Analyzing unusual firmware: analysis of the contest Best Reverser
When we invented the task for the reverse engineering contest , which took place on the PHDays V forum, we wanted to reflect the real problems that RE specialists face, but at the same time tried to avoid patterned solutions.
How usually look puzzles on the reverse? There is an executable file under Windows (or Linux, or MacOS, or another popular operating system), you can run it, look under the debugger, and turn it as you like in virtual environments. The file format is known. Processor Command System - x86, AMD64 or ARM.
')
Library functions and system calls are documented. Access to equipment - only through the mechanisms of the operating system.
With the use of existing tools (for example, IDAPro with HexRays and all related capabilities), the analysis of such applications becomes almost childish fun: everything works out simply and quickly.
Of course, sometimes to add complexity to the program, virtual machines are added with their own instruction set, code littering, protection against debugging, etc. But to be honest, how often do large software vendors use all this in their executable files? Yes, almost never! What is the point of making a contest aimed at demonstrating skills that are rarely required in real life?
However, there is another area of application for reverse engineering, which is increasingly in demand in recent years, firmware analysis. And then the situation is not the same as in the traditional RE.
The input file (with firmware) can be in any format, it can even be packed or encrypted. The operating system may not be at all popular - or it may even be missing. Part of the code can be hardcoded in the device and not updated through the firmware. The processor architecture can be any! IDAPro, for example, "knows" more than 100 different processors, but not all. And, of course, there is almost no documentation, debugging is almost never available, and often even normal code execution is impossible: there is firmware, but there is no device ...
We decided to offer approximately this task to the contestants (any Internet user could take part). Each of them had to analyze the executable file and find the correct key corresponding to its email.
First part: bootloader
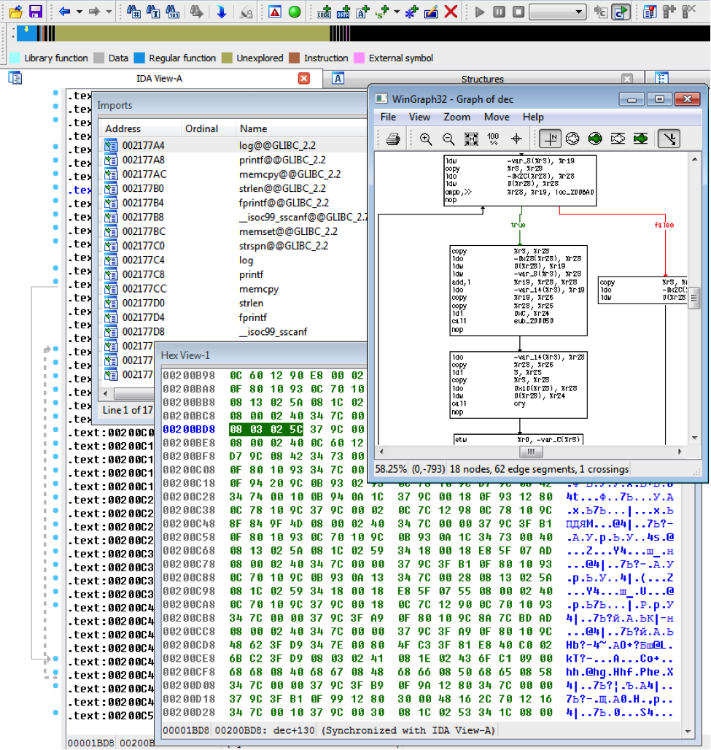
At the first stage, the input file was ELF, compiled by the cross-compiler for the PA-RISC architecture. IDA can work with this architecture, but not as well as with x86. Many calls to stack variables are not automatically recognized, and IDA has to be helped by hand. But at least all library functions are visible (log, printf, memcpy, strlen, fprintf, sscanf, memset, strspn) and even the symbolic names of some program functions (c32, exk, cry, pad, dec, cen, dde).
It's quite simple to understand that the program is waiting for two arguments to enter - email and key.
It is also easy to find out that the key should consist of two parts, separated by the symbol '-'. The first part (7 characters) should consist only of allowed MIME64 characters (0-9A-Za-z + /), and the second (32 characters) - from hexadecimal characters, which turn into 16 bytes.

Further, the
c32 function calls are c32 , folding in:t = c32(-1, argv[1], strlen(argv[1])+1)k = ~c32(t, argv[2], strlen(argv[2])+1)The name c32 is a hint: it is used by the RC32, which is confirmed by the constant
0xEDB88320 .Next comes the call to the dde function (short for doDecrypt), which takes the inverted CRC32 output in the first argument — the encryption key, and in the second and third, the address and size of the decrypted array.
Decryption is performed by the BTEA algorithm based on code borrowed from Wikipedia. You can guess that this is BTEA, you can use the constant
DELTA==0x9E3779B9 . True, it is used in other algorithms that are predecessors of the BTEA, but there are very few options.The key must be 128-bit, and CRC32 returns a 32-bit value, so three additional
exk (expand_key) are obtained in the exk (expand_key) function exk (expand_key) multiplying the previous value by the same DELTA value.True BTEA is not used very often. First, this algorithm has a custom block size, and the task uses a 12-byte block: if there are processors with 24-bit registers and memory cells, then why should the block size be a power of two? :) And secondly, the functions of encryption and decryption are interchanged - this is also possible.
Since the data stream is encrypted, blocking in CBC mode (Cipher Block Chaining) is applied. For the decrypted data in the function cen
(calc_enthropy) , the entropy is calculated, and if its value exceeds 7, the decryption result is considered invalid, and the program ends with the corresponding message.Since the encryption key is only 32 bits long, it may seem easy to pick it up. However, if you follow the logic of the program, to verify each key, you must first decrypt 80 kilobytes of data, and then calculate the entropy for them. And the search for the encryption key "in the forehead" will take too much time.
However, after entropy checking, another function is called, the pad (the original name is strip_pad), which checks and cuts
PKCS#7 padding . Because of the properties of the CBC mode, in order to check the addition, it is necessary to decrypt only one block (the last one), take the last byte N from it, check that its value lies in the range from 1 to 12 inclusive and that each of the last N bytes has the value N.This can significantly reduce the number of operations for checking one key, but if the last decrypted byte is 1 (and this will be true for 1/256 keys), you still have to do a full check ...
To find the key faster, it is enough to assume that the decrypted data will have a DWORD length (4 bytes). Then in the last DWORD of the last block there can be only one of the three possible values -
0x04040404 , 0x08080808 or 0x0C0C0C0C . And using such heuristics you can sort through all possible keys (and guaranteed to find the right one) in less than 20 minutes.If all checks after decryption (entropy and padding integrity) are successful, the fire_second_proc function is called, which simulates launching a second processor and loading decrypted data (firmware) into it - because in modern devices there are often more than one processor, and with completely different architectures.
If the second processor was successfully launched, the user’s email and 16 bytes with the second part of the key are sent to it via the send_auth_data function. In this place we accidentally made a mistake: instead of the size of the second part of the key, the size of the string with the email was used.
The second part: firmware
With the analysis of the second part is all somewhat more complicated. There is not ELF, but simply an image of memory - without headers, names of functions and other meta-information. And of course, neither the type of processor nor the address of the load is known.
The algorithm for determining the processor architecture that we conceived is a brute force. We open it in IDA, set the next type, look at the resulting garbage, and repeat until IDA shows something like code. A search should ideally lead to the conclusion that this is a big-endian SPARC.
Now you need to determine the download address. The function at offset 0x22E0 is not called anywhere, but it contains quite a lot of code. It can be assumed that this is the entry point into the program, the start function.
In the third statement of the start function, the unknown library function is called with one argument
== 0x126F0 , and the same function is called from start 4 more times, always with different, but close in value arguments ( 0x12718 , 0x12738 , 0x12758 , 0x12760 ). And in the middle of the program, starting at offset 0x2490 , there are just 5 text lines with messages: 00002490 .ascii "Firmware loaded, sending ok back."<0> 000024B8 .ascii "Failed to retrieve email."<0> 000024D8 .ascii "Failed to retrieve codes."<0> 000024F8 .ascii "Gratz!"<0> 00002500 .ascii "Sorry may be next time..."<0> If we assume that the download address is
0x126F0-0x2490 == 0x10260 , then all arguments when calling the library function will point to the lines exactly, and the unknown function itself will be the printf function (or puts, which is not important in this case).After changing the download base, the code will look like this:

The value
0x0BA0BAB0 , passed to the sub_12194 function, is also found in the first part of the job, in the fire_second_proc function, and is compared with what is obtained from read_pipe_u32() . So, sub_12194 should be called write_pipe_u32 .Similarly, the two library function
sub_24064 are memset(someVar, 0, 0x101) for email and code, and sub_121BC is read_pipe_str() , the reverse of write_pipe_str() from the first part.The very first function (at offset 0 or address
0x10260 ) has characteristic constants that allow it to accurately determine MD5_Init:
And right next to the place where
MD5_Init a single call, it is easy to detect the functions MD5_Update() and MD5_Final () , before which the library strlen() called.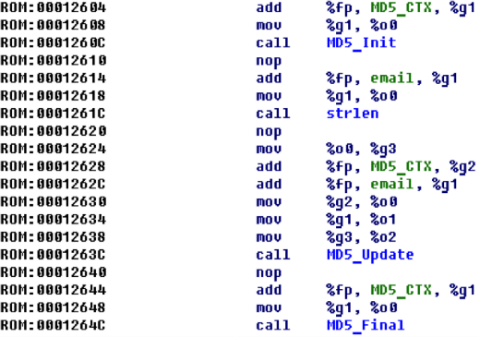
In the
start() function, very few unknown functions remain.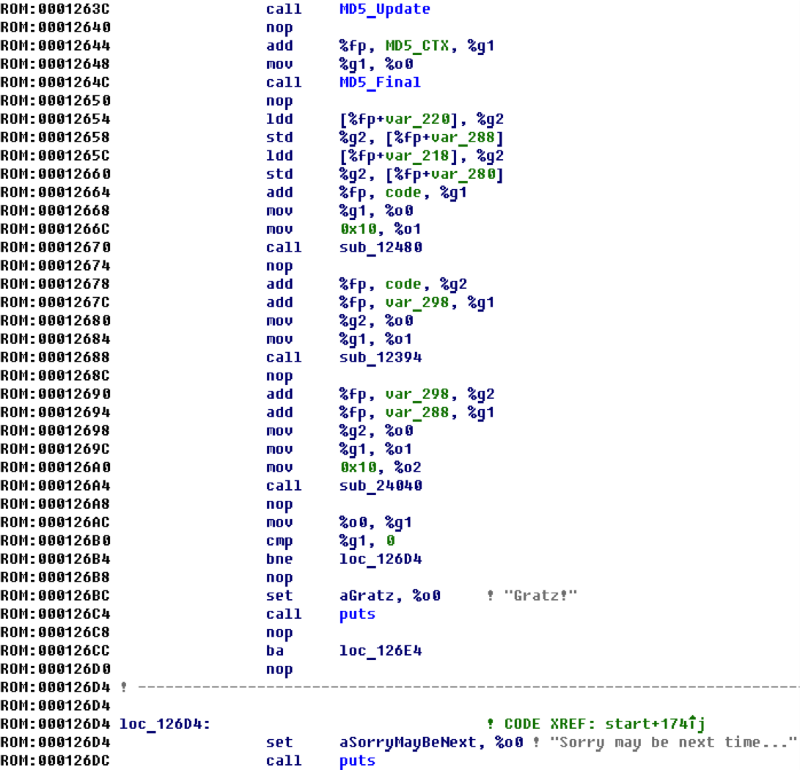
The
sub_12480 function reverses a byte array of a given length. In fact, this is a memrev, to the input of which an array of code 16 bytes is fed.It is obvious that in
sub_24040 a decision is made on whether the code was correct. In this case, the arguments are passed a pointer to the calculated MD5 (email) value, a pointer to an array filled in the sub_12394 function, and the number 16. It could well have been just a call to memcmp!The main magic is performed in the
sub_12394 function. There are almost no clues there, but the algorithm itself is described by one phrase - multiplication of a 128-bit binary matrix by a 128-bit binary vector. The matrix is stored in the firmware body at 0x240B8 .Thus, the code will be recognized as valid if
MD5(email) == matrix_mul_vector(matrix, code) .Calculating the correct key
To find the correct value of code, it is necessary to solve the system of binary equations described by the matrix, when the corresponding bits from MD5 (email) are on the right-hand side. If someone has forgotten linear algebra: this is easy to do by the Gauss method.
When the right part of the key is known (32 hexadecimal characters), it is necessary to select the first 7 characters so that the result of the CRC32 calculation is equal to the found value of the key for the BTEA. These values are approximately 1024 pieces, and you can search for them either by simple enumeration (fairly quickly), and by reversing CRC32 and checking valid symbols (generally instantly).
It remains to collect everything together and get a key that will pass all the checks and will be recognized as valid by our verifier :)
We were afraid that the task would be too complicated and no one could solve it independently from the beginning to the end. Fortunately, Viktor Alyushin showed that our fears were groundless, for which he thanks a lot :) His rantup with the solution of our competitive task: nightsite.info/blog/16542-phdays-2015-best-reverser.html We will remind you that Victor is victorious in Best Reverser second time: he was the best in 2013.
The second place, having completed only part of the task, was taken by the participant who asked not to publish his name.
Thanks to all the contestants!
Author : Dmitry Sklyarov, Head of Application Analysis, Positive Technologies
Source: https://habr.com/ru/post/261375/
All Articles