Typical interlocks in MS SQL and ways to deal with them
Most often deadlock is described approximately as follows:
Process 1 locks resource A.
Process 2 blocks the resource B.
Process 1 is trying to access resource B.
Process 2 is attempting to access resource A.
As a result, one of the processes must be interrupted so that the other can continue execution.
But this is the simplest variant of mutual blocking, in reality one has to deal with more complicated cases. In this article we will tell you what kind of deadlocks in MS SQL we had to meet and how we fight them.

When using such complex DBMS as MS SQL, it is necessary to understand how and what resources block typical queries and how this is affected by the isolation levels of the transaction.
For those who have a bad understanding of this, we recommend reading the following articles:
When using transactions with a serializable isolation level, any interlocks can occur. When using the repeatable read isolation level, some of the deadlocks described below cannot occur. For transactions with read committed isolation levels, only simple interlocks can occur. A transaction with an isolation level of read uncommitted has virtually no effect on the speed of other transactions, and interlocks cannot occur due to reading, as it does not impose shared locks (although there may be interlocks with transactions that modify the database schema).
Transaction isolation levels greatly affect the speed of the system and without taking into account interlocks, so it is very important to choose the right isolation level depending on the task that the transaction performs. Here are some tips:
In a fairly complex system, which has dozens of different types of business transactions, it is unlikely that you will be able to design all transactions in such a way that the deadlock cannot occur under any circumstances. It is not worth spending time preventing mutual locks, the likelihood of which is extremely small. But in order not to spoil the user experience, in the case when the operation is interrupted due to interlocking, it needs to be repeated. In order for the operation to be safely repeated, it does not have to change the input data and must be wrapped in one transaction (or instead of the entire operation, you must wrap each SQL transaction in an operation in RetryOnDeadlock).
')
Here is an example of the C # RetryOnDeadlock function:
It is important to understand that the RetryOnDeadlock function only improves the user experience when occasional deadlocks occur. If they occur very often, it will only worsen the situation, at times increasing the load on the system.
If a deadlock occurs because the two processes access the same resources but in a different order (as described at the beginning of the article), then it is enough to change the order of blocking resources. In principle, if a certain set of resources are blocked in different operations, the same resource should always be blocked first , if possible. This advice applies not only to relational databases, but generally to any systems in which interlocks occur.
When applied to MS SQL, this advice can be slightly simplified as follows: in different transactions that change several tables, the same table should be changed first.
The most common deadlock in our practice occurs in a transaction with an isolation level of Repeatable read or Serializable as follows:
For the occurrence of such mutual blocking, one resource is enough, for which two transactions of the same type compete. The fight can be fought not only for one record but also for any other resource. For example, if two Serializable transactions consider the number of records with a specific value, and then insert a record with the same value, then the resource, the release of which they are waiting for, will be the key in the index.
To avoid such mutual blocking, it is necessary that only one of the two transactions that are going to change the record be read. Especially for this update was introduced lock. It can be applied as follows:
If you use ORM and cannot control how the entity is requested from the database, then you will have to execute a separate query in pure SQL to lock the record before requesting it from the database. It is important that the overlaying update request must be the first request that accesses this record in this transaction, otherwise the same deadlock will occur, but when you try to impose an update lock, and not when the record is changed.
By imposing an update lock, we force all transactions that refer to the same resource to be performed in turn, but usually transactions that change the same resource cannot be done in parallel in principle, so this is normal.
Such a deadlock can occur in any transaction that checks data before changing it, but for rarely changing entities, you can use RetryOnDeadlock. The approach with pre-update blocking is enough to use only for entities that are often changed by different processes in parallel.
Example
Users order prizes for points. The number of prizes of each type is limited. The system should not allow to order more prizes than is available. Due to the peculiarities of the promotion, there are occasional raids by users who want to order the same prize. If you use RetryOnDeadlock in this situation, then during the raid of users the order of the prize in most cases will fall on the web timeout.
If we store the number of remaining prizes in the record of the prize type, the prize order transaction should look like this:
Thus, we allow at one moment to order the same type of prize to only one user. All user requests to order the same type of prize are lined up, but this approach gives a better user experience than RetryOnDeadlock or error output to the consumer in the event of a deadlock.
If you do not store the number of remaining prizes, and calculate it based on the number of prizes ordered, then you can apply the update lock when calculating the number of prizes ordered. It will look something like this:
Most of the deadlocks described below occur in a similar way - we are trying to change the data after we impose a Shared lock on them. But in each of these cases there are some nuances.
If we are in a serializable transaction looking for a record on a field that is not included in any index, then the shared lock will be imposed on the entire table. Otherwise, one cannot make sure that no other transaction can insert an entry with the same value until the current transaction is completed. As a result, any transaction sampling on this field, and then changing this table, will mutually block with any similar transaction.
If we add an index on this field (or an index on several fields, the first of which is the field on which we are looking), then the key in this index will be blocked. So in serializable transactions it is even more important to think whether there is an index on the columns for which you are looking for records.
There is one more nuance about which it is important to remember: if the index is unique, then the lock is imposed only on the requested key, and if it is nonunique, the value following this key is also blocked. Two transactions requesting different entries by a non-unique index, and then modifying them, can mutually block if adjacent key values are requested. This is usually a rare situation and it is enough to use RetryOnDeadlock to avoid problems, but in some cases it may be necessary to impose an update lock when pulling records using a non-unique key.
Example
We need to check if there is a user with such an Id on Facebook in the database before adding it. Since we are working with a single line in the database, it seems that only it will be blocked and the probability of interlocking is small. However, if you try to select a non-existent value in a transaction with the isolation level Serializable (and this column is included in the index), then a shared lock will be imposed on all keys between the two closest values that are in the table. For example, if the database has Id 15 and Id 1025, and there are no values between them, then when you execute SELECT * FROM Users WHERE FacebookId = 500, the Shared lock is imposed on the keys from 15 to 1025. If, prior to insertion, another transaction checks whether a user with FacebookId = 600 and tries to insert it, then a deadlock occurs. If there are already many users in the database who have FacebookId full, then the probability of interlocking will be small and we only need to use RetryOnDeadlock. But if you perform many such transactions on an almost empty database, then deadlocks will occur often enough to greatly affect performance.
We have this problem when parallel import of consumers from new customers (for each customer we create a new empty database). Since we are currently satisfied with the speed of single-threaded import, we simply turned off parallelism. But in principle, the problem is solved as well as in the above example, you need to use the update block:
In this case, when multithreaded imports into an empty database, at the beginning, the threads will be idle, waiting for the lock to be released, but as the base is filled, the degree of parallelism will increase. Although if the imported data is ordered by FacebookId, in parallel to import them will not work. When importing into an empty database, such ordering should be avoided (or not to check the presence of users in the database on FacebookId during the first import).
If you have a complex aggregate in your system, the data of which is stored in several tables, and there are many transactions that change different parts of this aggregate in parallel, then you need to build all these transactions in such a way that they do not interlock each other.
Example
The database stores personal data of the consumer, his identifiers in social networks, orders in the online store, records of letters sent to him.
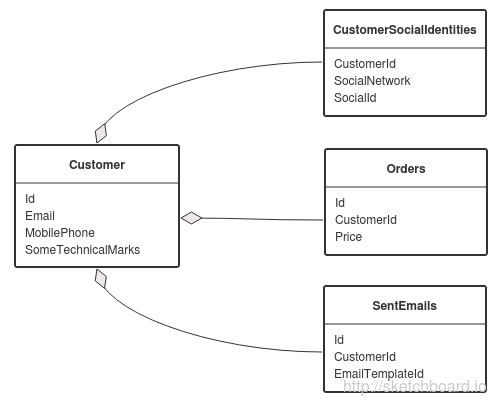
Transactions that add an identifier to the social network, send letters and register purchases can also change technical fields in the main consumer record. In any of these transactions there is a consumer Id.
To avoid deadlocks, you need to start any transaction with the following query:
In this case, at one time only one transaction will be able to change the data related to a specific consumer and interlocks will not occur regardless of how complex the consumer’s aggregate is.
You can try to change the data storage scheme so that transactions, sending letters and registering purchases do not change technical notes in the consumer. Then information about orders and sent letters can be changed in parallel with the change of the consumer. In this case, we actually take this data out of the “consumer” aggregate.
To summarize, tips for working with aggregates can be described as follows:
These tips, of course, are not a panacea for mutual interlocks, but can greatly facilitate your life.
Such interlocks occur under very specific conditions, but we did encounter them a couple of times, so it's worth telling about them too.
Example
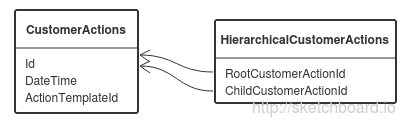
When sending a letter from DirectCRM to the email gateway, the consumer is given an action about the fact of sending (one entry in the database). An action id is a regular identity, incremented by one for each subsequent entry. When a letter is successfully sent to the mail server, the email gateway reports this to DirectCRM, and CRM issues an action about the successful sending of the letter that refers to the action about the fact of sending (the link is stored in the HierarchicalCustomerActions table). In order for the operation of processing a message from the email gateway to be idempotent (why you need to read it in the previous article ), we check if there was an action about successful sending before this (in a serializable transaction). With such a check, a shared lock is imposed on the key in the index by RootCustomerActionId, corresponding to the fact of sending the letter. But the sending action is the first to refer to the fact of sending and at the time of its issuance there is not a single entry in the HierarchicalCustomerActions table with such a RootCustomerActionId. Therefore, a shared lock will be imposed on all keys between the two existing ones. Since the action Id is an identity, very often the RootCustomerActionId checked is greater than any of those already in the table and the lock is imposed on all keys greater than or equal to the maximum RootCustomerActionId value in the table. In an email gateway, sending a message occurs in several streams, and as a result, the following situation often occurs:
If you apply an update lock when requesting HierarchicalCustomerActions, then there will be no deadlocks, but there will be no parallel processing either - all transactions will wait until the transaction that imposed the update lock ends.
There are the following solutions to this problem:
Process 1 locks resource A.
Process 2 blocks the resource B.
Process 1 is trying to access resource B.
Process 2 is attempting to access resource A.
As a result, one of the processes must be interrupted so that the other can continue execution.
But this is the simplest variant of mutual blocking, in reality one has to deal with more complicated cases. In this article we will tell you what kind of deadlocks in MS SQL we had to meet and how we fight them.
Some theory
When using such complex DBMS as MS SQL, it is necessary to understand how and what resources block typical queries and how this is affected by the isolation levels of the transaction.
For those who have a bad understanding of this, we recommend reading the following articles:
Select transaction isolation level
When using transactions with a serializable isolation level, any interlocks can occur. When using the repeatable read isolation level, some of the deadlocks described below cannot occur. For transactions with read committed isolation levels, only simple interlocks can occur. A transaction with an isolation level of read uncommitted has virtually no effect on the speed of other transactions, and interlocks cannot occur due to reading, as it does not impose shared locks (although there may be interlocks with transactions that modify the database schema).
Transaction isolation levels greatly affect the speed of the system and without taking into account interlocks, so it is very important to choose the right isolation level depending on the task that the transaction performs. Here are some tips:
- If the transaction changes the data in the database and at the same time checks that this data does not contradict the already existing records in the database, then most likely it needs a serializable isolation level. But if inserting new records in parallel transactions can in no way affect the result of the current transaction, then you can use the isolation level repeatable read.
- To read data, it is usually sufficient to use the default isolation level (read committed) without any transaction. However, when reading aggregates, parts of which can be changed during reading, you may need to use a transaction with an isolation level of repeatable read or even serializable, otherwise you can get an aggregate from the database in an incorrect state, in which it can only be in the process of executing a change transaction.
- If you need to display real time statistics on constantly changing data, it is often better to use the read uncommitted isolation level. In this case, the statistics will have a certain amount of dirty data (although this is unlikely to be noticeable), but the construction of reports will have almost no effect on the speed of the system.
Retry on deadlock
In a fairly complex system, which has dozens of different types of business transactions, it is unlikely that you will be able to design all transactions in such a way that the deadlock cannot occur under any circumstances. It is not worth spending time preventing mutual locks, the likelihood of which is extremely small. But in order not to spoil the user experience, in the case when the operation is interrupted due to interlocking, it needs to be repeated. In order for the operation to be safely repeated, it does not have to change the input data and must be wrapped in one transaction (or instead of the entire operation, you must wrap each SQL transaction in an operation in RetryOnDeadlock).
')
Here is an example of the C # RetryOnDeadlock function:
private const int DefaultRetryCount = 6; private const int DeadlockErrorNumber = 1205; private const int LockingErrorNumber = 1222; private const int UpdateConflictErrorNumber = 3960; private void RetryOnDeadlock( Action<DataContext> action, int retryCount = DefaultRetryCount) { if (action == null) throw new ArgumentNullException("action"); var attemptNumber = 1; while (true) { var dataContext = CreateDataContext(); try { action(dataContext); break; } catch (SqlException exception) { if(!exception.Errors.Cast<SqlError>().Any(error => (error.Number == DeadlockErrorNumber) || (error.Number == LockingErrorNumber) || (error.Number == UpdateConflictErrorNumber))) { throw; } else if (attemptNumber == retryCount + 1) { throw; } } finally { dataContext.Dispose(); } attemptNumber++; } } It is important to understand that the RetryOnDeadlock function only improves the user experience when occasional deadlocks occur. If they occur very often, it will only worsen the situation, at times increasing the load on the system.
Fight against simple interlocks
If a deadlock occurs because the two processes access the same resources but in a different order (as described at the beginning of the article), then it is enough to change the order of blocking resources. In principle, if a certain set of resources are blocked in different operations, the same resource should always be blocked first , if possible. This advice applies not only to relational databases, but generally to any systems in which interlocks occur.
When applied to MS SQL, this advice can be slightly simplified as follows: in different transactions that change several tables, the same table should be changed first.
Shared-> Exclusive lock escalation
The most common deadlock in our practice occurs in a transaction with an isolation level of Repeatable read or Serializable as follows:
- Transaction 1 reads a record (an S-lock is applied).
- Transaction 2 reads the same record (a second S-lock is imposed).
- Transaction 1 tries to change the record and waits for Transaction 2 to end and release its S-lock.
- Transaction 2 tries to change the same record and waits for Transaction 1 to end and release its S-lock.
For the occurrence of such mutual blocking, one resource is enough, for which two transactions of the same type compete. The fight can be fought not only for one record but also for any other resource. For example, if two Serializable transactions consider the number of records with a specific value, and then insert a record with the same value, then the resource, the release of which they are waiting for, will be the key in the index.
To avoid such mutual blocking, it is necessary that only one of the two transactions that are going to change the record be read. Especially for this update was introduced lock. It can be applied as follows:
SELECT * FROM MyTable WITH (UPDLOCK) WHERE Id = @Id If you use ORM and cannot control how the entity is requested from the database, then you will have to execute a separate query in pure SQL to lock the record before requesting it from the database. It is important that the overlaying update request must be the first request that accesses this record in this transaction, otherwise the same deadlock will occur, but when you try to impose an update lock, and not when the record is changed.
By imposing an update lock, we force all transactions that refer to the same resource to be performed in turn, but usually transactions that change the same resource cannot be done in parallel in principle, so this is normal.
Such a deadlock can occur in any transaction that checks data before changing it, but for rarely changing entities, you can use RetryOnDeadlock. The approach with pre-update blocking is enough to use only for entities that are often changed by different processes in parallel.
Example
Users order prizes for points. The number of prizes of each type is limited. The system should not allow to order more prizes than is available. Due to the peculiarities of the promotion, there are occasional raids by users who want to order the same prize. If you use RetryOnDeadlock in this situation, then during the raid of users the order of the prize in most cases will fall on the web timeout.
If we store the number of remaining prizes in the record of the prize type, the prize order transaction should look like this:
- We get a record of the prize type, imposing update blocking.
- Check the number of remaining prizes. If it is 0, terminate the transaction and return the appropriate response to the user.
- If there are still prizes, reduce the number of remaining prizes by 1.
- Add a record of the ordered prize.
Thus, we allow at one moment to order the same type of prize to only one user. All user requests to order the same type of prize are lined up, but this approach gives a better user experience than RetryOnDeadlock or error output to the consumer in the event of a deadlock.
If you do not store the number of remaining prizes, and calculate it based on the number of prizes ordered, then you can apply the update lock when calculating the number of prizes ordered. It will look something like this:
SELECT count(*) FROM OrderedPrizes WITH (UPDLOCK) WHERE PrizeId = @PrizeId Most of the deadlocks described below occur in a similar way - we are trying to change the data after we impose a Shared lock on them. But in each of these cases there are some nuances.
Samples by non-indexable fields
If we are in a serializable transaction looking for a record on a field that is not included in any index, then the shared lock will be imposed on the entire table. Otherwise, one cannot make sure that no other transaction can insert an entry with the same value until the current transaction is completed. As a result, any transaction sampling on this field, and then changing this table, will mutually block with any similar transaction.
If we add an index on this field (or an index on several fields, the first of which is the field on which we are looking), then the key in this index will be blocked. So in serializable transactions it is even more important to think whether there is an index on the columns for which you are looking for records.
There is one more nuance about which it is important to remember: if the index is unique, then the lock is imposed only on the requested key, and if it is nonunique, the value following this key is also blocked. Two transactions requesting different entries by a non-unique index, and then modifying them, can mutually block if adjacent key values are requested. This is usually a rare situation and it is enough to use RetryOnDeadlock to avoid problems, but in some cases it may be necessary to impose an update lock when pulling records using a non-unique key.
Presence check before insertion
Example
We need to check if there is a user with such an Id on Facebook in the database before adding it. Since we are working with a single line in the database, it seems that only it will be blocked and the probability of interlocking is small. However, if you try to select a non-existent value in a transaction with the isolation level Serializable (and this column is included in the index), then a shared lock will be imposed on all keys between the two closest values that are in the table. For example, if the database has Id 15 and Id 1025, and there are no values between them, then when you execute SELECT * FROM Users WHERE FacebookId = 500, the Shared lock is imposed on the keys from 15 to 1025. If, prior to insertion, another transaction checks whether a user with FacebookId = 600 and tries to insert it, then a deadlock occurs. If there are already many users in the database who have FacebookId full, then the probability of interlocking will be small and we only need to use RetryOnDeadlock. But if you perform many such transactions on an almost empty database, then deadlocks will occur often enough to greatly affect performance.
We have this problem when parallel import of consumers from new customers (for each customer we create a new empty database). Since we are currently satisfied with the speed of single-threaded import, we simply turned off parallelism. But in principle, the problem is solved as well as in the above example, you need to use the update block:
SELECT * FROM Users WITH(UPDLOCK) WHERE FacebookId = 500 In this case, when multithreaded imports into an empty database, at the beginning, the threads will be idle, waiting for the lock to be released, but as the base is filled, the degree of parallelism will increase. Although if the imported data is ordered by FacebookId, in parallel to import them will not work. When importing into an empty database, such ordering should be avoided (or not to check the presence of users in the database on FacebookId during the first import).
Interlocking on complex units
If you have a complex aggregate in your system, the data of which is stored in several tables, and there are many transactions that change different parts of this aggregate in parallel, then you need to build all these transactions in such a way that they do not interlock each other.
Example
The database stores personal data of the consumer, his identifiers in social networks, orders in the online store, records of letters sent to him.
Transactions that add an identifier to the social network, send letters and register purchases can also change technical fields in the main consumer record. In any of these transactions there is a consumer Id.
To avoid deadlocks, you need to start any transaction with the following query:
SELECT * FROM Customers WITH (UPDLOCK) WHERE Id = @Id In this case, at one time only one transaction will be able to change the data related to a specific consumer and interlocks will not occur regardless of how complex the consumer’s aggregate is.
You can try to change the data storage scheme so that transactions, sending letters and registering purchases do not change technical notes in the consumer. Then information about orders and sent letters can be changed in parallel with the change of the consumer. In this case, we actually take this data out of the “consumer” aggregate.
To summarize, tips for working with aggregates can be described as follows:
- It is necessary to ensure that any transaction in the system does not change more than one unit
- in any transaction that modifies the aggregate, the first request accessing the aggregate data must impose an exclusive or update lock on the aggregate root
- to increase the degree of parallelism of the system it is necessary to make the units as small as possible
These tips, of course, are not a panacea for mutual interlocks, but can greatly facilitate your life.
Deadlocks on consecutive entries
Such interlocks occur under very specific conditions, but we did encounter them a couple of times, so it's worth telling about them too.
Example
When sending a letter from DirectCRM to the email gateway, the consumer is given an action about the fact of sending (one entry in the database). An action id is a regular identity, incremented by one for each subsequent entry. When a letter is successfully sent to the mail server, the email gateway reports this to DirectCRM, and CRM issues an action about the successful sending of the letter that refers to the action about the fact of sending (the link is stored in the HierarchicalCustomerActions table). In order for the operation of processing a message from the email gateway to be idempotent (why you need to read it in the previous article ), we check if there was an action about successful sending before this (in a serializable transaction). With such a check, a shared lock is imposed on the key in the index by RootCustomerActionId, corresponding to the fact of sending the letter. But the sending action is the first to refer to the fact of sending and at the time of its issuance there is not a single entry in the HierarchicalCustomerActions table with such a RootCustomerActionId. Therefore, a shared lock will be imposed on all keys between the two existing ones. Since the action Id is an identity, very often the RootCustomerActionId checked is greater than any of those already in the table and the lock is imposed on all keys greater than or equal to the maximum RootCustomerActionId value in the table. In an email gateway, sending a message occurs in several streams, and as a result, the following situation often occurs:
- DirectCRM adds actions about sending with Id N, N + 1, N + 2, etc.
- The email gateway handles the sending of all these emails in parallel.
- At the time of sending the sending actions, the maximum RootCustomerActionId value is N-1.
- When checking whether there is no record of the successful sending of the letter N, N + 1, N + 2, etc., a shared lock is imposed on the records with RootCustomerActionId greater than or equal to N-1.
- Each of the transactions tries to insert its sending record and waits for another transaction to release the shared lock.
- As a result, only one of all concurrently executed transactions will be executed, and the rest will be rolled out.
If you apply an update lock when requesting HierarchicalCustomerActions, then there will be no deadlocks, but there will be no parallel processing either - all transactions will wait until the transaction that imposed the update lock ends.
There are the following solutions to this problem:
- Reject identity and generate Id actions so that the new Id will in most cases be between two existing ones. Then the probability of interlocking will be small.
- When issuing an action about the fact of sending, also insert an entry in the HierarchicalCustomerActions (this record has a RootCustomerActionId of CustomerActionId). Then, when requesting records with RootCustomerActionId = N, a shared lock will be imposed on the values N and N + 1, since there are already records with such values. In order to avoid mutual locks during parallel insertion of actions about a successful post that refer to actions about the fact of sending with Id N and with Id N + 1, you need to apply an update lock when requesting HierarchicalCustomerActions. As a result, when parallel insertion of several records, the following occurs:
- Transaction 1 requests entries with RootCustomerActionId = N. In doing so, it imposes an update lock on the values of the key N and N + 1.
- Transaction 2 requests entries with RootCustomerActionId = N + 1. In doing so, he is trying to impose an update lock on the values of N + 1 and N + 2, so he is waiting for the completion of transaction 1.
- Transaction 3 requests entries with RootCustomerActionId = N + 2. In doing so, it imposes an update lock on the key values N + 2 and N + 3. Now transaction 2 must also wait for transaction 3 to complete.
- Transactions 1 and 3 are processed in parallel.
- Transaction 2 in progress.
Source: https://habr.com/ru/post/261661/
All Articles