Stream data processing with Akka
Hi, Habr! Everyone is used to associating big data processing with Hadoop (or Spark ), which implement the MapReduce paradigm (or its extensions). In this article, I will discuss the shortcomings of MapReduce, why we decided to abandon MapReduce, and how we adapted Akka + Akka Cluster to replace MapReduce.

The task for which we needed the tools to work with big data is user segmentation. The class of systems that solve the problem of user segmentation throughout the world is called the Data Management Platform or DMP for short. At the entrance of the DMP, data about user actions is received (first of all, these are facts of visits to various Internet pages), the output of the DMP is a “user profile” - its gender, age, interests, intentions, and so on. This profile is further used for advertising targeting, personal recommendations and for personalizing content in general. Read more about DMP here: http://digitalmarketing-glossary.com/What-is-DMP-definition .
Since DMP works with data from a large number of users, the amount of data that needs to be processed can be very impressive. For example, our DMP Facetz.DCA processes data from 600 million browsers, processing almost half a petebyte of data daily.
')
In order to process such data volumes, a good scalable architecture is required. Initially, we built a system based on the hadoop stack. A detailed description of the architecture deserves a separate article, in the same material I will limit myself to a brief description:
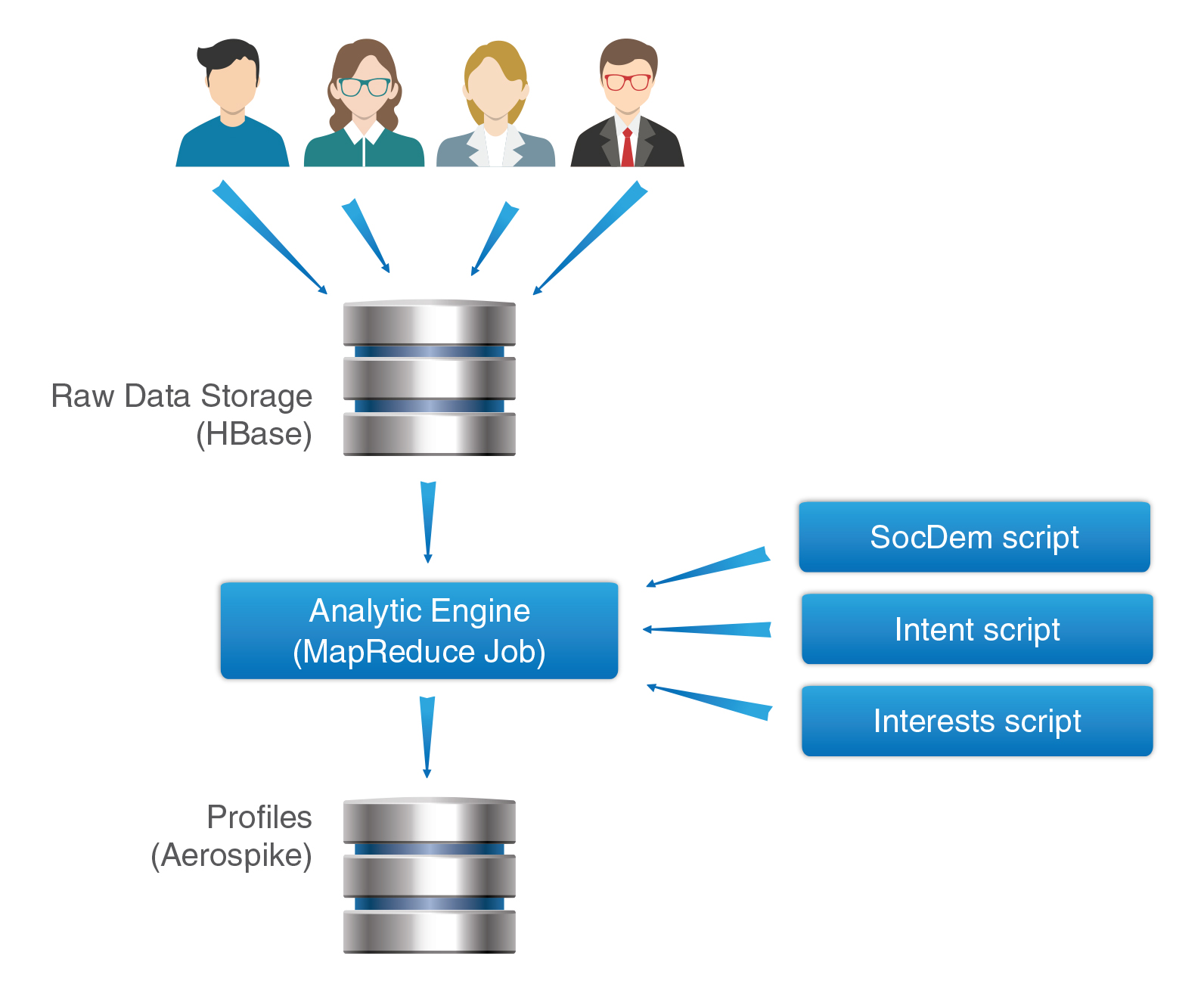
Facetz.DCA Architecture
The developed architecture proved to be good - it allowed to scale quickly up to the processing of user profiles of the entire Runet and mark them up with the help of hundreds of scripts (everyone can mark a user in several segments). However, it was not without flaws. The main problem is the lack of interactivity during processing. MapReduce, by its nature, is a paradigm of offline – data processing. So, for example, if a user watched football tickets today, he can get into the “Football Interests” segment only tomorrow. In some cases, this delay is critical. A typical example is retargeting - advertising a user of products that he has already looked at. The graph shows the probability of making a purchase by the user after viewing the product over time:

Graph of the probability of conversion after viewing the product. When there is no real-time engine, only the green part is available to us, while the maximum probability falls on the first hours.
It can be seen that the highest probability of purchase is within the first few hours. With this approach, the system would know that the user wants to buy goods only after a day — when the probability of a purchase has practically reached the plateau.
Obviously, a streaming real-time data processing mechanism is needed that minimizes latency. At the same time, I want to preserve the versatility of processing - the ability to build arbitrarily complex segmentation rules for users.
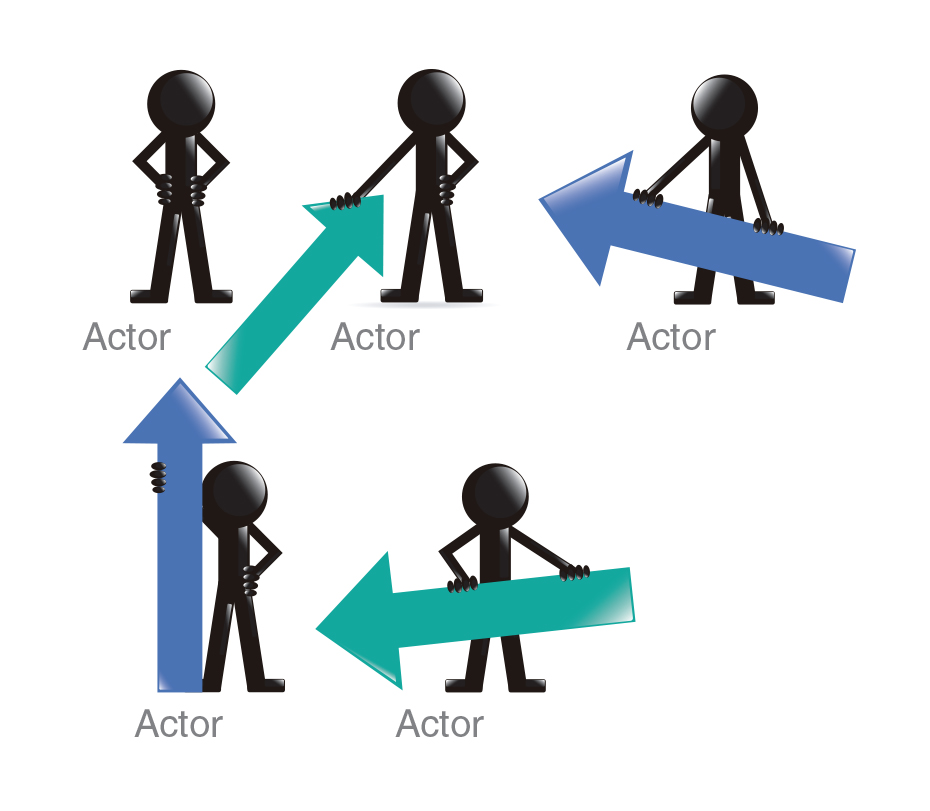
After some thought, we came to the conclusion that the reactive programming paradigm and the model of actors are best suited for solving the problem. Actor is a parallel programming primitive that can:
The model of actors originated in the erlang community, now implementations of this model exist for many programming languages.
For scala, which our DMP is written in, akka is a very good toolkit . It is the basis of several popular frameworks, well documented. In addition, on the Coursera there is an excellent course on the principles of reactive programming , in which these very principles are explained just by the example of akka. Separately, it is worth mentioning the akka cluster module, which allows you to scale solutions (based on actors) into several servers.
The final architecture is as follows:

The data provider adds information about user actions in RabbitMQ.
Sharding of actors across the cluster, their life and destruction is controlled by akka, which significantly simplifies development.

Our Real-Time Engine has shown itself well and we plan to develop it further. List of steps that we plan to take:
In the end, I would like to give a few links to some frameworks, on the basis of which you can also build stream processing of data:
- Apache Storm
- Spark Streaming
- Apache Samza
Thank you for your attention, we are ready to answer your questions.
Youtube Channel about data analysis
Data Management Platform
The task for which we needed the tools to work with big data is user segmentation. The class of systems that solve the problem of user segmentation throughout the world is called the Data Management Platform or DMP for short. At the entrance of the DMP, data about user actions is received (first of all, these are facts of visits to various Internet pages), the output of the DMP is a “user profile” - its gender, age, interests, intentions, and so on. This profile is further used for advertising targeting, personal recommendations and for personalizing content in general. Read more about DMP here: http://digitalmarketing-glossary.com/What-is-DMP-definition .
Since DMP works with data from a large number of users, the amount of data that needs to be processed can be very impressive. For example, our DMP Facetz.DCA processes data from 600 million browsers, processing almost half a petebyte of data daily.
')
DMP Facetz.DCA Architecture
In order to process such data volumes, a good scalable architecture is required. Initially, we built a system based on the hadoop stack. A detailed description of the architecture deserves a separate article, in the same material I will limit myself to a brief description:
- Logs of user actions are added to HDFS - a distributed file system, which is one of the basic components of the ecosystem hadoop
- From HDFS, data is added to the raw data storage, implemented on the basis of Apache HBase — a distributed, scalable database built on the basis of Big Table ideas. In fact, HBase is a very convenient database for key-value mass processing. All user data is stored in one large facts table. The data of one user corresponds to one line of HBase, which makes it very fast and convenient to get all the necessary information about it.
- Analytic Engine is launched once a day - a large MapReduce job, which, in fact, performs segmentation of users. In essence, the Analytic Engine is a container for segmentation rules, which are separately prepared by analysts. For example, one script may mark the gender of the user, another - his interests, and so on.
- Ready-made user segments are added to Aerospike — a key-value database that is very well tuned for quick returns — 99% of read requests work out in less than 1 ms, even with heavy loads of tens of thousands of requests per second.
Facetz.DCA Architecture
MapReduce problems
The developed architecture proved to be good - it allowed to scale quickly up to the processing of user profiles of the entire Runet and mark them up with the help of hundreds of scripts (everyone can mark a user in several segments). However, it was not without flaws. The main problem is the lack of interactivity during processing. MapReduce, by its nature, is a paradigm of offline – data processing. So, for example, if a user watched football tickets today, he can get into the “Football Interests” segment only tomorrow. In some cases, this delay is critical. A typical example is retargeting - advertising a user of products that he has already looked at. The graph shows the probability of making a purchase by the user after viewing the product over time:
Graph of the probability of conversion after viewing the product. When there is no real-time engine, only the green part is available to us, while the maximum probability falls on the first hours.
It can be seen that the highest probability of purchase is within the first few hours. With this approach, the system would know that the user wants to buy goods only after a day — when the probability of a purchase has practically reached the plateau.
Obviously, a streaming real-time data processing mechanism is needed that minimizes latency. At the same time, I want to preserve the versatility of processing - the ability to build arbitrarily complex segmentation rules for users.
Actor Model
After some thought, we came to the conclusion that the reactive programming paradigm and the model of actors are best suited for solving the problem. Actor is a parallel programming primitive that can:
- Accept messages
- Send messages
- Create new actors
- Set reaction to messages
The model of actors originated in the erlang community, now implementations of this model exist for many programming languages.
For scala, which our DMP is written in, akka is a very good toolkit . It is the basis of several popular frameworks, well documented. In addition, on the Coursera there is an excellent course on the principles of reactive programming , in which these very principles are explained just by the example of akka. Separately, it is worth mentioning the akka cluster module, which allows you to scale solutions (based on actors) into several servers.
Real-Time DMP Architecture
The final architecture is as follows:
The data provider adds information about user actions in RabbitMQ.
- Dispatcher reads user action messages from RabbitMQ. Dispatcher may be several, they work independently.
- For every online user, an actor is started in the system. Dispatcher sends a message about a new event (read from RabbitMQ) to the corresponding actor (or gets a new actor if this is the first user action and there is no actor for it yet).
- The actor corresponding to the user adds information about the action to the list of user actions and runs segmentation scripts (the same ones that run the Analytic Engine during MapReduce processing).
- The data on the marked segments are added to Aerospike. Also, data on segments and user actions are available via an API connected directly to the actors.
- If there is no data about the user within an hour, the session is considered complete and the actor is destroyed.
Sharding of actors across the cluster, their life and destruction is controlled by akka, which significantly simplifies development.
Current results:
- Akka-cluster of 6 nodes;
- Data flow 3000 events per second;
- 4-6 million users online (depending on the day of the week);
- The average time to execute one user segmentation script is less than five milliseconds;
- The average time between an event and a segmentation based on this event is one second.
Further development
Our Real-Time Engine has shown itself well and we plan to develop it further. List of steps that we plan to take:
- Persistence - now Real-Time Engine segments users only on the basis of the last session. We plan to add pull-ups of older information from HBase when a new user appears.
- Currently, only a part of our data is transferred to realtime processing. We plan to gradually transfer all our data sources to stream processing, after which the stream of processed data will increase to 30,000 events per second.
- After completing the transfer to Realtime, we will be able to abandon the daily calculation of MapReduce, which will save on servers due to the fact that only those users who are really active on the Internet today will be processed.
Links to similar solutions
In the end, I would like to give a few links to some frameworks, on the basis of which you can also build stream processing of data:
- Apache Storm
- Spark Streaming
- Apache Samza
Thank you for your attention, we are ready to answer your questions.
Youtube Channel about data analysis
Source: https://habr.com/ru/post/260845/
All Articles