Bit Kung Fu, or How to optimize traffic between a mobile application and a server
Old as the world ...
People always strive to keep abreast of the latest developments. Thanks to this aspiration, many media have emerged that need their own mobile application for delivering content to their readers. So in the shops appeared a great many news applications. Hundreds of applications for reading news, newspapers and magazines.

Almost all news applications have a similar hierarchical type of storing and displaying articles: headings or sections, news lists, and the article itself with the pictures contained in it, videos, and so on. Usually in a mobile application, the user has to download these items sequentially while navigating through the application.
 The most boring moment for the user in the navigation phase begins when the download is slow for some reason. Then, quite often, when navigating to an article in the list or when downloading pictures, it can only watch the progress bar. Perhaps that is why the varieties of these elements are also so many?
The most boring moment for the user in the navigation phase begins when the download is slow for some reason. Then, quite often, when navigating to an article in the list or when downloading pictures, it can only watch the progress bar. Perhaps that is why the varieties of these elements are also so many?')
In the article, we will discuss the new method for loading data for media applications, which we proposed and successfully implemented with one of our customers.
Salt of life in search of new. (with)
Standard loading, for example, of the list of articles in the section occurs as follows: the application requests the latest N news, reduces this list to what has been downloaded and stored locally, forms a new list and shows it to the user. Next, the user enters the article, downloads content and so on. When downloading a list of articles, the application and the server can interact in two ways:
• The application asks to download the list, starting with the last download. But then the server starts an operation to search for the necessary data in the database, which loads the server.
• The application always loads the last N articles and keeps the list on its side, but then it will be a losing option for traffic with frequent downloads.
It would seem that there can be changed? And it turned out that you can! But it is necessary to apply a creative approach and a little hard work.
We decided to offer one of our customers an original approach to the data loading method, in which the user will have a quick download of news content and traffic savings with frequent periodic use of the application.
Our idea was as follows: on the application side, you must always keep a fresh archive of news. And periodically in the background we will update it to the current state.

Easy to say, but harder to implement. It's great that news will always be up to date without (sometimes lengthy) data loading.
But how to synchronize the archive that is in the application, and prepared an updated archive, located on the server. Do you just need to download and replace the file? It is not effective ...
Solution scheme
So, we have two files - on the server and on the client (the initial situation, when there is no file in the application, we will consider later). And we do not want to load the entire server file with every update. Surely, many have already thought that you can compare 2 versions of a file and download only different parts. We thought the same and looked for ready-made solutions. As a result, came to the two most popular: bsdiff / bspatch and rsync.
We noticed bsdiff because of its ability to find the same sequence of bytes in two versions of files, but located in different places. Look at the two bit sequences “0 1 0 1 0 1 0 1” and “0 0 1 0 1 0 1 0”. They only share the first bit, but they can find a common sequence.
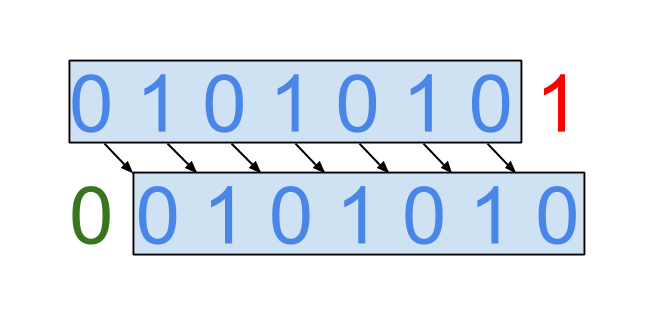
Thus, the second sequence from the first one can be obtained by shifting the first 7 bits to the right by a bit, add 0 to the free space and delete the last bit. This sequence of operations, recorded in a specific format and saved to a file, is the result of the bsdiff utility. Later this file, called a patch, and the source file can be processed by the bspatch utility to get a new file.
It sounded promising, but only versions of the file are needed to calculate the patch. As a result, the concept looked like this: on the server we store N named release versions for the last few days and another N-1 pre-calculated patches from each of them to the last. The client also has some version of the release and its id, according to which he will receive the necessary patch from the server and update it.
I wanted a more universal solution so that it was possible to upgrade from any version and not depend on N, but we were most worried about the fact that bspatch uses a memory-hungry algorithm. To patch a 1MB file with a 0.1MB patch, you need to spend 1MB + 0.1MB of RAM.
With such thoughts, we left bsdiff, intending never to return to it, and began to explore rsync . This client-server utility running at the TCP level
widely known among users of unix-like systems. In general terms, the algorithm of its work is reduced to the following steps:
1. The client splits his file into sequences of size K;
2. For each sequence, the client counts two checksums: MD4 and a ring hash and sends all the amounts to the server;
3. The server tries to find in its version of the file a sequence of size K, both sums of which coincide with one of those sent by the client;
4. The server generates a set of instructions for the client, which he needs to execute in order to turn his version of the file into the necessary one.
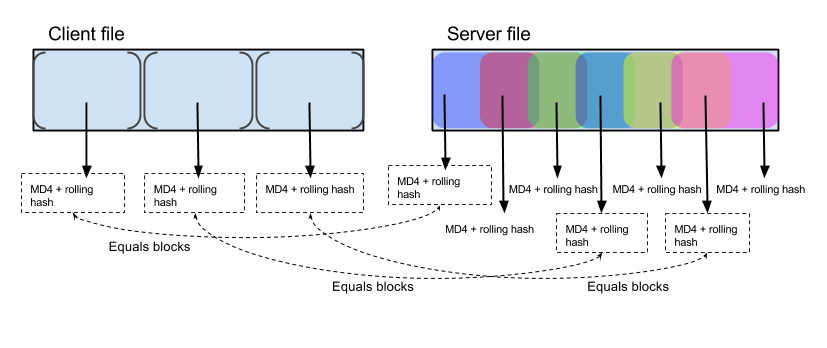
It is noteworthy that the server counts the amounts from intersecting sequences. This allows you to find the same data block, even if it is located at a different place, when compared with the old version of the file.
It looks archiccusto: synchronization of any version of the file (including no), smart search for common parts of the file - what you need. We conducted several proof-of-concept tests of the rsync utility from the Ubuntu repository, measuring the amount of data to be collected between the supposedly “yesterday” and “today's” releases, and obtained very encouraging results. That's just rsync is not designed for a large number of clients. Each file synchronization is the load on the server processor by checksum calculations. If we had offered such a concept, multiplied by our 200k daily users, the guys from the back-end would simply have twisted their fingers at their heads. Therefore, we did not offer this.
But, fortunately, after experimenting with rsync, we found a solution that finally came to us - zsync .
ZSYNC
In fact, zsync is an open source http wrapper over rsync. It uses the same algorithms for finding common parts / file differences as rsync, but the data transfer mechanism between the client and the server is completely different.
The first step on the server side of the target file is processed by the zsyncmake utility, which will generate the same file with the * .zsync extension with all calculated non-overlapping checksums, block size, reference to the main file and other useful information for the client. HTTP files are opened to both target files and * .zsync. The client first downloads the * .zsync file, then tries to find in his version of the file blocks with checksums identical to any amount from the metafile. Now the client knows what data blocks he lacks and makes the HTTP Range request the target file, receiving only the missing part of it.
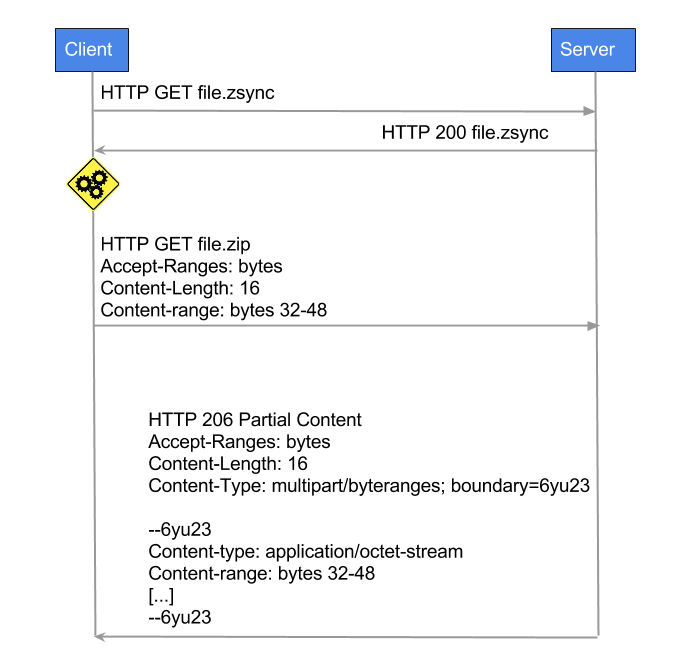
Have you noticed how cleverly on one of the steps did the client and server switch between zrsync and rsync? :) Now the HTTP server as the rsync client counts the amounts for non-overlapping blocks, and the HTTP client as the rsync server finds these blocks in its file.
To get zsync to work for us, we first had to port it slightly to Android. And to integrate zsync into our project, we wrote a java-wrapper that worked with zsync via JNI so that only algorithmic tasks remained on the C-code side, and downloading, deleting metafiles and range requests fell on the Android API.
There is another very important difference between rsync and zsync, which we haven’t mentioned before. The fact is that changing even one byte of the source file can lead to changes in the entire file of its archive, so the compression algorithms work. For this reason, rsync is not very efficient in synchronizing archives. You can try to increase efficiency by reducing the size of the blocks into which the file is divided. But this is a double-edged sword, because it will increase the volume of operations to find the same blocks on the server. The balance between the minimum block size and maximum efficiency depends on specific archives, compression algorithms and the content itself. Fortunately, zsync can, if necessary, divide into blocks and count the amounts not the archive itself, but its unpacked contents, but at the same time determine the missing blocks not from the unpacked content, but from the archive. Here is a trick, read more here in the Compressed Content section.
“What is your evidence?” (C)
Nothing is better than experimenting with real data. We collected 2 issues: Saturday and Sunday, with sizes of 7.8MB and 8.5MB, respectively. In the Sunday release, 2 articles disappeared and 3 new ones appeared, which brought about 2.9 MB of new pictures and about 100KB of new text and auxiliary files to the archive.
Let's see how zsync does the task:
Read topstories.zip. Target 61.8% complete.
downloading from http: // [...] /topstoriesweb.zip:
#################### 100.0% 0.0 kBps DONE
verifying download ... checksum matches OK
used 5234688 local fetched 3242306
The traffic was 3242306 bytes. Slightly more than the actual size of the new data, but this is only ~ 7% of redundancy. Good job, zsync.
One more thing ...
We have already done a good job to surprise the user of our application with solutions that he will never know about, but you can always do something a little better. And we did. We have prepared a special issue on the server from several of the hottest articles that only downloads when the application is launched for the first time so that the user will be up to date in a few seconds. In the meantime, he is busy, zsync will make sure that this small release becomes a real one.
For more than a year, we have been using the bundle downloading scheme in conjunction with zsync instead of the usual “request-per-item” for content delivery to users and are not going to refuse, because it seems more convenient to us:
• 1 request for release or 1 request for section is implemented easier than a chain: download list of articles -> download content of each article -> download media files of each article -> etc;
• out of the box offline mode, subject to successful synchronization, of course;
• Fits perfectly into the scheme of effective, in Google's opinion, synchronization : synchronization will occur at a time favorable for the device, with normal battery power and a good Internet connection.
But the whole Internet will not be able to download. This approach obviously requires much more local storage and you need to carefully approach the question of what we preload, and what is not. For example, to save space on old devices, we decided to teach our server to prepare special issues with pictures of lower resolution, and for devices with a slow Internet connection, this is altogether without illustrations. This does not mean that the user will not see the photos at all, they simply will not fall into preloading.
That's all
This method does not solve all the problems of transferring news content from the server to the numerous devices of our users. But he helped us in the application to speed up the loading of content, reducing the waiting for users, and also significantly reduce the load on the server. We managed to apply a creative approach and make a fast-running, cost-effective software solution, while not increasing the capacity of server hardware.
Have a great day everyone!
Source: https://habr.com/ru/post/263397/
All Articles