Testing serializers for .NET
The Serbench code is on github .
This benchmark project began with the article “ Serializers in .NET v.2 ” on GeeksWithBlogs.net. The article reviewed quite a lot of serializers available under .NET. But in order to turn this article and the corresponding code into a real benchmark, it was necessary to make several improvements.
First, serializers had to be tested on several data types. There are universal serializers, and there are specialized ones. Specialized work very well with only a few data types, for other data they work much worse or do not work at all. What we have seen in the future.
')
Secondly, serializers differ greatly in interfaces. Our benchmark should not force the serializer to follow our interface selection. On the contrary, the benchmark must be so flexible that each serializer can use the interface that is most suitable for it. That is, it is necessary to transfer additional parameters of a specific serializer to the benchmark.
The author of one of the serializers asked the author of the article to make an improved test. The author of the serializer was the initiator of this project, he was also the lead developer. Sergey was the developer of the entire Web part of the project, all the great reports. NFX was used as a benchmark platform , which made it possible to do everything planned (and much, much more) very quickly. NFX pulls on hundreds of similar articles, I hope it will interest you too.
To begin with, I will dwell a bit on presenting the results, on what requires special attention.
For example, look at the summary information of one of the tests:

On the left we will see three winners in the two most important categories: in speed and in the size of the data being serialized. At once I will make a reservation that there can be more winners, that all serializers that have fallen into the blue, green and, to a lesser, light brown category can be considered winners. The gray category is serializers that did not pass this test.
In the speed column, you can click on the name of the serializer and get a decryption of speed with separate numbers by serialization and deserialization.
The worst speed from serialization and deserialization is taken as the main one. We assume that the total system performance is important to you, and not just serialization or only de-serialization. Your case may be different, so the speed of another operation is also given on the chart with a thin stick.
On some tests, most of the tested serializers lost data. If you choose a “fast” serializer to work with, and it will spoil your data, this is the worst thing you can imagine. You will spend a lot of time trying to understand the cause of the corrupted data. And you are lucky if you stumble upon it in development, and not in production.
Our recommendation: download the benchmark code, change the test data or add your data and test it again. Never trust your intuition, do not trust extrapolation. Virtually any serializer will fall on some particular amount of data. We did not perform marginal tests, do them yourself according to your data. Very few serializers have passed all of our tests.
Attention!
Further on in the text you will constantly come across the words “usually”, “most often”, etc. I apologize for this and understand that this makes the test results a bit uncertain. I hope that you also understand that the test results should not show us the best serializer. They only limit the group of serializers that you need to base. You will use the serializer for YOUR data. Therefore, the final decision should be taken after running tests on ITS data, especially if these data are very different from those used in our tests.
We tried to provide data for the most used applications. We have no statistics on the use of serializers, so we selected data based on our own experience. If you see that we missed something important, let us know or just add your test data to Serbench.
We see typical applications in several areas:
Data relating to this type: Typical Person, Telemetry, EDI, Batching.
Data related to this type: Typical Person, Batching, Object Graph.
Here is a simple class with no interfaces and no inheritance. Almost all presented serializers pass this test.
Such data is generated by IoT (Internet of Things) devices. Their difference is the availability of numerical information, timestamps and several identifiers. Sometimes data is very short when one or more numbers are sent; sometimes large arrays of numbers are sent. The data structure is simple. The speed and density of data packing is important here.
EDI (Electronic Data Interchange) data are equivalent documents. They are characterized by a complex hierarchical structure and nesting of classes. There are collections of classes.
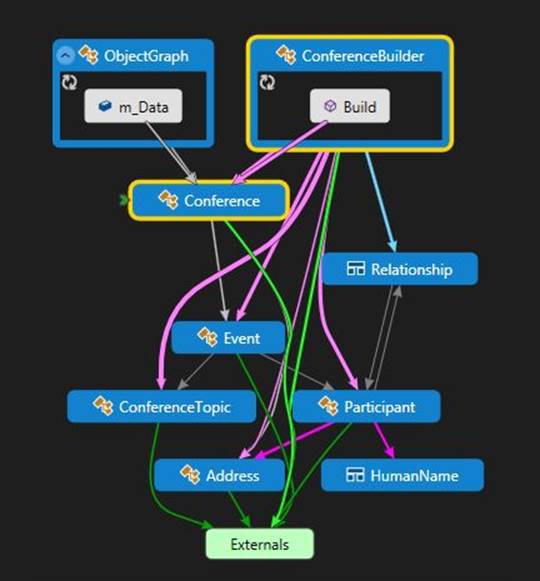
If you use object-oriented development, you probably had to deal with such classes. They are characterized by complex relationships between classes. We are testing the Conference class, which has a collection of Events (Event). An event can have several participants (Participant) and several Topics (Conference Topic).
Interestingly, a participant can have multiple Relationships, each of which refers to another participant. The result is cyclic links. This is a common situation, but it turns out that very few serializers can work with cyclic connections.
Imagine a situation where you need to send multiple instances of objects at once. This is a typical situation in distributed systems. By combining several data items into one packet, which is transmitted over the network in one step, we can significantly speed up the transfer. The package is called batch, hence the name - batching.
Usually, we need to explicitly create a package by enclosing data elements in a special envelope class. Some serializers allow you to do without envelopes, which greatly simplifies development.
Everything is simple here. In one test cycle, we will serialize an object or many objects in the case of a batch, and immediately diserialize it back. The target and source objects are compared to filter out errors. The comparison is quick, only for some values. We do not make a full comparison, but all interfaces for a full comparison are available.
Several test cycles are combined into one run (run), at the beginning of which the test data is generated.
Several tests are combined in sequences, the first test in which is the warmup test. This test usually consists of a single loop, the purpose of which is to initialize all the objects necessary for a given serializer.
Some serializers quickly initialize, but slowly serialize, some - vice versa. If you need to use the serializer once, then you should not neglect the results of warm-up tests, for you they are the main ones.
We usually tested a single object first, and then a collection of objects. As it turned out, serializers can be optimized for working with collections. Then they can break from outsiders to the leaders.
Any data, but usually collections, can be very large, which can lead to a sharp slowdown in the work of the serializer, or lead to errors. In some unpleasant situations, the serializer simply hung the system.
We list the winners in the tests, only in the sum of all tests. The winners in the individual tests are very well represented on the test results pages on the site . Here we draw some conclusions. I draw your attention to the fact that we do not claim the ultimate truth, we only comment on the numbers. Numbers can change a lot with future test updates.
Test results
I will review this test in detail. The rest of the tests - just mostly.
Almost all the tests revealed the same fast serializers: ProtoBuf, NFX Slim, MsgPack, NetSerializer. The warm-up tests gave a very large velocity spread. Microsoft BinaryFormatter showed good packaging on the collections and the worst on the same site. Unfortunately, Json.Net did not break into the lead in any test.
There is an amazing speed variation. NFX Slim does thousands of operations, and, for example, Jil has only one operation per second. The bulk of serializers does one or two dozen operations per second, sometimes a few dozen. What is even more amazing, NFX Slim makes about 45 thousand! deserializations per second. But for obvious reasons, we consider only the slowest operation.
The spread is not as large as in speeds. Several winners show almost the same result and JSON serializers, which naturally, show similar results. We specifically made two tests for one of the JSON serializers (NFX Json). One of the tests gives JSON text in a beautiful format, with all indents and line breaks, and the other test gives JSON without formatting. As you can see, the sizes for both cases are quite different from each other.
This result once again confirms the well-known rule: never format the serialized data in the channel! Do formatting for presentation only and never for data transfer.
Test results
Only ProtoBuf, Microsoft BinaryFormatter and NFX Slim can perform batching serialization. At the same time, Slim has a special batching mode.
There is a large variation in rates for different types of data. Winners vary from ProtoBuf for Trading and EDI classes, to Slim for RPC and Personal classes. At the same time, ProtoBuf could not serialize the RPC class in which the object [] field was encountered. It can be summarized that only Microsoft BinaryFormatter and NFX Slim successfully passed this test. Microsoft BinaryFormatter, as always, showed excellent results in warm-up tests and consistently worse results in packaging, which does not detract from the fact that it worked without errors.
Test results
This test was the most difficult to serialize. Many serializers have not passed it. Many have passed, but at the same time showed terrible speed and packaging. For example, Jil on the test ObjectGraph: Conferences: 1; Participants: 250; Events: 10 packed data in 2.6 MB, and leaders packed data in a little more than 100 KV, that is, they spent 26 times less memory.
In this test, we see several leaders who win by a very large margin. This is ProtoBuf and NFX Slim. Microsoft BinaryFormatter unexpectedly turned out to be among these leaders in terms of packaging.
Test results
It was interesting how with the growth of the data volume more and more serializers ended up working with errors.
As usual on the warming-up dough, the leader is NFX Slim.
It seems that the leaders in the package: ProtoBuf, MsgPack, NetSerializer, NFX Slim - use special packaging methods for such cases and these methods work very well.
I draw your attention to the fact that XML, which is often used for serialization and processing of EDI documents, showed, in the face of the XmlSerializer, disgusting results in packaging, using 8-9 times more space for serialized data.
Why do we need to choose a serializer? Why can't we do with the serializers from the .NET Framework? (Microsoft supplies several serializers, some of which have appeared quite recently, such as Bond and Avro.)
The fact is that serializers are becoming increasingly important elements of distributed systems. A slow serializer can interfere with maximum performance; a fast one can make your system better than its competitors. New serializers for .NET now appear with an enviable constancy. Each of them is advertised as the fastest. As proof of the creators cite test results.
We have developed our own test system and conducted an independent study. Now we will discuss the criteria that will help you make an informed choice of the serializer. The selection criteria are based on the results of the tests performed.
We were surprised to find that many serializers do not pass elementary tests. At best, we got an error in the program, at worst, the data was lost without any warning, or Windows was hanging for an indefinite time. In the intermediate case, the objects were distorted.
Carefully read the results of our tests. These results are very dependent on data. If the data is simple in structure, then almost any serializers do the job. If the data is complex or large, then, alas, all is not so good.
I emphasize reliability, because it’s unlikely that the speed or density of data packing will be an excuse for lost data or a hung system.
Surely, the most reliable serializer is Microsoft BinaryFormatter . He is not the fastest, but there is an important reason. It serializes almost everything without errors.
For example, you receive data from a partner in XML format, and you must work with XML. You have no opportunity to change this situation. In this case, your choice is limited to XmlSerializer and Json.Net.
If you integrate your system with foreign systems, the choice will be made for you, and you will most likely have to use one of two standard formats: XML or JSON. In rare cases, you will have to work with the CSV format or with the format of a particular system. Most often this happens when integrating with systems from the past millennium.
If you need to serialize simple .NET types, such as int, double, bool, then the elementary function ToString () is enough for you.
JSON serializers are more common. JSON is much simpler than XML, which in most cases is an advantage.
Many serializers pack data into their own binary format. JSON format is usually much more compact than XML. Binary formats are usually smaller than JSON.
If you can choose the data format yourself, the binary format is most likely the best choice. But remember, in this case, you must use the same serializer for both serialization and deserialization. At the moment, all binary formats are unique, none of them is standardized.
What is more important: serialization-deserialization speed or data packing density?
The size of serialized data is usually more important than the speed of the serialization-deserialization process. This is due to the fact that the speed of the processor (the speed that determines serialization-deserialization) is much higher than the speed of the data in the network, which is usually directly related to the size of the transmitted data. A 10% reduction in data size can lead to a 10% acceleration of data transfer, and a two-fold increase in the serialization-deserialization rate only to a 1% acceleration.
Look, for example, at serializers such as Bond, Thrift, Cap'n Proto. You don't just take and serialize any classes. You need to use a special IDL language and describe these classes for nothing. Usually you will be helped by utilities that generate class descriptions from the classes themselves. But even if they are, you need to deal with this language, take time away from the development itself.
Other serializers, for example, Slim from NFX, do not require anything from you. You simply serialize any classes. In intermediate cases, the classes being serialized need to be decorated with attributes. Surely you know the attribute [Serializable].
Is this important? Yes it can be important. Especially when your classes are not trivial in structure. For example, in our test system, you will find an EDI test class composed of dozens of nested classes and hundreds of fields. Adding attributes to all these classes and fields was a tedious and lengthy job.
This is also important when you serialize classes from libraries whose code you do not have access to . You can not take the code and add attributes there, the code is not available. Often, to circumvent this situation, programmers use the so-called DTO ( Data Transfer Object ). Their use is fraught with the complexity of the program and the drop in the speed of development. Instead of working on business logic, you have to write code that has nothing to do with it.
If your system is only the receiving or sending side, then you will agree that this is different from the case when you are responsible for both operations.
Serializers can be optimized to work with collections of objects. Other serializers do not distinguish the collection in any way, so they will show much worse speed and packaging.
Data can be very large, which can lead to a sharp slowdown of the serializer or lead to errors in serialization. The serializer can just hang the system.
Big data in memory can affect garbage collection, which in turn can cause long stops for programs.
And here you will be helped by serializers specializing in exactly this task. Here for example, the serializer engaged Linq expressions .
Then the best option would be to write your own highly specialized serializer.
If you do not want to do this, then pay attention to the additional methods used by different serializers. For example, batching is a great way to increase speed. Unfortunately, only a few serializers can use it without additional encoding.
Parallel serialization is also a good method for achieving high speeds. If you use it, the thread-safety of the serializer is important for you.
Project start
This benchmark project began with the article “ Serializers in .NET v.2 ” on GeeksWithBlogs.net. The article reviewed quite a lot of serializers available under .NET. But in order to turn this article and the corresponding code into a real benchmark, it was necessary to make several improvements.
First, serializers had to be tested on several data types. There are universal serializers, and there are specialized ones. Specialized work very well with only a few data types, for other data they work much worse or do not work at all. What we have seen in the future.
')
Secondly, serializers differ greatly in interfaces. Our benchmark should not force the serializer to follow our interface selection. On the contrary, the benchmark must be so flexible that each serializer can use the interface that is most suitable for it. That is, it is necessary to transfer additional parameters of a specific serializer to the benchmark.
The author of one of the serializers asked the author of the article to make an improved test. The author of the serializer was the initiator of this project, he was also the lead developer. Sergey was the developer of the entire Web part of the project, all the great reports. NFX was used as a benchmark platform , which made it possible to do everything planned (and much, much more) very quickly. NFX pulls on hundreds of similar articles, I hope it will interest you too.
Presentation of test results
To begin with, I will dwell a bit on presenting the results, on what requires special attention.
For example, look at the summary information of one of the tests:
On the left we will see three winners in the two most important categories: in speed and in the size of the data being serialized. At once I will make a reservation that there can be more winners, that all serializers that have fallen into the blue, green and, to a lesser, light brown category can be considered winners. The gray category is serializers that did not pass this test.
In the speed column, you can click on the name of the serializer and get a decryption of speed with separate numbers by serialization and deserialization.
The worst speed from serialization and deserialization is taken as the main one. We assume that the total system performance is important to you, and not just serialization or only de-serialization. Your case may be different, so the speed of another operation is also given on the chart with a thin stick.
What to look for:
- For serializers that did not pass the test:
On some tests, most of the tested serializers lost data. If you choose a “fast” serializer to work with, and it will spoil your data, this is the worst thing you can imagine. You will spend a lot of time trying to understand the cause of the corrupted data. And you are lucky if you stumble upon it in development, and not in production.
- Match your data with test data:
Our recommendation: download the benchmark code, change the test data or add your data and test it again. Never trust your intuition, do not trust extrapolation. Virtually any serializer will fall on some particular amount of data. We did not perform marginal tests, do them yourself according to your data. Very few serializers have passed all of our tests.
Attention!
Further on in the text you will constantly come across the words “usually”, “most often”, etc. I apologize for this and understand that this makes the test results a bit uncertain. I hope that you also understand that the test results should not show us the best serializer. They only limit the group of serializers that you need to base. You will use the serializer for YOUR data. Therefore, the final decision should be taken after running tests on ITS data, especially if these data are very different from those used in our tests.
What NOT to pay attention to:
- If the tests show the difference in numbers several times, do not pay attention to the difference in percentages. This is not only meaningless, but also wrong. Small variations in speed or size can be easily distorted by slightly changing the test data.
Test data
We tried to provide data for the most used applications. We have no statistics on the use of serializers, so we selected data based on our own experience. If you see that we missed something important, let us know or just add your test data to Serbench.
We see typical applications in several areas:
- distributed, independent systems (distributed systems) . Programs work independently, in different processes or on different machines, and exchange data. Programs exchange only contracts, interfaces. Under this type of fall messaging system (messaging) .
Data relating to this type: Typical Person, Telemetry, EDI, Batching.
- distributed but tightly coupled systems . The difference from the previous case is that systems can exchange not only contracts, but also libraries. Most often, these related systems are developed in one place. This type includes RPC (Remote Procedure Call) systems.
Data related to this type: Typical Person, Batching, Object Graph.
- storage systems . Data is transferred between programs and data stores. The difference from the previous cases is that the serialization-deserialization cycle does not occur within microseconds or seconds. Data can be stored for years. During the retention period, data contracts often change, which raises the problem of data versioning. We have not tested serializers to work with versions. Any of the available test data can work with storage systems. But serializers that support data versioning may be more convenient in this case.
Typical Person
Here is a simple class with no interfaces and no inheritance. Almost all presented serializers pass this test.
Telemetry
Such data is generated by IoT (Internet of Things) devices. Their difference is the availability of numerical information, timestamps and several identifiers. Sometimes data is very short when one or more numbers are sent; sometimes large arrays of numbers are sent. The data structure is simple. The speed and density of data packing is important here.
Edi
EDI (Electronic Data Interchange) data are equivalent documents. They are characterized by a complex hierarchical structure and nesting of classes. There are collections of classes.
Object graph
If you use object-oriented development, you probably had to deal with such classes. They are characterized by complex relationships between classes. We are testing the Conference class, which has a collection of Events (Event). An event can have several participants (Participant) and several Topics (Conference Topic).
Interestingly, a participant can have multiple Relationships, each of which refers to another participant. The result is cyclic links. This is a common situation, but it turns out that very few serializers can work with cyclic connections.
Batching
Imagine a situation where you need to send multiple instances of objects at once. This is a typical situation in distributed systems. By combining several data items into one packet, which is transmitted over the network in one step, we can significantly speed up the transfer. The package is called batch, hence the name - batching.
Usually, we need to explicitly create a package by enclosing data elements in a special envelope class. Some serializers allow you to do without envelopes, which greatly simplifies development.
Testing process
Everything is simple here. In one test cycle, we will serialize an object or many objects in the case of a batch, and immediately diserialize it back. The target and source objects are compared to filter out errors. The comparison is quick, only for some values. We do not make a full comparison, but all interfaces for a full comparison are available.
Several test cycles are combined into one run (run), at the beginning of which the test data is generated.
Several tests are combined in sequences, the first test in which is the warmup test. This test usually consists of a single loop, the purpose of which is to initialize all the objects necessary for a given serializer.
Some serializers quickly initialize, but slowly serialize, some - vice versa. If you need to use the serializer once, then you should not neglect the results of warm-up tests, for you they are the main ones.
We usually tested a single object first, and then a collection of objects. As it turned out, serializers can be optimized for working with collections. Then they can break from outsiders to the leaders.
Any data, but usually collections, can be very large, which can lead to a sharp slowdown in the work of the serializer, or lead to errors. In some unpleasant situations, the serializer simply hung the system.
Test results
We list the winners in the tests, only in the sum of all tests. The winners in the individual tests are very well represented on the test results pages on the site . Here we draw some conclusions. I draw your attention to the fact that we do not claim the ultimate truth, we only comment on the numbers. Numbers can change a lot with future test updates.
Typical Person
Test results
I will review this test in detail. The rest of the tests - just mostly.
All tests
Almost all the tests revealed the same fast serializers: ProtoBuf, NFX Slim, MsgPack, NetSerializer. The warm-up tests gave a very large velocity spread. Microsoft BinaryFormatter showed good packaging on the collections and the worst on the same site. Unfortunately, Json.Net did not break into the lead in any test.
Warm Up Tests (Warmup)
Speed
There is an amazing speed variation. NFX Slim does thousands of operations, and, for example, Jil has only one operation per second. The bulk of serializers does one or two dozen operations per second, sometimes a few dozen. What is even more amazing, NFX Slim makes about 45 thousand! deserializations per second. But for obvious reasons, we consider only the slowest operation.
Packaging
The spread is not as large as in speeds. Several winners show almost the same result and JSON serializers, which naturally, show similar results. We specifically made two tests for one of the JSON serializers (NFX Json). One of the tests gives JSON text in a beautiful format, with all indents and line breaks, and the other test gives JSON without formatting. As you can see, the sizes for both cases are quite different from each other.
This result once again confirms the well-known rule: never format the serialized data in the channel! Do formatting for presentation only and never for data transfer.
Batching
Test results
Only ProtoBuf, Microsoft BinaryFormatter and NFX Slim can perform batching serialization. At the same time, Slim has a special batching mode.
There is a large variation in rates for different types of data. Winners vary from ProtoBuf for Trading and EDI classes, to Slim for RPC and Personal classes. At the same time, ProtoBuf could not serialize the RPC class in which the object [] field was encountered. It can be summarized that only Microsoft BinaryFormatter and NFX Slim successfully passed this test. Microsoft BinaryFormatter, as always, showed excellent results in warm-up tests and consistently worse results in packaging, which does not detract from the fact that it worked without errors.
Object graph
Test results
This test was the most difficult to serialize. Many serializers have not passed it. Many have passed, but at the same time showed terrible speed and packaging. For example, Jil on the test ObjectGraph: Conferences: 1; Participants: 250; Events: 10 packed data in 2.6 MB, and leaders packed data in a little more than 100 KV, that is, they spent 26 times less memory.
In this test, we see several leaders who win by a very large margin. This is ProtoBuf and NFX Slim. Microsoft BinaryFormatter unexpectedly turned out to be among these leaders in terms of packaging.
EDI X12
Test results
It was interesting how with the growth of the data volume more and more serializers ended up working with errors.
As usual on the warming-up dough, the leader is NFX Slim.
It seems that the leaders in the package: ProtoBuf, MsgPack, NetSerializer, NFX Slim - use special packaging methods for such cases and these methods work very well.
I draw your attention to the fact that XML, which is often used for serialization and processing of EDI documents, showed, in the face of the XmlSerializer, disgusting results in packaging, using 8-9 times more space for serialized data.
Serializer Selection
Why do we need to choose a serializer? Why can't we do with the serializers from the .NET Framework? (Microsoft supplies several serializers, some of which have appeared quite recently, such as Bond and Avro.)
The fact is that serializers are becoming increasingly important elements of distributed systems. A slow serializer can interfere with maximum performance; a fast one can make your system better than its competitors. New serializers for .NET now appear with an enviable constancy. Each of them is advertised as the fastest. As proof of the creators cite test results.
We have developed our own test system and conducted an independent study. Now we will discuss the criteria that will help you make an informed choice of the serializer. The selection criteria are based on the results of the tests performed.
Serialization Reliability
We were surprised to find that many serializers do not pass elementary tests. At best, we got an error in the program, at worst, the data was lost without any warning, or Windows was hanging for an indefinite time. In the intermediate case, the objects were distorted.
Carefully read the results of our tests. These results are very dependent on data. If the data is simple in structure, then almost any serializers do the job. If the data is complex or large, then, alas, all is not so good.
I emphasize reliability, because it’s unlikely that the speed or density of data packing will be an excuse for lost data or a hung system.
Surely, the most reliable serializer is Microsoft BinaryFormatter . He is not the fastest, but there is an important reason. It serializes almost everything without errors.
Do you choose the data format?
For example, you receive data from a partner in XML format, and you must work with XML. You have no opportunity to change this situation. In this case, your choice is limited to XmlSerializer and Json.Net.
If you integrate your system with foreign systems, the choice will be made for you, and you will most likely have to use one of two standard formats: XML or JSON. In rare cases, you will have to work with the CSV format or with the format of a particular system. Most often this happens when integrating with systems from the past millennium.
If you need to serialize simple .NET types, such as int, double, bool, then the elementary function ToString () is enough for you.
JSON serializers are more common. JSON is much simpler than XML, which in most cases is an advantage.
Many serializers pack data into their own binary format. JSON format is usually much more compact than XML. Binary formats are usually smaller than JSON.
If you can choose the data format yourself, the binary format is most likely the best choice. But remember, in this case, you must use the same serializer for both serialization and deserialization. At the moment, all binary formats are unique, none of them is standardized.
Data packing density
What is more important: serialization-deserialization speed or data packing density?
The size of serialized data is usually more important than the speed of the serialization-deserialization process. This is due to the fact that the speed of the processor (the speed that determines serialization-deserialization) is much higher than the speed of the data in the network, which is usually directly related to the size of the transmitted data. A 10% reduction in data size can lead to a 10% acceleration of data transfer, and a two-fold increase in the serialization-deserialization rate only to a 1% acceleration.
Are you trying to squeeze maximum performance out of your system? Or maybe the performance of developers is more important for you?
Look, for example, at serializers such as Bond, Thrift, Cap'n Proto. You don't just take and serialize any classes. You need to use a special IDL language and describe these classes for nothing. Usually you will be helped by utilities that generate class descriptions from the classes themselves. But even if they are, you need to deal with this language, take time away from the development itself.
Other serializers, for example, Slim from NFX, do not require anything from you. You simply serialize any classes. In intermediate cases, the classes being serialized need to be decorated with attributes. Surely you know the attribute [Serializable].
Is this important? Yes it can be important. Especially when your classes are not trivial in structure. For example, in our test system, you will find an EDI test class composed of dozens of nested classes and hundreds of fields. Adding attributes to all these classes and fields was a tedious and lengthy job.
This is also important when you serialize classes from libraries whose code you do not have access to . You can not take the code and add attributes there, the code is not available. Often, to circumvent this situation, programmers use the so-called DTO ( Data Transfer Object ). Their use is fraught with the complexity of the program and the drop in the speed of development. Instead of working on business logic, you have to write code that has nothing to do with it.
Do you select a serializer for serialization and for deserialization, or just for one of these operations?
If your system is only the receiving or sending side, then you will agree that this is different from the case when you are responsible for both operations.
Do you have collections in your data?
Serializers can be optimized to work with collections of objects. Other serializers do not distinguish the collection in any way, so they will show much worse speed and packaging.
What is the size of your data?
Data can be very large, which can lead to a sharp slowdown of the serializer or lead to errors in serialization. The serializer can just hang the system.
Big data in memory can affect garbage collection, which in turn can cause long stops for programs.
Do you need to serialize something very extraordinary?
And here you will be helped by serializers specializing in exactly this task. Here for example, the serializer engaged Linq expressions .
Do you need super super performance?
Then the best option would be to write your own highly specialized serializer.
If you do not want to do this, then pay attention to the additional methods used by different serializers. For example, batching is a great way to increase speed. Unfortunately, only a few serializers can use it without additional encoding.
Parallel serialization is also a good method for achieving high speeds. If you use it, the thread-safety of the serializer is important for you.
Source: https://habr.com/ru/post/263705/
All Articles