Competently select and test the storage of their backups
Continuing to reveal the topic of not very obvious, but interesting aspects of building backup systems, today it is proposed to discuss, let's say, the end point of this system - the place where your backups will be saved, and find out why it is important to seriously approach its planning. You can call this place as anyone - repository, storeydzh, storage device, storage system, etc. But for simplicity, we will focus on the “storage” option, implying a classic disk drive (that is, tapes, magneto-optics and the like will not be affected today).

The reason for writing the article was not clear as a tradition that when creating backups any kind of junk can act as a repository, and for some reason became the norm phenomenon, when the only taken into account is the price of equipment. Moreover, it is desirable that for the three dedicated pennies there were rubber discs of the most friable rubber. In the best case, they can still pay attention to the speed of work declared by the manufacturer, without even thinking about what kind of figure they showed and what it refers to. The larger the number, the better, there is not even a doubt.
')
The problem is that some backup modes impose very serious requirements on the speed of reading and / or writing to the vaults, without forgetting the overall stability. This means that if you do not take them into account at the planning stage, you can at best get a barely living system, and at worst go to buy new equipment at the expense of their premium.
Under the cat, I will try to explain how to predict the behavior of the storage in advance, based on your backup plan, and also prove in practice that choosing a storage for backups on a residual basis is a bad practice.
As we all know very well, any equipment must be selected on the basis of its requirements. Requirements are born from the kind of tasks that will be solved with the help of this equipment. In this post, we will look at specific scenarios of how Veeam Backup & Replication v8 works, but the techniques described below can easily be applied to the work of your favorite software.
In our case, there is no need to use any specialized equipment. Some administrators try, for example, to use arrays with built-in data deduplication — for “more data on disks of the same size” —but they quickly stop doing this when faced with reality.
And for any general purpose storage, it’s enough to take into account only two parameters - volume and performance. And if everything is clear with the first one and no additional comments are required, then the second one should definitely focus on it. And the mass of articles about this topic on Habré is proof of that.
Many people mistakenly believe that the performance of the drive is a kind of characteristic measured in the amount of data transferred somewhere. Or, maybe, read data, or (sometimes even that!) Random access time. All of these characteristics are wonderful and beautiful, but what does it mean to your production system if we have high write speed, low read speed and mediocre access time? And how does this compare with the option when fast reading, fast writing, but the access time is twice as long, and the cost is the same? A complex characteristic is needed, which in a single, irrelevant figure unambiguously characterizes this particular repository. And this characteristic is called IOPS - the number of I / O operations per second. The last question remains - how to correctly measure it in relation to its tasks.
And here an extremely important truth is revealed to us - testing must necessarily be extended in time. And the longer the storage will hold under the load test, the more correct the picture of the world you get. A classic example is the entry-level NAS, in which the IOPS obtained in 5 minutes will differ by an order of magnitude or two from that obtained after a test lasting half an hour. A backup can last much longer than thirty minutes.
Absolutely all backup software supports NAS as a repository, and many choose this option as the simplest. There is nothing wrong with that, but any technical support engineer will tell you that there is nothing better than regular disks geared to a regular server. The reason is simple - you can store information on a network balloon, but you cannot operate it. Even for the most banal actions, the file must be downloaded, modified and uploaded. In the case of large files, this can lead to a strong load on both the network and the NAS itself, not to mention the overall speed of such a system. While using a dedicated server on its side, you can run a microscopic agent that will actively roll back terabytes of backups without any influence on the external environment and without restrictions caused by the transmission medium.
Another consequence is that it is impossible to be 100% sure that the information recorded on the NAS is correct. The NAS constantly has an intermediate data transfer environment that introduces uncertainty.
And do not forget that the NAS is a file storage device, and the disks are block storage. This is a nod to reliability storage.
Moral - if it is possible not to use the NAS, you must use it safely. Then you say thank you yourself.
Not to say that the standard, but one of the most popular testing methods is a long run with the help of an excellent Iometr . Originally developed by Intel, it is a tool with a ton of features, a great interface and well-deserved fame. It allows you to test both individual disks and entire clusters, and the flexibility of settings allows you to recreate (simulate) many types of loads.
But for our research, it does not fit at all (from the word "completely"), because all this splendor has a set of important minuses for us - for example, the latest release was already in 2006, so he does not know about such things as SSD cache, server side cache and other newfangled things, without which no modern piece of hardware can do, and not taking them into account would be strange.
Another problem is the load emulation mechanism, which is somewhat far from the actual production. The mechanism of operation is as simple as three kopecks - a dummy file of a given size is created on the disk, and then sequential read / write operations in the specified proportions begin. This makes it impossible to make interesting tricks like “And let's imagine that right now a piece of data has been created in the farthest corner of the disk, which our cache has not yet seen.” Such a situation is called “read miss” and for production systems is a commonplace gray, and not a fantastic rarity. Also, there is another mass of nuances and subtleties that are hardly interesting for many; you just need to remember the main thing - Iometr is an excellent tool for quick testing, when you need to get a more or less plausible picture of the world in a couple of clicks, but it is better to entrust the long-term tests to specialized software.
I will take the liberty to recommend the FIO utility ( Flexible I / O tester ) which is constantly evolving and, by the way, multiplatform ( here are some ready-made binaries for Windows). The console utility is launched with the configuration file specified as “fio config_file”. All grown-up.
Along with it comes the finest HOWTO file and a few examples of ready-made tests. Therefore, I will not describe in detail all the parameters (of which there is darkness, but they are prudently divided into basic and incidental), but simply analyze the most important for us.
So, each halyard can consist of several sections. Sections [global] and qualifying sections for different test variants in one launch.
The most interesting for us in the [global] section:
Before we start writing configs, let's take a closer look at the loads we need to emulate.
The easiest case is the creation of the first full backup (creating a .vbk file). Active Full in our terminology. From the point of view of storage, everything is clear - there is one write operation for each data block.
If further we use Forward incremental ie simply append the incremental files, then the load rule is preserved.
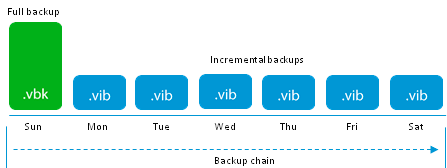
Thus, this method gives the lowest load on the storage because There is nothing easier than sequential recording. And even suitable for long-suffering entry-level NAS, if they are willing to ensure stable operation, which unfortunately is not always the case.
This means that in the configuration it remains to specify the path to the test object and the fact that we need to test the normal entry:
A simple sequential write test will start, almost completely identical to the actual process. Why practically? The reason lies in the deduplication process, which, before recording a new data block, first checks for its presence and, if there is a match, the block is skipped to write. But since the comparison takes place not with real blocks, but with their metadata, the size of which is negligibly small against the background of the backup file, this error is of a sort acceptable and is ignored.
Hereinafter, under the spoiler, I will lay out the full config of the test.
Let us turn to more “adult” methods. Next is Forward incremental with periodic Synthetic fulls .
Backups creation modes have already been repeatedly and in detail understood (you can refresh your memory here and here ), so I’ll just say the main difference: Synthetic full backups are not created by directly copying data from the production system, but by creating a new increment and “collapsing” the entire incremental chain into single file that becomes new vbk. From the point of view of IO operations, this means that each block will first be read from its own vbk or vib, and then written into a new vbk ie the total number of operations doubles.
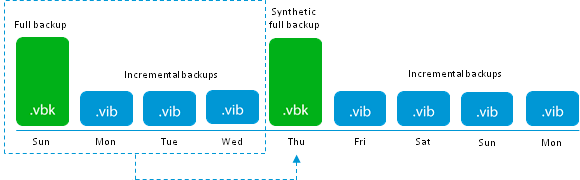
Adhering to the idea of maximum likelihood, our test, from now on, should consist of two parts - the first is to create an increment
And the second part is the creation of synthetic full. If you plan to keep backups for a week, then the correct config will look like this:
With the stonewall parameter, I hope everything is clear. The new_group parameter following it is responsible for outputting the received data to a separate report, otherwise the resulting values will be added to the data from the previous test.
As mentioned in the paragraph above, two I / O operations will be performed on each block, therefore, using the rwmixread parameter, we set the ratio of read / write operations to 50%.
How this happens deserves a small digression, which will explain the next nine lines of the config.
At the time of launching the process of creating a synthetic file, we have a previous vbk, six old increments for each day of the week, and one fresh for the current day. It seems that the data block we need should be read through the whole chain of these files, i.e. in the worst case, all eight files should be open. But doing so is completely inhumane, so the metadata of all the files are loaded into the RAM and the choice of the location of the necessary block occurs there, and the process only needs to read the block from the right place.
Two important points that are often overlooked by administrators are that at the last moment of creating a synthetic vbk, there are actually two full backups on the repository, which can dramatically indicate the amount of available space. The old backup, and its entire incremental chain, will be deleted at the very last stage, when the new file passes all integrity tests.
The second missing moment is the time to create a synthetic file. In general, it is equal to twice the creation time of Active full.
Full config under spoiler
Next in line will be the reverse order of building files used for Reversed incremental backups. Perhaps the most beloved by society type of backups, the easiest to understand, but one of the most terrible in terms of loads and design of the entire system.
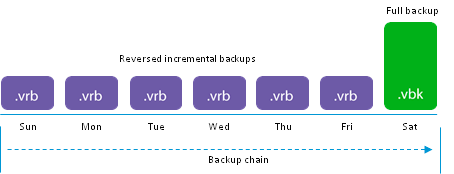
The beginning is the same as everywhere - a full backup is created in the .vbk format. With the next launches, as well as for the forward incremental, differential files are created, but their fate is much more interesting. Instead of being recorded as separate .vib files, they are injected into the existing .vbk, displacing data blocks from it that have been modified in the backup system. The preempted blocks are saved in the .vrb file, and the new .vbk still corresponds to the state of the system at the time of the last backup.
The obvious advantages are the minimal use of storage space, exact correspondence of the number of points, recovery to the number of files in the storage, fast recovery from the last point.
Let's see how this is implemented at the data storage level. Three I / O operations are performed on each data block:
A set of these operations can be run on any stored block and it is impossible to predict who will be next. Or, to put it simply, there is a storm of arbitrary I / O operations on the disk and not every system is given with honor to undergo a similar test.
But let's move on to practice! The part of the config that interests us will look like this:
The parameter rwmixread = 33 should be interpreted as: 33% I / O operations will be read operations, 66% of the write operation. Thanks to the use of the round-robin algorithm and the ability of FIO to work with two files at the same time, it turns out an excellent simulation of a process that can bring not the worst equipment to its knees.
And be careful when it comes to analyzing the results - FIO will show the full amount of IOPS and a beautiful (hopefully) KB / s figure, but you shouldn’t be deceived until you divide it into three. They shared - they got the real speed of work, they didn't divide - they got the speed of writing a new file to the empty storage.
And of course, ready to launch config.
Go to the mixed modes of creating backups. They are represented by the Forever Forward Incremental algorithm.
It is new and fresh, and it is better to tell some details. This mode is designed to deal with the main problem of simple incremental backups - the storage of an excessive number of recovery points.
Before reaching the number of recovery points specified in the task settings, the algorithm works as a forward incremental i.e. a complete archive is created and increments are added to it every day.
Focus starts on the day you reach the specified number of points. First of all, the next increment is created:
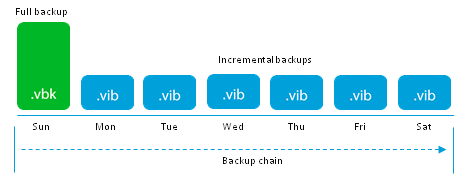
The next step, the initial .vbk begins its “journey” to the top, and absorbs the next incremental .vib. replacing their obsolete blocks with blocks of the nearest incremental file. After successful injection, the .vib file is deleted, and the .vbk file is one day younger.
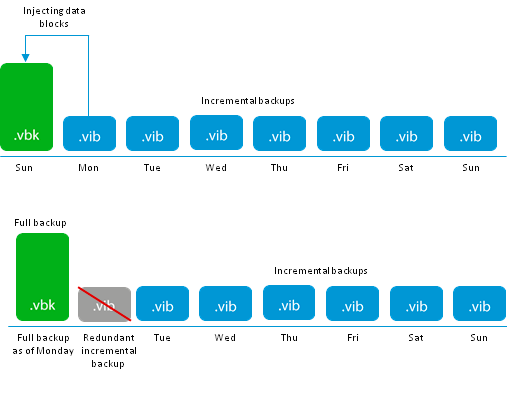
This algorithm allows you to keep the exact number of files in an incremental chain, and also has a number of other advantages:
- In comparison with the classic forward incremental, there is no need to periodically create a full backup, which has a very positive effect on the health of production systems
- Like reverse incremental uses the minimum required space
- Consumption of I / O operations remains at the same level: only two operations for data injection, which allows not stretch the time required for backup.
- Comparing with forward incremental, with periodic synthetic full, where only two I / O are also involved, you can notice an interesting correlation. In fact, instead of a one-time heavy and long transformation of a large file, there is a daily run of a mini-copy of this operation, which in sum gives the same result, but with less blood.
Let's go to the tests! Create an increment file:
Now we simulate the transformation:
As you can see no magic, so immediately ready config:
So, the test is completed and we have a set of numbers. Let's disassemble it.
Netapp FAS2020 will be prepared today, do not consider it an advertisement, with 12 disks on board, one controller and all this is in RAID-DP mode, which is basically ordinary RAID6. This farm is connected to the Windows machine via iSCSI, all tests are run on the same machine.
As can be seen in the screenshot, a test was carried out with blocks of 512K in size, in four threads by one process (iodepth = 1). The runtime is set at 10 minutes, we emulated a reverse increment run, and as a result we have 60 iops with an average throughput of 31051 KB / s. Do not forget to divide into three, translate KB / s to MB / s and get an effective backup creation speed of 10.35 MB / s. Or 37.26 GB of data per hour.
The table below shows data on averaged values - each test was run three times. For the purity of the experiment, startups showing deviations of more than 10% were ignored and the test restarted.
The data are presented both in the form of effective speed and in pure form.
Additionally, all tests were performed on blocks of different sizes in order to select the best parameters for a specific piece of iron.
Always when you want to squeeze the most out of the equipment, it is very important not to bend the stick and optimize the excess.
As an example, we will look at the dynamics of changes in indicators when the number of I / O flows changes. We will check on the forward incremental task, with data blocks of 1 MB.
It is clearly seen that the throughput grows up to 15 simultaneous streams. But starting from 6 already, the performance gain is so insignificant that it raises the question of the expediency of further increasing the load on the CPU in an attempt to squeeze out an extra megabyte of speed.
When using 20 threads, performance degradation starts to be observed. incoming data becomes too much and I / O operations are placed in a queue, start to get lost, there are requests for retransmission and other horror.
This metric allows us to understand the optimal number of simultaneously running tasks for the best use of storage capacity. Some administrators, having many few backup tasks, prefer not to bother, but just to set up a simultaneous launch for a beautiful time. For example, one in the morning. As a result, the server sleeps most of the day, and then plows for hours like a damn. He, of course, iron, but if the load at least a little bit to spread in time, the peak load will smooth out and the storage will serve you a little longer.
Further. At the beginning of the article, the parameter direct = 1 was mentioned, thanks to which test streams are ignored by the OS cache and go directly to the repository. Of course, in reality, this situation is not often, but it must be taken into account. In our example, here’s what the change will be:
The invalidate parameter is responsible for the forced clearing of the cache and does not greatly affect the result, but as we can see, the presence of the cache itself gives an excellent boost. Especially if you count in percentage. Although it surprises anyone?
The main idea of the article is more good and correct tests! Feel free to test everything your hands reach, but do it correctly and slowly.
If on the array that was used in the tests for this article, run the usual sequential write test, we will see a delightful 12717 IOPS for 8K blocks, or 199.57 MB / S for 1 MB blocks. How far this is from the real situation is beautifully illustrated in the table, but who is too lazy to wind up above is a difference of two orders of magnitude.
Well, always keep in mind a simple set of rules:
The reason for writing the article was not clear as a tradition that when creating backups any kind of junk can act as a repository, and for some reason became the norm phenomenon, when the only taken into account is the price of equipment. Moreover, it is desirable that for the three dedicated pennies there were rubber discs of the most friable rubber. In the best case, they can still pay attention to the speed of work declared by the manufacturer, without even thinking about what kind of figure they showed and what it refers to. The larger the number, the better, there is not even a doubt.
')
The problem is that some backup modes impose very serious requirements on the speed of reading and / or writing to the vaults, without forgetting the overall stability. This means that if you do not take them into account at the planning stage, you can at best get a barely living system, and at worst go to buy new equipment at the expense of their premium.
Under the cat, I will try to explain how to predict the behavior of the storage in advance, based on your backup plan, and also prove in practice that choosing a storage for backups on a residual basis is a bad practice.
Fast and easy mate
As we all know very well, any equipment must be selected on the basis of its requirements. Requirements are born from the kind of tasks that will be solved with the help of this equipment. In this post, we will look at specific scenarios of how Veeam Backup & Replication v8 works, but the techniques described below can easily be applied to the work of your favorite software.
In our case, there is no need to use any specialized equipment. Some administrators try, for example, to use arrays with built-in data deduplication — for “more data on disks of the same size” —but they quickly stop doing this when faced with reality.
And for any general purpose storage, it’s enough to take into account only two parameters - volume and performance. And if everything is clear with the first one and no additional comments are required, then the second one should definitely focus on it. And the mass of articles about this topic on Habré is proof of that.
Many people mistakenly believe that the performance of the drive is a kind of characteristic measured in the amount of data transferred somewhere. Or, maybe, read data, or (sometimes even that!) Random access time. All of these characteristics are wonderful and beautiful, but what does it mean to your production system if we have high write speed, low read speed and mediocre access time? And how does this compare with the option when fast reading, fast writing, but the access time is twice as long, and the cost is the same? A complex characteristic is needed, which in a single, irrelevant figure unambiguously characterizes this particular repository. And this characteristic is called IOPS - the number of I / O operations per second. The last question remains - how to correctly measure it in relation to its tasks.
And here an extremely important truth is revealed to us - testing must necessarily be extended in time. And the longer the storage will hold under the load test, the more correct the picture of the world you get. A classic example is the entry-level NAS, in which the IOPS obtained in 5 minutes will differ by an order of magnitude or two from that obtained after a test lasting half an hour. A backup can last much longer than thirty minutes.
A small remark about NAS and backups
Absolutely all backup software supports NAS as a repository, and many choose this option as the simplest. There is nothing wrong with that, but any technical support engineer will tell you that there is nothing better than regular disks geared to a regular server. The reason is simple - you can store information on a network balloon, but you cannot operate it. Even for the most banal actions, the file must be downloaded, modified and uploaded. In the case of large files, this can lead to a strong load on both the network and the NAS itself, not to mention the overall speed of such a system. While using a dedicated server on its side, you can run a microscopic agent that will actively roll back terabytes of backups without any influence on the external environment and without restrictions caused by the transmission medium.
Another consequence is that it is impossible to be 100% sure that the information recorded on the NAS is correct. The NAS constantly has an intermediate data transfer environment that introduces uncertainty.
And do not forget that the NAS is a file storage device, and the disks are block storage. This is a nod to reliability storage.
Moral - if it is possible not to use the NAS, you must use it safely. Then you say thank you yourself.
What and how will we test?
Not to say that the standard, but one of the most popular testing methods is a long run with the help of an excellent Iometr . Originally developed by Intel, it is a tool with a ton of features, a great interface and well-deserved fame. It allows you to test both individual disks and entire clusters, and the flexibility of settings allows you to recreate (simulate) many types of loads.
But for our research, it does not fit at all (from the word "completely"), because all this splendor has a set of important minuses for us - for example, the latest release was already in 2006, so he does not know about such things as SSD cache, server side cache and other newfangled things, without which no modern piece of hardware can do, and not taking them into account would be strange.
Another problem is the load emulation mechanism, which is somewhat far from the actual production. The mechanism of operation is as simple as three kopecks - a dummy file of a given size is created on the disk, and then sequential read / write operations in the specified proportions begin. This makes it impossible to make interesting tricks like “And let's imagine that right now a piece of data has been created in the farthest corner of the disk, which our cache has not yet seen.” Such a situation is called “read miss” and for production systems is a commonplace gray, and not a fantastic rarity. Also, there is another mass of nuances and subtleties that are hardly interesting for many; you just need to remember the main thing - Iometr is an excellent tool for quick testing, when you need to get a more or less plausible picture of the world in a couple of clicks, but it is better to entrust the long-term tests to specialized software.
I will take the liberty to recommend the FIO utility ( Flexible I / O tester ) which is constantly evolving and, by the way, multiplatform ( here are some ready-made binaries for Windows). The console utility is launched with the configuration file specified as “fio config_file”. All grown-up.
Along with it comes the finest HOWTO file and a few examples of ready-made tests. Therefore, I will not describe in detail all the parameters (of which there is darkness, but they are prudently divided into basic and incidental), but simply analyze the most important for us.
So, each halyard can consist of several sections. Sections [global] and qualifying sections for different test variants in one launch.
The most interesting for us in the [global] section:
- size = 100g
Specifies the size of the test file. which will be created on the test object. The main rule - the more the better. If you have a new empty storage, then the best solution is to allocate the entire storage for the test.
But it is worth considering that before you directly start the test, fio will create this file and on large volumes this process may take some time.
In the case when it is impossible to use the entire amount of storage, it is important to adhere to the rule that the file size should at least twice overlap the size of all the caches available to the storage. Otherwise, you risk measuring only their performance. - bs = 512k
The most important parameter when it comes to squeezing all the juices and finding the maximum speeds. It is vital to correctly specify the size of the data block when it comes to testing specific scenarios. In our case, everything can be found in the documentation. And an important nuance - we will use the half values as the average expected gain from using the deduplication built into Backup & Replication. Accordingly, if you do not plan to deduplicate at all, then you take an integer value.
So, the possible options:- 512K, if Local Target is installed;
- 256K, if Lan Target is installed;
- 128K if Wan Target is installed;
For owners of really large infrastructures, where a daily incremental backup reaches terabytes, it makes sense to use 2048K if Local target 16 TB is set. there the block size is 4096K - numjobs = 1
The number of tasks performed in parallel. Just start with one and increase until you see obvious degradation. - runtime = 3600
Test duration in seconds. 3600 seconds is the hour. If you want the right results, then putting less makes no sense. But when you just need to run a few quick tests, be sure to keep track of the cache. If tests run until the cache is full before failure, the results can be much higher than the actual values. - ioengine = windowsaio
If the storage will be connected to the Windows server, leave so. If to Linux, then replace with libaio. Both methods use unbuffered IO, so all caches on the way to the storage will be ignored, which is exactly what we need. - iodepth = 1
The number of processes that simultaneously work with the file system. In our case, always 1. - direct = 1
Telling fio not to use the system file cache for read and write operations. With this we simulate the worst case when the system cache is clogged and does not accept data.
Separately, you can emulate the use of cache for write operations. To do this, change direct = 0 and add the option invalidate = 1.
And it should be noted that direct = 0 cannot be used for Linux repositories with the libaio mechanism. - overwrite = 1
Random block rewriting. As often happens in real life. To test the repository for the use of “heavy” backup options, such as forward incremental, the option is strictly required.
Creating a backup file in detail
Before we start writing configs, let's take a closer look at the loads we need to emulate.
The easiest case is the creation of the first full backup (creating a .vbk file). Active Full in our terminology. From the point of view of storage, everything is clear - there is one write operation for each data block.
If further we use Forward incremental ie simply append the incremental files, then the load rule is preserved.
Thus, this method gives the lowest load on the storage because There is nothing easier than sequential recording. And even suitable for long-suffering entry-level NAS, if they are willing to ensure stable operation, which unfortunately is not always the case.
This means that in the configuration it remains to specify the path to the test object and the fact that we need to test the normal entry:
filename= E\:\vbk # : rw=write # A simple sequential write test will start, almost completely identical to the actual process. Why practically? The reason lies in the deduplication process, which, before recording a new data block, first checks for its presence and, if there is a match, the block is skipped to write. But since the comparison takes place not with real blocks, but with their metadata, the size of which is negligibly small against the background of the backup file, this error is of a sort acceptable and is ignored.
Hereinafter, under the spoiler, I will lay out the full config of the test.
Forward.FIO
[global] size=100g bs=512k numjobs=2 runtime=3600 ioengine=windowsaio iodepth=1 direct=1 overwrite=1 thread unified_rw_reporting=1 norandommap=1 group_reporting [forward] filename=E\:\vbk rw=write Let us turn to more “adult” methods. Next is Forward incremental with periodic Synthetic fulls .
Backups creation modes have already been repeatedly and in detail understood (you can refresh your memory here and here ), so I’ll just say the main difference: Synthetic full backups are not created by directly copying data from the production system, but by creating a new increment and “collapsing” the entire incremental chain into single file that becomes new vbk. From the point of view of IO operations, this means that each block will first be read from its own vbk or vib, and then written into a new vbk ie the total number of operations doubles.
Adhering to the idea of maximum likelihood, our test, from now on, should consist of two parts - the first is to create an increment
[forward] rw=write filename=E\:\vib And the second part is the creation of synthetic full. If you plan to keep backups for a week, then the correct config will look like this:
[synthetic] stonewall # new_group # rw=randrw # / rwmixread=50 # r/w file_service_type=roundrobin filename=E\:\new_vbk filename=E\:\old_vbk filename=E\:\vib1 filename=E\:\vib2 filename=E\:\vib3 filename=E\:\vib4 filename=E\:\vib5 filename=E\:\vib6 filename=E\:\vib7_temporary With the stonewall parameter, I hope everything is clear. The new_group parameter following it is responsible for outputting the received data to a separate report, otherwise the resulting values will be added to the data from the previous test.
As mentioned in the paragraph above, two I / O operations will be performed on each block, therefore, using the rwmixread parameter, we set the ratio of read / write operations to 50%.
How this happens deserves a small digression, which will explain the next nine lines of the config.
At the time of launching the process of creating a synthetic file, we have a previous vbk, six old increments for each day of the week, and one fresh for the current day. It seems that the data block we need should be read through the whole chain of these files, i.e. in the worst case, all eight files should be open. But doing so is completely inhumane, so the metadata of all the files are loaded into the RAM and the choice of the location of the necessary block occurs there, and the process only needs to read the block from the right place.
Two important points that are often overlooked by administrators are that at the last moment of creating a synthetic vbk, there are actually two full backups on the repository, which can dramatically indicate the amount of available space. The old backup, and its entire incremental chain, will be deleted at the very last stage, when the new file passes all integrity tests.
The second missing moment is the time to create a synthetic file. In general, it is equal to twice the creation time of Active full.
Full config under spoiler
Synthetic.FIO
[global] bs=512k numjobs=2 ioengine=windowsaio iodepth=1 direct=1 overwrite=1 thread unified_rw_reporting=1 norandommap=1 group_reporting [forward] size=50g rw=write runtime=600 filename=E\:\vib [synthetic] stonewall new_group size=300g rw=randrw rwmixread=50 runtime=600 file_service_type=roundrobin filename=E\:\new_vbk filename=E\:\old_vbk filename=E\:\vib1 filename=E\:\vib2 filename=E\:\vib3 filename=E\:\vib4 filename=E\:\vib5 filename=E\:\vib6 filename=E\:\vib7_temporary Next in line will be the reverse order of building files used for Reversed incremental backups. Perhaps the most beloved by society type of backups, the easiest to understand, but one of the most terrible in terms of loads and design of the entire system.
The beginning is the same as everywhere - a full backup is created in the .vbk format. With the next launches, as well as for the forward incremental, differential files are created, but their fate is much more interesting. Instead of being recorded as separate .vib files, they are injected into the existing .vbk, displacing data blocks from it that have been modified in the backup system. The preempted blocks are saved in the .vrb file, and the new .vbk still corresponds to the state of the system at the time of the last backup.
The obvious advantages are the minimal use of storage space, exact correspondence of the number of points, recovery to the number of files in the storage, fast recovery from the last point.
Let's see how this is implemented at the data storage level. Three I / O operations are performed on each data block:
- Reading the data to be replaced from the vbk file
- Overwriting this block with new data
- Write extruded data to a new .vrb file
A set of these operations can be run on any stored block and it is impossible to predict who will be next. Or, to put it simply, there is a storm of arbitrary I / O operations on the disk and not every system is given with honor to undergo a similar test.
But let's move on to practice! The part of the config that interests us will look like this:
file_service_type=roundrobin filename=E\:\vbk filename=E\:\vrb rw=randrw rwmixread=33 The parameter rwmixread = 33 should be interpreted as: 33% I / O operations will be read operations, 66% of the write operation. Thanks to the use of the round-robin algorithm and the ability of FIO to work with two files at the same time, it turns out an excellent simulation of a process that can bring not the worst equipment to its knees.
And be careful when it comes to analyzing the results - FIO will show the full amount of IOPS and a beautiful (hopefully) KB / s figure, but you shouldn’t be deceived until you divide it into three. They shared - they got the real speed of work, they didn't divide - they got the speed of writing a new file to the empty storage.
And of course, ready to launch config.
Reversed.FIO
[global] size=100g bs=512k numjobs=2 runtime=3600 ioengine=windowsaio iodepth=1 direct=1 overwrite=1 thread unified_rw_reporting=1 norandommap=1 group_reporting [reversed] file_service_type=roundrobin filename=E\:\vbk filename=E\:\vrb rw=randrw rwmixread=33 Go to the mixed modes of creating backups. They are represented by the Forever Forward Incremental algorithm.
It is new and fresh, and it is better to tell some details. This mode is designed to deal with the main problem of simple incremental backups - the storage of an excessive number of recovery points.
Before reaching the number of recovery points specified in the task settings, the algorithm works as a forward incremental i.e. a complete archive is created and increments are added to it every day.
Focus starts on the day you reach the specified number of points. First of all, the next increment is created:
The next step, the initial .vbk begins its “journey” to the top, and absorbs the next incremental .vib. replacing their obsolete blocks with blocks of the nearest incremental file. After successful injection, the .vib file is deleted, and the .vbk file is one day younger.
This algorithm allows you to keep the exact number of files in an incremental chain, and also has a number of other advantages:
- In comparison with the classic forward incremental, there is no need to periodically create a full backup, which has a very positive effect on the health of production systems
- Like reverse incremental uses the minimum required space
- Consumption of I / O operations remains at the same level: only two operations for data injection, which allows not stretch the time required for backup.
- Comparing with forward incremental, with periodic synthetic full, where only two I / O are also involved, you can notice an interesting correlation. In fact, instead of a one-time heavy and long transformation of a large file, there is a daily run of a mini-copy of this operation, which in sum gives the same result, but with less blood.
Let's go to the tests! Create an increment file:
[forward] size=50g rw=write filename=E\:\vib Now we simulate the transformation:
[transform] stonewall new_group size=100g rw=randrw rwmixread=50 runtime=600 file_service_type=roundrobin filename=E\:\vbk filename=E\:\old_vib As you can see no magic, so immediately ready config:
Forward-incremental-forever.FIO
[global] bs=512k numjobs=2 ioengine=windowsaio iodepth=1 direct=1 overwrite=1 thread unified_rw_reporting=1 norandommap=1 group_reporting [forward] size=50g rw=write runtime=600 filename=E\:\vib [transform] stonewall new_group size=100g rw=randrw rwmixread=50 runtime=600 file_service_type=roundrobin filename=E\:\vbk filename=E\:\old_vib Interpret the results
So, the test is completed and we have a set of numbers. Let's disassemble it.
Netapp FAS2020 will be prepared today, do not consider it an advertisement, with 12 disks on board, one controller and all this is in RAID-DP mode, which is basically ordinary RAID6. This farm is connected to the Windows machine via iSCSI, all tests are run on the same machine.
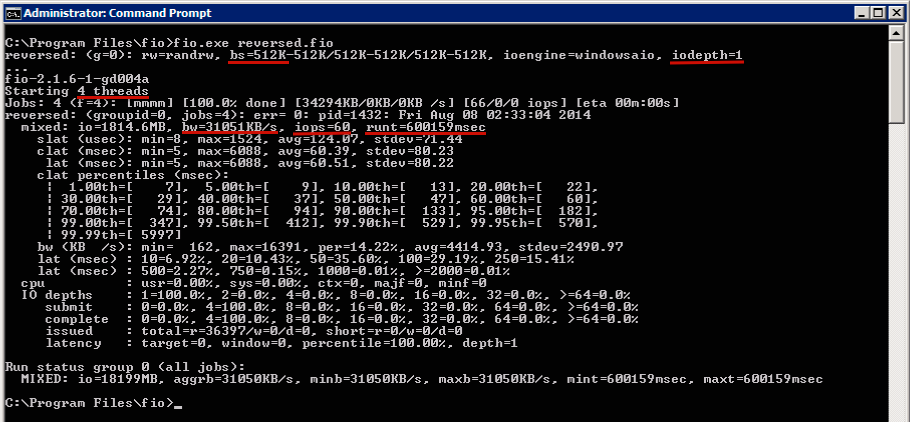
As can be seen in the screenshot, a test was carried out with blocks of 512K in size, in four threads by one process (iodepth = 1). The runtime is set at 10 minutes, we emulated a reverse increment run, and as a result we have 60 iops with an average throughput of 31051 KB / s. Do not forget to divide into three, translate KB / s to MB / s and get an effective backup creation speed of 10.35 MB / s. Or 37.26 GB of data per hour.
The table below shows data on averaged values - each test was run three times. For the purity of the experiment, startups showing deviations of more than 10% were ignored and the test restarted.
The data are presented both in the form of effective speed and in pure form.
Additionally, all tests were performed on blocks of different sizes in order to select the best parameters for a specific piece of iron.
| 512K | 256K | 128K | |
| Forward / 1 thread | 76 iops / 39068 KB / s 140.64 GB per hour | 142 iops / 36476 KB / s 131.31 GB per hour | 232 iops / 29864 KB / s 107.51 GB per hour |
| Forward / 2 threads | 127 iops / 65603 KB / s 236.17 GB per hour | 239 iops / 64840 KB / s 233.42 GB per hour | 409 iops / 52493 KB / s 188.97 GB per hour |
| Forward / 4 threads | 161 iops / 82824 KB / s 298.16 GB per hour | 312 iops / 80189 KB / s 288.68 GB per hour | 624 iops / 79977 KB / s 287.91 GB per hour |
| Synthetic / 1 thread | 32 iops / 17108 KB / s 61.59 GB per hour 30.79 real volume per hour | 42 iops / 11061 KB / s 39.82 GB per hour 19.91 real volume per hour | 66 iops / 8590 KB / s 30.92 GB per hour 15.46 real volume per hour |
| Synthetic / 2 threads | 48 iops / 25198 KB / s 90.71 GB per hour 45.35 real volume per hour | 71 iops / 18472 KB / s 66.50 GB per hour 33.25 real volume per hour | 112 iops / 14439 KB / s 51.98 GB per hour 25.99 real volume per hour |
| Synthetic / 4 threads | 58 iops / 30360 KB / s 109.29 GB per hour 54.64 real volume per hour | 99 iops / 25424 KB / s 91.52 GB per hour 45.76 real volume per hour | 174 iops / 22385 KB / s 80,58 GB per hour 40.29 real volume per hour |
| Reversed / 1 thread | 36 iops / 19160 KB / s 68.97 GB per hour 22.99 real volume per hour | 50 iops / 12910 KB / s 46.47 GB per hour 15.49 real volume per hour | 68 iops / 8777 KB / s 31.59 GB per hour 10.53 real volume per hour |
| Reversed / 2 threads | 52 iops / 27329 KB / s 98.38 GB per hour 32.79 real volume per hour | 76 iops / 19687 KB / s 70.87 GB per hour 23.62 real volume per hour | 109 iops / 14085 KB / s 50.70 GB per hour 16.90 real volume per hour |
| Reversed / 4 threads | 66 iops / 34183 KB / s 123.06 GB per hour 41.02 real volume per hour | 100 iops / 25699 KB / s 92.51 GB per hour 30.84 real volume per hour | 172 iops / 22006 KB / s 79.22 GB per hour 26.41 real volume per hour |
| Forward incremental forever / 1 thread | 31 iops / 16160 KB / s 58.17 GB per hour 29.09 real volume per hour | 41 iops / 10806 KB / s 38.90 GB per hour 19.45 real volume per hour | 54 iops / 7081 KB / s 25.49 GB per hour 12.74 real volume per hour |
| Forward incremental forever / 2 threads | 48 iops / 25057 KB / s 90.21 GB per hour 45.10 real volume per hour | 66 iops / 17075 KB / s 61.47 GB per hour 30.73 real volume per hour | 95 iops / 12304 KB / s 44.29 GB per hour 22.15 real volume per hour |
| Forward incremental forever / 4 threads | 57 iops / 29893 KB / s 107.61 GB per hour 53.80 real volume per hour | 88 iops / 22770 KB / s 81.97 GB per hour 40.98 real volume per hour | 150 iops / 19323 KB / s 69.56 GB per hour 34.78 real volume per hour |
A little about optimization
Always when you want to squeeze the most out of the equipment, it is very important not to bend the stick and optimize the excess.
As an example, we will look at the dynamics of changes in indicators when the number of I / O flows changes. We will check on the forward incremental task, with data blocks of 1 MB.
- 1 thread 76 iops / 39,07 MB / s 140,64 GB per hour
- 2 threads 127 iops / 65,60MB / s 236,17 GB per hour
- 4 threads 161 iops / 82,82 MB / s 298,16 GB per hour
- 6 threads 174 iops / 89,44 MB / s 321,98 GB per hour
- 8 threads 180 iops / 92,49 MB / s 332,99 GB per hour
- 10 threads 186 iops / 95,24 MB / s 342,89 GB per hour
- 15 threads 191 iops / 98,19 MB / s 353,48 GB per hour
- 20 threads 186 iops / 95.23 MB / s 342.84 GB per hour.
It is clearly seen that the throughput grows up to 15 simultaneous streams. But starting from 6 already, the performance gain is so insignificant that it raises the question of the expediency of further increasing the load on the CPU in an attempt to squeeze out an extra megabyte of speed.
When using 20 threads, performance degradation starts to be observed. incoming data becomes too much and I / O operations are placed in a queue, start to get lost, there are requests for retransmission and other horror.
This metric allows us to understand the optimal number of simultaneously running tasks for the best use of storage capacity. Some administrators, having many few backup tasks, prefer not to bother, but just to set up a simultaneous launch for a beautiful time. For example, one in the morning. As a result, the server sleeps most of the day, and then plows for hours like a damn. He, of course, iron, but if the load at least a little bit to spread in time, the peak load will smooth out and the storage will serve you a little longer.
Further. At the beginning of the article, the parameter direct = 1 was mentioned, thanks to which test streams are ignored by the OS cache and go directly to the repository. Of course, in reality, this situation is not often, but it must be taken into account. In our example, here’s what the change will be:
- direct = 1 65.60 MB / s
- direct = 0 98.31 MB / s
- direct = 0 + invalidate 96,51 MB / s
The invalidate parameter is responsible for the forced clearing of the cache and does not greatly affect the result, but as we can see, the presence of the cache itself gives an excellent boost. Especially if you count in percentage. Although it surprises anyone?
findings
The main idea of the article is more good and correct tests! Feel free to test everything your hands reach, but do it correctly and slowly.
If on the array that was used in the tests for this article, run the usual sequential write test, we will see a delightful 12717 IOPS for 8K blocks, or 199.57 MB / S for 1 MB blocks. How far this is from the real situation is beautifully illustrated in the table, but who is too lazy to wind up above is a difference of two orders of magnitude.
Well, always keep in mind a simple set of rules:
- Even the simplest, in your opinion, functions in the software can consist of a set of simple actions and be very complex for the equipment, so before you accuse the software, look what happens on the hard drive. In our case, an example of such stress are reverse incremental backups.
- The larger the block size, the better the result.
- Deduplication is a great technology, but don’t get carried away by high values.
- Several simultaneously running tasks will give a better result than one large one. Multitasking is our everything.
Source: https://habr.com/ru/post/261595/
All Articles