ELK + R as log repository
In the company of the customer there is a need for a certain log repository with the possibility of horizontal scaling. Starting from the beginning of the task, the first thought is Splunk. Unfortunately, the cost of this decision went far beyond the budget of the customer.
As a result, the choice fell on a bunch of Logstash + Elasticsearch + Kibana.
Inspired by the article on Habré “Collect and analyze logs using Lumberjack + Logstash + Elasticsearch + RabbitMQ” and having armed with a small “cloud” on DevStack, the experiments began.
The first thing you liked was RabbitMQ as an intermediate link, so as not to lose the logs. But, unfortunately, logstash-forwarder was not very convenient in collecting logs from Windows, and since most of the clients will be on WinServer, this turned out to be critical. Searches led to the nxlog community edition. It was not difficult to find a bundle with logstash (tcp + json was used tritely).
')
And the tests began. All experiments were conducted on the configuration:
Name / Cores / RAM / HDD
HAProxy: 1Core / 512MB / 4Gb
LIstener: 2Core / 512MB / 4G
RABBIT: 2Core / 2Gb / 10G
Filter: 2Core / 2G / 4G
ES_MASTER: 2Core / 2G / 4G
ES_DATA: 2Core / 2G / 40G
ES_BALANSER: 2Core / 2G / 4G
KIBANA: 2Core / 2G / 4G
System: Ubuntu Server 14.04 LTS (image here ).
Bunch : nxlog => haproxy => logstash (listener) => rabbimq => logstash (filter) => elasticsearch
listeners and filters on 2 instances
elasticsearch - a cluster of 2 "equal" instances
Benefits:
Disadvantages:
Errors were taken into account + there was a new requirement: the system should be on CentOS.
Bundle: nxlog => haproxy => logstash (listener) => haproxy (2) => rabbimq => haproxy (3) => logstash (filter) => elasticsearch-http => elasticsearch-data + master
haproxy (2) and haproxy (3) are the same machine.
Under ES 5 machines - ES-http, 2xES-data and 2xES-master.
Benefits:
Disadvantages:
As a result, we got something like this:
The system quietly "digests" 17,488,154 log messages per day. Message size - up to 2kb.
One of the advantages of ES is the fact that the size of the message base is greatly reduced when the fields are of the same type: with a stream of 17 million messages and an average message size of 1kb, the size of the database was slightly more than 2GB. Almost 10 times less than it should be.
With this configuration of the equipment, up to 800 messages / sec without delays are free. With more messages, the queue grows, but for peak loads it is not so critical.
TODO:
The problem with the installation is solved by means of Chef-server.
Everything fit (and there is still room) on the i5-4570 4x3.2GHz + 24Gb RAM + 2x500Gb HDD test bench.
If it is interesting and relevant, I can write a detailed manual, what and how to install.
As a result, the choice fell on a bunch of Logstash + Elasticsearch + Kibana.
Inspired by the article on Habré “Collect and analyze logs using Lumberjack + Logstash + Elasticsearch + RabbitMQ” and having armed with a small “cloud” on DevStack, the experiments began.
The first thing you liked was RabbitMQ as an intermediate link, so as not to lose the logs. But, unfortunately, logstash-forwarder was not very convenient in collecting logs from Windows, and since most of the clients will be on WinServer, this turned out to be critical. Searches led to the nxlog community edition. It was not difficult to find a bundle with logstash (tcp + json was used tritely).
')
And the tests began. All experiments were conducted on the configuration:
Name / Cores / RAM / HDD
HAProxy: 1Core / 512MB / 4Gb
LIstener: 2Core / 512MB / 4G
RABBIT: 2Core / 2Gb / 10G
Filter: 2Core / 2G / 4G
ES_MASTER: 2Core / 2G / 4G
ES_DATA: 2Core / 2G / 40G
ES_BALANSER: 2Core / 2G / 4G
KIBANA: 2Core / 2G / 4G
System: Ubuntu Server 14.04 LTS (image here ).
First approach
Bunch : nxlog => haproxy => logstash (listener) => rabbimq => logstash (filter) => elasticsearch
listeners and filters on 2 instances
elasticsearch - a cluster of 2 "equal" instances
Benefits:
- Easy to install on the customer side.
Disadvantages:
- The bottleneck is rabbitmq. After the rabbitmq restart, I had to restart the listeners, because, for some unknown reason, they did not want to reconnect on their own. And the fall of the "rabbit" has not been canceled;
- Elasticsearch with a very large attempt to digest queries, after filling the index> 100mb;
- It is inconvenient to add new instances to the ES cluster: we had to manually add to the filter a list of available servers.
Errors were taken into account + there was a new requirement: the system should be on CentOS.
Second approach
Bundle: nxlog => haproxy => logstash (listener) => haproxy (2) => rabbimq => haproxy (3) => logstash (filter) => elasticsearch-http => elasticsearch-data + master
haproxy (2) and haproxy (3) are the same machine.
Under ES 5 machines - ES-http, 2xES-data and 2xES-master.
Benefits:
- Horizontal growth to infinity;
- Fault tolerance;
- You can implement the exchange between the listener and filter on rabbitmq ram nodes (+10 performance).
Disadvantages:
- Massive decision;
- Difficulties in installation at the client;
As a result, we got something like this:
Scheme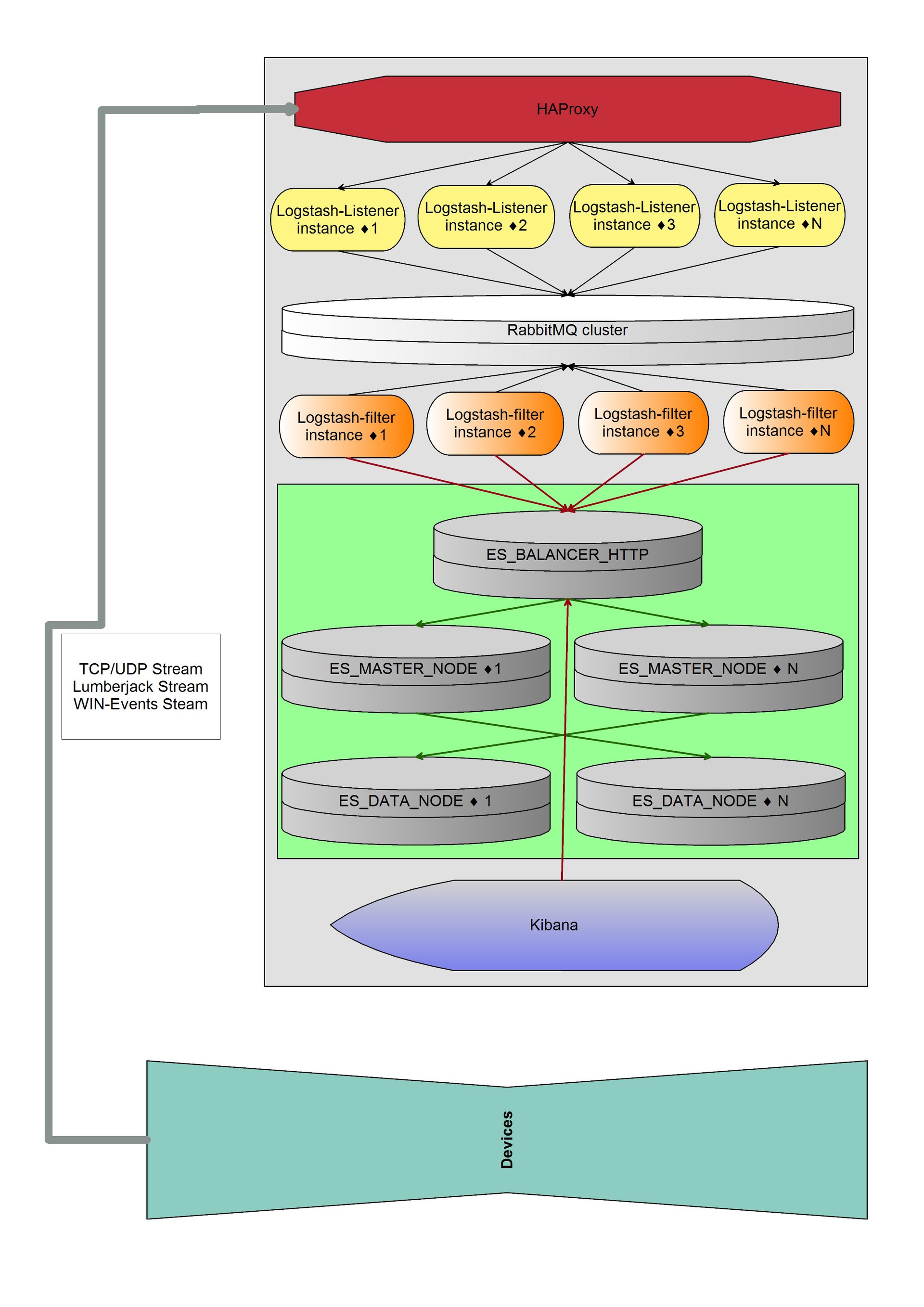
The system quietly "digests" 17,488,154 log messages per day. Message size - up to 2kb.
One of the advantages of ES is the fact that the size of the message base is greatly reduced when the fields are of the same type: with a stream of 17 million messages and an average message size of 1kb, the size of the database was slightly more than 2GB. Almost 10 times less than it should be.
With this configuration of the equipment, up to 800 messages / sec without delays are free. With more messages, the queue grows, but for peak loads it is not so critical.
TODO:
- After restarting all RabbitMQ instances one by one, the logstash listener started hysterically and unsuccessfully trying to reconnect to the Rabbit. Restarting listeners is required. The search for causes continues;
- Squeeze Elasticsearch for more performance.
The problem with the installation is solved by means of Chef-server.
Everything fit (and there is still room) on the i5-4570 4x3.2GHz + 24Gb RAM + 2x500Gb HDD test bench.
If it is interesting and relevant, I can write a detailed manual, what and how to install.
Source: https://habr.com/ru/post/260869/
All Articles