The first acquaintance with the coprocessor Intel Xeon Phi
The desire to get acquainted with the Xeon Phi coprocessor arose long ago, but then everything was not possible, that time. In the end, the miracle happened and got to the object of lust. Unfortunately, far from the latest model - 5110P - fell into the hands, but for the first acquaintance it will do. Having experience working with CUDA, I was very interested in the question of differences between programming for the GPU and the coprocessor. The second question was: "What (except for an extra headache) will I have using this device instead of a GPU or CPU?"
Note: This article is not an advertisement or anti-advertising of any software or hardware product, but only describes the personal experience of the author.
In fact, the coprocessor is a separate piece of hardware that is installed in the PCI-e slot. Unlike the GPU, the coprocessor has its own Linux-like micro OS, the so-called Card OS or uOS. There are two options to run the code on Xeon Phi:
Another important point is the possibility of using OpenMP to distribute work between the threads inside the device - that's fine, let's do that. First we implement a simple algorithm on the CPU, and then we remake the program so that it works on the coprocessor.
As a test example, the task of force interaction of the bodies was chosen ( n-body problem ): there are N bodies the interaction between which is described by a certain pair potential, it is necessary to determine the position of each body after some time.
The potential and strength of the pair interaction (in this case, we can take any function since we are not interested in the physics of the process):
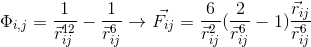
The algorithm is simple:
Obviously, the most “difficult” stage is the calculation of forces, since it is necessary to perform about N 2 operations, and even at each time step (of course, using tricks like neighbor lists and remembering Newton's third law, you can significantly reduce the number of operations, but separate story).
The serial code of this algorithm is very simple and easily converted to parallel using OpenMP directives.
Consider our original program. First we find out the device name and the available number of processors. The figure below clearly shows the differences between the code for the host (the top image) and the device (the bottom image).

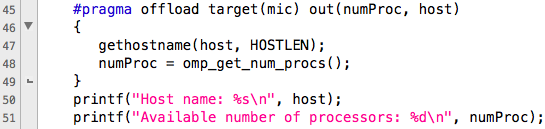
In the lower figure you can see that the directive #pragma offload is used to perform the unloading (offload) of the code on the device, the target for unloading is mic (our device). If there are several coprocessors in the system, then the device number must be specified Example:
After specifying the target, the unloading parameters follow, they can be:
Detailed description offload here .
In this case, the variables numProc and host are only declared on the host, but not initialized, so we use out to copy (you can, of course, inout, but we will not disturb the order).
The resulting code is quite possible to compile and run - no special compilation flags are required. In this case, the number of threads will determine the device, returning the value of numProc, while the calculations will still be done on the host, since we have not yet unloaded the procedures.
The very first procedure sets the initial conditions, it requires about N operations and is called only once, so we will leave it on the host.
Next, a time cycle is started, at each step of which it is necessary to calculate the interaction forces and integrate the equations of motion. The latter procedure requires, as well as setting the initial conditions, about N operations, and it would seem that it would also be logical to leave it on the host, but this will require copying the array with forces at each step. Obviously, with a large system size, most of the time will go on dragging the array back and forth. Therefore, it is necessary to upload all the source data to the device, perform the necessary number of iterations and upload the result to the host. This approach is also used when parallelizing for a GPU.
In addition to the names of arrays, here you must also specify their size. Thus, the cycle is fully loaded on the device, executed on it, after which the results are copied back. It should be noted that for the routines that will be executed on the device, you must specify the appropriate attributes :
That's all, the first program for Intel Xeon Phi is ready and even works. When you start the program, it may be useful to find out who exactly and where it copies (between the host and the device). This can be done using the environment variable OFFLOAD_REPORT. Example ( detailed ):
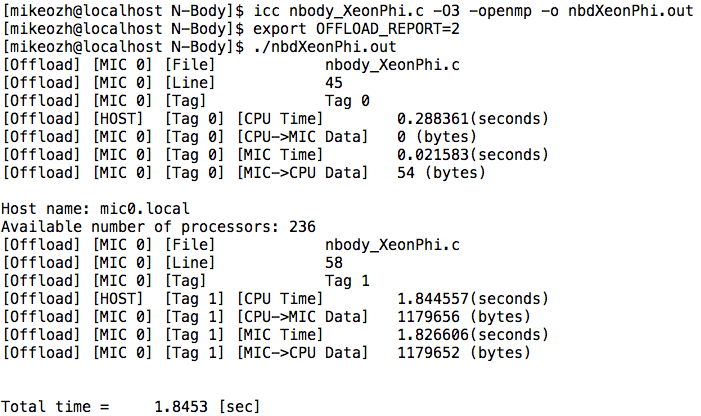
It can be seen that in the first unloading nothing was copied onto the device, but 54 bytes were received from it (the line with the name and the integer number of processors). In the second case (the second unload), it was received 4 bytes less than it was sent, since the value of the variable nBod was not copied back.
Code operation time on 24 host threads (2 Intel Xeon E5-2680v3 processors): 5.9832 sec

Code operation time on 236 device threads (Intel Xeon Phi 5110P): 1.8667 sec
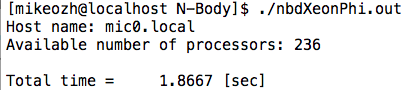
Total, 2 lines of code gave a performance boost of almost 3 times - very nice. It should be noted that you can also consider the option of hybrid computing - part of the problem is solved on the host, part on the device, however, there is no way to avoid data exchanges between the host and the device to synchronize coordinates.
')
The only similarity between programming for the GPU and Xeon Phi is the need to take care of moving data between the host and the device, in fact, this is the difference from using OpenMP exclusively for the CPU. It should be noted that the native compiler is able to automatically vectorize the code not only for the host, but also for the device, so you can get decent performance without much getting into the details.
In my opinion, Xeon Phi is well suited if you already have ready code that works with OpenMP and you need to improve performance, but there is no desire / ability to rewrite for the GPU. An important point, which will surely be enjoyed by people from the scientific community, is the support of Fortran.
www.prace-ri.eu/best-practice-guide-intel-xeon-phi-html
www.ichec.ie/infrastructure/xeonphi
www.cism.ucl.ac.be/XeonPhi.pdf
hpc-education.unn.ru/files/courses/XeonPhi/Lection03.pdf
Note: This article is not an advertisement or anti-advertising of any software or hardware product, but only describes the personal experience of the author.
Wisdom from the Developer's Quick Start Guide
In fact, the coprocessor is a separate piece of hardware that is installed in the PCI-e slot. Unlike the GPU, the coprocessor has its own Linux-like micro OS, the so-called Card OS or uOS. There are two options to run the code on Xeon Phi:
- Compile the native code for the MIC using the –mmic flag
- Run the code via offload. In this case, part of the compiled code is run on the host (computer containing the coprocessor), and part on the device (hereinafter, the coprocessor will be referred to as just a device).
Another important point is the possibility of using OpenMP to distribute work between the threads inside the device - that's fine, let's do that. First we implement a simple algorithm on the CPU, and then we remake the program so that it works on the coprocessor.
Test task description
As a test example, the task of force interaction of the bodies was chosen ( n-body problem ): there are N bodies the interaction between which is described by a certain pair potential, it is necessary to determine the position of each body after some time.
The potential and strength of the pair interaction (in this case, we can take any function since we are not interested in the physics of the process):
The algorithm is simple:
- We set the initial coordinates and velocities of the bodies;
- We calculate the force acting on each body by the others;
- We determine the new coordinates of the bodies;
- Repeat steps 2 and 3 until we reach the desired result.
Obviously, the most “difficult” stage is the calculation of forces, since it is necessary to perform about N 2 operations, and even at each time step (of course, using tricks like neighbor lists and remembering Newton's third law, you can significantly reduce the number of operations, but separate story).
The serial code of this algorithm is very simple and easily converted to parallel using OpenMP directives.
Parallel code using OpenMP
/*---------------------------------------------------------*/ /* N-Body simulation benchmark */ /* written by MSOzhgibesov */ /* 04 July 2015 */ /*---------------------------------------------------------*/ #include <stdio.h> #include <stdlib.h> #include <math.h> #include <string.h> #include <time.h> #include <omp.h> #define HOSTLEN 50 int numProc; // Initial conditions void initCoord(float *rA, float *vA, float *fA, \ float initDist, int nBod, int nI); // Forces acting on each body void forces(float *rA, float *fA, int nBod); // Calculate velocities and update coordinates void integration(float *rA, float *vA, float *fA, int nBod); int main(int argc, const char * argv[]) { int const nI = 32; // Number of bodies in X, Y and Z directions int const nBod = nI*nI*nI; // Total Number of bodies int const maxIter = 20; // Total number of iterations (time steps) float const initDist = 1.0; // Initial distance between the bodies float *rA; // Coordinates float *vA; // Velocities float *fA; // Forces int iter; double startTime0, endTime0; char host[HOSTLEN]; rA = (float*)malloc(3*nBod*sizeof(float)); fA = (float*)malloc(3*nBod*sizeof(float)); vA = (float*)malloc(3*nBod*sizeof(float)); gethostname(host, HOSTLEN); printf("Host name: %s\n", host); numProc = omp_get_num_procs(); printf("Available number of processors: %d\n", numProc); // Setup initial conditions initCoord(rA, vA, fA, initDist, nBod, nI); startTime0 = omp_get_wtime(); // Main loop for ( iter = 0; iter < maxIter; iter++ ) { forces(rA, fA, nBod); integration(rA, vA, fA, nBod); } endTime0 = omp_get_wtime(); printf("\nTotal time = %10.4f [sec]\n", endTime0 - startTime0); free(rA); free(vA); free(fA); return 0; } // Initial conditions void initCoord(float *rA, float *vA, float *fA, \ float initDist, int nBod, int nI) { int i, j, k; float Xi, Yi, Zi; float *rAx = &rA[ 0]; //---- float *rAy = &rA[ nBod]; // Pointers on X, Y, Z components of coordinates float *rAz = &rA[2*nBod]; //---- int ii = 0; memset(fA, 0.0, 3*nBod*sizeof(float)); memset(vA, 0.0, 3*nBod*sizeof(float)); for (i = 0; i < nI; i++) { Xi = i*initDist; for (j = 0; j < nI; j++) { Yi = j*initDist; for (k = 0; k < nI; k++) { Zi = k*initDist; rAx[ii] = Xi; rAy[ii] = Yi; rAz[ii] = Zi; ii++; } } } } // Forces acting on each body void forces(float *rA, float *fA, int nBod) { int i, j; float Xi, Yi, Zi; float Xij, Yij, Zij; // X[j] - X[i] and so on float Rij2; // Xij^2+Yij^2+Zij^2 float invRij2, invRij6; // 1/rij^2; 1/rij^6 float *rAx = &rA[ 0]; //---- float *rAy = &rA[ nBod]; // Pointers on X, Y, Z components of coordinates float *rAz = &rA[2*nBod]; //---- float *fAx = &fA[ 0]; //---- float *fAy = &fA[ nBod]; // Pointers on X, Y, Z components of forces float *fAz = &fA[2*nBod]; //---- float magForce; // Force magnitude float const EPS = 1.E-10; // Small value to prevent 0/0 if i==j #pragma omp parallel for num_threads(numProc) private(Xi, Yi, Zi, \ Xij, Yij, Zij, magForce, invRij2, invRij6, j) for (i = 0; i < nBod; i++) { Xi = rAx[i]; Yi = rAy[i]; Zi = rAz[i]; fAx[i] = 0.0; fAy[i] = 0.0; fAz[i] = 0.0; for (j = 0; j < nBod; j++) { Xij = rAx[j] - Xi; Yij = rAy[j] - Yi; Zij = rAz[j] - Zi; Rij2 = Xij*Xij + Yij*Yij + Zij*Zij; invRij2 = Rij2/((Rij2 + EPS)*(Rij2 + EPS)); invRij6 = invRij2*invRij2*invRij2; magForce = 6.0*invRij2*(2.0*invRij6 - 1.0)*invRij6; fAx[i]+= Xij*magForce; fAy[i]+= Yij*magForce; fAz[i]+= Zij*magForce; } } } // Integration of coordinates an velocities void integration(float *rA, float *vA, float *fA, int nBod) { int i; float const dt = 0.01; // Time step float const mass = 1.0; // mass of a body float const mdthalf = dt*0.5/mass; float *rAx = &rA[ 0]; float *rAy = &rA[ nBod]; float *rAz = &rA[2*nBod]; float *vAx = &vA[ 0]; float *vAy = &vA[ nBod]; float *vAz = &vA[2*nBod]; float *fAx = &fA[ 0]; float *fAy = &fA[ nBod]; float *fAz = &fA[2*nBod]; #pragma omp parallel for num_threads(numProc) for (i = 0; i < nBod; i++) { rAx[i]+= (vAx[i] + fAx[i]*mdthalf)*dt; rAy[i]+= (vAy[i] + fAy[i]*mdthalf)*dt; rAz[i]+= (vAz[i] + fAz[i]*mdthalf)*dt; vAx[i]+= fAx[i]*dt; vAy[i]+= fAy[i]*dt; vAz[i]+= fAz[i]*dt; } } Load the coprocessor
Consider our original program. First we find out the device name and the available number of processors. The figure below clearly shows the differences between the code for the host (the top image) and the device (the bottom image).
In the lower figure you can see that the directive #pragma offload is used to perform the unloading (offload) of the code on the device, the target for unloading is mic (our device). If there are several coprocessors in the system, then the device number must be specified Example:
#pragma offload target (mic:1) After specifying the target, the unloading parameters follow, they can be:
- in - variables are input only, that is, after the completion of the code, the values of the variables back to the host are not copied.
- out - variables are solely the result, that is, before starting the work of the unloaded part, their values are not copied from the host.
- inout - before launching the unloaded code, all variables are copied to the device, and after completion - to the host.
- nocopy - variables are not copied anywhere. Used to reuse variables already initialized.
Detailed description offload here .
In this case, the variables numProc and host are only declared on the host, but not initialized, so we use out to copy (you can, of course, inout, but we will not disturb the order).
The resulting code is quite possible to compile and run - no special compilation flags are required. In this case, the number of threads will determine the device, returning the value of numProc, while the calculations will still be done on the host, since we have not yet unloaded the procedures.
The very first procedure sets the initial conditions, it requires about N operations and is called only once, so we will leave it on the host.
Next, a time cycle is started, at each step of which it is necessary to calculate the interaction forces and integrate the equations of motion. The latter procedure requires, as well as setting the initial conditions, about N operations, and it would seem that it would also be logical to leave it on the host, but this will require copying the array with forces at each step. Obviously, with a large system size, most of the time will go on dragging the array back and forth. Therefore, it is necessary to upload all the source data to the device, perform the necessary number of iterations and upload the result to the host. This approach is also used when parallelizing for a GPU.
startTime0 = omp_get_wtime(); // Main loop #pragma offload target(mic) inout(rA, fA, vA:length(3*nBod)) in(nBod) for ( iter = 0; iter < maxIter; iter++ ) { forces(rA, fA, nBod); integration(rA, vA, fA, nBod); } endTime0 = omp_get_wtime(); In addition to the names of arrays, here you must also specify their size. Thus, the cycle is fully loaded on the device, executed on it, after which the results are copied back. It should be noted that for the routines that will be executed on the device, you must specify the appropriate attributes :
// Initial conditions void initCoord(float *rA, float *vA, float *fA, \ float initDist, int nBod, int nI); // Forces acting on each body __attribute__ ((target(mic))) void forces(float *rA, float *fA, int nBod); // Calculate velocities and update coordinates __attribute__ ((target(mic))) void integration(float *rA, float *vA, float *fA, int nBod); That's all, the first program for Intel Xeon Phi is ready and even works. When you start the program, it may be useful to find out who exactly and where it copies (between the host and the device). This can be done using the environment variable OFFLOAD_REPORT. Example ( detailed ):
It can be seen that in the first unloading nothing was copied onto the device, but 54 bytes were received from it (the line with the name and the integer number of processors). In the second case (the second unload), it was received 4 bytes less than it was sent, since the value of the variable nBod was not copied back.
Code operation time on 24 host threads (2 Intel Xeon E5-2680v3 processors): 5.9832 sec
Code operation time on 236 device threads (Intel Xeon Phi 5110P): 1.8667 sec
Total, 2 lines of code gave a performance boost of almost 3 times - very nice. It should be noted that you can also consider the option of hybrid computing - part of the problem is solved on the host, part on the device, however, there is no way to avoid data exchanges between the host and the device to synchronize coordinates.
Full code for Xeon Phi
/*---------------------------------------------------------*/ /* N-Body simulation benchmark */ /* written by MSOzhgibesov */ /* 04 July 2015 */ /*---------------------------------------------------------*/ #include <stdio.h> #include <stdlib.h> #include <math.h> #include <string.h> #include <time.h> #include <omp.h> #include <unistd.h> #define HOSTLEN 50 __attribute__ ((target(mic))) int numProc; // Initial conditions void initCoord(float *rA, float *vA, float *fA, \ float initDist, int nBod, int nI); // Forces acting on each body __attribute__ ((target(mic))) void forces(float *rA, float *fA, int nBod); // Calculate velocities and update coordinates __attribute__ ((target(mic))) void integration(float *rA, float *vA, float *fA, int nBod); int main(int argc, const char * argv[]) { int const nI = 32; // Number of bodies in X, Y and Z directions int const nBod = nI*nI*nI; // Total Number of bodies int const maxIter = 20; // Total number of iterations (time steps) float const initDist = 1.0; // Initial distance between the bodies float *rA; // Coordinates float *vA; // Velocities float *fA; // Forces int iter; double startTime0, endTime0; double startTime1, endTime1; char host[HOSTLEN]; rA = (float*)malloc(3*nBod*sizeof(float)); fA = (float*)malloc(3*nBod*sizeof(float)); vA = (float*)malloc(3*nBod*sizeof(float)); #pragma offload target(mic) out(numProc, host) { gethostname(host, HOSTLEN); numProc = omp_get_num_procs(); } printf("Host name: %s\n", host); printf("Available number of processors: %d\n", numProc); // Setup initial conditions initCoord(rA, vA, fA, initDist, nBod, nI); startTime0 = omp_get_wtime(); // Main loop #pragma offload target(mic) inout(rA, fA, vA:length(3*nBod)) in(nBod) for ( iter = 0; iter < maxIter; iter++ ) { forces(rA, fA, nBod); integration(rA, vA, fA, nBod); } endTime0 = omp_get_wtime(); printf("\nTotal time = %10.4f [sec]\n", endTime0 - startTime0); free(rA); free(vA); free(fA); return 0; } // Initial conditions void initCoord(float *rA, float *vA, float *fA, \ float initDist, int nBod, int nI) { int i, j, k; float Xi, Yi, Zi; float *rAx = &rA[ 0]; //---- float *rAy = &rA[ nBod]; // Pointers on X, Y, Z components of coordinates float *rAz = &rA[2*nBod]; //---- int ii = 0; memset(fA, 0.0, 3*nBod*sizeof(float)); memset(vA, 0.0, 3*nBod*sizeof(float)); for (i = 0; i < nI; i++) { Xi = i*initDist; for (j = 0; j < nI; j++) { Yi = j*initDist; for (k = 0; k < nI; k++) { Zi = k*initDist; rAx[ii] = Xi; rAy[ii] = Yi; rAz[ii] = Zi; ii++; } } } } // Forces acting on each body __attribute__ ((target(mic))) void forces(float *rA, float *fA, int nBod) { int i, j; float Xi, Yi, Zi; float Xij, Yij, Zij; // X[j] - X[i] and so on float Rij2; // Xij^2+Yij^2+Zij^2 float invRij2, invRij6; // 1/rij^2; 1/rij^6 float *rAx = &rA[ 0]; //---- float *rAy = &rA[ nBod]; // Pointers on X, Y, Z components of coordinates float *rAz = &rA[2*nBod]; //---- float *fAx = &fA[ 0]; //---- float *fAy = &fA[ nBod]; // Pointers on X, Y, Z components of forces float *fAz = &fA[2*nBod]; //---- float magForce; // Force magnitude float const EPS = 1.E-10; // Small value to prevent 0/0 if i==j #pragma omp parallel for num_threads(numProc) private(Xi, Yi, Zi, \ Xij, Yij, Zij, magForce, invRij2, invRij6, j) for (i = 0; i < nBod; i++) { Xi = rAx[i]; Yi = rAy[i]; Zi = rAz[i]; fAx[i] = 0.0; fAy[i] = 0.0; fAz[i] = 0.0; for (j = 0; j < nBod; j++) { Xij = rAx[j] - Xi; Yij = rAy[j] - Yi; Zij = rAz[j] - Zi; Rij2 = Xij*Xij + Yij*Yij + Zij*Zij; invRij2 = Rij2/((Rij2 + EPS)*(Rij2 + EPS)); invRij6 = invRij2*invRij2*invRij2; magForce = 6.0*invRij2*(2.0*invRij6 - 1.0)*invRij6; fAx[i]+= Xij*magForce; fAy[i]+= Yij*magForce; fAz[i]+= Zij*magForce; } } } // Integration of coordinates an velocities __attribute__ ((target(mic))) void integration(float *rA, float *vA, float *fA, int nBod) { int i; float const dt = 0.01; // Time step float const mass = 1.0; // mass of a body float const mdthalf = dt*0.5/mass; float *rAx = &rA[ 0]; float *rAy = &rA[ nBod]; float *rAz = &rA[2*nBod]; float *vAx = &vA[ 0]; float *vAy = &vA[ nBod]; float *vAz = &vA[2*nBod]; float *fAx = &fA[ 0]; float *fAy = &fA[ nBod]; float *fAz = &fA[2*nBod]; #pragma omp parallel for num_threads(numProc) for (i = 0; i < nBod; i++) { rAx[i]+= (vAx[i] + fAx[i]*mdthalf)*dt; rAy[i]+= (vAy[i] + fAy[i]*mdthalf)*dt; rAz[i]+= (vAz[i] + fAz[i]*mdthalf)*dt; vAx[i]+= fAx[i]*dt; vAy[i]+= fAy[i]*dt; vAz[i]+= fAz[i]*dt; } } ')
Conclusion
The only similarity between programming for the GPU and Xeon Phi is the need to take care of moving data between the host and the device, in fact, this is the difference from using OpenMP exclusively for the CPU. It should be noted that the native compiler is able to automatically vectorize the code not only for the host, but also for the device, so you can get decent performance without much getting into the details.
In my opinion, Xeon Phi is well suited if you already have ready code that works with OpenMP and you need to improve performance, but there is no desire / ability to rewrite for the GPU. An important point, which will surely be enjoyed by people from the scientific community, is the support of Fortran.
useful links
www.prace-ri.eu/best-practice-guide-intel-xeon-phi-html
www.ichec.ie/infrastructure/xeonphi
www.cism.ucl.ac.be/XeonPhi.pdf
hpc-education.unn.ru/files/courses/XeonPhi/Lection03.pdf
Source: https://habr.com/ru/post/262019/
All Articles