How to make the browser cache not as useless as usual
I want to tell you about how we in Yandex Browser tried to make the cache not so useless for users as usual. In the recently published new beta of Yandex Browser for Android (we are planning for other OS), you can get access to recently visited sites even if you are not connected to the Internet. And it should work much more reliably and more conveniently, than everything that you saw before.
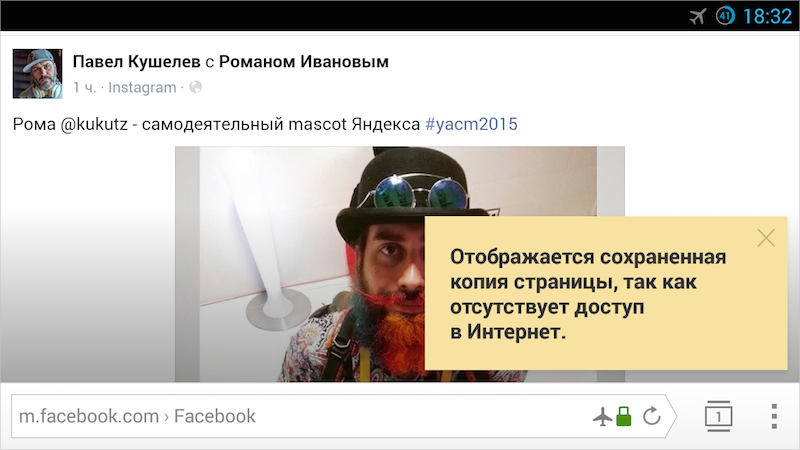
To make this possible, we came up with our own cluster caching, the algorithm of which monitors how to keep the pages as completely as possible. Details about the device all - under the cut.
Permanent and uninterrupted access to the Internet anywhere in the world or at least the city is still a dream. Therefore, in reality, we somehow encounter offline and the troubles it generates. For example, you will not be able to continue reading a previously open post in the browser if you refresh the tab in the absence of WiFi / 3G / LTE. Or she decides to upgrade herself, because she was unloaded from the RAM. Or you decide to return to the previous page using the "Back" button. Situations are different, but each of them will end in error, because the browser will not be able to download material from the network. Stop! But after all, it has already been downloaded to your device. Everything you are looking for is already in the browser cache. So why not use it? Sounds simple enough, doesn't it?
')
That is what our team has taken to implement in Yandex. Browser. We set ourselves the task of achieving predictable and high-quality work offline using the browser cache.
Normal caching
If you look at the experience of desktop browsers, you can recall the offline mode in Internet Explorer or Firefox, which was the browser trying to load the requested page from a saved copy or cache. Ten or even twenty years ago, this was especially true because of the widespread use of dialup and payment for the time spent on the network. It was cheaper to download all the necessary sites first, go offline and continue reading them there absolutely free. Over time, the need for such solutions began to fall, and work on caching in various products, if not stopped, then certainly did not continue in the direction of offline.
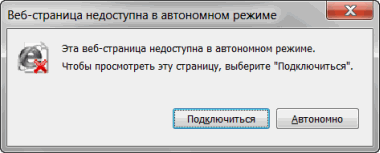
On the contrary, modern mobile browsers have faced the problem of offline to the full. No, now you don’t need to pay for the time spent on the Internet, but the network users themselves are mobile and can leave the coverage area at any time. We did not notice any radical solutions to this problem in popular products. At the same time, in mobile assemblies of Chromium for Android (recall, Yandex. The browser uses it at its core), the caching process is a very simplified version from the desktop. No complicated logic. All cached resources live in the same queue and are deleted in accordance with the LRU algorithm (those elements that have not been used the longest) are deleted. The cache itself is a “dump” of individual resources (html, css, png, js, ...) with a capacity of about 300 MB. From the point of view of the caching algorithm, these resources are in no way interconnected and are removed independently of each other when there is a shortage of memory for new pages.

Such simplified logic became a problem for us, because it did not allow us to achieve a predictable result when working offline. Simply put, the browser does not know what it has in the cache and how much is enough for a full page display. We could use the mechanism implemented in the framework of the experiment chrome: // flags / # show-saved-copy. If you do not know what it is about, then here is a brief summary. If there is no network, the user is prompted to try to download the site from the cache. This is exactly what we need, you would think!

Unfortunately, if you enable this experiment, the browser checks the availability of a local copy of only the main HTML document without taking into account all other resources and scripts. For simple text pages, this is usually enough. But for everything else, the result is sometimes too sad. And soon we learned that for many popular sites the experiment will not work even if there is a cache, but more on that below, but for now we had to learn how to predict the result.
Projected caching
We wanted to achieve better and unobtrusive work offline. That the user could get access to the information already loaded on his device without unnecessary buttons. And the browser should warn him if some resources have already been removed from the cache. For this, Yandex. The browser had to know whether all the resources that are present on the requested page are still available in the cache.
Theoretically, we could check the availability of an HTML document in the cache, and then go over all dependencies from it and evaluate the availability of each resource. Unfortunately, such a simple method of assessing "in the forehead" can not boast of speed. Yes, and on the consumption of resources, this affects especially strongly. So much so that in cold winter evenings your smartphone could warm you up. That's just outside the summer.
Such unsuccessful ideas gradually led us to the idea that the result could not be achieved without structural changes in the cache. Therefore, we came from the other side. We taught the browser to memorize the dependencies between the page and its resources at the stage of loading the site All the resources that are needed to display a specific page are now logically combined by the browser into a data set. We called this set a “cluster”. Moreover, if the resource is present on two different pages (for example, the site logo is usually duplicated), then it will be associated with two different clusters. In this case, the browser can clear the cache only at the expense of those resources that belong to the unused cluster itself (the same LRU, but at the cluster level, and not individual resources).
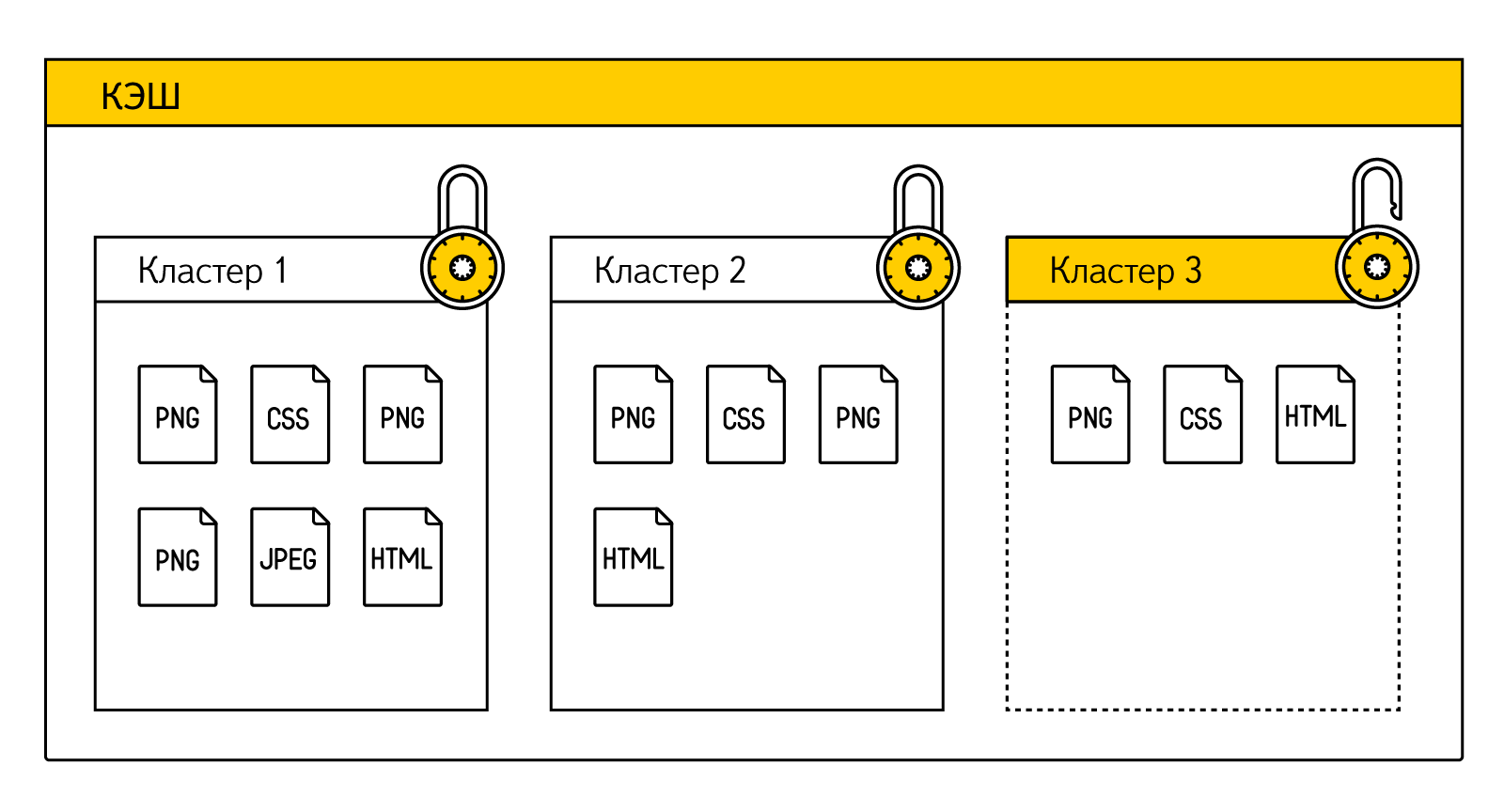
At that moment, when a user requests a page, Yandex.Browser already knows which cluster corresponds to the requested address, and what resources are needed for it. And then it just checks the availability of each item from the cluster. If the cluster (i.e., virtually all the resources of the desired page) is fully accessible, then you can not frighten the user with an error, but immediately show the site, warning that it is working offline. If some resources have already been deleted, then in the current build we also restore the page, but we warn you that the copy has been partially saved.

By the way, in the screenshot one of the five experimental designs for the tablet, which are also being tested in the current beta.
Quality caching
When we talk about working offline, we mean not only the banal restoration of the tab when the browser starts. In our case, the cache is used for any way to open pages. You can click “Refresh” or navigate through the history through “Forward” / “Back”. You can tap on the link. You can enter the address manually. In all these situations, Yandex. The browser will evaluate the availability of resources and load a local page, if possible.
We have previously suspected that not every site can be recovered from the cache. But only after they learned how to predict the result, it became clear that you can forget about the full-fledged and high-quality work offline. Many sites will never open offline. For example, Yandex, Habrahabr, Facebook or VKontakte (if you are authorized to them).

The reason lies in the HTTP cache-control: no-cache, no-store header, which prevents the browser from storing resources in the cache. We understand that webmasters use it to ensure that regularly updated resources are not taken from the cache, but are always loaded with the latest version. Unfortunately, it is common practice to add this header not for individual resources, but for the entire HTML document, which puts an end to the opening of the site offline.
We were definitely not going to refuse offline. But simply ignoring the specified HTTP headers could not be solved. This could lead to the use of irrelevant cached resources online. We needed to observe the meaning of the HTTP header, but at the same time provide access to information without connecting to the network. Fortunately, our developers managed to find such a compromise solution. According to this solution, Yandex. Browser stores all resources in the cache, including those for which a ban has been registered via “cache-control”. But at the same time, we also keep information about the existence of a ban and do not use such resources during normal online work. The browser accesses them only offline. Moreover, we are now exploring the ability to encrypt this part of the cache.
By the way, the results of POST requests or the execution of AJAX are also stored in the cache. Without this, many dynamic sites would look offline offline.
Cluster Caching Perspectives
We return to our clusters. In normal caching, all stored resources are unrelated and are deleted according to LRU. It does not take into account whether the tab with the page is still somewhere in the background, or the user has closed it for a long time. To better understand the problem, take a look at a simple example. You open a post on Habré in a browser on your smartphone and leave it open to read on board the aircraft. But until the landing begins, you may need to look at the weather forecast, check for new posts on the social network, or work with the web version of mail. Yes, the tab with the post on Habré is still open in the background. But its resources had already moved to the end of the queue and were removed from the cache. And the tab itself has already been thrown out of RAM. And here you fly 10 thousand meters above the ground, take out your phone and click on the desired tab, anticipating an exciting reading. But the browser gives an error, because the merciless LRU does not care about open tabs and your problems.
Fortunately, we have already invented clusters that can solve this problem. The introduction of clusters allowed us to combine resources into logical groups, each of which is clearly associated with a particular page. To solve the problem described above, it is enough to forbid the browser to delete the resources of those clusters that correspond to the open tabs. And you can go even further and provide for the ability to manually save the page. It is on these ideas that we continue to work now.
Unfortunately, even cluster caching at the moment cannot guarantee access to the page offline. If you suddenly load a heavy site, then its resources can very quickly remove all the rest from the cache. But in most cases, our technology avoids awkward moments and gives the user access to the downloaded information. And no matter how hard we try, websites offline do not always work exactly the same way as online, so we are sure to inform the user about the absence of a network with a special icon.
You can try offline mode in the beta version of Yandex. Browser 15.6 for Android . Already in this build, the browser can open pages offline, if the necessary resources are available in the cache. We invite everyone to help us with the search for problems and new ideas.
PS The iOS version was almost ready, but recently we started the migration to the new WKWebView component, which, unfortunately, lost many features compared to the outdated UIWebView. And there is still no new caching for several reasons. But that's another story.
PPS By the way, if you want to help our mobile team with the invention of other interesting technologies, then vacancies are waiting . We are looking for developers (C, C ++, Java), designers, project managers, product specialists and testers to Yandex offices in Moscow, St. Petersburg and Novosibirsk.
To make this possible, we came up with our own cluster caching, the algorithm of which monitors how to keep the pages as completely as possible. Details about the device all - under the cut.
Permanent and uninterrupted access to the Internet anywhere in the world or at least the city is still a dream. Therefore, in reality, we somehow encounter offline and the troubles it generates. For example, you will not be able to continue reading a previously open post in the browser if you refresh the tab in the absence of WiFi / 3G / LTE. Or she decides to upgrade herself, because she was unloaded from the RAM. Or you decide to return to the previous page using the "Back" button. Situations are different, but each of them will end in error, because the browser will not be able to download material from the network. Stop! But after all, it has already been downloaded to your device. Everything you are looking for is already in the browser cache. So why not use it? Sounds simple enough, doesn't it?
')
That is what our team has taken to implement in Yandex. Browser. We set ourselves the task of achieving predictable and high-quality work offline using the browser cache.
Normal caching
If you look at the experience of desktop browsers, you can recall the offline mode in Internet Explorer or Firefox, which was the browser trying to load the requested page from a saved copy or cache. Ten or even twenty years ago, this was especially true because of the widespread use of dialup and payment for the time spent on the network. It was cheaper to download all the necessary sites first, go offline and continue reading them there absolutely free. Over time, the need for such solutions began to fall, and work on caching in various products, if not stopped, then certainly did not continue in the direction of offline.
On the contrary, modern mobile browsers have faced the problem of offline to the full. No, now you don’t need to pay for the time spent on the Internet, but the network users themselves are mobile and can leave the coverage area at any time. We did not notice any radical solutions to this problem in popular products. At the same time, in mobile assemblies of Chromium for Android (recall, Yandex. The browser uses it at its core), the caching process is a very simplified version from the desktop. No complicated logic. All cached resources live in the same queue and are deleted in accordance with the LRU algorithm (those elements that have not been used the longest) are deleted. The cache itself is a “dump” of individual resources (html, css, png, js, ...) with a capacity of about 300 MB. From the point of view of the caching algorithm, these resources are in no way interconnected and are removed independently of each other when there is a shortage of memory for new pages.
Such simplified logic became a problem for us, because it did not allow us to achieve a predictable result when working offline. Simply put, the browser does not know what it has in the cache and how much is enough for a full page display. We could use the mechanism implemented in the framework of the experiment chrome: // flags / # show-saved-copy. If you do not know what it is about, then here is a brief summary. If there is no network, the user is prompted to try to download the site from the cache. This is exactly what we need, you would think!
Unfortunately, if you enable this experiment, the browser checks the availability of a local copy of only the main HTML document without taking into account all other resources and scripts. For simple text pages, this is usually enough. But for everything else, the result is sometimes too sad. And soon we learned that for many popular sites the experiment will not work even if there is a cache, but more on that below, but for now we had to learn how to predict the result.
Projected caching
We wanted to achieve better and unobtrusive work offline. That the user could get access to the information already loaded on his device without unnecessary buttons. And the browser should warn him if some resources have already been removed from the cache. For this, Yandex. The browser had to know whether all the resources that are present on the requested page are still available in the cache.
Theoretically, we could check the availability of an HTML document in the cache, and then go over all dependencies from it and evaluate the availability of each resource. Unfortunately, such a simple method of assessing "in the forehead" can not boast of speed. Yes, and on the consumption of resources, this affects especially strongly. So much so that in cold winter evenings your smartphone could warm you up. That's just outside the summer.
Such unsuccessful ideas gradually led us to the idea that the result could not be achieved without structural changes in the cache. Therefore, we came from the other side. We taught the browser to memorize the dependencies between the page and its resources at the stage of loading the site All the resources that are needed to display a specific page are now logically combined by the browser into a data set. We called this set a “cluster”. Moreover, if the resource is present on two different pages (for example, the site logo is usually duplicated), then it will be associated with two different clusters. In this case, the browser can clear the cache only at the expense of those resources that belong to the unused cluster itself (the same LRU, but at the cluster level, and not individual resources).
At that moment, when a user requests a page, Yandex.Browser already knows which cluster corresponds to the requested address, and what resources are needed for it. And then it just checks the availability of each item from the cluster. If the cluster (i.e., virtually all the resources of the desired page) is fully accessible, then you can not frighten the user with an error, but immediately show the site, warning that it is working offline. If some resources have already been deleted, then in the current build we also restore the page, but we warn you that the copy has been partially saved.
By the way, in the screenshot one of the five experimental designs for the tablet, which are also being tested in the current beta.
Quality caching
When we talk about working offline, we mean not only the banal restoration of the tab when the browser starts. In our case, the cache is used for any way to open pages. You can click “Refresh” or navigate through the history through “Forward” / “Back”. You can tap on the link. You can enter the address manually. In all these situations, Yandex. The browser will evaluate the availability of resources and load a local page, if possible.
We have previously suspected that not every site can be recovered from the cache. But only after they learned how to predict the result, it became clear that you can forget about the full-fledged and high-quality work offline. Many sites will never open offline. For example, Yandex, Habrahabr, Facebook or VKontakte (if you are authorized to them).
The reason lies in the HTTP cache-control: no-cache, no-store header, which prevents the browser from storing resources in the cache. We understand that webmasters use it to ensure that regularly updated resources are not taken from the cache, but are always loaded with the latest version. Unfortunately, it is common practice to add this header not for individual resources, but for the entire HTML document, which puts an end to the opening of the site offline.
We were definitely not going to refuse offline. But simply ignoring the specified HTTP headers could not be solved. This could lead to the use of irrelevant cached resources online. We needed to observe the meaning of the HTTP header, but at the same time provide access to information without connecting to the network. Fortunately, our developers managed to find such a compromise solution. According to this solution, Yandex. Browser stores all resources in the cache, including those for which a ban has been registered via “cache-control”. But at the same time, we also keep information about the existence of a ban and do not use such resources during normal online work. The browser accesses them only offline. Moreover, we are now exploring the ability to encrypt this part of the cache.
By the way, the results of POST requests or the execution of AJAX are also stored in the cache. Without this, many dynamic sites would look offline offline.
Cluster Caching Perspectives
We return to our clusters. In normal caching, all stored resources are unrelated and are deleted according to LRU. It does not take into account whether the tab with the page is still somewhere in the background, or the user has closed it for a long time. To better understand the problem, take a look at a simple example. You open a post on Habré in a browser on your smartphone and leave it open to read on board the aircraft. But until the landing begins, you may need to look at the weather forecast, check for new posts on the social network, or work with the web version of mail. Yes, the tab with the post on Habré is still open in the background. But its resources had already moved to the end of the queue and were removed from the cache. And the tab itself has already been thrown out of RAM. And here you fly 10 thousand meters above the ground, take out your phone and click on the desired tab, anticipating an exciting reading. But the browser gives an error, because the merciless LRU does not care about open tabs and your problems.
Fortunately, we have already invented clusters that can solve this problem. The introduction of clusters allowed us to combine resources into logical groups, each of which is clearly associated with a particular page. To solve the problem described above, it is enough to forbid the browser to delete the resources of those clusters that correspond to the open tabs. And you can go even further and provide for the ability to manually save the page. It is on these ideas that we continue to work now.
Unfortunately, even cluster caching at the moment cannot guarantee access to the page offline. If you suddenly load a heavy site, then its resources can very quickly remove all the rest from the cache. But in most cases, our technology avoids awkward moments and gives the user access to the downloaded information. And no matter how hard we try, websites offline do not always work exactly the same way as online, so we are sure to inform the user about the absence of a network with a special icon.
You can try offline mode in the beta version of Yandex. Browser 15.6 for Android . Already in this build, the browser can open pages offline, if the necessary resources are available in the cache. We invite everyone to help us with the search for problems and new ideas.
PS The iOS version was almost ready, but recently we started the migration to the new WKWebView component, which, unfortunately, lost many features compared to the outdated UIWebView. And there is still no new caching for several reasons. But that's another story.
PPS By the way, if you want to help our mobile team with the invention of other interesting technologies, then vacancies are waiting . We are looking for developers (C, C ++, Java), designers, project managers, product specialists and testers to Yandex offices in Moscow, St. Petersburg and Novosibirsk.
Source: https://habr.com/ru/post/263031/
All Articles