Fault tolerance in MS SQL 2012 for 1C: Enterprise 8.2
Many are currently using resiliency technologies in building information systems and this topic is not new. At the same time, ensuring only fault tolerance is no longer considered the only and sufficient requirement. The ideal system, in my opinion, should be
For those who have no desire to master a lot of letters and pictures, I suggest moving to the end of the article to conclusions, along the way you can still look into the experiment.
First, let's take a quick look at existing Microsoft high availability database technologies. One solution for fault tolerance is to use a Windows Server Failover Cluster (WSFC). Consider it by example:
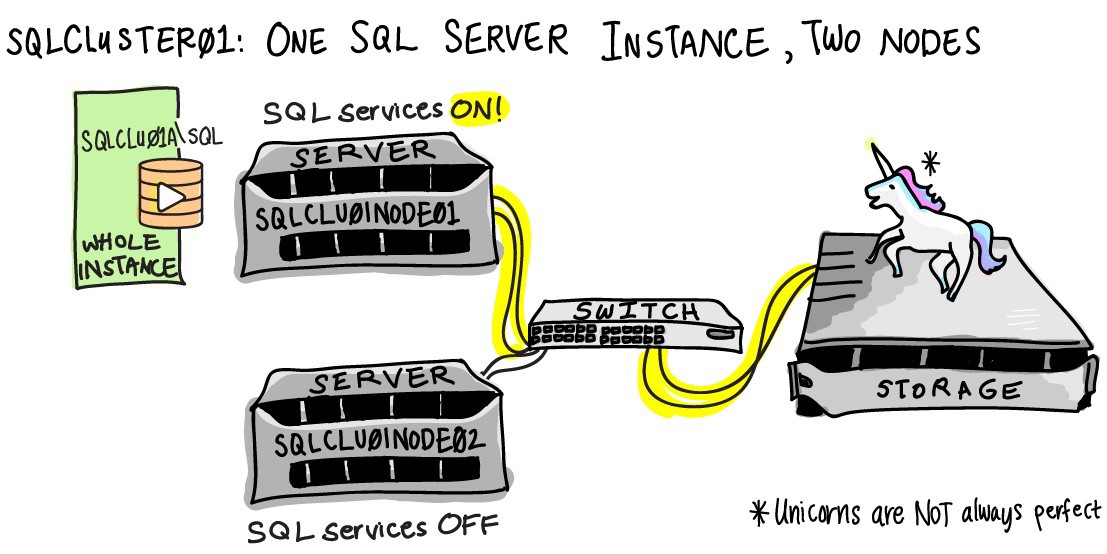
The WSFC uses shared network storage (SAN). When installing SQL in a failover cluster, system and user databases are placed on shared storage. In the diagram, two nodes (SQLCLU01NODE01 and SQLCLU01NODE02) are combined into a failover cluster SQLCLUSTER01A. In this case, SQL is set to a named instance (instance), i.e. The clustered SQL server connection address is as follows SQLCLUSTER01A \ SQL. During normal operation, one of the cluster nodes (server) is active (in the example, SQLCLU01NODE01), and the second is in hot standby. When the active server SQLCLU01NODE01 fails, the cluster service switches (transparent to users) to the backup node SQLCLU01NODE01.
')
The obvious advantages of WSFC follow from the above: high reliability by full server redundancy, no downtime in case of server failure, as well as disadvantages: no protection of disk array failure, high solution cost (idle standby server, similar to the working one).
The solution has been around for a long time (in my opinion, starting with Windows Server 2000 and SQL Server 2000) and should not cause any difficulties when deploying.
With the release of SQL2005SP1, the possibility of database mirroring has appeared. The basic principle of mirroring is to create a hot backup copy of a database on another server (storage).
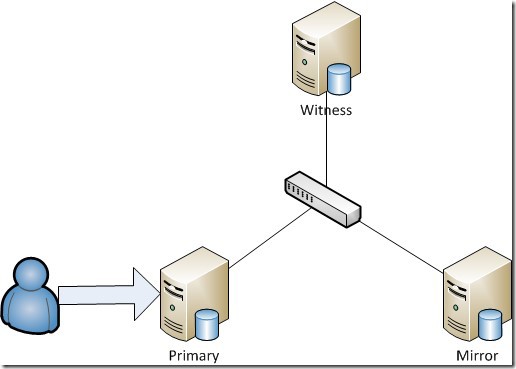
On the primary server (Primary) is a database (principal database), which users normally work with.
On the backup server (Mirror) is a mirror copy of the database (mirror database).
When protected synchronous mode of mirroring, a witness server (Witness) can be added to the schema, the task of which is to monitor the mirroring and in the event of a failure of the main server or database, automatically bring the mirrored database to the operational state.
The advantages of mirroring are: ensuring the fault tolerance of disk arrays, the ability to use the resources of a backup server, the ability to create a geographically distributed cluster. Disadvantages: the high cost of the solution (requires a backup server with a disk subsystem, as well as a tracking server).
It should be noted that the connection to the mirror database by the client application will not work due to the fact that this database is always in recovery mode. In this case, you can use a snapshot (snapshot) of the mirror base. You can read about this and other Microsoft technologies, for example, here.
In addition to all of the above, SQL 2012 introduced a new functionality - AlwaysOn Accessibility Groups. What Microsoft writes to us:
Interesting ... Ie We are provided with a new high-level enterprise availability technology and it most likely should be cooler than what is already there.
Let's try to understand the features. At first glance, the AlwaysOn availability group is the development of mirroring. There are many instructions on the network for deploying and configuring AlwaysOn, so I’ll only talk about the essence. To deploy AlwaysOn, you need a WSFC failover cluster. To enable AlwaysOn support, you must install MS SQL on the failover cluster instance and enable AlwaysOn high availability in the SQL service properties (SQL Server Configuration Manager snap-in). Naturally, this must be done on all servers that we plan to use for AlwaysOn.
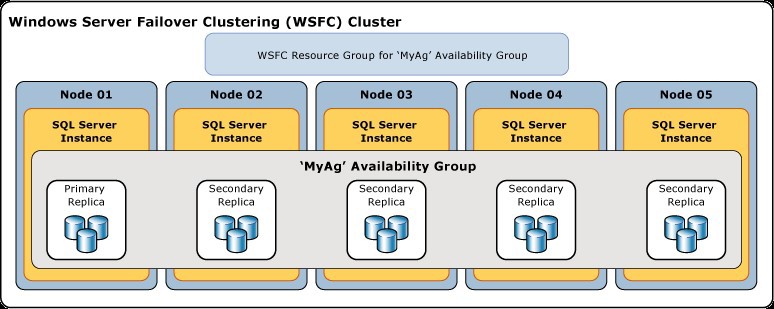
The following figure shows a WSFC cluster with nodes Node01-Node05. An instance of SQL server with AlwaysOn support is installed on each node. As part of the SQL servers, the MyAg availability group has been created with the maximum possible number of replicas (the working base is Primary Replica and the 4th copies are Secondary Replica).
An accessibility group is a collection of availability replicas, their modes of operation, a collection of databases, and a group listener. The figure below shows the MS SQL Management Studio utility with an availability group.
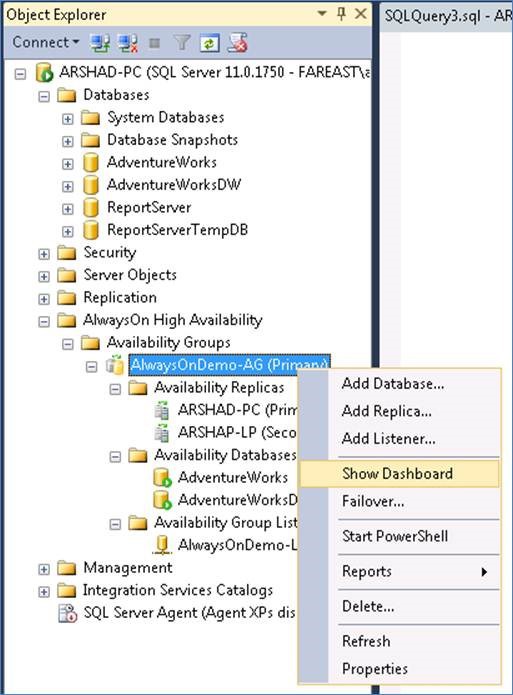
Here we see a connection to the SQL server instance named ARSHAD-PC. On this server, an AlwaysOnDemo-AG availability group has been created, to which two replicas have been added (servers on which replicas are located) ARSHAD-PC and ARSHAD-LP. And, at the moment, the main replica of the availability group is located on the ARSHAD-PC server and this group is managed from the same server. The accessibility group also includes two databases, AdventureWorks and AdventureWorksDW. This availability group has a listener named AlwaysOnDemo-L. In essence, this is the fault-tolerant address of the connection to the virtual server of the availability group.
Accessibility groups can be created an unlimited number, and there can be many databases in one group. Creating a group is accompanied by a simple and clear wizard and should not cause any special problems. It is worth paying attention to two features.
When adding the base of the current server to the availability group, you must first make an archive of this base (the recovery model must be Full). Creating a listener when creating an availability group will require domain administrator authority.
And when adding databases to an existing availability group, the authority of the SQL server administrator will suffice.
It is also necessary to mention that the rest of the “binding” (users, maintenance plans, agent tasks, etc.) that are not in the accessibility group remains local to the server. About synchronization between servers and the coordination among themselves of this "binding" should be taken care of independently.
The advantages and disadvantages of AlwaysOn are basically the same as mirroring, but there are also features. As I understand it, the main differences between AlwaysOn and mirroring are the ability to create read-only replicas, the ability to create more than one copy, easy setup, greater flexibility, and the lack of a Whitness server (instead of a listener in the accessibility group).
Due to some experience with 1C, there was a desire to test the work of AlwaysOn together with 1C: Enterprise. Moreover, when building a WSFC for 1C, there should not be any problems or features. In fact, AlwaysOn should provide fault tolerance higher than WSFC (if you use different storages), while it will be possible to unload the main database from report users (ReadOnly replica) and we will be able to distribute the load across the servers by creating several working groups.
The 1C: Enterprise platform, starting from version 8.2.17, officially supports working with MSSQL 2012 (before that, it was necessary to transfer the sp_dboption stored procedure from SQL2008).
In connection with the emergence of AlwaysOn in SQL, the ODBC connection string syntax was added, the following parameters appeared: ApplicationIntent - allows you to determine the type of workload (ReadOnly / ReadWrite), MultiSubnetFailover - accelerated detection of the active server, etc. These new features do not support 1C. There is a way out - to specify the address of a listener when connecting to the working database, and to the database in read mode, connect directly to the ReadOnly server replica (see the experiment for more details).
Work with the base to read. As you know, when working with 1C, even if the user is not going to change anything in the database, there are algorithms that try to call insert and update in the database. The easiest way is to rewrite the 1C configuration in which to remove (comment out) parts of the code that lead to changes. If this is not done, the user will not be able to work with the ReadOnly database - 1C will fall off with an error that it is impossible to change the database. Below are examples for typical configurations.
So, the experiment itself. Earlier, we agreed that we will explore AlwaysOn SQL 2012 in relation to 1C. To begin, I will describe the server configuration.
We have 4 servers: one application server 1C and three SQL servers in a cluster.
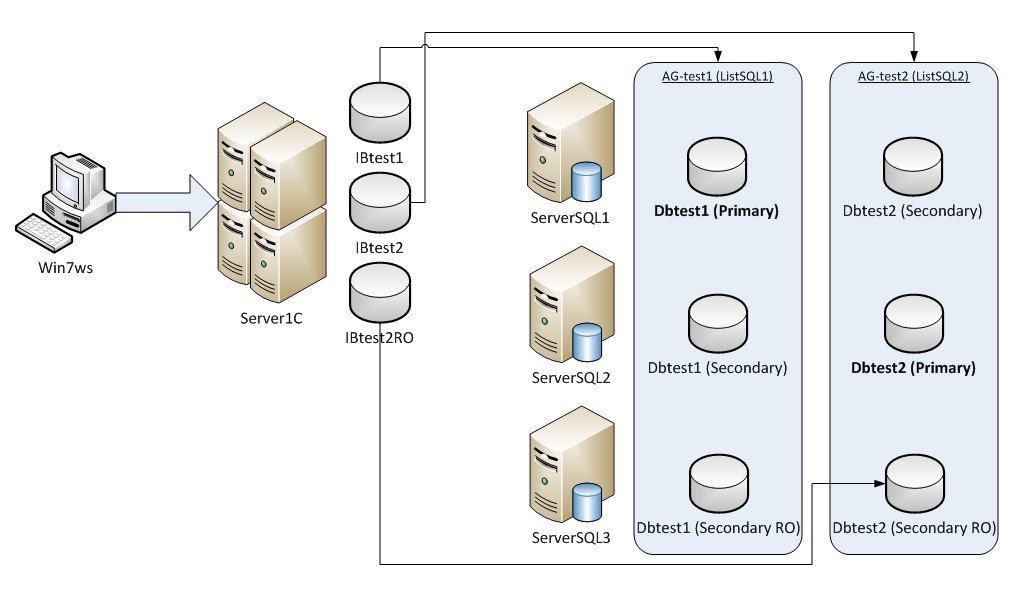
The experiment will be carried out in two stages. At the first stage, we will test the possibility of operating the 1C information database using AlwaysOn SQL 2012 and check the failover. In the second stage, we examine the work of the ReadOnly replica. For simplicity, we restrict ourselves to two databases.
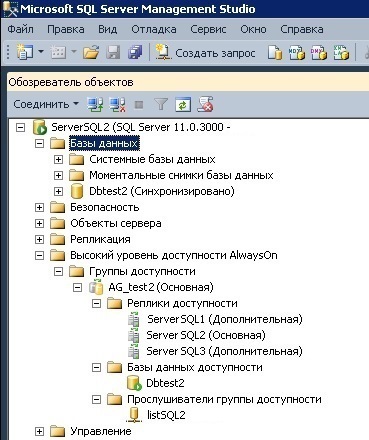
As the 1C information base, we take the typical configuration “1C: Enterprise Accounting”. Let's do the preparatory work and configure the servers, availability groups and databases. So, we create the Dbtest2 database on the ServerSQL2 server, then on the same server we create the availability group AG_test2, where we place the same database:
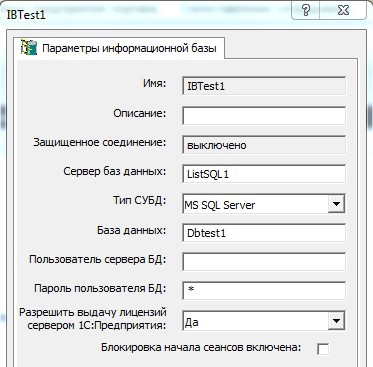
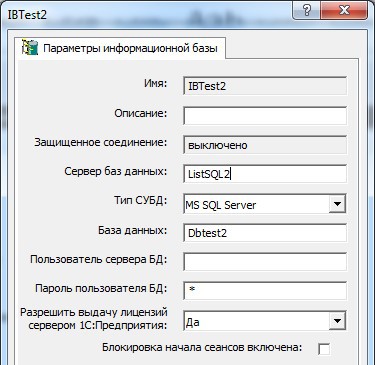
We do the same with the Dbtest1 database on ServerSQL1. Now on the application server “Server1C” we register two information bases:
Well, let's proceed to the experiment itself, connecting from a client computer using 1C: Peredpriyatiya to both information databases. Let's run in both 1C: Enterprise sessions the formation of any long-running report, and without waiting for the completion of its formation, we will simulate a server failure in the availability group AGtest2:
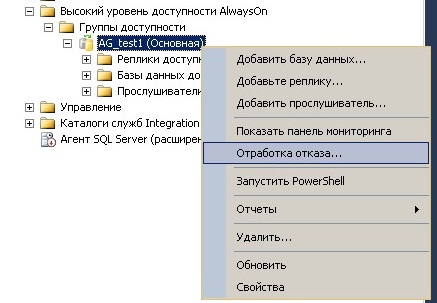
And then we get an error in the information database, which is located in the accessibility group, where the failure was modeled:

Connection to another information base (for obvious reasons) remains working. We restart on the client the 1C application of the “emergency” information database, the program works correctly. At the same time, we can observe in SQL Management Studio that now the main replica in this availability group is ServerSQL1.î
Probably, if we do not read, but change something, for example, to conduct a document, then the result of the change will most likely be rolled back in the transaction by mistake. Those. fault tolerance does not apply to running requests.
Now let's try working with the ReadOnly database. In order to connect from 1C to such a database, you need to do two things: modify the 1C configuration so that it does not write to the database during operation, and set up the connection of the information base.
Examples of refinement configuration 1C above. As for connecting to the SQL database, then everything is much easier. Since 1C: Enterprise platform does not support the new syntax of the connection string to MSSQL 2012, we will write the connection to the database in ReadOnly mode directly:
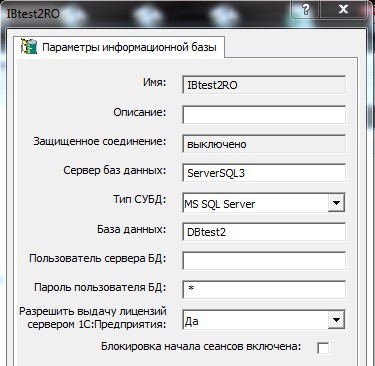
You must also specify the ability to connect to the ReadOnly replica for all clients. To do this, open the properties of the availability group in SQL Management Studio and change the “Secondary replica for reading” property from “Read only” to “Yes” for the replica:
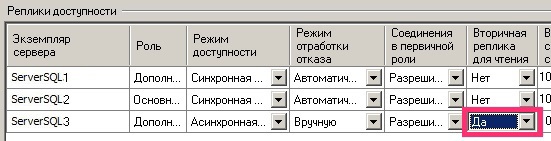
After that, we connect from the client computer with the 1C: Enterprise application to the ReadOnly information base. Connection occurs without problems, reports are generated. But when you try to change something, SQL returns an error about the impossibility of changes and the 1C session closes.
Additionally, I note that in large databases it is absolutely possible to allocate a significant category of users for working with reports (this is the case). By allocating individual servers for them (1C and SQL), you can distribute the load across hardware resources. It works.
Update information in the database ReadOnly occurs "almost instantly." Only a significant change in the data in the main replica may result in a delay in updating the database for reading.
A curious effect was also noticed. In the main database we change the structure (for example, add a new directory), having previously kicked out users. At the same time, we do not expel users from the database for reading, report users continue to work quietly. At the same time, the main base changes the structure, full-fledged users start working in it, they fill in the new reference book. Changing the base structure and filling the base with new information is overloaded into a replica for reading. At the same time, users of reports (replicas for reading) will not see changes in the structure in the current session, i.e. The new directory (as the 1C client read the old metadata). But they will always have updated information from "known" objects. As soon as the users of the reports restart 1C (re-read the metadata), they will see a change in the structure (in our example, a new reference).
It is clear that this behavior has a negative point - it is the control of the integrity of receiving information (for example, the user can generate a report on an outdated algorithm).
Unfortunately, there is fault tolerance in the Microsoft DBMS, but there is still no balancing. It’s also disappointing to work with a failure in AlwaysOn: the active connections to the base fall off. The expectations, based on the general description of technology on Microsoft resources and on presentations at various conferences, were somewhat different. But looking at the resources of Microsoft, I found this .
All honestly said, but in the general descriptions of this important feature is not, and it becomes obvious only after the experiment.
But at the same time, I was pleased with the flexibility and ease of setting up and managing AlwaysOn.
I was also pleased with the “transparent” for 1C work of the ReadOnly replica, although it is necessary to “finish” the 1C configuration a little.
Well, it should be said that the current implementation of AlwaysOn failover can easily be used if the business is not critical to lose pending transactions and disconnect active sessions at the moment of switching.
PS: An article from the report, which is 2.5 years old, but it seemed to me that it is relevant even now (despite the release of SQL2014 and 1C 8.3).
PPS: And yet - do not forget to do BackUps, AlwaysOn does not replace them.
- Fault tolerant (ensuring continuous operation of the system in case of failure of its component parts)
- With load balancing and high utilization of resources (with the current operation, even load distribution and use of all resources, including those reserved for failure), if possible
- Easy to expand (scalable)
For those who have no desire to master a lot of letters and pictures, I suggest moving to the end of the article to conclusions, along the way you can still look into the experiment.
Fault tolerance in MS SQL
First, let's take a quick look at existing Microsoft high availability database technologies. One solution for fault tolerance is to use a Windows Server Failover Cluster (WSFC). Consider it by example:
The WSFC uses shared network storage (SAN). When installing SQL in a failover cluster, system and user databases are placed on shared storage. In the diagram, two nodes (SQLCLU01NODE01 and SQLCLU01NODE02) are combined into a failover cluster SQLCLUSTER01A. In this case, SQL is set to a named instance (instance), i.e. The clustered SQL server connection address is as follows SQLCLUSTER01A \ SQL. During normal operation, one of the cluster nodes (server) is active (in the example, SQLCLU01NODE01), and the second is in hot standby. When the active server SQLCLU01NODE01 fails, the cluster service switches (transparent to users) to the backup node SQLCLU01NODE01.
')
The obvious advantages of WSFC follow from the above: high reliability by full server redundancy, no downtime in case of server failure, as well as disadvantages: no protection of disk array failure, high solution cost (idle standby server, similar to the working one).
The solution has been around for a long time (in my opinion, starting with Windows Server 2000 and SQL Server 2000) and should not cause any difficulties when deploying.
With the release of SQL2005SP1, the possibility of database mirroring has appeared. The basic principle of mirroring is to create a hot backup copy of a database on another server (storage).
On the primary server (Primary) is a database (principal database), which users normally work with.
On the backup server (Mirror) is a mirror copy of the database (mirror database).
When protected synchronous mode of mirroring, a witness server (Witness) can be added to the schema, the task of which is to monitor the mirroring and in the event of a failure of the main server or database, automatically bring the mirrored database to the operational state.
The advantages of mirroring are: ensuring the fault tolerance of disk arrays, the ability to use the resources of a backup server, the ability to create a geographically distributed cluster. Disadvantages: the high cost of the solution (requires a backup server with a disk subsystem, as well as a tracking server).
It should be noted that the connection to the mirror database by the client application will not work due to the fact that this database is always in recovery mode. In this case, you can use a snapshot (snapshot) of the mirror base. You can read about this and other Microsoft technologies, for example, here.
New features in MS SQL 2012
In addition to all of the above, SQL 2012 introduced a new functionality - AlwaysOn Accessibility Groups. What Microsoft writes to us:
If you’re not a problem, you’ll be able to manage your project.
Interesting ... Ie We are provided with a new high-level enterprise availability technology and it most likely should be cooler than what is already there.
Let's try to understand the features. At first glance, the AlwaysOn availability group is the development of mirroring. There are many instructions on the network for deploying and configuring AlwaysOn, so I’ll only talk about the essence. To deploy AlwaysOn, you need a WSFC failover cluster. To enable AlwaysOn support, you must install MS SQL on the failover cluster instance and enable AlwaysOn high availability in the SQL service properties (SQL Server Configuration Manager snap-in). Naturally, this must be done on all servers that we plan to use for AlwaysOn.
The following figure shows a WSFC cluster with nodes Node01-Node05. An instance of SQL server with AlwaysOn support is installed on each node. As part of the SQL servers, the MyAg availability group has been created with the maximum possible number of replicas (the working base is Primary Replica and the 4th copies are Secondary Replica).
An accessibility group is a collection of availability replicas, their modes of operation, a collection of databases, and a group listener. The figure below shows the MS SQL Management Studio utility with an availability group.
Here we see a connection to the SQL server instance named ARSHAD-PC. On this server, an AlwaysOnDemo-AG availability group has been created, to which two replicas have been added (servers on which replicas are located) ARSHAD-PC and ARSHAD-LP. And, at the moment, the main replica of the availability group is located on the ARSHAD-PC server and this group is managed from the same server. The accessibility group also includes two databases, AdventureWorks and AdventureWorksDW. This availability group has a listener named AlwaysOnDemo-L. In essence, this is the fault-tolerant address of the connection to the virtual server of the availability group.
Accessibility groups can be created an unlimited number, and there can be many databases in one group. Creating a group is accompanied by a simple and clear wizard and should not cause any special problems. It is worth paying attention to two features.
When adding the base of the current server to the availability group, you must first make an archive of this base (the recovery model must be Full). Creating a listener when creating an availability group will require domain administrator authority.
And when adding databases to an existing availability group, the authority of the SQL server administrator will suffice.
It is also necessary to mention that the rest of the “binding” (users, maintenance plans, agent tasks, etc.) that are not in the accessibility group remains local to the server. About synchronization between servers and the coordination among themselves of this "binding" should be taken care of independently.
The advantages and disadvantages of AlwaysOn are basically the same as mirroring, but there are also features. As I understand it, the main differences between AlwaysOn and mirroring are the ability to create read-only replicas, the ability to create more than one copy, easy setup, greater flexibility, and the lack of a Whitness server (instead of a listener in the accessibility group).
Due to some experience with 1C, there was a desire to test the work of AlwaysOn together with 1C: Enterprise. Moreover, when building a WSFC for 1C, there should not be any problems or features. In fact, AlwaysOn should provide fault tolerance higher than WSFC (if you use different storages), while it will be possible to unload the main database from report users (ReadOnly replica) and we will be able to distribute the load across the servers by creating several working groups.
Work 1C: Enterprise and MS SQL 2012
The 1C: Enterprise platform, starting from version 8.2.17, officially supports working with MSSQL 2012 (before that, it was necessary to transfer the sp_dboption stored procedure from SQL2008).
In connection with the emergence of AlwaysOn in SQL, the ODBC connection string syntax was added, the following parameters appeared: ApplicationIntent - allows you to determine the type of workload (ReadOnly / ReadWrite), MultiSubnetFailover - accelerated detection of the active server, etc. These new features do not support 1C. There is a way out - to specify the address of a listener when connecting to the working database, and to the database in read mode, connect directly to the ReadOnly server replica (see the experiment for more details).
Work with the base to read. As you know, when working with 1C, even if the user is not going to change anything in the database, there are algorithms that try to call insert and update in the database. The easiest way is to rewrite the 1C configuration in which to remove (comment out) parts of the code that lead to changes. If this is not done, the user will not be able to work with the ReadOnly database - 1C will fall off with an error that it is impossible to change the database. Below are examples for typical configurations.
- Routine tasks, obviously for the ReadOnly database, they need to be disabled
- Processing the “Function Panel”, when opening, always tries to set the value of the Open option when starting the Function Panel of the Register of Users Settings to True. Workarounds - disable the "Open the When Starting the Function Panel" setting for users, comment out the code or add a special role ReadOnly, and execute the code if the role is different
- Processing the “Function Panel”, when closing, records the value of the “CurrentPagePanelsFunction” parameter in the information register of the “Users Settings” information. Bypass paths - disable the “Open the When Starting the Function Panel” setting for the user, add the ReadOnly special role, and execute the code if the role is different
- Online user support (general form "Internet Customer Support Online Access Error"). When starting the 1C configuration, it offers to connect to the 1C server and, if there is a connection, installs the setting in the general settings storage. Workarounds - reset auto-connect settings for Internet support by creating external processing with the following button code:
- When a report is closed (for example, a reverse balance sheet), the report settings are recorded in the “Saved Settings” directory. Workarounds: add the ReadOnly special role and, in the SaveSetup procedure, configure the general module StandardReports, insert the check of saving settings, if the role is different
Experiment
So, the experiment itself. Earlier, we agreed that we will explore AlwaysOn SQL 2012 in relation to 1C. To begin, I will describe the server configuration.
We have 4 servers: one application server 1C and three SQL servers in a cluster.
The experiment will be carried out in two stages. At the first stage, we will test the possibility of operating the 1C information database using AlwaysOn SQL 2012 and check the failover. In the second stage, we examine the work of the ReadOnly replica. For simplicity, we restrict ourselves to two databases.
As the 1C information base, we take the typical configuration “1C: Enterprise Accounting”. Let's do the preparatory work and configure the servers, availability groups and databases. So, we create the Dbtest2 database on the ServerSQL2 server, then on the same server we create the availability group AG_test2, where we place the same database:
We do the same with the Dbtest1 database on ServerSQL1. Now on the application server “Server1C” we register two information bases:
Well, let's proceed to the experiment itself, connecting from a client computer using 1C: Peredpriyatiya to both information databases. Let's run in both 1C: Enterprise sessions the formation of any long-running report, and without waiting for the completion of its formation, we will simulate a server failure in the availability group AGtest2:
And then we get an error in the information database, which is located in the accessibility group, where the failure was modeled:
Connection to another information base (for obvious reasons) remains working. We restart on the client the 1C application of the “emergency” information database, the program works correctly. At the same time, we can observe in SQL Management Studio that now the main replica in this availability group is ServerSQL1.î
Probably, if we do not read, but change something, for example, to conduct a document, then the result of the change will most likely be rolled back in the transaction by mistake. Those. fault tolerance does not apply to running requests.
Now let's try working with the ReadOnly database. In order to connect from 1C to such a database, you need to do two things: modify the 1C configuration so that it does not write to the database during operation, and set up the connection of the information base.
Examples of refinement configuration 1C above. As for connecting to the SQL database, then everything is much easier. Since 1C: Enterprise platform does not support the new syntax of the connection string to MSSQL 2012, we will write the connection to the database in ReadOnly mode directly:
You must also specify the ability to connect to the ReadOnly replica for all clients. To do this, open the properties of the availability group in SQL Management Studio and change the “Secondary replica for reading” property from “Read only” to “Yes” for the replica:
After that, we connect from the client computer with the 1C: Enterprise application to the ReadOnly information base. Connection occurs without problems, reports are generated. But when you try to change something, SQL returns an error about the impossibility of changes and the 1C session closes.
Additionally, I note that in large databases it is absolutely possible to allocate a significant category of users for working with reports (this is the case). By allocating individual servers for them (1C and SQL), you can distribute the load across hardware resources. It works.
Update information in the database ReadOnly occurs "almost instantly." Only a significant change in the data in the main replica may result in a delay in updating the database for reading.
A curious effect was also noticed. In the main database we change the structure (for example, add a new directory), having previously kicked out users. At the same time, we do not expel users from the database for reading, report users continue to work quietly. At the same time, the main base changes the structure, full-fledged users start working in it, they fill in the new reference book. Changing the base structure and filling the base with new information is overloaded into a replica for reading. At the same time, users of reports (replicas for reading) will not see changes in the structure in the current session, i.e. The new directory (as the 1C client read the old metadata). But they will always have updated information from "known" objects. As soon as the users of the reports restart 1C (re-read the metadata), they will see a change in the structure (in our example, a new reference).
It is clear that this behavior has a negative point - it is the control of the integrity of receiving information (for example, the user can generate a report on an outdated algorithm).
findings
Unfortunately, there is fault tolerance in the Microsoft DBMS, but there is still no balancing. It’s also disappointing to work with a failure in AlwaysOn: the active connections to the base fall off. The expectations, based on the general description of technology on Microsoft resources and on presentations at various conferences, were somewhat different. But looking at the resources of Microsoft, I found this .
All honestly said, but in the general descriptions of this important feature is not, and it becomes obvious only after the experiment.
But at the same time, I was pleased with the flexibility and ease of setting up and managing AlwaysOn.
I was also pleased with the “transparent” for 1C work of the ReadOnly replica, although it is necessary to “finish” the 1C configuration a little.
Well, it should be said that the current implementation of AlwaysOn failover can easily be used if the business is not critical to lose pending transactions and disconnect active sessions at the moment of switching.
useful links
- http://msdn.microsoft.com/en-us/library/ff929171.aspx
- http://support.microsoft.com/default.aspx?scid=kb;EN-US;822400
- http://softpoint.ru/products_id15.htm
- http://andriy.co/Zerkalirovanie_bazy_dannyh_na_MSSQL_Server_2005_2008.aspx
- http://www.brentozar.com/archive/2010/11/sql-server-denali-database-mirroring-rocks/
PS: An article from the report, which is 2.5 years old, but it seemed to me that it is relevant even now (despite the release of SQL2014 and 1C 8.3).
PPS: And yet - do not forget to do BackUps, AlwaysOn does not replace them.
Source: https://habr.com/ru/post/263267/
All Articles