How to design and write a full program
"Instructions for creating a functional application", part 1.
“It seems to me that I understand functional programming at a basic level, and I even wrote simple programs, but how can I create a full-fledged application, with real data, error handling, and so on?”
This is a very common question, so I decided that in this series of articles I will describe the instruction covering design, validation, error handling, persistence, dependency management, code organization, and so on.
First, a few comments and cautions:
An overview of what I plan to describe in this series of articles:
Let's take a very simple example, namely, updating some customer information through a web service.
')
And so, our basic requirements are:
This is a common data processing script. Here there is a specific request that runs the script, after which the data from the request "flow" through the system, being processed at each step. I use this script as an example because it is distributed in corporate software.
Here is a diagram of the process components:

But this description is only a successful version of events. Reality is never so simple! What happens if the user ID is not found in the database, or the mailing address is incorrect, or is there an error in the database?
Let's change the diagram and mark everything that could go wrong.
As you can see, at each step of the script errors may occur for various reasons. One of the goals of the series of these articles is to explain how to manage errors elegantly.
Now that we have understood the stages of our scenario, how to implement it with the help of the functional approach?
First we turn to the differences between the original scenario and functional thinking.
In a script, we usually mean a request-response model. The request is sent, the answer comes back. If something went wrong, then the flow of actions is completed and the answer comes "ahead of time" (note of the translator: It is solely about the process, not about the time spent.).
What I mean, you can see in the diagram of a simplified version of the script.
But in the functional model, the function is a black box with input and output, like this:

How can we adapt our script to such a model?
First, you need to realize that the functional data flow is only forward. You cannot return "ahead of time".
In our case, this means that all errors must be transmitted before the end of the script along an alternative path.
As soon as we do this, we will have the opportunity to turn the entire stream into a single function — the black box:

Of course, if you look inside this large function, you will find that it is made from (“is composition” in terms of functional methodology) smaller functions, one for each stage of the scenario, connected in series.

The last diagram shows one successful exit and three exits for errors. This is a problem, since functions can only have one output, not four!
What can we do about it?
The answer is to use the Merge type, where each option represents one of the possible exits. Then the function will actually have only one way out.
Here is an example of a possible type definition for outputting a result:
And here is a reworked chart showing a single exit with four different options included in it:

This solves the problem, but the presence of an error for each step is a fragile and poorly reusable design. Can we do better?
Yes! We really only need two methods. One for a successful case and another for all erroneous:

This type is very versatile and will work with any process! Actually, you will soon see that to work with this type we can make a good library of useful functions, which is suitable for any scripts.
One more thing - as a result, which the function returns, there is no data at all, only the status of success / failure. We need to correct something so that the result of the function contains the actual successful or failed object. We will declare successful and failed types as generic (using type parameters).
Finally, our final, universal version:
In fact, in the F # library there is already a similar type. It is called Choice . For clarity, I will continue to use the Result type created earlier in this and subsequent articles. We will return to this issue when we come to more serious problems.
Now, once again looking at the scenario with separate steps, we will see that we must combine the errors of each step into a single “failed” path.

How to do this is the topic of the next article.
So, we have the following provisions to the instructions:
Methodical instructions
“It seems to me that I understand functional programming at a basic level, and I even wrote simple programs, but how can I create a full-fledged application, with real data, error handling, and so on?”
This is a very common question, so I decided that in this series of articles I will describe the instruction covering design, validation, error handling, persistence, dependency management, code organization, and so on.
First, a few comments and cautions:
- I will describe only one script, and not the entire application. I hope it will be obvious how to extend the code if necessary.
- This is intentionally a very simple instruction without special tricks and advanced technology, focused on in-line data processing. But if you are a beginner, I think it will be useful for you to have a sequence of simple steps that you can repeat and get the expected result. I do not claim that this is the only sure way. Different scenarios will require different approaches, and of course with the growth of your own expertise you may find that this instruction is too simple and limited.
- To facilitate the transition from object-oriented design, I will try to use familiar concepts such as “templates”, “services”, “dependency injection”, etc., as well as explain how they relate to the functional approach.
- The instruction is also intentionally made to some extent imperative, i.e. an explicit step-by-step process is used. I hope this approach will ease the transition from OOP to FP.
- For simplicity (and the ability to use F # script), I will install a stub on the entire infrastructure and shy away from interacting with the UI directly.
Overview
An overview of what I plan to describe in this series of articles:
- Script conversion to function. In the first article, we will look at a simple script and see how it can be implemented using a functional approach.
- Combining small functions. In the next article, we will discuss a simple metaphor about combining small functions into larger ones.
- Designing using types and error types. In the third article, we will create the types necessary for the script and discuss special types for error handling.
- Configure and manage dependencies. In this article we will talk about how to link all the functions.
- Validation. In this article, we will discuss various ways to implement checks and transform from a dangerous outside world into a warm, fluffy world of type safety.
- Infrastructure. In this article, we will discuss the various components of the infrastructure, such as logging, working with external code, etc.
- Item Level In this article, we will discuss how subject-oriented design works in a functional world.
- Presentation level In this article we will discuss how to display the results and errors in the UI.
- Work with changing requirements. In this article we will discuss what to do with changing requirements and how they affect the code.
Let's get started
Let's take a very simple example, namely, updating some customer information through a web service.
')
And so, our basic requirements are:
- The user sends some data (user ID, name and mailbox address).
- We check the correctness of the name and address of the box.
- The name and address of the mailbox is updated in the database in the corresponding user record.
- If the mailbox address is changed, send a verification letter to this address.
- We display the result of the operation to the user.
This is a common data processing script. Here there is a specific request that runs the script, after which the data from the request "flow" through the system, being processed at each step. I use this script as an example because it is distributed in corporate software.
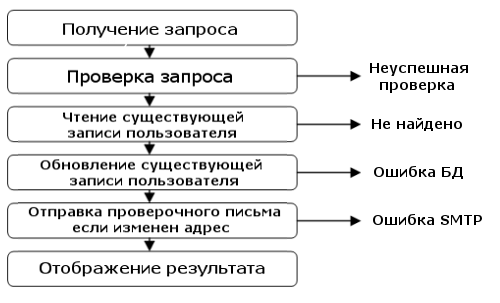
Here is a diagram of the process components:
But this description is only a successful version of events. Reality is never so simple! What happens if the user ID is not found in the database, or the mailing address is incorrect, or is there an error in the database?
Let's change the diagram and mark everything that could go wrong.
As you can see, at each step of the script errors may occur for various reasons. One of the goals of the series of these articles is to explain how to manage errors elegantly.
Functional thinking
Now that we have understood the stages of our scenario, how to implement it with the help of the functional approach?
First we turn to the differences between the original scenario and functional thinking.
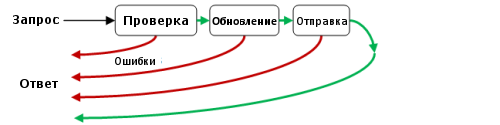
In a script, we usually mean a request-response model. The request is sent, the answer comes back. If something went wrong, then the flow of actions is completed and the answer comes "ahead of time" (note of the translator: It is solely about the process, not about the time spent.).
What I mean, you can see in the diagram of a simplified version of the script.
But in the functional model, the function is a black box with input and output, like this:
How can we adapt our script to such a model?
Unidirectional flow
First, you need to realize that the functional data flow is only forward. You cannot return "ahead of time".
In our case, this means that all errors must be transmitted before the end of the script along an alternative path.
As soon as we do this, we will have the opportunity to turn the entire stream into a single function — the black box:
Of course, if you look inside this large function, you will find that it is made from (“is composition” in terms of functional methodology) smaller functions, one for each stage of the scenario, connected in series.
Error management
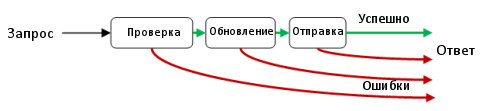
The last diagram shows one successful exit and three exits for errors. This is a problem, since functions can only have one output, not four!
What can we do about it?
The answer is to use the Merge type, where each option represents one of the possible exits. Then the function will actually have only one way out.
Here is an example of a possible type definition for outputting a result:
type UseCaseResult = | Success | ValidationError | UpdateError | SmtpError And here is a reworked chart showing a single exit with four different options included in it:
Simplify Error Management
This solves the problem, but the presence of an error for each step is a fragile and poorly reusable design. Can we do better?
Yes! We really only need two methods. One for a successful case and another for all erroneous:
type UseCaseResult = | Success | Failure This type is very versatile and will work with any process! Actually, you will soon see that to work with this type we can make a good library of useful functions, which is suitable for any scripts.
One more thing - as a result, which the function returns, there is no data at all, only the status of success / failure. We need to correct something so that the result of the function contains the actual successful or failed object. We will declare successful and failed types as generic (using type parameters).
Finally, our final, universal version:
type Result<'TSuccess,'TFailure> = | Success of 'TSuccess | Failure of 'TFailure In fact, in the F # library there is already a similar type. It is called Choice . For clarity, I will continue to use the Result type created earlier in this and subsequent articles. We will return to this issue when we come to more serious problems.
Now, once again looking at the scenario with separate steps, we will see that we must combine the errors of each step into a single “failed” path.
How to do this is the topic of the next article.
Summary and guidelines
So, we have the following provisions to the instructions:
Methodical instructions
- Each script is equivalent to an elementary function.
- The return type of the scenario function is a combination with two options: Success and Failure.
- A scenario function is built from a series of small functions that represent individual steps in a data stream.
- Errors of all stages are combined into a single path of errors.
Source: https://habr.com/ru/post/263035/
All Articles