Distributed cryptoprocessing
From the first day, when I began to realize how most of the financial processing works, the painful “It’s impossible to live like this!” Was spinning in my head. But now, the concept of how to try to live, it seems, has developed. Do you want strict consistency on N replicas without linear loss of speed? Storage of states on blockchains?

This article is a “dry residue” of thoughts on how to approach the solution of some inevitable problems in the system of distributed storage and state changes, financial processing in particular. The article is not to "cast in granite" any one point of view, but rather for the exchange of views and constructive criticism.
At once I will clarify: the described approaches work in accordance with the CAP theorem, do not allow data to move faster than the speed of light, and do not refute any other fundamental laws of nature.
')
Financial processing, a bird's-eye view, is a data structure that stores a set of states (balance sheets) and a history of changes in these states. A program is attached to this structure, which determines the logic in accordance with which state changes are made. It seems to be not particularly difficult.
But processing requires the ability to conduct transactions as quickly as possible, since its main user is not Alice who sent Bob 10 rubles, but online stores with thousands and tens of thousands of customers who, with a drop in conversion, due to accidents or brakes, will go to competitors without hesitation . (Actually, this seems to be the main reason why private processing cannot gobble up bitcoin).
For an approximate understanding of existing needs, you can build on VISA reports on how they prepare for New Year's peaks .
But as soon as we try to share the load, make the processing distributed (at each node there is a copy of the data and the ability to perform transactions), we will face the problem of data consistency. What is the actual problem?
When a database with a lot of replicas is created, the question always arises of how to resolve the ambiguity (inconsistency) of data, when in some nodes of the system the data have already been changed, and before the other nodes the changes are still “not reached”. With a parallel flow of changes, the system, from more than one node, simply can not always be in a consistent state (if you do not use the mechanisms described below).
Existing terminology defines several types of consistency:
This is a quotation of a Habrpost , in which there is much more interesting about the types of consistency, but for understanding the article these three are enough.
If we score consistency, we get a vulnerability called the race condition. In practice, this is exploited as “double waste” (Double Spending is the most obvious way but far from the only) when two purchases are made for the same money if the time between purchases is less than the replication time. There is no need to go far for an example. How to deal with it?
Modern distributed storage systems support different conditions under which the state change (commit) is recognized as successful, that is, the same state is available on all nodes of the network and is recognized by them as true. With proper “cooking,” these conditions can be very tight on life. For example, in cassandra db modes are supported:
A general commit may seem salutary, but:
In summary, a total commit might be good for redundancy, supporting a small number of hot copies, but is detrimental to speed and useless against a large number of transactions. Partly because of this, the majority of modern successful (that is, large and growing) processings are very affected in the base area.
From all that has been written, it is possible to derive the properties that a distributed structure must possess in order to claim the role of a part of modern processing:
Here an interesting feature of the working conditions of processing can come to the rescue. Transactions for the withdrawal of funds are made in it, in 95-99% of cases, by living people who do not really need immediate system readiness for the next transaction (10-60s). Moreover, a fast transaction flow for write-off is sometimes specifically blocked, since it is a sign of quick withdrawal in case of theft (when there is a limit on the size of a single transaction). If you go back to the example of an online store with thousands of customers, then individually, the customer does not pay often.
Based on this property, we can describe a system that allows using the post-transaction time for an inconsistency window. That is, after each transaction from a particular account, we will have a certain time interval T, which will be less than or equal to the data replication speed in the system and during which transactions from this and only this account will be impossible, but not more than the one that affects user experience 95-99% of customers. First, a few terms.
Necessary for ease of perception.
First, consider the special case when the system is in a consistent state, that is, the chain for an attacking account is the same on all nodes at the time of creating two conflicting transaction requests on different nodes of the system. In order to exclude the possibility of simultaneously processing a transaction request on two different nodes, we introduce the routing created by the nodes. Moreover, in such a way that 2 conflicting requests for the transaction could not be processed and included in the chain on 2 different nodes. How to do it?
In order for the system to not have a single point of failure and scale horizontally (and also have a lot of nice features), it is reasonable to make routing based on the well-studied DHT protocol - Kademlia.
What is DHT and why is one here? In short, DHT is a space of values (for example, all possible values of the md5 hash function), which is evenly divided between network nodes.

In the picture, an example of a space of values of 0-1000, which is distributed between nodes A, B, C, D, E, in this case is not uniform.
In a DHT network, nodes contain information about the N nearest neighbors, and if you need to find a particular hash from a shared value space, by sending a request to such a network, you can relatively quickly find the node responsible for that part of the value space where the desired hash is located .
To understand how quickly, 2 graphics with the dependence of the number of hops in the search for the classic implementation of Kademlia:
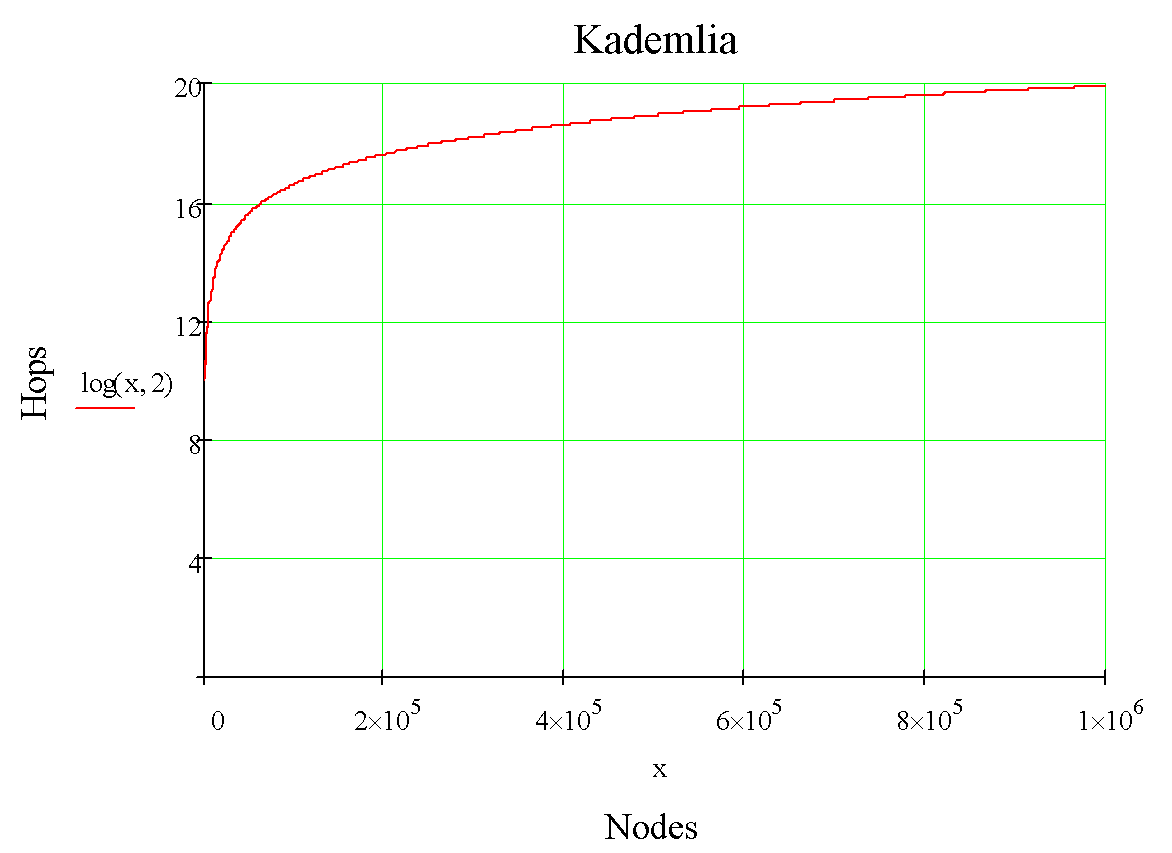
And optimized:
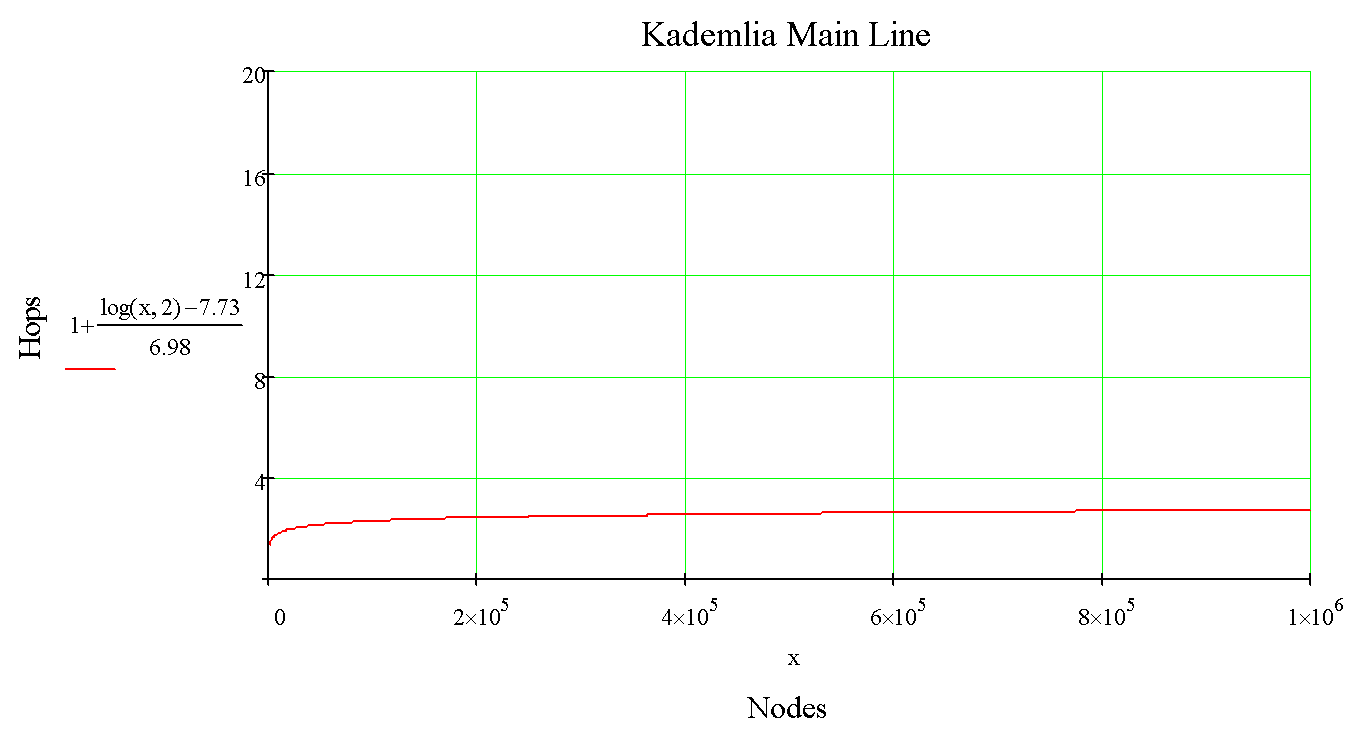
As the number of hops in routing grows logarithmically, the network has outstanding horizontal scaling potential.
By the way, DHT is used in Cassandra DB and Amazono Dynamo, but with an important difference, there it is used only for navigating shard data, and in case of changing the replicated data, the methods described in the introduction are used.
How to make so that at change of the data in mirror replicas to exclude parallel change of the data on different replicas?
To do this, we will consider the hash from the last transaction in the chain and use it as the value from the namespace, which is divided between the network nodes. Thus, on both nodes where conflicting requests for a transaction were created, the resulting value will be the same (since in accordance with the chain on the nodes in a consistent state). Further, using this value in the DHTsearch function, our requests will be “pointed” to one and only one node, on which requests will be processed sequentially. But this is in the case of initial consistency, which in the real world exists only on paper :)
Now consider the general case when the system is in a non-consistent state, that is, the number of transactions in the chain of a particular account may differ from node to node. Therefore, it is possible that 2 conflicting transactions will be received at nodes N1 and N2, where chains of different degrees of relevance (different recent transactions from which the hash is calculated), because of which requests for transactions will seem to be “hovering” on nodes N3 and N4 accordingly, where they will be processed, which will lead to the "branching" of the chain, which should not be allowed. If we consider this problem in detail, it does not exist, since we have an unequivocal connection:
..> transaction> processing node> next transaction> ..
that for different transactions of the same chain can be represented like this:
R - route (value from a shared namespace)
N - the node on which the next transaction is processed
T - transaction
hash (T0) = R1 - destination, or the route to the node on which T1 will be processed
R1 -> Nx - we aim at the node
Nx -> hash (T1) - create a new route if T1 is processed successfully and included in the chain
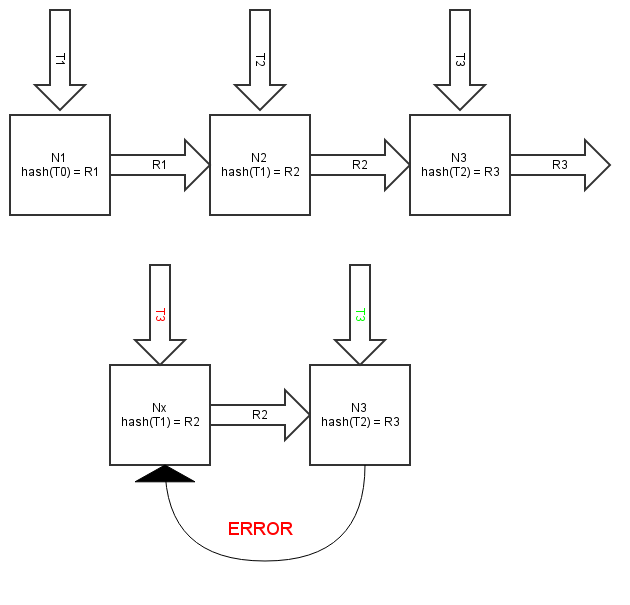
From this it follows that if a transaction request arrives at a “lagging” node, where the outdated version of the chain is, then this transaction request will be “pointed” to the node where the most recent transaction has already been created and saved, i.e. the last transaction hashes do not exactly match, and the request will be rejected. There is no branching of the chain.
Here it is better to go for tea.
A method of safe state change was described, but for the processing work this is not enough, you need an unequivocal knowledge of which state we are changing into which:
A small change in terminology - transactions, within the framework of this section, for simplicity of perception, are called incoming or outgoing transfers.
How is all this achieved when transferring from IDa and IDb to IDc accounts, and then IDc does IDd transfer? The initial state (here, for simplicity, is presented as a table, where each transaction added to the chain of some of the accounts is a series added from below):
The balance that is on the account at the time of completion of the processing of the outgoing transfer is recorded in this transfer (data structure included in the chain). All subsequent incoming transfers in this value are not entered into the “linked” transfer in any way and exist only as outgoing transfers on the chains of senders' accounts.
Processing confirmations - a field in which it is noted whether the means of this transaction were used, that is, if A and B translate C, then this value is set to NULL in these translations, and after C translates D, then this value is for A and B will be changed to the hash of the transaction in which these funds participated (C => D).
In the “Hash of the previous confirmed” field, there will be respectively for each chain A and B the hash from the previous confirmed transaction in these chains, in which the “processing confirmation” field is not zero, is entered. (why is it described below)
The balance in C => D is calculated in the following steps:
This algorithm allows you to uniquely fix the balance when translating performed on a node locally, while simultaneously receiving data that allows you to safely make the next transfer on a distributed system.
When it comes to a distributed system, it is possible that the data on incoming transfers on the node on which the next transfer will be performed will be inconsistent with the data from the node where the previous transfer was performed: the "processing confirmation" field will also be set to NULL for transfers , which were used to calculate the balance in the previous transfer, as a result, these transfers can be credited again, which cannot be allowed.
In order to detect such states, the “incoming checksum” field is used, in which the hash from the hashes of all incoming transfers that were used as part of the outgoing processing is saved.
Using this value, before processing a new N translation, you can check the consistency of incoming translations for N-1 translation, by collecting them (by value from the `processing confirmation` field), calculating the HASH hash (CONCAT (INCOME_BLOCKS)) from them and comparing it with the hash in the Checksum Incoming field in the N-1 translation. In the event of a mismatch, the transfer request is rejected.
Since the consistency of the last incoming transfers is verified by the described method, there is a possibility that due to the erroneous (or deliberate) resetting of the confirmation field in some old incoming transfer that was used to calculate the balance sometime in the past, this is the old incoming transfer when processing A new transfer may be counted by the recipient again, which cannot be allowed.
In order to prevent this situation, the “previous confirmed hash” field is used, where the previous translation hash is set up with a non-zero confirmation, calculated using the value from this field (“previous confirmed hash”), so we create a double connection in the sender's chain: the fact of transfer and the fact of receipt, i.e. use by the recipient. And if, due to zeroing (which destroys one of the links), confirming this transfer “pops up” when calculating incoming ones, it will be rejected at the integrity control stage of the sender's chain.
As a result, the final translation IDc => IDd will look like this:
If for routing cryptographic, that is, one that has the property of uniform distribution of values, is used as a hash function, all requests for a transaction from different accounts will be distributed evenly across all nodes, where they will be processed independently of each other, i.e. the load will be distributed evenly.
The loss of one node in the network will result in the system not being able to process only transactions directed to this node. This problem can be solved by creating standby copies for each node in a simple case or by dynamically redistributing the name space between the remaining nodes (which should be done VERY carefully).
Despite the complexity of the presentation, I hope I was able to convey fundamental differences with traditional systems. If you have found the strength to read this line up, then, probably, while waiting for the link to the githab, where will the collected concept already be? Unfortunately, there is no practical PoC yet, however, the publication of this article is an attempt to collect the pitfalls that I could miss. And one more step closer to practical implementation, so that all comments, constructive criticism, possible jambs are very welcome!
Introduction
This article is a “dry residue” of thoughts on how to approach the solution of some inevitable problems in the system of distributed storage and state changes, financial processing in particular. The article is not to "cast in granite" any one point of view, but rather for the exchange of views and constructive criticism.
At once I will clarify: the described approaches work in accordance with the CAP theorem, do not allow data to move faster than the speed of light, and do not refute any other fundamental laws of nature.
')
Processing problem
Financial processing, a bird's-eye view, is a data structure that stores a set of states (balance sheets) and a history of changes in these states. A program is attached to this structure, which determines the logic in accordance with which state changes are made. It seems to be not particularly difficult.
But processing requires the ability to conduct transactions as quickly as possible, since its main user is not Alice who sent Bob 10 rubles, but online stores with thousands and tens of thousands of customers who, with a drop in conversion, due to accidents or brakes, will go to competitors without hesitation . (Actually, this seems to be the main reason why private processing cannot gobble up bitcoin).
For an approximate understanding of existing needs, you can build on VISA reports on how they prepare for New Year's peaks .
But as soon as we try to share the load, make the processing distributed (at each node there is a copy of the data and the ability to perform transactions), we will face the problem of data consistency. What is the actual problem?
When a database with a lot of replicas is created, the question always arises of how to resolve the ambiguity (inconsistency) of data, when in some nodes of the system the data have already been changed, and before the other nodes the changes are still “not reached”. With a parallel flow of changes, the system, from more than one node, simply can not always be in a consistent state (if you do not use the mechanisms described below).
Existing terminology defines several types of consistency:
- Strict consistency - after changing the data, the updated version is available immediately on all nodes of the system.
- Weak consistency - the system does not guarantee that subsequent accesses to the data will return the updated value. Before the updated value is returned, a number of conditions must be met. The period between the update and the moment when each observer is always guaranteed to see the updated value is called the inconsistency window.
- Eventual consistency is a special case of weak consistency. The system ensures that in the absence of new data updates, ultimately, all requests will return the latest updated value. In the absence of failures, the maximum inconsistency window size can be determined based on factors such as communication latency, system load, and number of replicas according to the replication scheme. The most popular system implementing “consistency in the long run” is DNS. The updated entry is distributed in accordance with the configuration parameters and settings of the caching intervals. Ultimately, all customers will see the update.
This is a quotation of a Habrpost , in which there is much more interesting about the types of consistency, but for understanding the article these three are enough.
If we score consistency, we get a vulnerability called the race condition. In practice, this is exploited as “double waste” (Double Spending is the most obvious way but far from the only) when two purchases are made for the same money if the time between purchases is less than the replication time. There is no need to go far for an example. How to deal with it?
Modern distributed storage systems support different conditions under which the state change (commit) is recognized as successful, that is, the same state is available on all nodes of the network and is recognized by them as true. With proper “cooking,” these conditions can be very tight on life. For example, in cassandra db modes are supported:
- general commit - changes passed without errors on all nodes
- kommit by quorum - on most nodes the changes occurred without errors
- commit by the number of successes - on N nodes, changes occurred without errors
A general commit may seem salutary, but:
- It does not scale well, since the relationship between the time required for a successful commit is linear (in the best case) depends on the number of nodes in the cluster.
- The same transaction is processed on all nodes, which does not solve the problem of load distribution.
In summary, a total commit might be good for redundancy, supporting a small number of hot copies, but is detrimental to speed and useless against a large number of transactions. Partly because of this, the majority of modern successful (that is, large and growing) processings are very affected in the base area.
Task
From all that has been written, it is possible to derive the properties that a distributed structure must possess in order to claim the role of a part of modern processing:
- Inability to race condition when conducting transactions
- Strict consistency in fixing the balance during the transaction
- Uniform distribution of computational load
- Capacity nodes with the influence on the optimal rate of linear
- No single point of failure
Here an interesting feature of the working conditions of processing can come to the rescue. Transactions for the withdrawal of funds are made in it, in 95-99% of cases, by living people who do not really need immediate system readiness for the next transaction (10-60s). Moreover, a fast transaction flow for write-off is sometimes specifically blocked, since it is a sign of quick withdrawal in case of theft (when there is a limit on the size of a single transaction). If you go back to the example of an online store with thousands of customers, then individually, the customer does not pay often.
Based on this property, we can describe a system that allows using the post-transaction time for an inconsistency window. That is, after each transaction from a particular account, we will have a certain time interval T, which will be less than or equal to the data replication speed in the system and during which transactions from this and only this account will be impossible, but not more than the one that affects user experience 95-99% of customers. First, a few terms.
Terms and Definitions
Necessary for ease of perception.
- Transaction - a change in account status. The same as the translation.
- An account is a certain ID with which some state (balance) is associated, which is changed by transactions.
- Chain is a chain of debit transactions associated with an ID. It is designed like a classic block chain. Technically, this is a write-off transaction log, where in each subsequent transaction there is a hash sum of the previous ones, this relationship gives two important properties
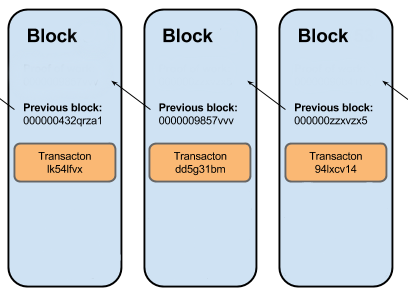
- Monitored transaction sequence
- Integrity control (not to be confused with authenticity control!). If any of the transactions have been changed, then through checking the hashes it will immediately become noticeable.
- A transaction request is a data structure in which the information necessary for conducting a transaction (to whom and how much) is located, but according to which the transaction has not yet been carried out and some decision on correctness has not yet been made
- A node is a program that stores a replica of all the chains in the system, ensures that the replica is up-to-date, processes transactions, creates new blocks (transactions and routes requests for transactions. A set of nodes forms a network or system.
- A system is a set of nodes that forms a network and that receives requests for transactions at the input. The system works in a trusted environment: the nodes trust each other, that is, the Byzantine problem does not solve the problem.
How to protect against race condition
First, consider the special case when the system is in a consistent state, that is, the chain for an attacking account is the same on all nodes at the time of creating two conflicting transaction requests on different nodes of the system. In order to exclude the possibility of simultaneously processing a transaction request on two different nodes, we introduce the routing created by the nodes. Moreover, in such a way that 2 conflicting requests for the transaction could not be processed and included in the chain on 2 different nodes. How to do it?
In order for the system to not have a single point of failure and scale horizontally (and also have a lot of nice features), it is reasonable to make routing based on the well-studied DHT protocol - Kademlia.
What is DHT and why is one here? In short, DHT is a space of values (for example, all possible values of the md5 hash function), which is evenly divided between network nodes.
In the picture, an example of a space of values of 0-1000, which is distributed between nodes A, B, C, D, E, in this case is not uniform.
In a DHT network, nodes contain information about the N nearest neighbors, and if you need to find a particular hash from a shared value space, by sending a request to such a network, you can relatively quickly find the node responsible for that part of the value space where the desired hash is located .
To understand how quickly, 2 graphics with the dependence of the number of hops in the search for the classic implementation of Kademlia:
And optimized:
As the number of hops in routing grows logarithmically, the network has outstanding horizontal scaling potential.
By the way, DHT is used in Cassandra DB and Amazono Dynamo, but with an important difference, there it is used only for navigating shard data, and in case of changing the replicated data, the methods described in the introduction are used.
How to make so that at change of the data in mirror replicas to exclude parallel change of the data on different replicas?
To do this, we will consider the hash from the last transaction in the chain and use it as the value from the namespace, which is divided between the network nodes. Thus, on both nodes where conflicting requests for a transaction were created, the resulting value will be the same (since in accordance with the chain on the nodes in a consistent state). Further, using this value in the DHTsearch function, our requests will be “pointed” to one and only one node, on which requests will be processed sequentially. But this is in the case of initial consistency, which in the real world exists only on paper :)
Now consider the general case when the system is in a non-consistent state, that is, the number of transactions in the chain of a particular account may differ from node to node. Therefore, it is possible that 2 conflicting transactions will be received at nodes N1 and N2, where chains of different degrees of relevance (different recent transactions from which the hash is calculated), because of which requests for transactions will seem to be “hovering” on nodes N3 and N4 accordingly, where they will be processed, which will lead to the "branching" of the chain, which should not be allowed. If we consider this problem in detail, it does not exist, since we have an unequivocal connection:
..> transaction> processing node> next transaction> ..
that for different transactions of the same chain can be represented like this:
R - route (value from a shared namespace)
N - the node on which the next transaction is processed
T - transaction
hash (T0) = R1 - destination, or the route to the node on which T1 will be processed
R1 -> Nx - we aim at the node
Nx -> hash (T1) - create a new route if T1 is processed successfully and included in the chain
From this it follows that if a transaction request arrives at a “lagging” node, where the outdated version of the chain is, then this transaction request will be “pointed” to the node where the most recent transaction has already been created and saved, i.e. the last transaction hashes do not exactly match, and the request will be rejected. There is no branching of the chain.
Here it is better to go for tea.
Strict balance consistency
A method of safe state change was described, but for the processing work this is not enough, you need an unequivocal knowledge of which state we are changing into which:
- Local unambiguity - on the node on which the transaction is processed, it should be possible to uniquely “fix the balance” and exclude the possibility of re-using funds
- Inbound consistency - elimination of the possibility of double use of incoming funds in case of inconsistency of data on incoming funds on nodes when conducting two consecutive transactions (which, in accordance with the routing, will be performed on different nodes, and control through the routability of one chain does not guarantee the consistency of others routed independently ).
A small change in terminology - transactions, within the framework of this section, for simplicity of perception, are called incoming or outgoing transfers.
How is all this achieved when transferring from IDa and IDb to IDc accounts, and then IDc does IDd transfer? The initial state (here, for simplicity, is presented as a table, where each transaction added to the chain of some of the accounts is a series added from below):
| Hash previous | ID the sender | ID recipient | Transfer | Balance | the confirmation | Control the sum incoming | Previous hash confirmed |
|---|---|---|---|---|---|---|---|
| Ba | IDa | IDc | Xa | Ya | Null | Ha | Null |
| Bb | IDb | IDc | Xb | Yb | Null | Hb | Null |
The balance that is on the account at the time of completion of the processing of the outgoing transfer is recorded in this transfer (data structure included in the chain). All subsequent incoming transfers in this value are not entered into the “linked” transfer in any way and exist only as outgoing transfers on the chains of senders' accounts.
Processing confirmations - a field in which it is noted whether the means of this transaction were used, that is, if A and B translate C, then this value is set to NULL in these translations, and after C translates D, then this value is for A and B will be changed to the hash of the transaction in which these funds participated (C => D).
In the “Hash of the previous confirmed” field, there will be respectively for each chain A and B the hash from the previous confirmed transaction in these chains, in which the “processing confirmation” field is not zero, is entered. (why is it described below)
The balance in C => D is calculated in the following steps:
- SELECT `Translation` FROM transactions WHERE` Recipient ID` = IDc AND `processing confirmation` = NULL; Thus, we get the sum of all incoming funds that were transferred during the time period from the previous outgoing transfer with IDc.
- We consider the total balance by adding the value obtained in claim 1 to the balance value recorded in the last transfer IDc.
- We check the integrity of the sender's chains and whether the requested transfer meets all the necessary conditions, at a minimum, that the result is not negative. Subtract the transfer from the amount received in paragraph 2.
- If everything is ok, then we write another translation to the table, and we’ve set the hash of this transfer to the field “confirmation of processing” and “the hash of the previous confirmed one.” Yc is the IDc balance immediately after the transfer.
This algorithm allows you to uniquely fix the balance when translating performed on a node locally, while simultaneously receiving data that allows you to safely make the next transfer on a distributed system.
When it comes to a distributed system, it is possible that the data on incoming transfers on the node on which the next transfer will be performed will be inconsistent with the data from the node where the previous transfer was performed: the "processing confirmation" field will also be set to NULL for transfers , which were used to calculate the balance in the previous transfer, as a result, these transfers can be credited again, which cannot be allowed.
In order to detect such states, the “incoming checksum” field is used, in which the hash from the hashes of all incoming transfers that were used as part of the outgoing processing is saved.
Using this value, before processing a new N translation, you can check the consistency of incoming translations for N-1 translation, by collecting them (by value from the `processing confirmation` field), calculating the HASH hash (CONCAT (INCOME_BLOCKS)) from them and comparing it with the hash in the Checksum Incoming field in the N-1 translation. In the event of a mismatch, the transfer request is rejected.
Since the consistency of the last incoming transfers is verified by the described method, there is a possibility that due to the erroneous (or deliberate) resetting of the confirmation field in some old incoming transfer that was used to calculate the balance sometime in the past, this is the old incoming transfer when processing A new transfer may be counted by the recipient again, which cannot be allowed.
In order to prevent this situation, the “previous confirmed hash” field is used, where the previous translation hash is set up with a non-zero confirmation, calculated using the value from this field (“previous confirmed hash”), so we create a double connection in the sender's chain: the fact of transfer and the fact of receipt, i.e. use by the recipient. And if, due to zeroing (which destroys one of the links), confirming this transfer “pops up” when calculating incoming ones, it will be rejected at the integrity control stage of the sender's chain.
As a result, the final translation IDc => IDd will look like this:
| Hash previous | ID the sender | ID recipient | Transfer | Balance | the confirmation | Control the sum incoming | Previous hash confirmed |
|---|---|---|---|---|---|---|---|
| Ba | IDa | IDc | Xa | Ya | HASH (LAST_C_BLOCK) | Ha | HASH (LAST_CONFIRMD_A_BLOCK) |
| Bb | IDb | IDc | Xb | Yb | HASH (LAST_C_BLOCK) | Hb | HASH (LAST_CONFIRMD_A_BLOCK) |
| Bc | IDc | Idd | Xc | Yc | Null | HASH (CONCAT (INCOME_BLOCKS)) | Null |
About load sharing
If for routing cryptographic, that is, one that has the property of uniform distribution of values, is used as a hash function, all requests for a transaction from different accounts will be distributed evenly across all nodes, where they will be processed independently of each other, i.e. the load will be distributed evenly.
fault tolerance
The loss of one node in the network will result in the system not being able to process only transactions directed to this node. This problem can be solved by creating standby copies for each node in a simple case or by dynamically redistributing the name space between the remaining nodes (which should be done VERY carefully).
Conclusion
Despite the complexity of the presentation, I hope I was able to convey fundamental differences with traditional systems. If you have found the strength to read this line up, then, probably, while waiting for the link to the githab, where will the collected concept already be? Unfortunately, there is no practical PoC yet, however, the publication of this article is an attempt to collect the pitfalls that I could miss. And one more step closer to practical implementation, so that all comments, constructive criticism, possible jambs are very welcome!
References
Source: https://habr.com/ru/post/261549/
All Articles