Google AI or Data Center in the power of artificial intelligence
Artificial intelligence (hereinafter AI) has always attracted not only science fiction writers and writers, but also ordinary inhabitants. Robots endowed with reason tease our curiosity and alarm our primitive fears, become characters of books and films. However, AI can be intangible, not endowed with a shell of metal or plastic. A set of programs and algorithms that can independently make decisions and change certain variables to obtain a given goal - this is also AI. Nowadays, when the future in the opinion of many science fiction writers has already arrived, many companies with great interest and enthusiasm look to the use of artificial intelligence in order to modernize the production process and provide goods and services. Who, if not the data centers, should stand at the origins of this, perhaps, revolutionary breakthrough.

One of the largest, in many understandings, a fan of AI is Google. We all know about the car, which is able to move on a busy road without direct human intervention, about smartphone applications that can recognize speech and communicate with a person, about search services that can instantly recognize digital images. All these fantastic things are developed not only by Google. Many companies, such as Facebook, Microsoft and IBM, also do not graze the back. This is a clear indicator of their extremely high interest in introducing AI into our daily life.
')

Google car
Many revolutionary projects are based on the use of AI in one form or another. Among them, Google Auto, IBM Watson (a supercomputer equipped with an AI question-answer system). These are quite loud and public projects. However, not the only, and not the most important. Most companies devote significantly more time and resources to the development of the so-called artificial intelligence “depth learning” system.
 IBM Watson (a supercomputer equipped with an AI question-answer system)
IBM Watson (a supercomputer equipped with an AI question-answer system)
It is this system that Google is developing in its data centers. Behind all Google services is a huge amount of data that requires processing and analysis. Accordingly, the company owns its huge data centers, which is not a secret. Currently, corporations have begun to use artificial neural networks in the data center, whose task is to analyze the work of the data center itself. Further, the data obtained are used to improve the operation of the data storage and processing structure. In fact, these neural networks are computer algorithms that can recognize patterns and make a certain decision based on the data obtained. This network can not be compared with human intelligence, but it can perform many tasks much faster and more efficiently. It is for this reason that Google uses these algorithms in the work of its data centers, precisely where speed means a lot.
The creator of AI for the data center Google has become a young engineer Jim Gao (Jim Gao), whom many of the team called the "young genius." At one time, he took an online lecture course at Andrew Ng, a professor at Stanford University. The professor is a leading expert in the field of studying AI.

Prof. Eun
Jim Gao used his “20% of the time” * to study the operation of artificial neural networks and how to use them in the work of the company's data centers.
Every few seconds, Google collects a huge amount of all sorts of data: indicators of energy consumed, the amount of water used in the cooling system, the temperature outside the data center, etc. Jim Gao created an AI system that would collect this information, process it and predict the level of performance of the data center. After 12 months, the model has been adjusted, due to even more new data. As a result, the prediction accuracy was 99.6%.
This AI system is a kind of preventive measure during the solution of a problem. At the moment, AI is engaged in the work of the main data center support systems (power supply, cooling, etc.). For example, an AI system can “offer” a replacement for a heat exchanger, which will improve the performance of the cooling system. A couple of months ago, the data center had to shut down a number of servers, which usually affects energy efficiency, but thanks to Jim Gao's AI, which controls the cooling system, technical work went smoothly, and the level of energy efficiency remained high throughout the entire time. AI, according to representatives of Google, may notice those small details that are not visible to a person, which makes it so effective.
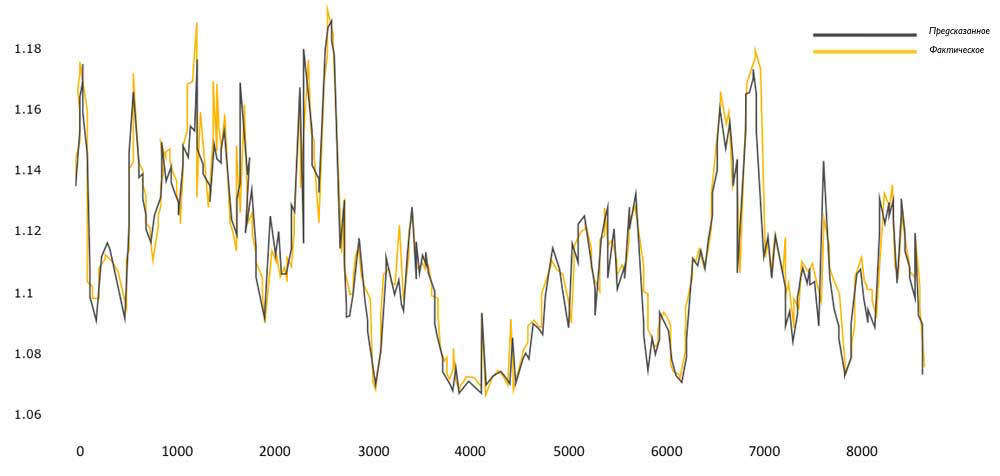
This graph shows the ratio of the predictions of the AI system and the actual performance of the PUE (Power usage effectiveness) energy efficiency.
Of course, we can not but rejoice at the success of Google, but it’s still interesting how this system works.
First of all, the task was set to determine precisely those factors that have the greatest impact on the level of energy efficiency (PUE). Jim Gao reduced the list to 19 factors (variables). After the artificial neural network was formed. This system had to analyze (or process, as it is more convenient to whom) a huge amount of data and look for patterns in them.
The difficulty lies in the quantity, as it is not funny, of everything. More precisely, in the number of variables. The amount of equipment, their combinations, compounds, factors of influence, such as weather conditions.
In more detail, this problem and methods of solving it in the context of using AI in the work of the data center Jim Gao describes in his work “machine learning in data center optimization”.
Here is what Jim Gao himself says in the introductory part of his work:
Model implementation
The input variable x - (mxn) is an array of data, where m is the number of training examples, and n is the number of features, which include IT load and weather conditions, the number of running coolers and cooling towers, the number of installed equipment, etc.
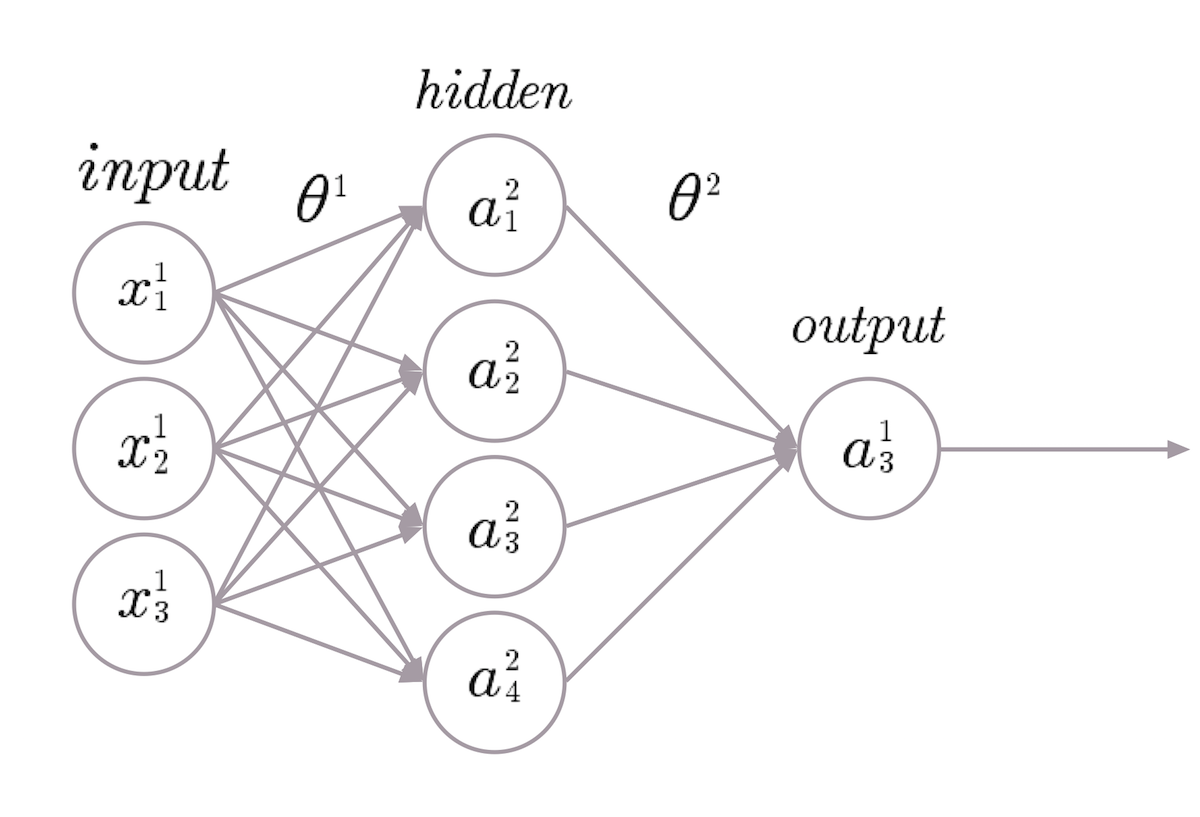
Ordinary three-layer neural network
The input matrix x is multiplied by the parameters of the model matrix θ 1 to obtain the hidden state of the matrix. In practice, a acts as an intermediate segment that interacts with the second parameter of the matrix θ 2 to calculate the initial data h θ (x) . The size and number of hidden layers directly depends on the complexity of the simulated system. In this case, h θ (x) is the variability of the output data, presented in the form of a certain range of indicators, which must be optimized. The level of energy efficiency is used in the formation of this system as an indicator of the efficiency of the data center. The range of indicators is a coefficient that does not reflect the total energy consumption of the data center. Other baseline data includes server utilization data to maximize productivity, or equipment failure data to understand how the data center infrastructure affects its reliability. The neural network is looking for a relationship between various data indicators, in order to form a mathematical model that calculates the source data h θ (x) . Understanding the basic mathematical principles of h θ (x) , one can control and optimize them.
Despite the fact that linear independence of indicators is not necessary, its use significantly reduces the training time of the system and reduces the number of retraining processes. In addition, this linear scorecard simplifies the model by limiting the number of input data exclusively to those indicators that are the most fundamental for the work of the data center. For example, the temperature in the openings of the cooling system is not an important indicator for the formation of the level of energy efficiency, as it is a consequence of the work of other systems (operation of cooling towers, temperatures of water condensate and chilled water entry points), the indicators of which are fundamental.
The learning process of the neural network can be divided into four main stages (+ the fifth stage, repeating steps 2-4):
1. Arbitrary initialization of parameters (patterns) of the model;
2. Implementation of the algorithm for further branching;
3. Calculate the cost function J (θ);
4. Implementation of the algorithm of reverse branching;
5. Repetition of points 2, 3 and 4 to achieve maximum convergence, or to achieve the required number of attempts.
1. Arbitrary initialization
Arbitrary initialization is the process of randomly assigning a value of θ between [-1, 1] immediately before the start of training a model. To understand why this is necessary, consider the scenario where all model parameters will be equal to 0. The incoming data in each subsequent layer of the neural network will be the same, since they are multiplied by θ (equal to 0). In addition, this error will spread in the opposite direction, through hidden layers, which will lead to the fact that any changes in the model parameters will also be absolutely identical. It is for this reason that the value of θ arbitrarily varies in the range [-1, 1] in order to avoid the formation of an imbalance.
2. Further branching
Further branching refers to the process of calculating each subsequent layer, since the value of each of them depends on the parameters of the model and on the layers preceding them. The initial data of the model is calculated by a further branching algorithm, where a l j reflects the activation of node l in layer j , and θ l is the data matrix (model parameters) transforming layer l into layer l +1 .
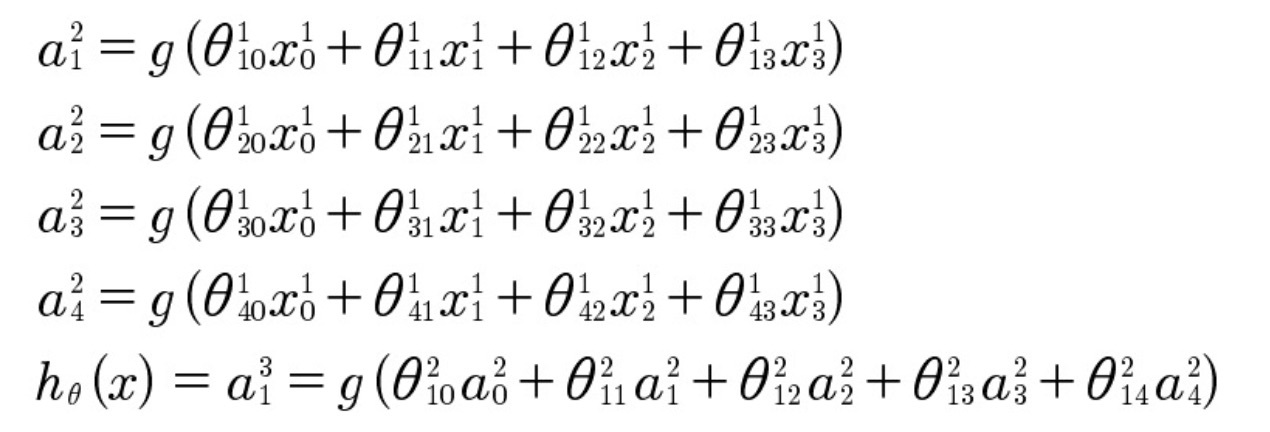
Basic parameters (nodes with a value of 1) are added to each dissimilar layer to represent a digital expression in each layer.
In the above equations, θ 1 10 represents the value between the added base parameter x 1 0 and the element of the hidden layer a 2 1 .
The purpose of the activation function x (z) is to simulate the operation of biological neural networks, by imposing input data on the source within the range (0, 1). It is given by the sigmoid logistic function g (z) = 1 / (1 + e -z )
It should be noted that the above equations can be expressed more compactly in matrix form:
a 2 = g (θ 1 x)
h θ (x) = a 3 = g (θ 2 a 2 )
3. Cost function
This function is a parameter that should decrease with each integration in the system learning process. The formula for this parameter is as follows:
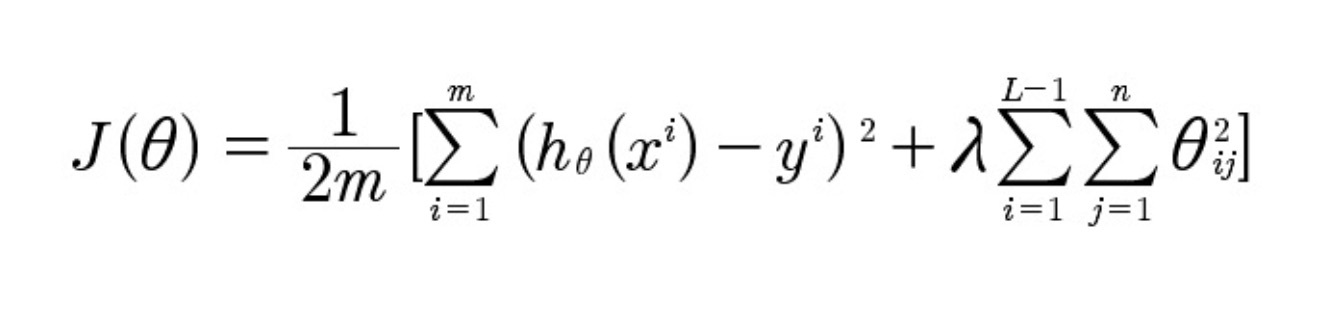
Where:
h θ (x) is the predicted calculated data;
y - the actual data corresponding to the output data;
m is the number of teaching examples per indicator;
L is the number of layers;
n is the number of nodes;
λ is the regulating parameter responsible for balancing between the accuracy of the system and the number of its retraining processes.
In this case, h θ (x) is the calculated level of energy efficiency, and y is the actual level of energy efficiency.
4. Reverse branching
After calculating the cost function, the error indicator δ is distributed to all layers in the reverse order to eliminate the value 0. The error in the output layer is defined as the difference between the calculated output data h θ (x) and the actual y .
For a three-layer neural circuit, the error associated with the output and hidden layers is expressed as:
δ 3 = a 3 - y
δ 2 = (θ 2 ) T. * g '(z 2 ) = (θ 2 ) T δ 3. * [a 2. * (1-a 2 )]
Where:
g '(z) is a derivative of the activation function. This expression can be simplified to the following form: a. * (1-a) .
There is no error exclusively in the first layer, since it is a combination of input data. For each layer, the error is calculated using the formulas below:
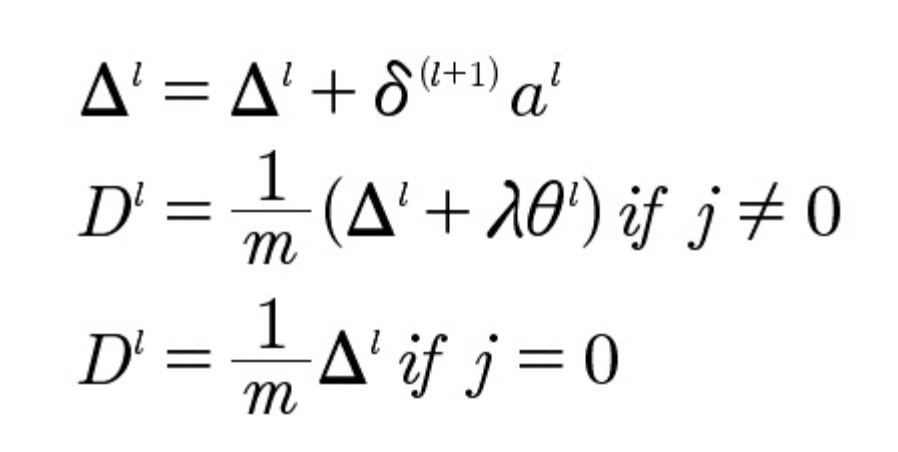
Where: Δ l is initialized as a vector of zeros. Dl is added to update the model of each layer before repeating items 2-4. By combining all the learning algorithms, this process can produce many (or, more precisely, hundreds of thousands) iterations before convergence is achieved, the process of achieving which is accelerated by the cost formula.
Implementation
This artificial neural network uses 5 hidden layers, 50 nodes in each layer, and the regularization parameter = 0.001. For calculations, 19 parameters are used. As a result, we get one parameter - the level of energy efficiency of the data center. Each of these parameters includes 184,435 examples of 5 minutes each (data on the operation of a system in the data center for 5 minutes, collected many times for analysis and calculations). This is approximately 2 years of data (in time equivalent). 70% of the data is used for training the system, the remaining 30% is used for cross-checking and testing. The chronological sequence in data collection and analysis was deliberately disrupted to achieve more accurate results.
Data normalization were used in view of the large number of raw parameters of the data center systems. The value of the vector z is determined in the range [-1, 1]:
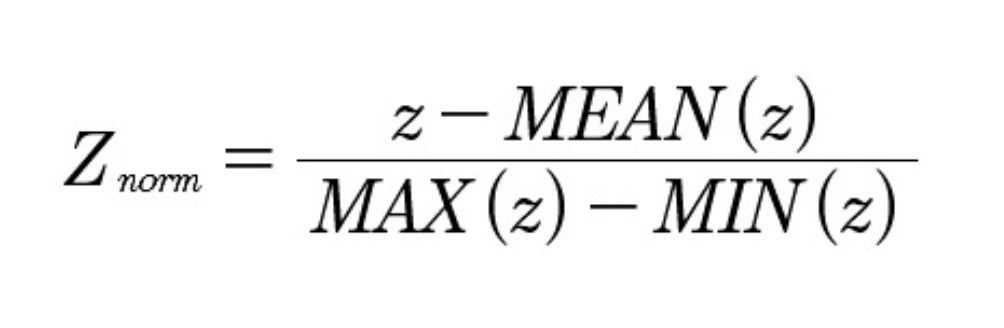
As mentioned earlier, 19 parameters were used for more optimal and accurate calculations performed by the neural circuit. Here is a complete list of them:
Such positive results of a working system capable of fairly accurately analyzing the data, nevertheless, were achieved by Gao without using “deep learning”. The work of AI, in the case of using this system, can significantly improve and expand in its powers. Now Google uses its AI exclusively to improve the performance of certain systems in its data centers. In the future, AIs will also be used for data analysis / processing. Perhaps the AI will control the entire Internet as its own structure, improving it, making it more responsive to users. Artificial intelligence can change the world, it is a fact.
But how much more will we, the people, have to learn, how much to understand and realize, before we give the AI more power than we have ourselves. Maybe we can create a full-fledged artificial intelligence, but just do not want this. For we all know the saying "the disciple has surpassed his teacher." Is it possible that our creation will surpass us. We do not yet know the answers to these questions, but this is only for the time being.
One of the largest, in many understandings, a fan of AI is Google. We all know about the car, which is able to move on a busy road without direct human intervention, about smartphone applications that can recognize speech and communicate with a person, about search services that can instantly recognize digital images. All these fantastic things are developed not only by Google. Many companies, such as Facebook, Microsoft and IBM, also do not graze the back. This is a clear indicator of their extremely high interest in introducing AI into our daily life.
')
Google car
Many revolutionary projects are based on the use of AI in one form or another. Among them, Google Auto, IBM Watson (a supercomputer equipped with an AI question-answer system). These are quite loud and public projects. However, not the only, and not the most important. Most companies devote significantly more time and resources to the development of the so-called artificial intelligence “depth learning” system.
IBM Watson (a supercomputer equipped with an AI question-answer system)It is this system that Google is developing in its data centers. Behind all Google services is a huge amount of data that requires processing and analysis. Accordingly, the company owns its huge data centers, which is not a secret. Currently, corporations have begun to use artificial neural networks in the data center, whose task is to analyze the work of the data center itself. Further, the data obtained are used to improve the operation of the data storage and processing structure. In fact, these neural networks are computer algorithms that can recognize patterns and make a certain decision based on the data obtained. This network can not be compared with human intelligence, but it can perform many tasks much faster and more efficiently. It is for this reason that Google uses these algorithms in the work of its data centers, precisely where speed means a lot.
The creator of AI for the data center Google has become a young engineer Jim Gao (Jim Gao), whom many of the team called the "young genius." At one time, he took an online lecture course at Andrew Ng, a professor at Stanford University. The professor is a leading expert in the field of studying AI.
Prof. Eun
Jim Gao used his “20% of the time” * to study the operation of artificial neural networks and how to use them in the work of the company's data centers.
* “20% of the time” is Google’s innovation to improve the performance of its employees. In fact, this is the official permission from the management to use 20% of the working time for research and development of their own ideas, which may later be useful to the company.
Every few seconds, Google collects a huge amount of all sorts of data: indicators of energy consumed, the amount of water used in the cooling system, the temperature outside the data center, etc. Jim Gao created an AI system that would collect this information, process it and predict the level of performance of the data center. After 12 months, the model has been adjusted, due to even more new data. As a result, the prediction accuracy was 99.6%.
This AI system is a kind of preventive measure during the solution of a problem. At the moment, AI is engaged in the work of the main data center support systems (power supply, cooling, etc.). For example, an AI system can “offer” a replacement for a heat exchanger, which will improve the performance of the cooling system. A couple of months ago, the data center had to shut down a number of servers, which usually affects energy efficiency, but thanks to Jim Gao's AI, which controls the cooling system, technical work went smoothly, and the level of energy efficiency remained high throughout the entire time. AI, according to representatives of Google, may notice those small details that are not visible to a person, which makes it so effective.
This graph shows the ratio of the predictions of the AI system and the actual performance of the PUE (Power usage effectiveness) energy efficiency.
Of course, we can not but rejoice at the success of Google, but it’s still interesting how this system works.
First of all, the task was set to determine precisely those factors that have the greatest impact on the level of energy efficiency (PUE). Jim Gao reduced the list to 19 factors (variables). After the artificial neural network was formed. This system had to analyze (or process, as it is more convenient to whom) a huge amount of data and look for patterns in them.
The difficulty lies in the quantity, as it is not funny, of everything. More precisely, in the number of variables. The amount of equipment, their combinations, compounds, factors of influence, such as weather conditions.
In more detail, this problem and methods of solving it in the context of using AI in the work of the data center Jim Gao describes in his work “machine learning in data center optimization”.
Here is what Jim Gao himself says in the introductory part of his work:
“A modern data center (DC) is a complex set of mechanical, electrical, and control systems. The huge number of possible configurations of operational and non-linear connections complicates the understanding and optimization of energy efficiency. We have developed a structure of neural connections, which, through the analysis of actual operational data, learns to model an action plan and predict the level of energy efficiency of PUE, with an error within 0.004 +/- 0.005, or with an error of 0.4% of PUE 1.1. The model has been seriously tested in Google data centers. The results showed that machine learning is an effective way to use already available sensory data to simulate data center operation and improve energy efficiency. ”
Model implementation
The input variable x - (mxn) is an array of data, where m is the number of training examples, and n is the number of features, which include IT load and weather conditions, the number of running coolers and cooling towers, the number of installed equipment, etc.
Ordinary three-layer neural network
The input matrix x is multiplied by the parameters of the model matrix θ 1 to obtain the hidden state of the matrix. In practice, a acts as an intermediate segment that interacts with the second parameter of the matrix θ 2 to calculate the initial data h θ (x) . The size and number of hidden layers directly depends on the complexity of the simulated system. In this case, h θ (x) is the variability of the output data, presented in the form of a certain range of indicators, which must be optimized. The level of energy efficiency is used in the formation of this system as an indicator of the efficiency of the data center. The range of indicators is a coefficient that does not reflect the total energy consumption of the data center. Other baseline data includes server utilization data to maximize productivity, or equipment failure data to understand how the data center infrastructure affects its reliability. The neural network is looking for a relationship between various data indicators, in order to form a mathematical model that calculates the source data h θ (x) . Understanding the basic mathematical principles of h θ (x) , one can control and optimize them.
Despite the fact that linear independence of indicators is not necessary, its use significantly reduces the training time of the system and reduces the number of retraining processes. In addition, this linear scorecard simplifies the model by limiting the number of input data exclusively to those indicators that are the most fundamental for the work of the data center. For example, the temperature in the openings of the cooling system is not an important indicator for the formation of the level of energy efficiency, as it is a consequence of the work of other systems (operation of cooling towers, temperatures of water condensate and chilled water entry points), the indicators of which are fundamental.
The learning process of the neural network can be divided into four main stages (+ the fifth stage, repeating steps 2-4):
1. Arbitrary initialization of parameters (patterns) of the model;
2. Implementation of the algorithm for further branching;
3. Calculate the cost function J (θ);
4. Implementation of the algorithm of reverse branching;
5. Repetition of points 2, 3 and 4 to achieve maximum convergence, or to achieve the required number of attempts.
1. Arbitrary initialization
Arbitrary initialization is the process of randomly assigning a value of θ between [-1, 1] immediately before the start of training a model. To understand why this is necessary, consider the scenario where all model parameters will be equal to 0. The incoming data in each subsequent layer of the neural network will be the same, since they are multiplied by θ (equal to 0). In addition, this error will spread in the opposite direction, through hidden layers, which will lead to the fact that any changes in the model parameters will also be absolutely identical. It is for this reason that the value of θ arbitrarily varies in the range [-1, 1] in order to avoid the formation of an imbalance.
2. Further branching
Further branching refers to the process of calculating each subsequent layer, since the value of each of them depends on the parameters of the model and on the layers preceding them. The initial data of the model is calculated by a further branching algorithm, where a l j reflects the activation of node l in layer j , and θ l is the data matrix (model parameters) transforming layer l into layer l +1 .
Basic parameters (nodes with a value of 1) are added to each dissimilar layer to represent a digital expression in each layer.
In the above equations, θ 1 10 represents the value between the added base parameter x 1 0 and the element of the hidden layer a 2 1 .
The purpose of the activation function x (z) is to simulate the operation of biological neural networks, by imposing input data on the source within the range (0, 1). It is given by the sigmoid logistic function g (z) = 1 / (1 + e -z )
It should be noted that the above equations can be expressed more compactly in matrix form:
a 2 = g (θ 1 x)
h θ (x) = a 3 = g (θ 2 a 2 )
3. Cost function
This function is a parameter that should decrease with each integration in the system learning process. The formula for this parameter is as follows:
Where:
h θ (x) is the predicted calculated data;
y - the actual data corresponding to the output data;
m is the number of teaching examples per indicator;
L is the number of layers;
n is the number of nodes;
λ is the regulating parameter responsible for balancing between the accuracy of the system and the number of its retraining processes.
In this case, h θ (x) is the calculated level of energy efficiency, and y is the actual level of energy efficiency.
4. Reverse branching
After calculating the cost function, the error indicator δ is distributed to all layers in the reverse order to eliminate the value 0. The error in the output layer is defined as the difference between the calculated output data h θ (x) and the actual y .
For a three-layer neural circuit, the error associated with the output and hidden layers is expressed as:
δ 3 = a 3 - y
δ 2 = (θ 2 ) T. * g '(z 2 ) = (θ 2 ) T δ 3. * [a 2. * (1-a 2 )]
Where:
g '(z) is a derivative of the activation function. This expression can be simplified to the following form: a. * (1-a) .
There is no error exclusively in the first layer, since it is a combination of input data. For each layer, the error is calculated using the formulas below:
Where: Δ l is initialized as a vector of zeros. Dl is added to update the model of each layer before repeating items 2-4. By combining all the learning algorithms, this process can produce many (or, more precisely, hundreds of thousands) iterations before convergence is achieved, the process of achieving which is accelerated by the cost formula.
Implementation
This artificial neural network uses 5 hidden layers, 50 nodes in each layer, and the regularization parameter = 0.001. For calculations, 19 parameters are used. As a result, we get one parameter - the level of energy efficiency of the data center. Each of these parameters includes 184,435 examples of 5 minutes each (data on the operation of a system in the data center for 5 minutes, collected many times for analysis and calculations). This is approximately 2 years of data (in time equivalent). 70% of the data is used for training the system, the remaining 30% is used for cross-checking and testing. The chronological sequence in data collection and analysis was deliberately disrupted to achieve more accurate results.
Data normalization were used in view of the large number of raw parameters of the data center systems. The value of the vector z is determined in the range [-1, 1]:
As mentioned earlier, 19 parameters were used for more optimal and accurate calculations performed by the neural circuit. Here is a complete list of them:
- IT load
- The load on the core network of the entire premises
- Total number of running water pumps
- Average speed of variable frequency drive of water pumps
- Total number of running condensate pumps
- Average speed of variable frequency drive of condensate pumps
- Total number of operating cooling towers
- Average cooling water temperature
- Total number of operating chillers
- Total number of working dry coolers
- Total number of cooling water inlet pumps
- Average water temperature in inlet pumps
- Average heat exchanger temperature
- Outside temperature of the wet thermometer
- Outside temperature dry thermometer
- Outside air heat content
- Relative humidity of outdoor air
- Wind speed
- Direction of the wind
Such positive results of a working system capable of fairly accurately analyzing the data, nevertheless, were achieved by Gao without using “deep learning”. The work of AI, in the case of using this system, can significantly improve and expand in its powers. Now Google uses its AI exclusively to improve the performance of certain systems in its data centers. In the future, AIs will also be used for data analysis / processing. Perhaps the AI will control the entire Internet as its own structure, improving it, making it more responsive to users. Artificial intelligence can change the world, it is a fact.
But how much more will we, the people, have to learn, how much to understand and realize, before we give the AI more power than we have ourselves. Maybe we can create a full-fledged artificial intelligence, but just do not want this. For we all know the saying "the disciple has surpassed his teacher." Is it possible that our creation will surpass us. We do not yet know the answers to these questions, but this is only for the time being.
Source: https://habr.com/ru/post/261069/
All Articles