We collect people base from open data WhatsApp and VK
scene from the movie Mission Impossible II
This story began a couple of months ago, on the first birthday of my son. An SMS was sent to my phone with congratulations and wishes from an unknown number. I think if it was my birthday I would have had the audacity to send back, not quite cultural, in my opinion, “Thank you, and who are you?”. However, my birthday is not mine, but it was interesting to find out who sends the congratulations.
First success
It was decided to try the following option:
- Add an unknown number to the phone’s address book;
- Go one by one to the applications associated with the number (Viber, WhatsApp);
- Open a new chat with the newly created contact and identify the sender from the photo.
I was lucky and in my case, a miniature of a photo appeared on the Viber contact list next to the newly created contact, by which I, without opening it completely, recognized the sender and satisfied with the “investigation” I wrote sms with gratitude for the congratulations.
')
Immediately after the second interval of euphoria from a successful search in my head, the idea appeared to search the base of the list of mobile phone numbers [phone_number => photo]. In another second, the idea is to skip these photos through the face recognition system and link it with other open data, such as photos from social networks.
Naturally, at point 3 (from the photo to determine the sender), we can overtake failure and this failure has 6 options:
- Number is not attached to whatsapp or viber
- The user is, but he did not install himself
- The photo is set, but the “privacy” or “privacy” settings are configured (“Show photos only to my contacts”, but you are not on this list)
- You have a photo available, but it shows a cat
- In the photo is a man, but the features and / or body features cannot be disassembled (lack of sharpness, low resolution, dark glasses, hats, caps, make-up)
- In the photo the owner of the room; full face; high definition but remember this person you can't
The fourth item (in the photo cat) has many options: this and photos of celebrities, and cartoon characters, and photos of food, cars, weapons, etc.
Tests on small orders.
As a sample of the pen, it was decided to experiment on his contact list. On Android phones, Viber stores photos of contacts in the / sdcard / viber / media / User photos folder as [Hash] .jpg . Files are saved only if you have communicated with this contact or at least opened its profile and deleted after some time. For the experiment, manually open / close the profiles of 20 users.
Some of the acquaintances for whom files were found were also found on social networks are uploaded to Picasa with the option “Face Recognition Automatically” enabled. The persons recognized by the program were then named according to their owners. In the next step we feed Picas'e folder with photos from Viber. For similar persons, icons with a question mark appear in the “Users” window.
In my case, for the original 20 Viber users, Picasa found only two matches. At the same time, these two cases quite comically coincided: in each pair the photographs differed from each other, but were taken on the same day (for the first person, the two photos differed in head and presence / absence of a smile, for the second only a smile differed)
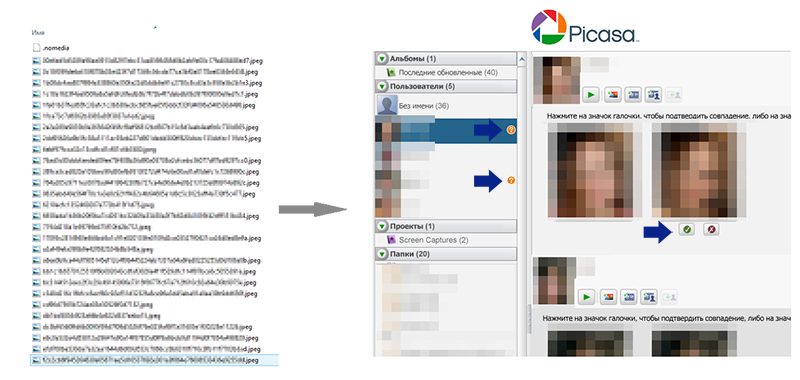
The intermediate result is quite successful:
Sample from Viber: 20 (all in a row with cats and food)
Sample from VK: 5 (only if you can visually recognize someone in the photo)
Matches true: 2
False Matches: 0
Getting bust
Let's try to get data using the phone. Viber takes contacts from the phone book, which in turn in the Android OS is associated with Google Contacts, which have a limit of 25,000 numbers per account. At the moment, the number of mobile operators assigned to Moscow is 93 311 000. So the idea of getting a base with such a “head-on solution” is no longer relevant. Moreover, even if Viber takes at least the first pack of 25,000 numbers, you still need to go into each profile, and then also associate the resulting file [Hash] .jpg with a specific number (which can probably be tracked by file creation date , but it is still very time consuming and long).
The solution was found quickly: the network has a software implementation of another popular service - WhatsApp. All calls go through php. There is a ready script for registering a new user and an example of a call to getProfilePicture . To start the process, you need a * nix server and you need to understand how much you can take in with the frequency and speed of requests. For the experiment, php code was written, which is authorized in Whatsapp and in an infinite loop it receives / does not receive for numbers + 7XXXXXXXXXX getProfilePicture and displays a timestamp on the screen. During the first and subsequent launches this code reached 220-250 numbers and left at timeout - we try to pause after every 200th sleep (5) - it does not help, timeout is still. We try to complete the process and immediately start again - success. Accordingly, we deal with either a restriction on the server (it is necessary to reauthorize after 200 requests), or an error in this php implementation. I did not experiment, but killed two birds with one stone, rewriting the php script so that it would process only 200 numbers and add a control script to Bash, which in the loop starts php with the $ startPhoneNumber parameter and waits for it to complete.
Thus, we got a working search circuit with a speed of 5.7 numbers per second.
To handle the entire Moscow capacity, we need:
93,311,000 (numbers) / 5.7 (numbers per second) / 60 (seconds) / 60 (minutes) / 24 (hours) ~ 190 days .
Multithreading
Authorization in WhatsApp goes through a bunch
username - phone numbers in the format + 7XXXXXXXXXXX
password - received through the registration script (for registration, you need a working sim card to get a confirmation code)
nickname - can be any
WhatsApp prohibits> 1 authorization for one username at one time. In this connection, the official store purchased three SIM-cards of the operator Megaphone for 200 rubles each. each From the same server on Centos OS, all three numbers were registered in WhatsApp and all three were launched using a script with a piece of Beeline Business capacity. The ratio of the number of rooms to the stored photos kept around 10 to the 1st; then the difference increased due to “hundreds” and “thousands”, which are apparently not yet distributed and do not give a single image for the whole range.
Lock
The license agreement WhatsApp (with which I agree when I go through registration) says:
Extract from the ENG agreement
If you are not a limiting system, including "robots," "spiders," "offline readers," etc. or "load testers" such as wget, apache bench, mswebstress, httpload, blitz, Xcode Automator, Android Monkey, etc., that is, If you are not allowed to use it. If you are not a victim of the materials, you must be able to find out what kind of materials you need. WhatsApp reserves for revoke these exceptions either generally or in specific cases. If you’re looking for something like a snooper, it’s not a problem. We have to disallow your request using the tools such as fiddler or whisker. You must be secured It is not a problem to use any information. For commercial purposes, or for users of the Service.
Extract from the agreement; approximate translation
"You agree not to use or not to run automated systems that send more requests to the WhatsApp service than a person is capable of ..."
All my SIM cards were blocked on the third day without explanation. The logs show that the disconnection occurred at 00:22 Moscow time on all the cards at the same time (about 500,000 numbers each managed to process the cards). What is interesting is that the WhatsApp server first began to respond to requests for a very long time, and then stopped authorizing altogether. At the attempt to register the number anew, the server responds with " Failed; Reason: Blocked; ". When I try to register WhatsApp in a human way, a message pops up from the phone: “Sorry, you can no longer use the WhatsApp service.”
Besides the fact that all three running scripts did the same at the same speed, they had much in common to block them simultaneously, namely: they all logged in with the same nickname "V" and worked from the same IP addresses.
Complicate the scheme

We believe that they have become slightly (namely, at 600 rubles spent on those three SIMs) smarter. At this time we buy 10 SIM cards in the "unofficial store" at the metro at 100 rubles. a piece. Complicate the script, create an array of sim cards and give each our own nickname according to the list of actors of a remarkable movie:
Array declaration
// username,"password","nickname" $SIMDict = array( <br> "SIM1" => array(7969XXXXXXX,"123123211231231231231231231=","Zooey"), "SIM2" => array(7916XXXXXXX,"123123211231231231231231231=","Martin"), "SIM3" => array(7985XXXXXXX,"123123211231231231231231231=","Sam"), "SIM4" => array(7916XXXXXXX,"123123211231231231231231231=","Bill"), "SIM5" => array(7985XXXXXXX,"123123211231231231231231231=","Mos"), "SIM6" => array(7985XXXXXXX,"123123123211231231231231231=","Warwick"), "SIM7" => array(7916XXXXXXX,"123123211231231231231231231=","Anna"), "SIM8" => array(7985XXXXXXX,"123123123123123123123123121=","John"), "SIM9" => array(7,"","Kelly"), "SIM10" => array(7,"","Jason") ); We force each SIM card to exit through a separate IP address.
Our Centos is a virtual server running under the Hyper-V hypervisor, which allows us to add 7 more Ethernet adapters to it (Hyper-v restriction: 8 Ethernet adapters + 4 legacy). It only remains to make the php processes go to the Internet each with a different ip address.
The system has a default subsystem ip namespaces (ip netns), which allows you to fully virtualize the network stack. This means that you can create so-called namespacs (ns), and within each individual ns there will be your own addresses, routes, rules, dns, etc. There are not so many articles on ip netns on the Internet, and those that have different readings on using physical interfaces - some people write that it is impossible to add a physical interface to the namespace that is different from default, some that can be, but only connected via a tap interface, some that can be done without tap.
I did not manage to create seven secondary ip (alias) and scatter them in different namespace, either directly or through tap interfaces. But the option to create 7 namespaces and to attach a separate physical interface to each, despite assurances from the Internet community, was possible without problems.
Legacy adapter did not work at all, so we’ll stop on 8 cards.
Now the Bash script takes as input startNumber, endNumber, SIM, NS, where SIM is the name of the sim card in the array, NS is the name of the namespace in which to start the php process. Call example:
The system has a default subsystem ip namespaces (ip netns), which allows you to fully virtualize the network stack. This means that you can create so-called namespacs (ns), and within each individual ns there will be your own addresses, routes, rules, dns, etc. There are not so many articles on ip netns on the Internet, and those that have different readings on using physical interfaces - some people write that it is impossible to add a physical interface to the namespace that is different from default, some that can be, but only connected via a tap interface, some that can be done without tap.
I did not manage to create seven secondary ip (alias) and scatter them in different namespace, either directly or through tap interfaces. But the option to create 7 namespaces and to attach a separate physical interface to each, despite assurances from the Internet community, was possible without problems.
Setup Commands
LINUX
CISCO
ip netns add net1 && ip link set netns net1 dev eth1 ip netns exec net1 ip addr add YYY71/24 dev eth1 ip netns exec net1 ip link set up dev eth1 ip netns exec net1 ip route add default via YYY1 ip netns add net2 && ip link set netns net2 dev eth2 ip netns exec net2 ip addr add YYY72/24 dev eth2 ip netns exec net2 ip link set up dev eth2 ip netns exec net2 ip route add default via YYY1 CISCO
ip nat inside source static YYY71 XXX71 ip nat inside source static YYY72 XXX72 Legacy adapter did not work at all, so we’ll stop on 8 cards.
Now the Bash script takes as input startNumber, endNumber, SIM, NS, where SIM is the name of the sim card in the array, NS is the name of the namespace in which to start the php process. Call example:
./run.sh 79671380000 79671780000 SIM1 net1 & Script itself run.sh
... start=$1 last=$2 net=$4 startParam="ip netns exec $net" ./pushme.sh "$3 $4" "$start begins" while [ $start -lt $last ] do $startParam php ./getProfiles.php instance=$start prefix=$start count=50 sim=$3 net=$4 #> $3.log start=$(( $start + 50 )) done ... We divide the capacity into pieces smaller than 2 000 numbers. We also add push notifications via Pushover to Bash and php ("7XXXXX start", "7XXXXX finish", "Houston we have a problem")
The last one is sent with non-standard WhatsApp server responses, or with very long (> 5 seconds) non-response.
Looking ahead, I want to say that WhatsApp is smarter than me and all these sim cards were also blocked after a while and also almost simultaneously. In any case, the 8,000,000 phone numbers of the scripts did work successfully, and we have 411,279 photos in our hands. Ratio of 20 to 1. Which is already quite good.

Sampling of the results of processing in Moscow
Nenets Autonomous Okrug
For a long time it was not possible to activate the remaining SIM cards and run scripts. Finally, a free minute appeared, and with it the strength to admit that starting the search from Moscow (population 12,197,596 people) is smart. Therefore, we hide our youthful maximalism more deeply and take a less populated subject, for example, the Nenets Autonomous District. Why not. We launch the script - and after 12 hours, the search of all tanks of the Nenetsky Okrug is completed. For 169,995 numbers, a total of 2,208 photos were found in WhatsApp. Go to the next step.
In contact with
Task: get all photos of VK users who have the city of interest.
A considerable amount of time was spent to deal with the VK API. And it turned out that the getuser request can be executed without problems without having an access-token. But the search request (to take only people from a particular city) will work only with the token, and received by the user, and not by the standalone application. This article will help us How do I get access token to interact with vk api . But even when we received this token - we stick to the restriction - you can only get 1000 users (not 1000 for one request, but 1000 in total), despite the fact that, for example, the city of Naryan-Mar (Nenets Autonomous Region) is listed at 15,660 people .
We try to go through get_users through brute force: we iterate over all users of VKontakte from $ id = 1 to N with the following query:
response=$(curl --silent "https:// api.vk.com /method/users.get?user_id=$id&fields=photo_max_orig,country,city") On the VKontakte network at the time of this writing, there were N = 300,000,000 users. One such request without downloading a photo took 1 second.
300,000,000 (users) / 1 (per second) / 60 (seconds) / 60 (minutes) / 24 (hours) ~ 3472 days.
Total about 3472 days in one stream, provided that VK will not block our IP addresses. Option discarded.
We return to users.search with a limit on the number of issue, but not on the "quality" of the request. I explain. In the request, you can infinitely specify the parameters: for example, take only women or men, reducing the issue by half, or take only those who have a photo, and what is most convenient is to take only people of a specific age, naturally in a cycle of $ age = 14 up to 80. A total of 66 runs of 1,000, with the observation that if for some ages we pass over 1000, we will repeat such requests with additional division by gender.
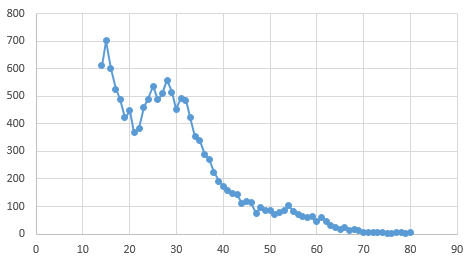
VK user distribution by city of Naryan-Mar by age
The script is a gradual download from VK
Actually, the script, using the previously obtained (from the same IP) access_token, requests through the VK API in a cycle a list of all people of a specific age from a particular city (city = 2487).
The most interesting thing here is line number 9:
It turns the JSON response from VKontakte ({"response": [COUNT, {"uid": XXXXXXX, "first_name": "Ivan", "last_name": "Ivanov", "photo_max_orig": "http: \ / \ / QQQ.vk.me \ / ZZZ \ /YYY.jpg »}) to list
id photo_url (XXXXX http: // QQQ.vk.me / zzz / yyy, etc.)
There are lots of ways to realize this and surely there is a nicer option. But in search of how to do this, I came across the so-called “jq is a lightweight and flexible command-line JSON processor”, the syntax of which I liked:
jq '.response | . [] | (.uid | tostring) + "" + .photo_max_orig '
If read from the end, then: take the text user id (.uid | tostring) with a link to the photo .photo_max_orig for all elements of the array. [] Within the scope of the response object
01: acc_token="abc123abc123abc123abc123abc123abc123abc123abc123" 02: vk_url="api.vk.com/method/users.search?has_photo=1&count=1000&city=2487&country=1&access_token=$acc_token&fields=photo_max_orig" 03: 04: for age in {14..80} 05: do 06: echo -n $id " " >>vk.log 07: date +"%T" >>vk.log 08: mkdir photos/$id 09: list=$(curl --silent "$vk_url&age_from=$age&age_to=$age" | jq '.response | .[] | (.uid|tostring) + " " + .photo_max_orig' | \ sed 's/^"\(.*\)"$/\1/') 10: counter=0 11: while read -r line; do 12: let counter++ 13: arr=($line) 14: echo -n "$counter." >>vk.log 15: photo=${arr[1]} 16: filename=${arr[0]}$(echo $photo | sed "s/.*\(\..*\).*$/\1/") 17: wget $photo -O photos/$id/$filename 18: done <<< "$list" 19:done Actually, the script, using the previously obtained (from the same IP) access_token, requests through the VK API in a cycle a list of all people of a specific age from a particular city (city = 2487).
The most interesting thing here is line number 9:
It turns the JSON response from VKontakte ({"response": [COUNT, {"uid": XXXXXXX, "first_name": "Ivan", "last_name": "Ivanov", "photo_max_orig": "http: \ / \ / QQQ.vk.me \ / ZZZ \ /YYY.jpg »}) to list
id photo_url (XXXXX http: // QQQ.vk.me / zzz / yyy, etc.)
There are lots of ways to realize this and surely there is a nicer option. But in search of how to do this, I came across the so-called “jq is a lightweight and flexible command-line JSON processor”, the syntax of which I liked:
jq '.response | . [] | (.uid | tostring) + "" + .photo_max_orig '
If read from the end, then: take the text user id (.uid | tostring) with a link to the photo .photo_max_orig for all elements of the array. [] Within the scope of the response object
At 19 years old VK was suspicious of something, and began to respond very slowly to requests. An hour and a half later 13,967 images were downloaded. For the remaining 1,700 people, the age was apparently not indicated at all. Another 400 downloaded images were, for some reason, broken, or very small (<10 kb).
Face Recognition and Comparison
Among the obtained images, as we have already found out, there are a lot of cats and cars, so first we want to filter them. OpenCV (Open Source Computer Vision Library, open source computer vision library) will help us with this.
There are many implementations in various programming languages based on this library. For example, facedetect, which determines the coordinates for which the person is in the photo. She, along with ImageMagick, will cut the recognized face into coordinates in a separate file.
On face recognition in the photo, there is an interesting implementation from the company Betaface. They have a paid API for a large number of images, but there is a great demo that recognizes all those present in the uploaded photo and among other things determines the gender, the presence of whiskers, glasses, smiles and (women will not like it) shows the estimated age (gives me 27, a plush rabbit on the fridge - 42).

We will take ready python scripts from the English developer Terence Eden. He wrote them in a very interesting project . His task was to download an open collection of paintings from the London Museum Tate Britain, and recognize images of people on it. Then with the help of the resulting database of people and your photo you can find a picture that depicts a person as close as possible to you. Unfortunately, the Web API does not give it, but all the sources are on github.
Correct Terens script - turn off the download from the British Gallery and delete the processing by folders.
Python script
import sys, os import cv2 import urllib from urlparse import urlparse def detect(path): img = cv2.imread(path) cascade = cv2.CascadeClassifier("haarcascade_frontalface_alt.xml") rects = cascade.detectMultiScale(img, 1.3, 4, cv2.cv.CV_HAAR_SCALE_IMAGE, (20,20)) if len(rects) == 0: return [], img rects[:, 2:] += rects[:, :2] return rects, img def box(rects, img, file_name): i = 0 # Track how many faces found for x1, y1, x2, y2 in rects: print "Found " + str(i) + " face!" # Tell us what's going on cut = img[y1:y2, x1:x2] # Defines the rectangle containing a face file_name = file_name.replace('.jpg','_') # Prepare the filename file_name = file_name + str(i) + '.jpg' file_name = file_name.replace('\n','') print 'Writing ' + file_name cv2.imwrite('detected/' + str(file_name), cut) # Write the file i += 1 # Increment the face counter def main(): for filename in os.listdir('whphotos'): print filename + " " rects, img = detect("whphotos/" + filename) box(rects, img, filename) os.remove("whphotos/" + filename) if __name__ == "__main__": main() Processing result:
13,500 images from VK => 6,427 / 5,446 faces. (including / excluding cases with several persons in one photo)
2,208 of WhatsApp => 963/876 individuals
An interesting pattern is peeped out - every second user does not put a photo on the profile.
Following recognition comes the creation of the model eigenfaces.xml . The script provides for a folder of source photos to form an XML file, which will be searched in the future. Therefore, we prepare such a file for one set, and then take one element from the second and look for a match. The technics decided for me which of the kits to take for the main one: the script could not process 6,400 photos from VK with the error " Couldn't allocate over 4GB " with an error in memory. The time is 11 nights - it's not a hunt to understand - we skip 963 photos from WhatsApp through a script and after 20 minutes we have eigenfaces.xml with a size of 1.6 GB. You can imagine what size it was in the case of VK. Later it turned out, reworking the script for myself, I accidentally deleted the identification string in the model, instead all elements had the identifier "0". It would be ridiculous to wait a few days to run the script and only then discover it. We correct the error and wait another 20 minutes.
Then for each file from VK we run the check script.
find detectedVK/ -name *.jpg -exec ./myscript.sh {} \; #myscript.sh python recognise.py detectedWH $1 100000 >> result `100000` here - the accuracy of the match, with 100 - a perfect match.
For one comparison, we have 40 seconds. 6,400 * 40 ~ 3 days on one processor. Leave overnight; we go to sleep tomorrow monday.
I must say that I had thoughts that for such a small sample of coincidences there would be zero. While the scripts were working, I periodically looked at coincidences. With the accuracy indicated by me, there were many results, but upon closer examination, even on coincidences of the order of `3500`, there were many boy-girl results. Moreover, the feeling was that these two were relatives. The result is interesting, but this is not exactly what we were looking for.
The first hit happened at the end of the first thousand accounts. Yana's girlfriend from the city of Naryan-Mar put the same photo in both WhatsApp and VK. Despite the fact that the photos are the same (only the resolution is different), the accuracy of the match is ~ 3,000. For all the results with an accuracy of <6000, using convert we combine the matched images to finally make a visual decision
... if [ "$precise" -lt 6000 ] then echo $precise $whIMG $vkIMG convert detectedWH.bak/$whIMG detectedVK.bak/$vkIMG -append convertResults/${precise}_$whIMG$vkIMG fi ... 
In total, by the end of the second day, 25 VK accounts were successfully recognized and tied to the phone number.
These are 2% of the number of faces found by WhatsApp, or 1% of all images.

Analysis results for Naryan-Mar
I believe that this is an excellent result, and this is why:
- We have small samples, with a big difference between them (16 600 VK vs. 2 000 WhatsApp);
- To search for matches, we used only the Eigenfaces algorithm, and you can add, for example, Fisherfaces;
- You can increase the chances of recognition by adding by analogy brute force through Viber;
- From VK you can take not only the last profile photo, but also several previous ones;
- Finally, Facebook, Odnoklassniki, etc. can be added to the list of social networks.
It is difficult to talk about specific numbers, but it can be said for sure that the percentage of successful hits will increase significantly if all points are observed. Processor power for this, of course, also need to be increased several times.
Conclusion
What is it all about? I have not yet thought of a practical application of the obtained data for society. It turned out a little research for the sake of research.
The OpenCV library is an excellent tool, using which on the data obtained, you can conduct a number of interesting experiments.
As a reward read to the end, such, for example, is a fun option: Collect the model eigenfaces.xml from photographs of famous actresses, Russian and foreign, and do a search for compliance using the Muscovites' database obtained from WhatsApp (we currently have ~ 400,000). Without taking into account the moral component (namely, the question: is it cultural to call strangers), dial the number and invite you to the cinema. It's fun to go to the movies with a girl who, with an accuracy of 3000 to 100, looks like the main character.

Even as a conclusion, one could say: "Do not forget to tick the privacy settings." But I am not a big supporter of paranoid moods (“ They know where I am,” “The Internet provider knows everything about me,” “Big Brother is watching us,” etc.). For example, I am amused when my wife turns off the collection of anonymous geodata on the phone, with the words that she will be “found” (who, and most importantly, why she has not thought of it yet).
I don’t know if anyone will ever look for me - I didn’t seem to break anything in my life (except for the WhatsApp license agreement).
Source: https://habr.com/ru/post/262053/
All Articles