PostgreSQL and btrfs - an elephant on an oily diet
Recently, looking at an article on the wiki about file systems, I became interested in btrfs, namely its rich features, stable status and, most importantly, the mechanism of transparent data compression. Knowing how easy it is to keep databases containing textual information, I was curious to clarify how much this is applicable in a use case such as postgres.
Of course, this testing cannot be called complete, since only reading and that linear is involved. But the results are already forced to reflect on the possible transition to btrfs in certain cases.
But the main goal is to find out the opinion of the community about how reasonable this is and what pitfalls can be concealed in the approach of transparent compression at the file system level.
')
For those who do not want to waste time, I will immediately tell you about the findings. The PostgreSQL database hosted on btrfs with the compress = lzo option reduces the database size by two (compared to any FS without compression) and when using multi-threaded, sequential reading, significantly reduces the load on the disk subsystem.
Physical server - 1 pc
So, we have a physical machine with 2 disks: the first postgres database (which is after initdb) is stored on the first one, and the second disk is fully formatted into test files (ext4, btrfs lzo / zlib) without creating markup on it.
The test disk is placed on the table space from the backup copy, which participates in the testing, made using pg_basebackup. The main postgres db is also restored.
The essence of testing lies in sequential reading of five tables - clones in five streams.
The script is extremely simple and is the usual “explain analyze”.
Each table has a size of 13GB, total volume ~ 65GB.
Data for graphs is taken from sar with the simplest parameters: "sar 1" - CPU ALL; "Sar -d 1" - I / O.
Before each launch, reset the pagecache with the command:
We check the completion of background processes:
As can be seen from the graphs, compression with the lzo algorithm gives only an insignificant load on the CPU, which, coupled with a 2-fold decrease in the volume of occupied space and some acceleration, makes this approach extremely attractive. Zlib presses our database 4 times, but at the same time, the load on the processor increases significantly (~ 7.5% of processor time), which is also quite acceptable for certain scenarios. However, btrfs has only recently acquired the status of stable (since kernel 3.10) and it is possible to introduce it into the production environment prematurely. On the other hand, the presence of a synchronous replica solves this question.
As far as I know, zlib and, probably, lzo use instructions from SSE 4.2, which reduces processor utilization and it is quite possible that in some virtualization environments, high processor utilization will prevent you from taking advantage of the compression.
If someone tells me how to influence this, then I will try to double-check the difference with and without hardware acceleration.
Of course, this testing cannot be called complete, since only reading and that linear is involved. But the results are already forced to reflect on the possible transition to btrfs in certain cases.
But the main goal is to find out the opinion of the community about how reasonable this is and what pitfalls can be concealed in the approach of transparent compression at the file system level.
')
For those who do not want to waste time, I will immediately tell you about the findings. The PostgreSQL database hosted on btrfs with the compress = lzo option reduces the database size by two (compared to any FS without compression) and when using multi-threaded, sequential reading, significantly reduces the load on the disk subsystem.
So, what is available
Physical server - 1 pc
- CPU: 2 Sockets for 6 cores
- RAM: 48 GB
- Storage:
- 2x - SAS 10K 300GB in configuration RAID 1 + 0 - for OS and main postgres db
- 2x - SAS 10K 300GB in RAID 1 + 0 configuration - for tests
- OS: Ubuntu 04/14/2 - 3.16.0-41
- PG: 9.4.4 x86_64
Testing method
So, we have a physical machine with 2 disks: the first postgres database (which is after initdb) is stored on the first one, and the second disk is fully formatted into test files (ext4, btrfs lzo / zlib) without creating markup on it.
The test disk is placed on the table space from the backup copy, which participates in the testing, made using pg_basebackup. The main postgres db is also restored.
The essence of testing lies in sequential reading of five tables - clones in five streams.
The script is extremely simple and is the usual “explain analyze”.
Each table has a size of 13GB, total volume ~ 65GB.
Data for graphs is taken from sar with the simplest parameters: "sar 1" - CPU ALL; "Sar -d 1" - I / O.
Before each launch, reset the pagecache with the command:
free && sync && echo 3 > /proc/sys/vm/drop_caches && free We check the completion of background processes:
SELECT sa.pid, sa.state, sa.query FROM pg_stat_activity sa; Numbers
Dimensions
| FS | Size in DB | Disk size | Compression factor |
|---|---|---|---|
| btrfs-zlib | 156GB | 35GB | 4.4 |
| btrfs-lzo | 156GB | 67GB | 2.3 |
| ext4 | 156GB | 156GB | one |
Explain analyze
| btrfs-zlib | 302000 ms |
| btrfs-lzo | 262000 ms |
| ext4 | 420000 ms |
Charts
CPU load
| btrfs-zlib |  |
| btrfs-lzo |  |
| ext4 | 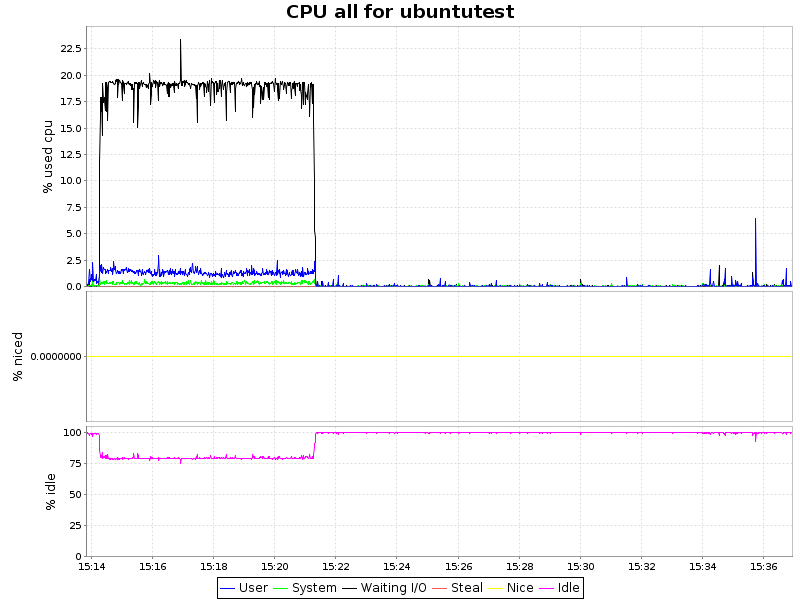 |
IO Block Transfer
| btrfs-zlib |  |
| btrfs-lzo |  |
| ext4 | 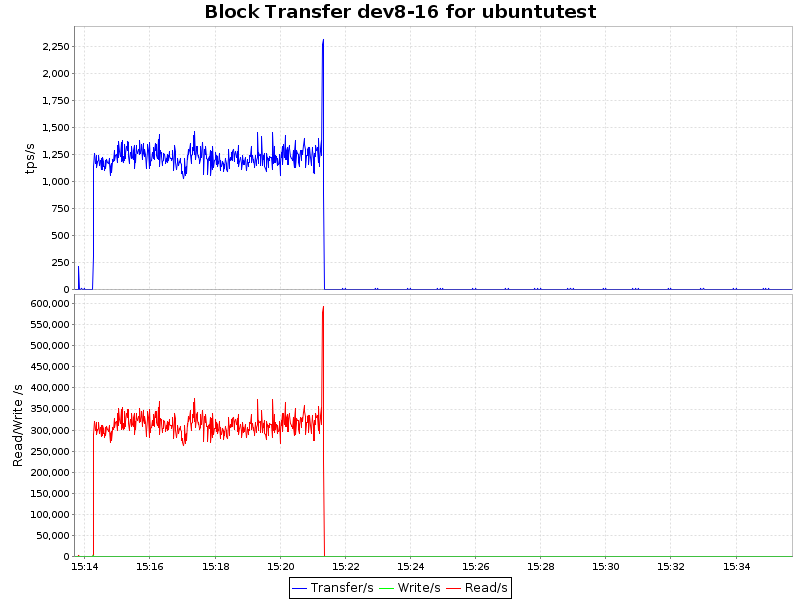 |
Io wait
| btrfs-zlib | 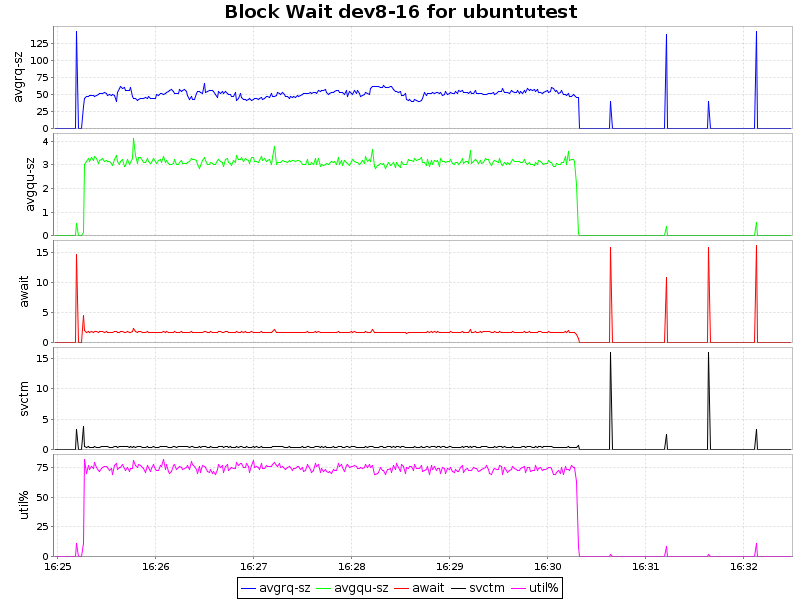 |
| btrfs-lzo | 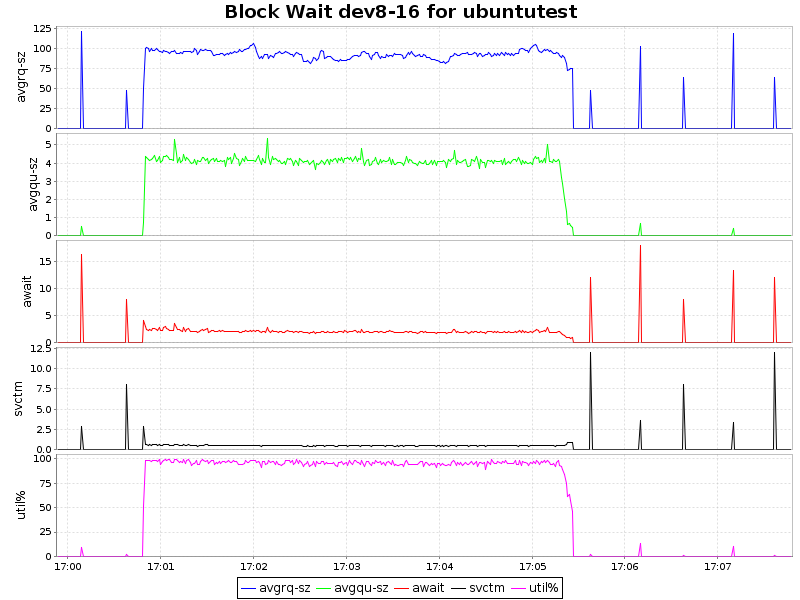 |
| ext4 |  |
Conclusion
As can be seen from the graphs, compression with the lzo algorithm gives only an insignificant load on the CPU, which, coupled with a 2-fold decrease in the volume of occupied space and some acceleration, makes this approach extremely attractive. Zlib presses our database 4 times, but at the same time, the load on the processor increases significantly (~ 7.5% of processor time), which is also quite acceptable for certain scenarios. However, btrfs has only recently acquired the status of stable (since kernel 3.10) and it is possible to introduce it into the production environment prematurely. On the other hand, the presence of a synchronous replica solves this question.
PS
As far as I know, zlib and, probably, lzo use instructions from SSE 4.2, which reduces processor utilization and it is quite possible that in some virtualization environments, high processor utilization will prevent you from taking advantage of the compression.
If someone tells me how to influence this, then I will try to double-check the difference with and without hardware acceleration.
Source: https://habr.com/ru/post/261921/
All Articles