Call Center Analysis
To test the technology, I recorded several calls to different call centers. Then they will appear under the code names: water, mosenergo, rigla, transaero and worldclass.
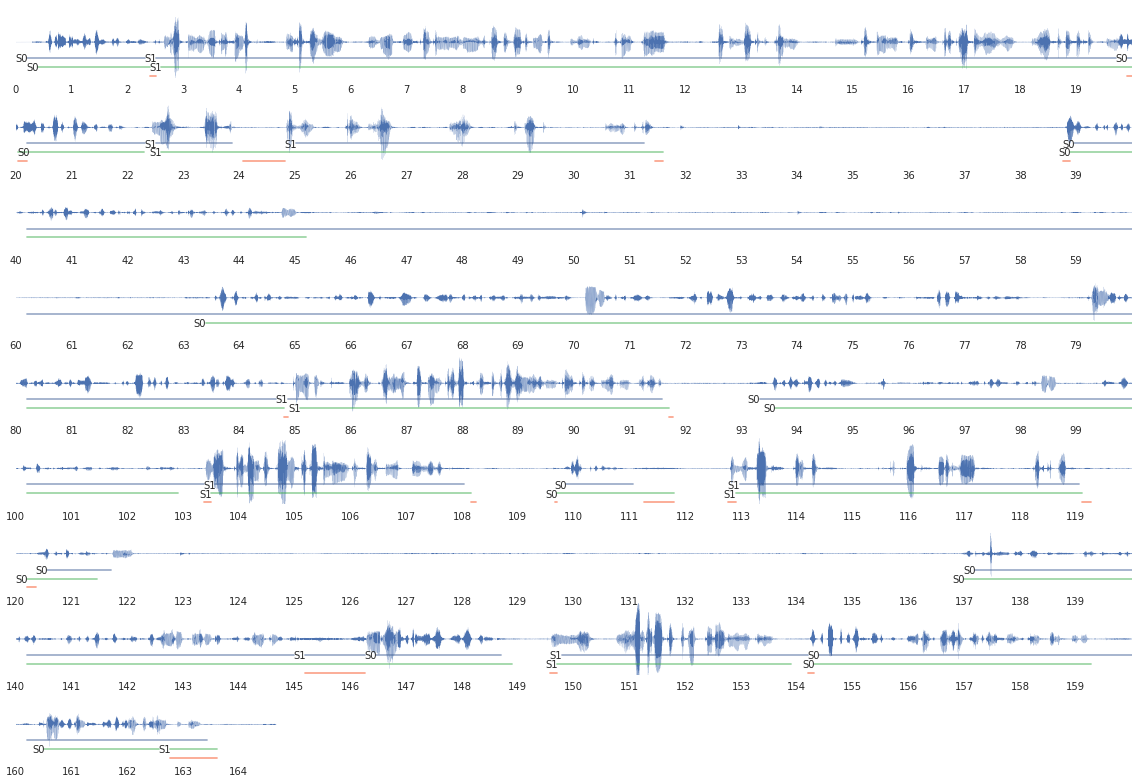
The first step is to break the record into replicas. As it turned out, this process is called diarization . There are several ready-made tools: LIUM , ALIZE , SDT . I chose LIUM, because it looked more solid than the rest. I wrote a small wrapper and marked my tracks. The quality turned out to be normal, the picture shows the markup for water:

To decrypt the replicas, I used Yandex SpeechKit . To evaluate the error of the work of their API, I first fed there the replicas obtained from the manual reference markup. Errors are significant, but you can live. The picture shows the decoding for water:




Then I deciphered the replicas received automatically. He made sure that the errors did not change much, introduced himself as the owner of the call center and tried to get some benefit:
In my opinion, technology is viable and can be of some benefit.
The first step is to break the record into replicas. As it turned out, this process is called diarization . There are several ready-made tools: LIUM , ALIZE , SDT . I chose LIUM, because it looked more solid than the rest. I wrote a small wrapper and marked my tracks. The quality turned out to be normal, the picture shows the markup for water:
- Green marks the reference marking, blue - automatic, red - errors.
- SO is an operator, S1 is me. It can be seen that the short answers of S1 are often glued to S0. This is not very scary, usually there is nothing meaningful, only phrases like: “yes”, “true”, “no”, “good”.
- The pauses in the conversation stand out more or less correctly.
mosenergo, rigla, transaero and worldclass.
mosenergo
rigla
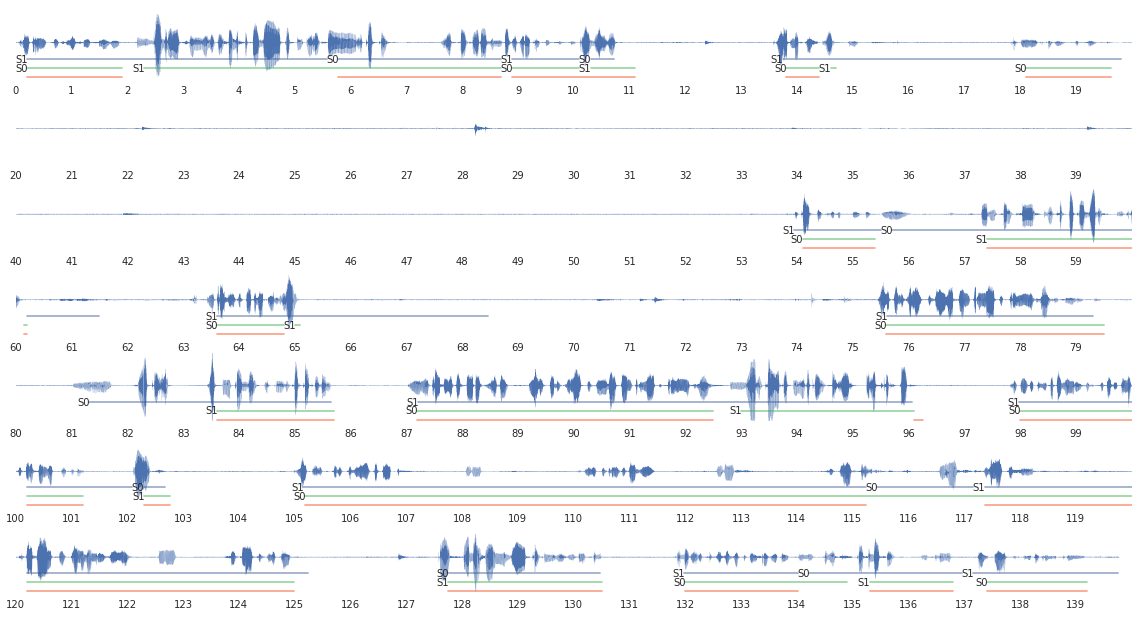
transaero
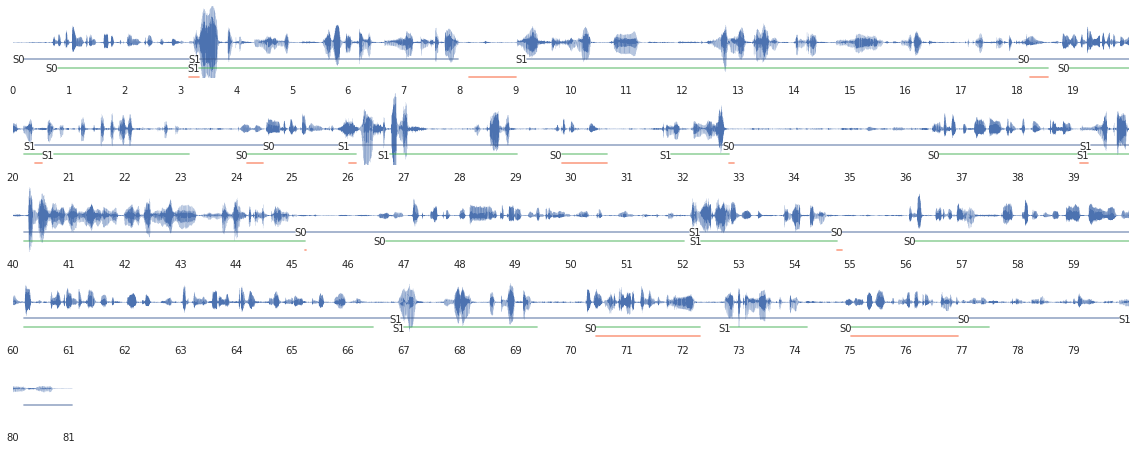
worldclass
rigla
transaero
worldclass
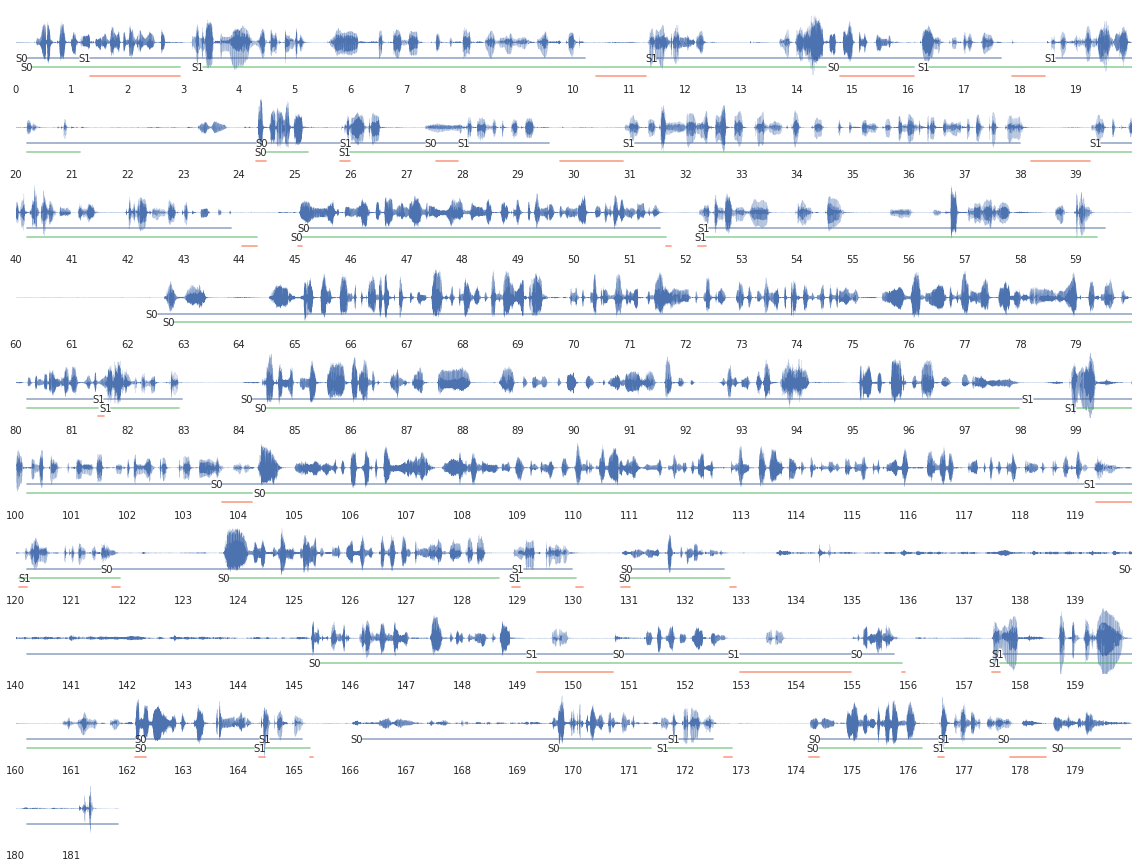
To decrypt the replicas, I used Yandex SpeechKit . To evaluate the error of the work of their API, I first fed there the replicas obtained from the manual reference markup. Errors are significant, but you can live. The picture shows the decoding for water:
- On the left, the text that came from the API, on the right, what was actually in the record. All that did not fall into the intersection is underlined in red.
- Errors on the left are words that were not actually in the record. It seems to me that they are not scary because they often get completely out of the context of the conversation: “even death”, “paddle rings”, “up to how many women”, “Lenin gray”, “evening of your country” and will not lead to errors of the second kind.
- Errors in the right column are words that were lost during expansion. Their 30% -50%. This, of course, is sad.
mosenergo, rigla, transaero and worldclass.
mosenergo

rigla

transaero

worldclass


rigla
transaero
worldclass
Then I deciphered the replicas received automatically. He made sure that the errors did not change much, introduced himself as the owner of the call center and tried to get some benefit:
- I tried to evaluate the success of hits by keywords:
show_query_results(query_transcripts(u' ', transcripts, top=10))show_query_results(query_transcripts(u' ', transcripts, top=5))show_query_results(query_transcripts(u' ', transcripts))show_query_results(query_transcripts(u' ', transcripts)) - I checked the skills of the operators for parsing services:
show_query_results(query_transcripts(u' ', transcripts))show_query_results(query_transcripts(u' ', transcripts))show_query_results(query_transcripts(u' ', transcripts))show_query_results(query_transcripts(u' ', transcripts))show_query_results(query_transcripts(u' ', transcripts))show_query_results(query_transcripts(u' ', transcripts))show_query_results(query_transcripts(u' ', transcripts))show_query_results(query_transcripts(u' ', transcripts))show_query_results(query_transcripts(u' ', transcripts)) - I tried to determine the purpose of the call:
show_query_results(query_transcripts(u' ', transcripts, top=5))show_query_results(query_transcripts(u' ', transcripts))
In my opinion, technology is viable and can be of some benefit.
')
Source: https://habr.com/ru/post/261993/
All Articles