"Y" you do not "and" short! The Importance of Unicode Normalization

Over the past six months, the Internet has simply flooded the "letter" "y." I met her on news sites, in instant messengers, on habrahabr and geektimes. "What is it all about?" - you ask - "I see the usual letter d!". What a score. I see her like this:
 |
 |
 |
 |
 |
How is that?
Graphemes, glyphs, code points, layout and bytes
Very brief introduction:Grapheme is what we used to call a letter in the sense of a unit of text. A glyph is a unit of graphics, and can graphically represent the grapheme itself or a part of it (for example, various diacritical marks: stress, umlauts, a superscript colon for the letter e, etc.).
Code Point - how the text is written in the Unicode view. One grapheme can be recorded with different code points.
Code Points are encoded by different byte representation depending on the standard: UTF-8, UTF-16, UTF-32, BE, LE ...
Programming languages, as a rule, work with code points; for us humans, it is habitual to think in glyphs.
')
Let's finally deal with our letter nd. What is so special about her?
This letter is one grapheme (“and” short), but it is recorded by two code points:
U+000438 CYRILLIC SMALL LETTER I U+000306 COMBINING BREVE If you did the trick with pressing the backspace, you just erased COMBINING BREVE, or, speaking in print, the short icon over the vowel.
The usual letter “and” short, which we are all used to typing with the keyboard, is a composite character, which is recorded by one code point:
U+000439 CYRILLIC SMALL LETTER SHORT I The display of accents depends on the font and renderer. For example, in the editing window of this post, the symbol looks right, but when viewing it goes. Some fonts may display accented characters separately, even in composite characters.
What is bad?
Not all programs, but sites even more so, are able to lead code points to a form that allows you to compare identical glyphs recorded with different code points. In other words, not every program and site recognizes “» ”and“ ”for one character, which makes it impossible, for example, to search for such letters.There is no need to go far for an example: a relatively recent article with a review of the mouse on geektimes , a screenshot of which is given above in the article. Let's do a Google search for the following phrase, which, like, is in the article:
«» 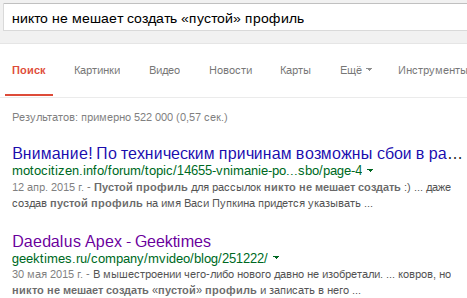
The post is issued the second result, and, as can be seen from the bold part, we have a full text match. Great, open it and try to find the same text on the page and see that Firefox did not find anything:

Search in Geektimes also does not produce a suitable result:
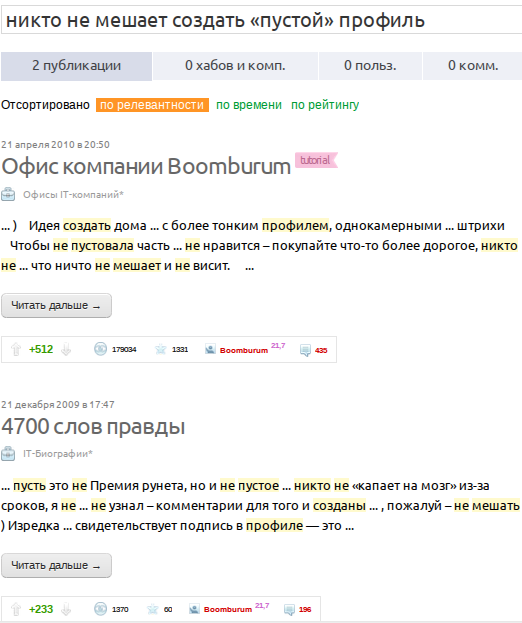
But it is worth replacing the composite “d” with its decomposition counterpart “d”, as everything falls into place:
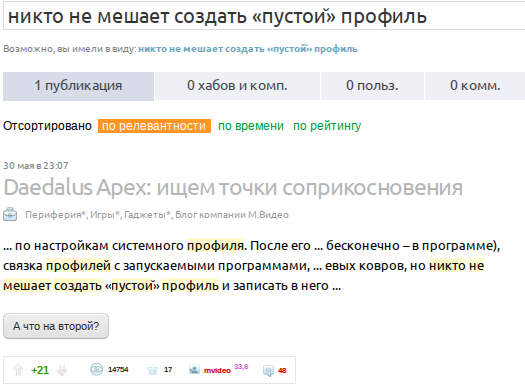
Obviously, Google somehow translates the search query, allowing you to search by glyphs, not by their code points.
How it works?
Normalization
The Unicode Normalization Standard describes two symbol equivalents: Canonical and Compatibility. The first just allows you to compare the same glyphs with different code points, and the second allows you to compare them with simplified counterparts - ½ with 1/2, c H, etc.There are also 4 types of normalization:
- Normalization Form D (NFD) - canonical decomposition. Spread cześć (hello in Polish) to c, z, e, c + ´, s + ´.
- Normalization Form C (NFC) - collects what the previous version has laid out.
- Normalization Form KD (NFKD) - compatibility decomposition. Make 1/2 of ½, 25 of 2⁵.
- Normalization Form KC (NFKC) - will try to collect what the previous one has laid out.
If we talk about a site like habrakhabra, then it makes sense to NFC-normalize all posts before they are published, and subject the search query to NFKD processing.
In Python, for example, this can be done with the unicodedata module.
Hidden text
import sys
import unicodedata
print (unicodedata.normalize ('NFKD', sys.argv [1]))
% python unicode.py cześć | hexdump -C
00000000 63 7a 65 73 cc 81 63 cc 81 0a | czes..c ... |
% echo 'cześć' | hexdump -C
00000000 63 7a 65 c5 9b c4 87 0a | cze ..... |
import unicodedata
print (unicodedata.normalize ('NFKD', sys.argv [1]))
% python unicode.py cześć | hexdump -C
00000000 63 7a 65 73 cc 81 63 cc 81 0a | czes..c ... |
% echo 'cześć' | hexdump -C
00000000 63 7a 65 c5 9b c4 87 0a | cze ..... |
Conclusion
I can not say with complete certainty who is to blame for the appearance of the "th" in runet, but the suspicion falls on Google Docs. Fortunately, it seems that the bug was repaired, because 3 weeks I have not had to look at the crawl briefly.Problems with glyphs also happen offline. Here is a picture of a real passport with a letter, probably “” (CYRILLIC SMALL LETTER IE + COMBINING DIAERESIS)

Source: https://habr.com/ru/post/262679/
All Articles