_u.svu_iv) - STRUCT_OFFSET(XPVIV, xiv_iv)) The advantage of using a macro is that the fee for speed is charged only during compilation, and it does not suffer from execution.
And how did this change our situation? When using a macro, the two rendered lines become simpler. As a result, the patch only needed to replace the call.
sv_upgrade(dstr, SVt_IV); On these two lines:
SET_SVANY_FOR_BODYLESS_IV(dstr); SvFLAGS(dstr) |= SVt_IV; As a result, due to the removal of a relatively uncomplicated code, we must get an increase in speed. But will we get it? What will be the real gain from this?
Measure benefit
Our benchmark is quite specific, but at the same time it is a fairly frequent case.
$ dumbbench -i50 --pin-frequency -- \ ./perl -Ilib -e \ 'for my $x (1..1000){my @a = (1..2000);}' And here are the results of the work. Before optimization:
Rounded run time per iteration: 2.4311e-01 +/- 1.4e-04 After optimization:
Rounded run time per iteration: 1.99354e-01 +/- 5.5e-05 An increase of 18%. Success.
We have demonstrated the need for this optimization, the complexity of which tends to zero. In some places, the Perl code has become a bit more complicated, but the insides of the sv_upgrade function have become simpler. Acting in this way, we found several more places where optimization could be achieved using similar methods. As a result, we made five patches to the Perl code:
- Refactor bodyless-IV / NV hacks into define
- Speed up assigning an IV to a previously cleared SV
- Speed up newSViv ()
- Repeat newSViv optimization for newSVuv
- Optimize newRV
With the release of Perl 5.22, including thanks to this work, many programs will work faster.
Source: https://habr.com/ru/post/263939/
All Articles