Seven kinds of virtual machine interpreters. In search of the fastest
All problems in the field of Computer Science can be solved by introducing an additional level of indirection. Except for one: too many levels of indirection.
But for all the problems of computer science, it’s possible to solve all problems.
Software interpreters are known for their low speed. In this article I will tell you how to speed them up.
I have long wanted to elaborate on the creation of interpreters. Just the same promised, including himself. However, a serious approach required the use of more or less realistic code for examples, as well as performance measurements, confirming (and sometimes refuting) my arguments. But at last I am ready to present to the venerable public results, and even a little more interesting than I intended.
This article will describe seven ways to build a software VM for a single guest system. We will proceed from the slowest to the faster ones, in turn getting rid of various “inefficiencies” in the code, and at the end we will compare their work using the example of one program.
Those who are not afraid of assembler listings, macro-speckled C code, richly fertilized with address arithmetic, goto and even longjmp, as well as programs that use copy-paste in the name of speed or even create pieces of themselves, please under cat.

Interpreters are a class of programs that analyze text written in some input language for one phrase (expression, statement, instruction, other semantic unit) at a time and immediately perform the actions prescribed by this phrase. In this way, they differ, for example, from translators in which the phases of parsing the input language and the execution of actions are separated in time.
This definition is quite general, and many programs fall under it, including implementing virtual machines (VMs). The latter can be divided into two classes : language and system.
It should be warned that most of the ideas that I will talk about were found quite a long time [3, 4]. Moreover, a similar comparison of the speed of various types of interpreters (for a very primitive VM) has already been made [2]. There are even Russian-language books of the Soviet time [1] on this topic.
1. I allow myself to limit myself to Intel® 64 host architecture. Measurements will be made for only one machine. I urge all readers to clearly understand that the details of the architecture and micro-architecture (such as the organization of the transition predictor) directly affect the speed of the programs, in particular the interpreters. Moreover, it may turn out that algorithm A, which runs faster than algorithm B on architecture Z, will lose to him on system Y.
')
2. Code examples were made with the expectation of inter-system portability. They must be handled correctly by the currently popular versions of the GCC and ICC compilers on POSIX systems. I will point out a few “non-portable” places separately.
3. The story is focused on interpreters created for the needs of simulation of central processing units. The specificity of this subject area affects the structure of the solution. For example, further attention is drawn to the non-triviality of the decoding phase of the input machine language, whereas in the works I know, this problem is considered trivial (solved by the identity operator).
4. In this article, nothing will be said about the analysis of grammar, that is, about that part of the interpretation necessary for building interpreters of high-level languages. In the book of Terrence Parr [5], the creator of ANTLR - a powerful framework for creating lexers, parsers and generators, this issue is revealed in detail and in detail.
So, first, the description of what we will model is the specification of the virtual machine.
The architecture of the investigated VM
The full code of the examples, as well as the Makefile for the build and the script for performance testing are published here: github.com/grigory-rechistov/interpreters-comparison .
Further I will quote some pieces of code from there and refer the reader to specific file names and functions.
For the purposes of this article, I wanted to use a VM, simple enough to have time to write and debug several options for its implementation in a reasonable time, but difficult enough so that it manifests various effects inherent in real projects, and that it can be performed though would be a minimally useful program, and not just a boring pseudo-random flow of instructions.
In general, this VM is inspired by the Fort language. Compared to it, it is greatly simplified and has only those instructions that were necessary to illustrate the ideas described in the article. The most important, in my opinion, its omissions (simplifications) compared with the normal Fort - the lack of a procedural mechanism and a dictionary.
I want to note that all the examples described below can be directly adapted not only for stack but also register VMs.
- The word width is 32 bits. All operands and instructions are signed or unsigned 32-bit integers.
- Three processor states: Running — active execution of instructions; Halted - stop after the execution of Halt, corresponds to the normal completion of the program; Break - stop after any abnormal, unsupported, or non-standard state instruction, indicates an error in the program. In other words, the VM starts working in the Running state. She finishes her work in the Halted state, if no unexpected events occurred during the work and the execution reached the Halt instruction. If there was a division by zero, going beyond the code, overflowing or emptying the stack, or something else that I didn’t want to support during implementation, it stops in Break mode.
- All registers are implicit, and there are only two of them. PC is a pointer to the current command. SP is a pointer to the top of the stack. At the beginning of the PC = 0, SP = -1.
- A stack of parameters with 32 unsigned whole words. SP points to the current member, or is -1 if the stack is empty.
- Program memory with a capacity of 512 words, available only for reading. When going beyond the boundaries [0; 511] the processor stops in the Break state.
- Instructions can have zero or one explicit operand (imm). In the first case, they have a length of one word, in the second - two.
- Description of all machine instructions. Operation codes, as well as other elements of the VM architecture, are described in the common.h file.Description of instruction setBreak = 0x0000 - put the processor in the Break state. Since the uninitialized program memory is filled with zeros, any random transition "past the code" leads to a halt.
Nop = 0x0001 - an empty command that does not change the stack and SP.
Halt = 0x0002 - put the processor in the Halted state.
Push = 0x0003 imm - put the imm constant at the top of the stack.
Print = 0x0004 - remove the value from the top of the stack and print it in decimal form.
JNE = 0x0005 imm - remove the value from the top of the stack, and if it is not zero, add imm to PC. The imm is interpreted as a signed number.
Swap = 0x0006 - swap the top of the stack and the next element below.
Dup = 0x0007 - put a copy of the topmost item on the top of the stack.
JE = 0x0008 imm - remove the value from the top of the stack, and if it is zero, add imm to PC. The imm is interpreted as a signed number.
Inc = 0x0009 - add one to the top of the stack.
Add = 0x000a - add the top two stack elements. Remove them from the stack and put the result as the top.
Sub = 0x000b - subtract from the top of the stack following it. Remove them from the stack and place the result on top.
Mul = 0x000c - multiply the top two stack elements. Remove them from the stack and put the result as the top.
Rand = 0x000d - place a random number on the top of the stack.
Dec = 0x000e - subtract one from the top of the stack.
Drop = 0x000f - remove the number from the top of the stack and “throw it away”.
Over = 0x0010 - place on the top of the stack a copy of the item that is the second in the stack after the top.
Mod = 0x0011 - divide the top stack element to the next one. Remove them from the stack and place the remainder of the division at the top.
Jump = 0x0012 imm - add imm to PC. The imm is interpreted as a signed number.
Arithmetic operations that lead to overflow (except division by zero) do not cause a transition to the Break state and are not signaled in any way.
I note that all instructions, including those that control execution (ie, Jump, JE, JNE), unconditionally promote the PC to its length at the end of the execution. This should be taken into account when calculating the transition address offset. Those. the jump is counted from the beginning of the instruction, following for the current one. - Execution of any instruction not explicitly defined in the architecture is equivalent to execution of Break.
- For debugging needs, the processor contains a 64-bit register of steps, increasing by one after each executed VM instruction. Programs allow you to set a limit on the number of steps after which the simulation is interrupted. By default, it is LLONG_MAX.
- After completion of the simulation program displays the status of the processor and the stack on the screen.
Benchmark
To compare the performance needed a program written for this VM. It had to be long enough, with a non-trivial flow of control, not to use excessive input-output, i.e. be computationally complex. And at the same time be simple enough that such a scattered person like me could debug it in machine codes even without a normally working simulator. The result is what I called Primes.
Primes displays all prime numbers contained in the interval from 2 to 100,000. Its code for the VM is contained in the Primes [] array, which was declared the same in all examples.
Primes
const Instr_t Primes [PROGRAM_SIZE] = {
Instr_Push, 100000, // nmax (maximal number to test)
Instr_Push, 2, // nmax, c (minimal number to test)
/ * back: * /
Instr_Over, // nmax, c, nmax
Instr_Over, // nmax, c, nmax, c
Instr_Sub, // nmax, c, c-nmax
Instr_JE, +23, / * end * / // nmax, c
Instr_Push, 2, // nmax, c, divisor
/ * back2: * /
Instr_Over, // nmax, c, divisor, c
Instr_Over, // nmax, c, divisor, c, divisor
Instr_Swap, // nmax, c, divisor, divisor, c
Instr_Sub, // nmax, c, divisor, c-divisor
Instr_JE, +9, / * print_prime * / // nmax, c, divisor
Instr_Over, // nmax, c, divisor, c
Instr_Over, // nmax, c, divisor, c, divisor
Instr_Swap, // nmax, c, divisor, divisor, c
Instr_Mod, // nmax, c, divisor, c mod divisor
Instr_JE, +5, / * not_prime * / // nmax, c, divisor
Instr_Inc, // nmax, c, divisor + 1
Instr_Jump, -15, / * back2 * / // nmax, c, divisor
/ * print_prime: * /
Instr_Over, // nmax, c, divisor, c
Instr_Print, // nmax, c, divisor
/ * not_prime * /
Instr_Drop, // nmax, c
Instr_Inc, // nmax, c + 1
Instr_Jump, -28, / * back * / // nmax, c
/ * end: * /
Instr_Halt // nmax, c (== nmax)
};
In my launches, it ran from half to three minutes. Its algorithm is approximately (corrected for the stack architecture) corresponds to the program contained in the file native.c.
main () from native.c
int main () {
for (int i = 2; i <100000; i ++) {
bool is_prime = true;
for (int divisor = 2; divisor <i; divisor ++) {
if (i% divisor == 0) {
is_prime = false;
break;
}
}
if (is_prime)
printf ("[% d] \ n", i);
}
return 0;
}
Optimization Note
One misleading benchmark can help achieve what is impossible to get through years of good engineering work.
A misleading benchmark can be done.
dilbert.com/strip/2009-03-02
I want to once again emphasize one very important point in optimizing application performance: no one can be trusted . Especially if someone says something like: “use algorithm X instead of your Y, because it is always faster”. It is impossible to trust hardware prospectuses to manufacturers of equipment, articles of creators of compilers, promises of authors of libraries. You can not believe your instinct - in matters of finding bottlenecks in performance, it still lies like. You can only believe the results of measurements and profiling, and then not always.
Nevertheless, you can believe me. Indeed, the Primes program, which I use to compare performance, is ridiculously naive: not only does it hardly create any significant load on all processor subsystems, so the algorithm used in it is not optimal! In fact, for large N there is no need to check the divisibility of N by N-1; it suffices to check the dividers from 2 to √N. She doesn't even use all the available instructions that I wrote so carefully!
Yes, and VM, which is already there, a little worth it. Resource volumes are tiny, even 8-bit microcontrollers are often more complicated. Without mechanisms for calling procedures and handling exceptions, you won't get far.
But do not forget that all this material serves only an illustrative purpose. If the simulator were realistically complex, and the benchmark program were real sizes, then few would want to read them.
The optimization note applies to all subsequent material in this article. On another generation of host processors with a different version of the compiler, it may well turn out that the slowest code of this article will overtake all other options. I myself was surprised to receive the graphics - some results did not meet my expectations; Moreover, different compilers took the lead of different participants. But I am again running ahead.
Switchable
The first interpreter construction scheme is the most popular - the switched interpreter (the switched.c file). Its code naturally expresses the base cycle "read the operation code - recognize - execute - repeat". Since this is the first scheme to be analyzed, let us consider how all the phases of this cycle are expressed in code VM; in the future we will pay attention only to the differences (no one wants to read hundreds of lines of similar code).
The fetch () function reads the “raw code” of the operation located at PC. Since the interpreter models the system VM, it is necessary to be ready for the PC to go beyond memory; fetch_checked () is responsible for checking.
fetch () and fetch_checked () code
static inline Instr_t fetch (const cpu_t * pcpu) {
assert (pcpu);
assert (pcpu-> pc <PROGRAM_SIZE);
return pcpu-> pmem [pcpu-> pc];
};
static inline Instr_t fetch_checked (cpu_t * pcpu) {
if (! (pcpu-> pc <PROGRAM_SIZE)) {
printf ("PC out of bounds \ n");
pcpu-> state = Cpu_Break;
return Instr_Break;
}
return fetch (pcpu);
}
The decode () function should complete what started in fetch () —to fully define the characteristics of the command. In our case, this is its length (1 or 2) and the value of the literal operand for those instructions that have it. In addition, according to the adopted agreements, all unknown opcodes are considered equivalent to Break. All this becomes clear as a result of the work of a single switch statement.
The peculiarity of the processing of "long" instructions with the operand: they require additional reading of the instruction memory at PC + 1, which also needs to be checked to go beyond the boundaries.
decode code ()
static inline decode_t decode (Instr_t raw_instr, const cpu_t * pcpu) {
assert (pcpu);
decode_t result = {0};
result.opcode = raw_instr;
switch (raw_instr) {
case Instr_Nop:
case Instr_Halt:
case Instr_Print:
case Instr_Swap:
case Instr_Dup:
case Instr_Inc:
case Instr_Add:
case Instr_Sub:
case Instr_Mul:
case Instr_Rand:
case Instr_Dec:
case Instr_Drop:
case Instr_Over:
case Instr_Mod:
result.length = 1;
break;
case Instr_Push:
case Instr_JNE:
case Instr_JE:
case Instr_Jump:
result.length = 2;
if (! (pcpu-> pc + 1 <PROGRAM_SIZE)) {
printf ("PC + 1 out of bounds \ n");
pcpu-> state = Cpu_Break;
break;
}
result.immediate = (int32_t) pcpu-> pmem [pcpu-> pc + 1];
break;
case Instr_Break:
default: / * Undefined instructions equal to Break * /
result.length = 1;
result.opcode = Instr_Break;
break;
}
return result;
}
For more realistic architectures, the decoding procedure in a software VM is somewhat more complicated : you have to search through the prefix tree, that is, go through a series of nested switches. But I think that the general idea was successful.
Finally, execution — by the operation code obtained from decode (), we move on to the service procedure (service routine) —a block of code responsible for the semantics of a specific guest instruction. Another switch, in all its
switch code
uint32_t tmp1 = 0, tmp2 = 0;
/ * Execute - a big switch * /
switch (decoded.opcode) {
case Instr_Nop:
/ * Do nothing * /
break;
case Instr_Halt:
cpu.state = Cpu_Halted;
break;
case Instr_Push:
push (& cpu, decoded.immediate);
break;
case Instr_Print:
tmp1 = pop (& cpu); BAIL_ON_ERROR ();
printf ("[% d] \ n", tmp1);
break;
case Instr_Swap:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1);
push (& cpu, tmp2);
break;
case Instr_Dup:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1);
push (& cpu, tmp1);
break;
case Instr_Over:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp2);
push (& cpu, tmp1);
push (& cpu, tmp2);
break;
case Instr_Inc:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 + 1);
break;
case Instr_Add:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 + tmp2);
break;
case Instr_Sub:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 - tmp2);
break;
case Instr_Mod:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
if (tmp2 == 0) {
cpu.state = Cpu_Break;
break;
}
push (& cpu, tmp1% tmp2);
break;
case Instr_Mul:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 * tmp2);
break;
case Instr_Rand:
tmp1 = rand ();
push (& cpu, tmp1);
break;
case Instr_Dec:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1-1);
break;
case Instr_Drop:
(void) pop (& cpu);
break;
case Instr_JE:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
if (tmp1 == 0)
cpu.pc + = decoded.immediate;
break;
case Instr_JNE:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
if (tmp1! = 0)
cpu.pc + = decoded.immediate;
break;
case Instr_Jump:
cpu.pc + = decoded.immediate;
break;
case Instr_Break:
cpu.state = Cpu_Break;
break;
default:
assert ("Unreachable" && false);
break;
}
Hereinafter, BAIL_ON_ERROR is used to intercept possible exceptions that occurred during the execution of individual commands:
#define BAIL_ON_ERROR () if (cpu.state! = Cpu_Running) break;
Unfortunately, this is C, and using normal try-catch will not work (but wait, near the end of the article there will be something similar to it).
An observant reader may wonder why two switches are used: in decode () and in main (), because they are called one by one and controlled by the same value, that is, they can be combined. The need for such a separation will become clear in the next section, where we will get rid of the need to constantly call decode ().
Pre-decoding (pre-decoding)
The first thing to get rid of is decoding at each step of the simulation (file predecoded.c). In fact, the contents of the program do not change in the course of work, or change very infrequently: when loading new applications or dynamic libraries, occasionally by the application itself (JIT program that adds its own pieces). In our VM there is generally no possibility to change the program during execution, and this should be used.
code predecode_program ()
static void predecode_program (const Instr_t * prog,
decode_t * dec, int len) {
assert (prog);
assert (dec);
/ * The program is short.
Otherwise, some sort of lazy decoding will be required * /
for (int i = 0; i <len; i ++) {
dec [i] = decode_at_address (prog, i);
}
}
Since the memory of the programs of this VM is only 512 words, we have the opportunity to decode it all at once and save the result in an array indexed by the value of PC. In real VMs with 2 ³² – 2⁶⁴ byte guest memory, this trick wouldn’t work. It would be necessary to use an a la cache structure with displacement, which in a limited amount of host memory would keep the working set of matches “PC → decode_t”. In this case, it would be necessary to make new entries in the cache of decoded instructions during simulation. However, in this case there would be a gain in speed. When re-executing recently executed instructions, they would not have to be re-decoded.
Well, let's call predecode_program () before execution:
Predecoded Code
decode_t decoded_cache [PROGRAM_SIZE];
predecode_program (cpu.pmem, decoded_cache, PROGRAM_SIZE);
while (cpu.state == Cpu_Running && cpu.steps <steplimit) {
if (! (cpu.pc <PROGRAM_SIZE)) {
printf ("PC out of bounds \ n");
cpu.state = Cpu_Break;
break;
}
decode_t decoded = decoded_cache [cpu.pc];
uint32_t tmp1 = 0, tmp2 = 0;
/ * Execute - a big switch * /
switch (decoded.opcode) {
case Instr_Nop:
/ * Do nothing * /
break;
case Instr_Halt:
cpu.state = Cpu_Halted;
break;
case Instr_Push:
push (& cpu, decoded.immediate);
break;
case Instr_Print:
tmp1 = pop (& cpu); BAIL_ON_ERROR ();
printf ("[% d] \ n", tmp1);
break;
case Instr_Swap:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1);
push (& cpu, tmp2);
break;
case Instr_Dup:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1);
push (& cpu, tmp1);
break;
case Instr_Over:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp2);
push (& cpu, tmp1);
push (& cpu, tmp2);
break;
case Instr_Inc:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 + 1);
break;
case Instr_Add:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 + tmp2);
break;
case Instr_Sub:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 - tmp2);
break;
case Instr_Mod:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
if (tmp2 == 0) {
cpu.state = Cpu_Break;
break;
}
push (& cpu, tmp1% tmp2);
break;
case Instr_Mul:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 * tmp2);
break;
case Instr_Rand:
tmp1 = rand ();
push (& cpu, tmp1);
break;
case Instr_Dec:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1-1);
break;
case Instr_Drop:
(void) pop (& cpu);
break;
case Instr_JE:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
if (tmp1 == 0)
cpu.pc + = decoded.immediate;
break;
case Instr_JNE:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
if (tmp1! = 0)
cpu.pc + = decoded.immediate;
break;
case Instr_Jump:
cpu.pc + = decoded.immediate;
break;
case Instr_Break:
cpu.state = Cpu_Break;
break;
default:
assert ("Unreachable" && false);
break;
}
cpu.pc + = decoded.length; / * Advance PC * /
cpu.steps ++;
}
Two comments.
1. Pre-decoding leads to the fact that at the stage of command execution the Fetch phase is not executed. In this case, there is a risk of incorrect simulation of architectural effects associated with it, such as triggering hardware breakpoints. This problem is solved by carefully tracking the entered cache.
2. Unlike system VMs, in language VMs, which usually have a very simple command structure, the fetch and decode phases are trivial. Therefore, for them, such caching is not applicable.
How much getting rid of decoding accelerated the simulation? Let me keep the intrigue until the end of the article, where all variants of interpreters will be compared. In the meantime, let's try to understand how to further speed up our interpreter.
As I already wrote, intuition in this case is a bad assistant. Let's turn to impartial tools: we use Intel® VTune Amplifier XE 2015 Update 4 to carry out “General Exploration” for predecoded. In the overview report, the problematic, from the point of view of the analyzer, aspects of the program are highlighted in red:
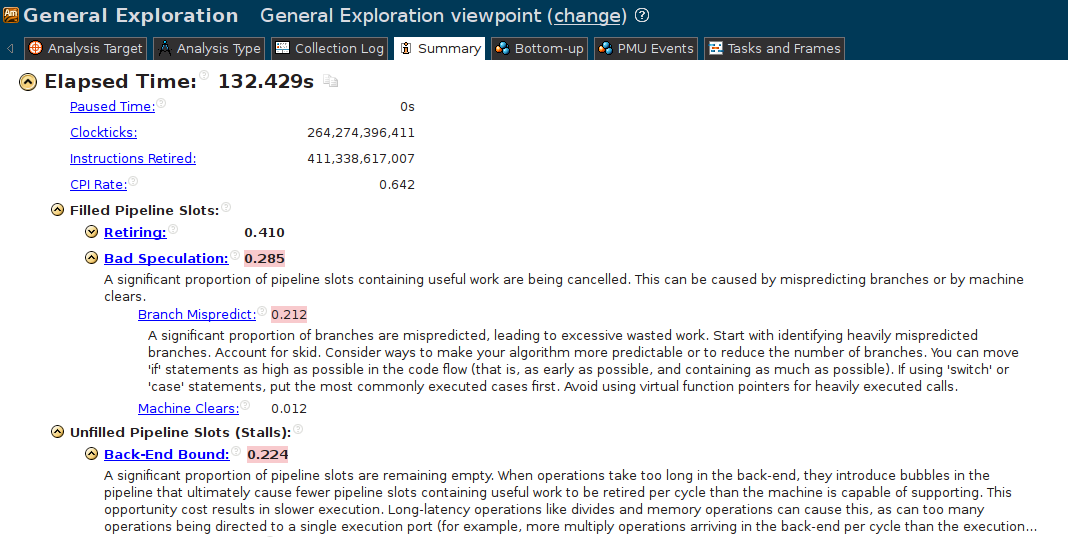
"Bad speculation" ??? What is such a speculator? Unclear. “Branch Mispredict” is already clearer. Some kind of conditional or indirect transition in our program constantly causes an error of the predictor of transitions. At this event, instead of doing useful work, the processor is forced to empty the pipeline and begin executing another instruction. In this case, there is a simple one in a couple of tens of cycles.
But why in such a simple program such a problem? Begin to go down below. I click on “Branch Mispredict”, it opens the Bottom-up view, which shows the main suspect - main ().

NDA, it did not become clearer. Let's try to search for the program line. We click on main (), a view of the program source opens (previously collected with symbolic information). Open both views - Source and Assembly, and carefully look at the columns "Branch Mispredict". Frankly, I did not immediately manage to find what I needed, even though I knew where and what to look for.
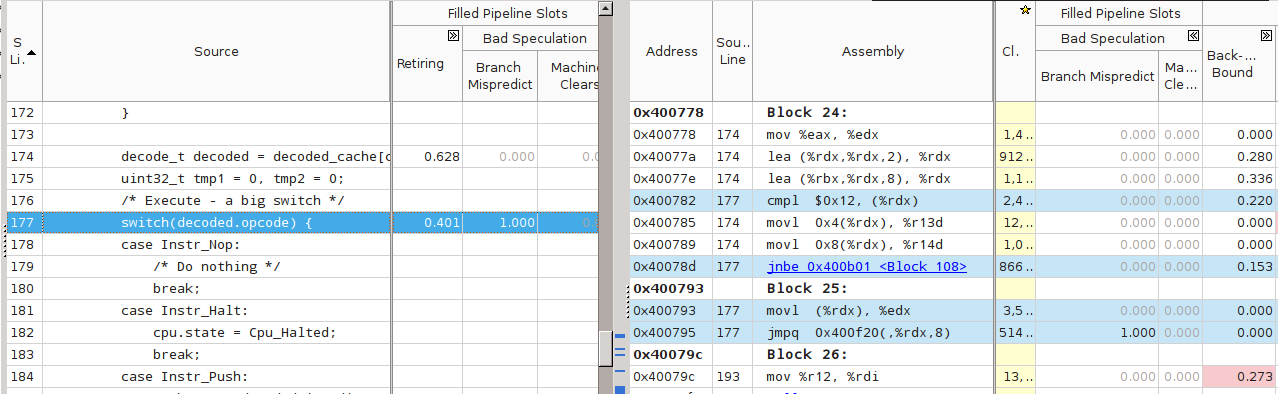
In this screenshot, blue highlights the lines of the source code and the corresponding machine code. Wow - our main switch and the corresponding command “jmpq 0x400f20 (,% rdx, 8)” have one hundred percent (1.000) incorrect predictions! How so? The reason is the limitations of the equipment for predicting such transitions.
The branch target predictor tries to predict where the transition will occur in the current jmp version, based on a limited set of historical data, such as the address of the instruction itself and the history of transitions from it. In our case, the transition history is the history of the execution of guest commands inside the VM. However, for Primes, it is completely chaotic - after push, both one more push and over can go, after over can go over, sub, swap; the number of iterations of the inner loop is large and changes all the time, etc.
Conditional transitions
A very good practical example illustrating the similar effect of the predictor of conditional jumps on the speed of the program, is available on Stackoverflow : pre-sorting of a random array speeds up the filtering algorithm on it.
The penalty of incorrectly predicting the address of the transition is the more likely the greater the number of instructions available in the VM - for this reason I abandoned the idea of using the BF machine as an experimental one: only 8 instructions could turn out to be insufficient.
Threaded
“SEDDRESSES are an important element of the Ardrit civilization from the planet Enteropia. See SEPULARS.
I followed this advice and read:
"SEPULCARIES - devices for seperation".
I searched "Sepulenie"; it said:
“SEPARATION is the occupation of the ardrites from the planet Enteropia. See SOPULTS.
Stanislav Lem. “The Star Diaries of Ion Tikhy. Journey fourteenth. "
With the cause of poor performance figured out. Let's start to eliminate it. Need to help predictor transitions. In this case, of course, it would be nice to know how it works, in detail. For lack (or unwillingness to contact) the details, we use general considerations. Recall that the predictor uses the address of the instruction itself to associate the transition history with it. That would be able to "smudge" a single jmp in several places; Each of them will have its own local history, which, hopefully, will be less chaotic to make adequate predictions.
This is what I tried to do in the threaded.c and threaded-cached.c files (an option that also includes pre-decoding).
The essence of the solution: after the execution of the current service procedure, do not return to the common point (switch), but go straight to the service procedure of the next instruction.
The bad news number 1 - to go on the label will have to use the operator goto. Yes, yes, I know, goto is bad, oh, I myself wrote about it. For the sake of speed - all serious. In the VM code, this will be hidden in the DISPATCH macro:
DISPATCH Code
#define DISPATCH () do {\
goto * service_routines [decoded.opcode]; \
} while (0);
The bad news is number 2: you will have to use a non-standard (absent in C standard) extension of the GCC language — the operator for taking the address of the && label:
Defining the service_routines tag array:
const void * service_routines [] = {
&& sr_Break, && sr_Nop, && sr_Halt, && sr_Push, && sr_Print,
&& sr_Jne, && sr_Swap, && sr_Dup, && sr_Je, && sr_Inc,
&& sr_Add, && sr_Sub, && sr_Mul, && sr_Rand, && sr_Dec,
&& sr_Drop, && sr_Over, && sr_Mod, && sr_Jump, NULL
};
This nonstandard operator is supported by GCC and ICC compilers for the C language (but as far as I know, not for C ++).
As a result, the main "loop" (which in fact does not do any iteration) of the interpreter looks like this:
Threaded-cached.c main () code
decode_t decoded = {0};
DISPATCH ();
do {
sr_Nop:
/ * Do nothing * /
ADVANCE_PC ();
DISPATCH ();
sr_Halt:
cpu.state = Cpu_Halted;
ADVANCE_PC ();
/ * No need to dispatch after Halt * /
sr_Push:
push (& cpu, decoded.immediate);
ADVANCE_PC ();
DISPATCH ();
sr_Print:
tmp1 = pop (& cpu); BAIL_ON_ERROR ();
printf ("[% d] \ n", tmp1);
ADVANCE_PC ();
DISPATCH ();
sr_Swap:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1);
push (& cpu, tmp2);
ADVANCE_PC ();
DISPATCH ();
sr_Dup:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1);
push (& cpu, tmp1);
ADVANCE_PC ();
DISPATCH ();
sr_Over:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp2);
push (& cpu, tmp1);
push (& cpu, tmp2);
ADVANCE_PC ();
DISPATCH ();
sr_Inc:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 + 1);
ADVANCE_PC ();
DISPATCH ();
sr_Add:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 + tmp2);
ADVANCE_PC ();
DISPATCH ();
sr_Sub:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 - tmp2);
ADVANCE_PC ();
DISPATCH ();
sr_Mod:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
if (tmp2 == 0) {
cpu.state = Cpu_Break;
break;
}
push (& cpu, tmp1% tmp2);
ADVANCE_PC ();
DISPATCH ();
sr_Mul:
tmp1 = pop (& cpu);
tmp2 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1 * tmp2);
ADVANCE_PC ();
DISPATCH ();
sr_Rand:
tmp1 = rand ();
push (& cpu, tmp1);
ADVANCE_PC ();
DISPATCH ();
sr_Dec:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
push (& cpu, tmp1-1);
ADVANCE_PC ();
DISPATCH ();
sr_Drop:
(void) pop (& cpu);
ADVANCE_PC ();
DISPATCH ();
sr_Je:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
if (tmp1 == 0)
cpu.pc + = decoded.immediate;
ADVANCE_PC ();
DISPATCH ();
sr_Jne:
tmp1 = pop (& cpu);
BAIL_ON_ERROR ();
if (tmp1! = 0)
cpu.pc + = decoded.immediate;
ADVANCE_PC ();
DISPATCH ();
sr_Jump:
cpu.pc + = decoded.immediate;
ADVANCE_PC ();
DISPATCH ();
sr_Break:
cpu.state = Cpu_Break;
ADVANCE_PC ();
/ * No need to dispatch after Break * /
} while (cpu.state == Cpu_Running);
The simulation begins with the first DISPATCH and then occurs as a leapfrog between service procedures. The number of host instructions for indirect transitions in the code has grown, and each of them now has an associated history for a couple of guest instructions. The probability of an unsuccessful prediction decreases in this case (in [4] it is stated that from 100% to 50%).
This technique has the name of the sewn code , in English - threaded code; Note that the modern term “thread - flow” appeared much later and is not related to the topic in question.
This optimization and in our time is used in quite popular projects. I will quote the post Utter_step habrahabr.ru/post/261575 of July 1 of this year:
Vamsi Parasa from the team of optimizing server scripting languages from Intel suggested a patch <...> that translated the switch block responsible for processing Python bytecode to use the computed goto, as already done in Python 3. As Eli Bendersky explained , in such a huge switch -block, as in the bytecode parsing unit in CPython (consisting of more than 2000 (!) lines), this gives an acceleration of about 15-20%. This happens for two reasons: the computed goto, unlike the switch-case, does not perform the boundary checks required for the switch operator according to the C99 standard, and, perhaps more importantly, the CPU can better predict branching in such situations <... >
However, when measuring the interpreter speed obtained from threaded.c with the default compilation flags (threaded-notune program), I got an unexpected result. The speed of the program was 10% –20% lower than switched. Analysis in VTune showed that the cause of the brakes is still the same - 100% Branch Mispredict on one of the indirect transitions within DISPATCH:
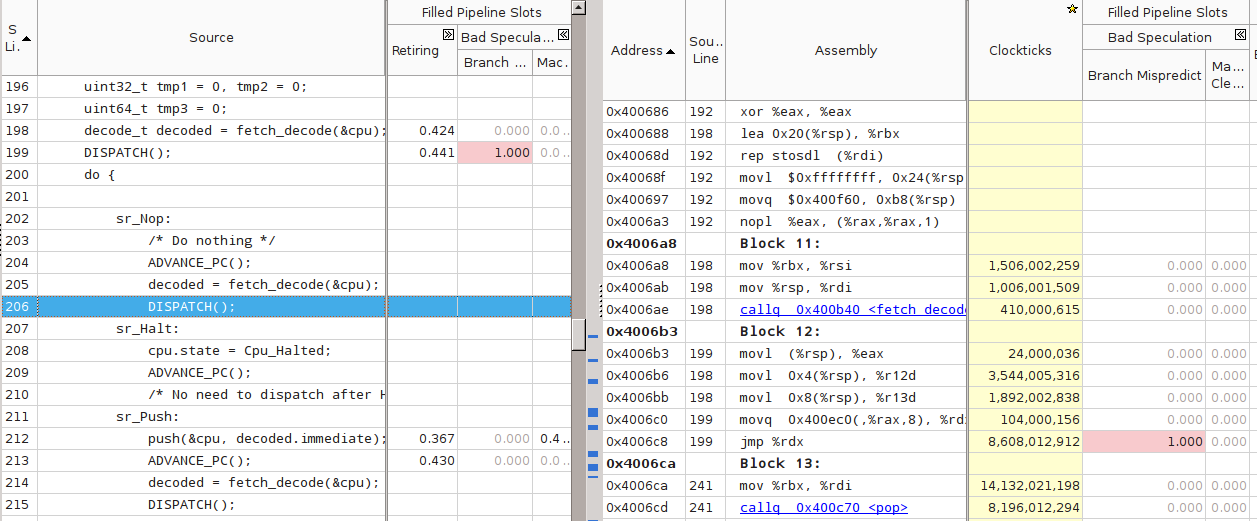
However, something is wrong here - for all other DISPATCH there are no statistics at all. Moreover, VTune does not show an assembly code for them. The objdump check by disassembling confirmed the suspicions - there was only one indirect transition in the whole body of main (), associated with the transition to service procedures:
$ objdump -d threaded-notune | grep 'jmpq \ s * \ *% rdx' 4006c8: ff e2 jmpq *% rdx 400ae7: ff e2 jmpq *% rdx
(The second jmpq at address 400ae7 - from the register_tm_clones function - is irrelevant). What turns out - the GCC compiler as a result of the optimization process helpfully slammed all the DISPATCH into one, in fact having rebuilt the switchable interpreter!
The compiler is a sworn friend
This is where my struggle with the compiler began. I spent a lot of time to get GCC to generate code with independent indirect transitions for each service procedure.
- Checked different levels of optimization. The correct code was obtained only with -Og, the levels of optimizations from -O1 to -O3 collapsed DISPATCH.
- I tried to replace goto with assembly insertion and thus hide the fact of switching from the compiler to the label:
#define DISPATCH () \ __asm__ __volatile __ ("mov (% 0,% 1, 8), %% rcx \ n" \ "jmpq * %% rcx \ n" \ :: "r"(&service_routines), "r"((uint64_t)decoded.opcode): "%rcx");
. (sr_Add, sr_Nop ..) , service_routines . . - service_routines - , : . . GCC DISPATCH !
, , , .
, . - , . :
Please note the warning under -fgcse about invoking -O2 on programs that use computed gotos .
<...>
Note: When compiling a program using computed gotos, a GCC extension, you may get better run-time performance if you disable the global common subexpression elimination pass by adding -fno-gcse to the command line.
! -fgcse threaded . , , . , «Fast interpreter using gcc's computed goto»:
I have the same problem as Philip. With G++ the compiler seems to go though incredible contortions to preserve a single indirect jump. Even going so far as to combine jumps from separate jump tables — with a series of direct jumps. This seems utterly bewildering behaviour as it specially breaks the performance gain having a jmp \*%eax for each interpreter leg.
-fno-gcse , :
threaded c objdump
$ objdump -d threaded| grep 'jmpq\s*\*%rdx' 4006c8: ff e2 jmpq *%rdx 40070d: ff e2 jmpq *%rdx 40084e: ff e2 jmpq *%rdx 4008bd: ff e2 jmpq *%rdx 40093d: ff e2 jmpq *%rdx 4009b1: ff e2 jmpq *%rdx 400a3b: ff e2 jmpq *%rdx 400aa2: ff e2 jmpq *%rdx 400b15: ff e2 jmpq *%rdx 400b89: ff e2 jmpq *%rdx 400c0b: ff e2 jmpq *%rdx 400c80: ff e2 jmpq *%rdx 400cd8: ff e2 jmpq *%rdx 400d3f: ff e2 jmpq *%rdx 400d90: ff e2 jmpq *%rdx 400dea: ff e2 jmpq *%rdx 400e44: ff e2 jmpq *%rdx 400e8c: ff e2 jmpq *%rdx 400f97: ff e2 jmpq *%rdx
, . , . , — , .. «» . , , DISPATCH , , - . .
threaded . — . .
(subroutined)
goto . — ( subroutined.c). service_routine_t:
typedef void (*service_routine_t)(cpu_t *pcpu, decode_t* pdecode);
:
void sr_Dec(cpu_t *pcpu, decode_t *pdecoded) {
uint32_t tmp1 = pop(pcpu);
BAIL_ON_ERROR();
push(pcpu, tmp1-1);
}
service_routines[] :
service_routines
service_routine_t service_routines[] = {
&sr_Break, &sr_Nop, &sr_Halt, &sr_Push, &sr_Print,
&sr_Jne, &sr_Swap, &sr_Dup, &sr_Je, &sr_Inc,
&sr_Add, &sr_Sub, &sr_Mul, &sr_Rand, &sr_Dec,
&sr_Drop, &sr_Over, &sr_Mod, &sr_Jump
};
. , .
main() subroutined
while (cpu.state == Cpu_Running && cpu.steps < steplimit) {
decode_t decoded = fetch_decode(&cpu);
if (cpu.state != Cpu_Running) break;
service_routines[decoded.opcode](&cpu, &decoded); /* Call the SR */
cpu.pc += decoded.length; /* Advance PC */
cpu.steps++;
}
VTune — :

, subroutined switched. , — . subroutined . «, — !». .
(tailrecursive)
, … — !
tailrecursive.c. subroutined.c .
fetch_decode() DISPATCH():
void sr_Dec(cpu_t *pcpu, decode_t *pdecoded) {
uint32_t tmp1 = pop(pcpu);
BAIL_ON_ERROR();
push(pcpu, tmp1-1);
ADVANCE_PC();
*pdecoded = fetch_decode(pcpu);
DISPATCH();
}
DISPATCH:
#define DISPATCH() service_routines[pdecoded->opcode](pcpu, pdecoded);
, , . main(), , :
decode_t decoded = fetch_decode(&cpu); service_routines[decoded.opcode](&cpu, &decoded);
And that's all. . , , , — …
, ?! , , , , . However, this does not happen.
, — . — . . call jmp, .
GCC -foptimize-sibling-calls (, -O1). ( tailrecursive-noopt), , . 90000 :
$ ./tailrecursive-noopt 90000 > /dev/null Segmentation fault (core dumped)
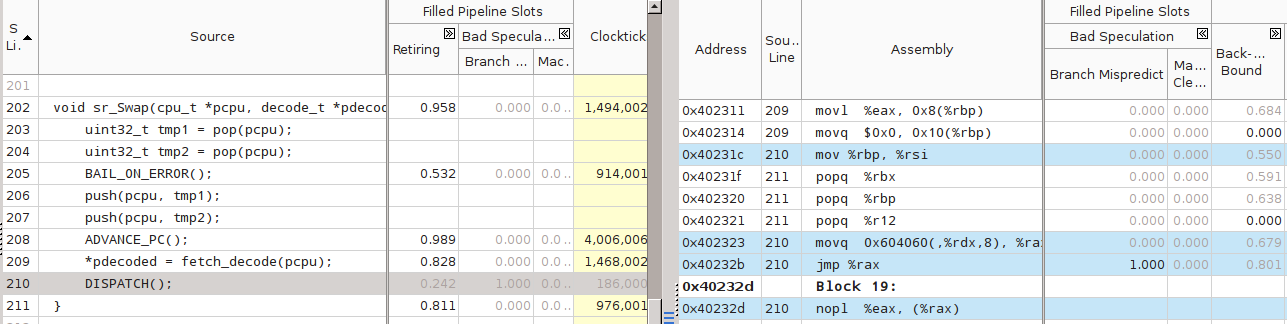
tailrecursive VTune . -, «» fetch(_decode) decode:

, ( ) .
-, , call jmpq. , sr_Swap(), Branch Mispredict:
(binary translation)
, , ( translated.c). : , (). , , translated . , , , , .
. — , POSIX-.
, , . , : Ubuntu 12.04 Windows 8.1 (Cygwin). . translated Cygwin — mprotect() «Invalid argument».
translated Intel 64 (x86_64, AMD64, x64... ), . translate_program() .
«», -. . .
.
#ifndef __x86_64__ /* The program generates machine code, only specific platforms are supported */ #error This program is designed to compile only on Intel64/AMD64 platform. #error Sorry. #endif
, Intel 64. .
pcpu R15
/* Global pointer to be accessible from generated code.
Uses GNU extension to statically occupy host R15 register. * /
register cpu_t * pcpu asm("r15");
cpu_t, , R15. GNU- , -std=gnu11 ( Makefile), — -std=c11.
char gen_code[JIT_CODE_SIZE] __attribute__ ((section (".text#")))
__attribute__ ((aligned(4096)));
gen_code . -, . -, (.text), (.data), - . , , . gen_code — .text .
static void enter_generated_code(void* addr) {
__asm__ __volatile__ ( "jmp *%0"::"r"(addr):);
}
static void exit_generated_code() {
longjmp(return_buf, 1);
}
gen_code. longjmp() — goto ( goto ). , , setjmp() c (return_buf).
, . exit_generated_code() , Halted/Break, PC. , , , — longjmp .
void sr_Drop() {
(void)pop(pcpu);
ADVANCE_PC(1);
}
void sr_Je(int32_t immediate) {
uint32_t tmp1 = pop(pcpu);
if (tmp1 == 0)
pcpu->pc += immediate;
ADVANCE_PC(2);
if (tmp1 == 0) /* Non-sequential PC change */
exit_generated_code ();
}
, (, Drop), pcpu. (, Je) . , ABI . System V ABI ( Linux) — RDI.
Translate_program code ()
static void translate_program (const Instr_t * prog, char * out_code, void ** entrypoints, int len) {assert (prog); assert (out_code); assert (entrypoints); / * An IA-32 instruction "MOV RDI, imm32" is used by the following CALL. * / #ifdef __CYGWIN__ / * Win64 ABI, use RCX instead of RDI * / const char mov_template_code [] = {0x48, 0xc7, 0xc1, 0x00, 0x00, 0x00, 0x00}; #else const char mov_template_code [] = {0x48, 0xc7, 0xc7, 0x00, 0x00, 0x00, 0x00}; #endif const int mov_template_size = sizeof (mov_template_code); / * An IA-32 instruction "CALL rel32" is used as a route to invoke service routines. A template for it is "call. + 0x00000005" * / const char call_template_code [] = {0xe8, 0x00, 0x00, 0x00, 0x00}; const int call_template_size = sizeof (call_template_code); int i = 0; / * Address * current guest instruction * / char * cur = out_code; / * Where to put new code * / / * The program is short. Otherwise, some sort of lazy decoding will be required * / while (i <len) {decode_t decoded = deco_at_address (prog, i); entrypoints [i] = (void *) cur; if (decoded.length == 2) {/ * Guest instruction has an immediate * / assert (cur + mov_template_size - out_code <JIT_CODE_SIZE); memcpy (cur, mov_template_code, mov_template_size); / * Patch template with the correct value * / memcpy (cur + 3, & decoded.immediate, 4); cur + = mov_template_size; } assert (cur + call_template_size - out_code <JIT_CODE_SIZE); memcpy (cur, call_template_code, call_template_size); intptr_t offset = (intptr_t) service_routines [decoded.opcode] - (intptr_t) cur - call_template_size; if (offset! = (intptr_t) (int32_t) offset) {fprintf (stderr, "it doesn’t fit in 32 bits. Cannot generate code for it, sorry", decoded.opcode); exit (2); } uint32_t offset32 = (uint32_t) offset; / * Patch template with correct offset * / memcpy (cur + 1, & offset, 4); i + = decoded.length; cur + = call_template_size; }} The most difficult block of the program requires detailed consideration. As a result of the work of the guest program prog length len, two arrays must be filled: out_code — the host guest code simulating a sequence of instructions from prog, and an array of entrypoints at the beginning of the individual capsules inside out_code.
Each guest instruction is decoded, and then translated into one or two host instructions. For guest instructions without operands, this is “call rel32”; for instructions with operand, the pair is “mov imm,% rdi; call rel32 ". RDI is here because the called procedures expect to see their argument in it.
rel32 is a 32-bit offset of the address of the function being called with respect to the current instruction. For each new CALL instruction, it is different, so it is calculated each time (offset32) relative to the current position.
Why did I use relative addresses here, not absolute ones? Because the host system uses 64-bit addresses, and to transfer 64 bits to the CALL, one more instruction and one more register would be required. Because of this, the gen_code is placed in the code section - so that all offsets fit into 32 bits. After all, the data section can be placed very far from the code.
Notice that both the template code (mov_template_code and call_template_code) and the subsequent manipulations with them (calls to memcpy ()) depend on the way in which the host instructions are encoded. When porting translated to another architecture, they will have to be fixed first.
The result of the translation of the program Primes, obtained using GDB at the time of the completion of translate_program ():
Master code for Primes
(gdb) disassemble gen_code, gen_code + 4096
Dump of assembler code from 0x403000 to 0x404000:
0x0000000000403000 <gen_code + 0>: mov $ 0x186a0,% rdi
0x0000000000403007 <gen_code + 7>: callq 0x4020c0 <sr_Push>
0x000000000040300c <gen_code + 12>: mov $ 0x2,% rdi
0x0000000000403013 <gen_code + 19>: callq 0x4020c0 <sr_Push>
0x0000000000403018 <gen_code + 24>: callq 0x4029a0 <sr_Over>
0x000000000040301d <gen_code + 29>: callq 0x4029a0 <sr_Over>
0x0000000000403022 <gen_code + 34>: callq 0x402720 <sr_Sub>
0x0000000000403027 <gen_code + 39>: mov $ 0x17,% rdi
0x000000000040302e <gen_code + 46>: callq 0x4021a0 <sr_Je>
0x0000000000403033 <gen_code + 51>: mov $ 0x2,% rdi
0x000000000040303a <gen_code + 58>: callq 0x4020c0 <sr_Push>
0x000000000040303f <gen_code + 63>: callq 0x4029a0 <sr_Over>
0x0000000000403044 <gen_code + 68>: callq 0x4029a0 <sr_Over>
0x0000000000403049 <gen_code + 73>: callq 0x4027e0 <sr_Swap>
0x000000000040304e <gen_code + 78>: callq 0x402720 <sr_Sub>
0x0000000000403053 <gen_code + 83>: mov $ 0x9,% rdi
0x000000000040305a <gen_code + 90>: callq 0x4021a0 <sr_Je>
0x000000000040305f <gen_code + 95>: callq 0x4029a0 <sr_Over>
0x0000000000403064 <gen_code + 100>: callq 0x4029a0 <sr_Over>
0x0000000000403069 <gen_code + 105>: callq 0x4027e0 <sr_Swap>
0x000000000040306e <gen_code + 110>: callq 0x4028c0 <sr_Mod>
0x0000000000403073 <gen_code + 115>: mov $ 0x5,% rdi
0x000000000040307a <gen_code + 122>: callq 0x4021a0 <sr_Je>
0x000000000040307f <gen_code + 127>: callq 0x402300 <sr_Inc>
0x0000000000403084 <gen_code + 132>: mov $ 0xfffffffffffffff1,% rdi
0x000000000040308b <gen_code + 139>: callq 0x402080 <sr_Jump>
0x0000000000403090 <gen_code + 144>: callq 0x4029a0 <sr_Over>
0x0000000000403095 <gen_code + 149>: callq 0x402460 <sr_Print>
0x000000000040309a <gen_code + 154>: callq 0x4022a0 <sr_Drop>
0x000000000040309f <gen_code + 159>: callq 0x402300 <sr_Inc>
0x000000000040a4 <gen_code + 164>: mov $ 0xffffffffffffffe4,% rdi
0x00000000004030ab <gen_code + 171>: callq 0x402080 <sr_Jump>
0x00000000004030b0 <gen_code + 176>: callq 0x402060 <sr_Halt>
0x00000000004030b5 <gen_code + 181>: callq 0x4020a0 <sr_Break>
0x00000000004030ba <gen_code + 186>: callq 0x4020a0 <sr_Break>
0x00000000004030bf <gen_code + 191>: callq 0x4020a0 <sr_Break>
0x00000000004030c4 <gen_code + 196>: callq 0x4020a0 <sr_Break>
0x00000000004030c9 <gen_code + 201>: callq 0x4020a0 <sr_Break>
0x00000000004030ce <gen_code + 206>: callq 0x4020a0 <sr_Break>
<...>
Once again I note: at the time of the start of the translation of this code did not exist.
Of course, instead of calling them endlessly, it would be better to substitute the bodies of the service procedures themselves in out_code. At the same time, the input and output time in the function would be saved. But I would have to do something with the epilogue prologues of the procedures, i.e. Learn to inline code behind the compiler. I will leave this exercise to readers who want to get deeper into the issues of code generation.
Finally, let's examine what is happening in main ():
main () inside translate
/ * Code section is protected from default, un-protect it * /
if (mprotect (gen_code, JIT_CODE_SIZE, PROT_READ | PROT_WRITE | PROT_EXEC)) {
perror ("mprotect");
exit (2);
}
/ * Pre-populate resulting code buffer with INT3 (machine code 0xCC).
This will help to catch jumps to wrong locations * /
memset (gen_code, 0xcc, JIT_CODE_SIZE);
void * entrypoints [PROGRAM_SIZE] = {0}; / * a map of guest PCs to capsules * /
translate_program (cpu.pmem, gen_code, entrypoints, PROGRAM_SIZE);
setjmp (return_buf); / * Will get here from generated code. * /
while (cpu.state == Cpu_Running && cpu.steps <steplimit) {
if (cpu.pc> PROGRAM_SIZE) {
cpu.state = Cpu_Break;
break;
}
enter_generated_code (entrypoints [cpu.pc]); / * Will not return * /
}
First, it is imperative that you allow writing to gen_code. This is done using the mprotect () system call. Then just in case, fill in the gen_code with the whole INT3 single-byte instruction - 0xcc. If something goes wrong when executing the generated code, and the control is transferred to the empty part of the array, an interrupt will occur immediately, which will make debugging easier.
Then we broadcast the program and set the return point with setjmp (). It is here, at the beginning of the while () loop, that execution will be returned.
The while loop will each time transfer control using the values from the display of the entrypoints for the current PC as the address. Perhaps the question arose - why bother exiting gen_code before the generated code ends?
Pay your attention once again to the listing of gen_code above. There is no branch instruction in it - all MOV and CALL will be executed sequentially. However, the original program had cycles!
The translation of the guest transition instructions is a difficult point: the displacements of the addresses of the guest code are generally non-linearly related to the displacements between the capsules of the master code. I circumvented this difficulty using the following trick. All service procedures that change the PC in a non-linear manner (ie, Jump, JE, JNE) are required to call exit_generated_code (). And already the external code, using the saved values in the entrypoints, will re-enter the guest code at the correct address. For the rest, "normal" service procedures, longjmp is not needed - they just fall through to the next procedure code.
I have an idea how to do without longjmp inside the procedures for JNE, JE and Jump. You can find the next entry point from entrypoints right inside the procedure, and put the additional value of the return address of the RIP on the stack so that when you exit the current procedure, you will not be in the function that called it, but immediately in the desired procedure! Another exercise for the inquisitive reader is to implement this idea.
Bottlenecks have changed. Now VTune has designated the main problem “Front End Bound”:

At the top of the list are service procedures, which can be considered to some extent a success:

Note that for a dynamically generated code, VTune is not expected to associate character information. However, this tool provides the JIT Profiling API , which allows you to mark the entry and exit to the regions of the generated code. translated does not use it, but it would obviously be useful for serious profiling.
Who is measuring
For test runs, the old, but still smart Lenovo Thinkpad X220i notebook was used.
- OS: Ubuntu 12.04.5 LTS, Linux version 3.2.0-75-generic x86_64
- Processor: Intel® Core (TM) i3-2310M CPU @ 2.10GHz
- 4 GB of RAM
Compilers:
- GCC 4.8.1-2ubuntu1 ~ 12.04
- ICC 15.0.3 20150407
Compare options for programs.
- switched - switchable interpreter.
- threaded - sewn interpreter.
- predecoded - the pre-decoded switchable interpreter.
- subroutined - the procedural interpreter.
- threaded-cached is a pre-decoded interpreter.
- tailrecursive is a procedural interpreter with optimized tail calls.
- translated - binary translator.
- native is an implementation of the Primes C algorithm. It is not quite fair to compare a static program with implementations of a VM capable of executing arbitrary code. However, in comparison, the native participates to show the potential for possible acceleration.
The experiments were automated using the measure.sh script. For each option, the execution time of the five program runs was measured and the average value was calculated.
For GCC:

predecoded runs only slightly faster than switched. For reasons unknown to me, simple threaded and remained slower switched. But the combination of pre-decoding with threaded code, threaded-cached, gave a noticeable increase. The procedural interpreter subroutined and procedural with tail optimizations tailrecursive have shown themselves remarkably well. It was also expected that the translated bypassed all the interpreters.
For ICC:

These results are even stranger. Absolutely the worst result showed threaded, despite all my efforts. predecoded, on the contrary, is so fast that I had doubts about the correctness of its execution. However, additional checks and repeated measurements found no problems. threaded-cached bypassed procedural options in speed, almost equaling translated, which, in turn, is not the fastest.
I note that the ICC did not understand my attempts to help with the generation of the code for the sewn variants, since not all the GCC options he understands:
icc -std = c11 -O2 -Wextra -Werror -gdwarf-3 -fno-gcse -fno-thread-jumps -fno-cse-follow-jumps -fno-crossjumping -fno-cse-skip-blocks -fomit-frame- pointer threaded-cached.c -o threaded-cached icc: command line warning # 10006: ignoring unknown option '-fno-gcse' icc: command line warning # 10006: ignoring unknown option '-fno-thread-jumps' icc: command line warning # 10006: ignoring unknown option '-fno-cse-follow-jumps' icc: command line warning # 10006: ignoring unknown option '-fno-crossjumping' icc: command line warning # 10006: ignoring unknown option '-fno-cse-skip-blocks'
Of course, it would be very interesting to study the causes of anomalies found on ICC assemblies. But the article and without it swelled to indecent size, so let me postpone this analysis for the next time.
Conclusion
As expected, various interpreter construction techniques vary in speed. However, it is impossible to advance, only from the structure of the VM code, to draw conclusions about which of the options will be faster in practice. Moreover, various techniques can be combined, but the effects that arise in this case are not cumulative: see how performance changes when using only pre-decoding or sewn code, and what effect is obtained from their sharing.
A significant, and not always positive, role is played by the compiler. Depending on the optimizations applied by them, a very simple interpretation scheme can show itself well, but a super-elaborated one will end up in the tail of the list.
The article is written, my conscience is clear to myself, it's time to go on vacation. Thanks for attention!
Literature
- Baranov S. N., Nozdrunov N. R. Language Fort and its implementation. 1988 Mechanical Engineering Publishing House 2.1. Sewn code and its versions www.netlib.narod.ru/library/book0001/ch02_01.htm
- M. Anton Ertl. 2007. Speed of various interpreter dispatch techniques V2 www.complang.tuwien.ac.at/forth/threading
- James E. Smith and Ravi Nair. Virtual machines - Versatile Platforms for Systems and Processes. Elsevier, 2005. ISBN 978-1-55860-910-5.
- M. Anton Ertl and David Gregg. Efficient interpreters // Journal of Instruction-Level Parallelism 5 (2003), pp. 1-25. www.jilp.org/vol5/v5paper12.pdf
- Terrence Parr. Language Implementation Patterns - The Pragmatic Bookshelf, 2010. ISBN-10: 1-934356-45-X ISBN-13: 978-1-934356-45-6
Source: https://habr.com/ru/post/261665/
All Articles