Creating a scalable distributed application from scratch
How did it start
All my life I have been developing under Windows. First in C ++, then in C #. In between flashed VB, Java Script and other vermin. However, some time ago, everything changed and I first encountered the world of Linux, Java and Scala. Denis and I, my friend and colleague on numerous ideas, already had our own project - a set of utilities for Windows, which enjoyed wide demand in narrow circles. At some point we both lost interest in this project and the question arose of what to do next. Denis initiated the idea of a new project - a service for exchanging clipboard between different devices. This project was significantly different from the previous one in addition to technology, and also the target audience. This service was supposed to be useful to everyone. Copy the data to the clipboard and paste from it on any other device. It sounds easier nowhere, until you think about how many different devices are there now, and how it will work with a large number of users.
The first prototype appeared a few months later. The server was written in ASP.NET and hosted on MS IIS. 2 clients were written: in C ++ under Windows and in Java under Android.
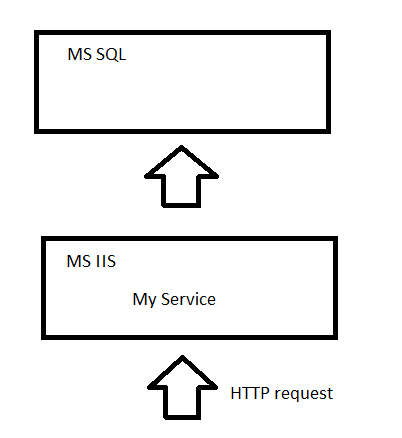
Testing has shown that the prototype holds about 500 compounds. What to do if there are more of them, we are counting on hundreds of thousands of users;) How to write a server that can work with a large number of connections, which will not need to be turned off during the upgrade of hardware or software and which will easily scale (i.e. expand in case of increasing the number of users).
Distributed scalable system
For me, such complex terms as “distributed scalable system” (a good article ) usually remain an empty sound until I understand what it stands for in terms of technology and products. It is not enough for me to know the characteristics of such systems and I want to try to create such a system myself in order to realize all its advantages and disadvantages.
')

So, a scalable system must have several nodes (nodes) so that in case of an increase in load we can add new nodes and in the event of a single node failure, the rest would continue to work. The node is an iron or a virtual machine. In this and other drawings, each square is a service, in accordance with the best traditions of SOA (Service-Oriented Architecture). In the future we will talk about where and how you can locate these services.
What modern companies write their servers. For example, Twitter uses a functional language, Scala, and has its own Finagle library ( The twitter stack ). Scala allows you to write non-blocking ( non blocking ), immutable code. The first is important to save server resources, because the thread does not wait for the release of any resource, for example, during IO (input output) operations. The second allows you to parallelize the code at any time and perform calculations in different threads without additional synchronization efforts. We started writing a new server on Scala and first using Finagle, but later moved to the Play framework . The advantage of the second is that it develops more dynamically and many plug-ins constantly appear to it.
In order for clients to quickly receive information about adding a new clipboard to the server, we used the long poll technology. The client accesses the service and if the service does not have new data, it does not immediately respond to the client, but keeps the connection for a given timeout, for example, 60 seconds. If during this timeout the server receives new data, it immediately returns it for the held connections. The client thus constantly repeats requests and waits for updated data.
With this mechanism, the services MyService1, MyService2, etc. should be able to inform each other about the new buffer. For example, if a client hangs and waits for a result from MyService1, however, the buffer was added by another client on MyService2, then MyService1 should immediately find out about it. In order for services to notify each other about such changes, we used remote actors from the Akka library. Akka is a library that allows you to use objects without having to synchronize access to them. This is achieved by sending a message to each actor, and not making a direct call, and at a single point in time only one message is processed by actor. In addition, Akka allows you to call actors from another service in the same way as local actors. The mechanism of remote actors hides interworking, which greatly facilitates the development. Thus, using Akka MyService1 (and any other service) can notify all other services if new data is supplied to it.
Where does MyService1 find out the IP addresses of MyService2 and MyService3. We used ZooKeeper to store the system configuration. Thus, each service knows the IP address of ZooKeeper and can register on it, as well as get information from it about what other nodes are in the system.

The figure shows that although we have created a scalable system where you can add or remove nodes directly into runtime, however the database is the same and it remains a weak point of the system. Each call to the database is quite a long operation. In order to reduce the load on the base and increase the overall system performance, we decided to add a cache. As a cache, it was decided to use Redis. Redis is an in-memory data storage in key-value (NoSQL key-value data store) format. Although it doesn't sound very clear, the idea is very simple. Redis allows you to get values by key and stores it all in memory. Thus, the call to Redis is very fast. In order to use Redis, our service was changed accordingly and began to apply for new data first to Redis and only then, if no data were found, to the database. Correspondingly, when a new buffer arrived, it immediately got into the base and into the cache.

The number of squares in our scheme is continuously increasing, but the reliability of the system also increases. Remove MyService2 and the requests will continue to process MyService1 and MyService3. Remove Redis and services will directly receive data from the database. Remove ... No, we don’t need to remove DB and ZooKeeper yet, as this will bring down our entire system :)
In order to ensure the reliability of the database, it must support replication. We chose the NoSQL MongoDB database. Our services have a JSON interface and it is more convenient to store the results in JSON format, which is supported by MongoDB. In addition, MongoDB perfectly supports replication, we can run several nodes with MongoDB, link them into one replica, and in the event of a node failure, all clients can continue to work with other nodes. Replicas in MongoDB must consist of at least 3 nodes: the main (primary) node, the secondary (secondary) and the arbiter (arbiter) that monitors the other nodes, and if the main node fails, it becomes the secondary node.

Now we can safely turn off one of the nodes with MongoDB and our system will not even notice it. I will not dwell on ZooKeeper in detail, but it will not be the Hech's heel of our system, as well as MongoDB supports replication.
A meticulous reader will notice that I have bypassed the question of how requests are distributed between MyService1, MyService2 and MyService3 nodes. In serious systems, a load balancer is used for this - load balancer. However, if you are already tired of the infinite number of support services in our system, you can use DNS as a simple load balancer. When a request to the api.myservice.com service comes to DNS, it returns several IP addresses. The trick is that for each request, the order of these IP addresses changes. For example, for the first request api.myservice.com returned: 132.111.21.2, 132.111.21.3, 132.111.21.4 and for the second 132.111.21.3, 132.111.21.4, 132.111.21.2, respectively, customers always try to first access the first IP from the list and only In case of error will use the 2nd or 3rd.

Deployment
As a result, we have built a truly scalable (you can add and remove service nodes), distributed (services can be located on different nodes and even in different data centers) system.
Let's check whether our application meets the basic requirements for such systems.
- Accessibility - our system is always available. If we change the iron for any node, the other nodes continue to work. We can also update the software one by one.
- Performance - using more complex load balancers, we can direct European users to the European node, and users from America to the American node. In addition, the use of Redis significantly reduces access to the database.
- Reliability - when any node fails, the remaining nodes continue to work
- Scalable - you can add as many MyServiceN
- Handling - hmmm, there are still questions, aren't there?
- Cost - all technologies and libraries used in this project are free and / or open source
Thus, only one criterion remained under question - controllability. What is the easiest way to deploy SOA systems consisting of dozens of services? We decided to use a fairly new, but well-proven technology - Docker. Docker is somewhat similar to widely used virtual machines, but it has several advantages. Using Docker you can create a docker container for each service, and then run them all either on the same or on different machines. The important point is that since Docker uses Linux’s built-in virtualization mechanism, it doesn’t require additional resources, unlike virtual machines. So we created containers for all nodes of our system. This makes it equally easy to deploy a test environment where all containers are running on one node and a working environment where each container is on its own node.
At some point we faced the question of where to place our system. Considered the most popular cloud provider - Amazon, however, decided to save money and place our application on a cheaper Digital Ocean.
Source: https://habr.com/ru/post/261509/
All Articles