Writing a wrapper for FUSE in Java Native Runtime
In this article I will tell you how to implement a file system in a user space in Java, without a line of kernel code. I will also show you how to link Java and native code without writing C code, while maintaining maximum performance.

Interesting? Welcome under the cut!
Before starting to implement the wrapper, you need to understand what FUSE is.
FUSE (Filesystem in Userspace) is a file system in user space that allows users to create their own file systems without privileges and without having to rewrite kernel code. This is achieved by running the file system code in user space, while the FUSE module only provides a bridge for the actual kernel interfaces. FUSE was officially included in the main Linux code tree in version 2.6.14.
')
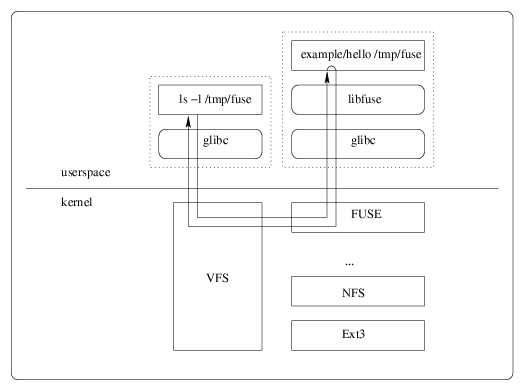
Those. You can easily create your own file system with the implementation of several methods ( an example of the simplest file system). Applications to this million, you can, for example, quickly write a file system, the backend for which is Dropbox or GitHub.
Or, consider such a case, you have a business application where all user files are stored in the database, but the client suddenly needed direct access to the directory on the server where all the files are located. Of course, duplicating files in the database and file system is not the best solution, and then the virtual file system comes to the rescue. You simply write your FUSE wrapper, which, when accessing files, follows them to the database.
Great, but the FUSE implementation starts with “include the header <fuse.h>”, and your business application is written in Java. Obviously, you need to interact in some way with the native code.
The standard tool is JNI, but it introduces a lot of complexity into the project, especially considering that to implement FUSE we will have to make callbacks from native code into Java classes. Yes, and “write once” actually suffers, although in the case of FUSE this is less important to us.
Actually, if you try to find projects that implement the wrapper for FUSE on JNI, you can find several projects that, however, have not been supported for a long time and provide an API curve.
Another option is the JNA library . JNA (Java Native Access) makes it quite easy to access native code without using JNI, limiting yourself to writing java-code. Everything is quite simple, we declare an interface that corresponds to the native code, we get its implementation through “Native.loadLibrary” and we use everything. Separate plus JNA is the most detailed documentation. The project is alive and actively developing.
Moreover, there is already a great project for FUSE that implements a wrapper on JNA.
However, JNA has certain performance issues. JNA is based on reflection, and the transition from native code with the conversion of all structures into java objects is very expensive. This is not very noticeable if native calls are rare, but this is not the case with the file system. The only way to speed up fuse-jna is to try to read files in large chunks, but this does not always work. For example, when there is no access to client code, or all files are small, a large number of text files.
Obviously, there should have been a library that would combine JNI performance and JNA convenience.
This is where the JNR (Java Native Runtime) comes. JNR, like JNA, is based on libffi, but instead of reflection, bytecode generation is used, thereby achieving a huge performance advantage.
Any information about JNR is quite small, the most detailed is the performance of Charles Nutter at JVMLS 2013 ( presentation ). However, JNR is already a fairly large ecosystem, which is actively used by JRuby. Many of its parts, for example, unix-sockets, posix-api are also actively used by third-party projects.
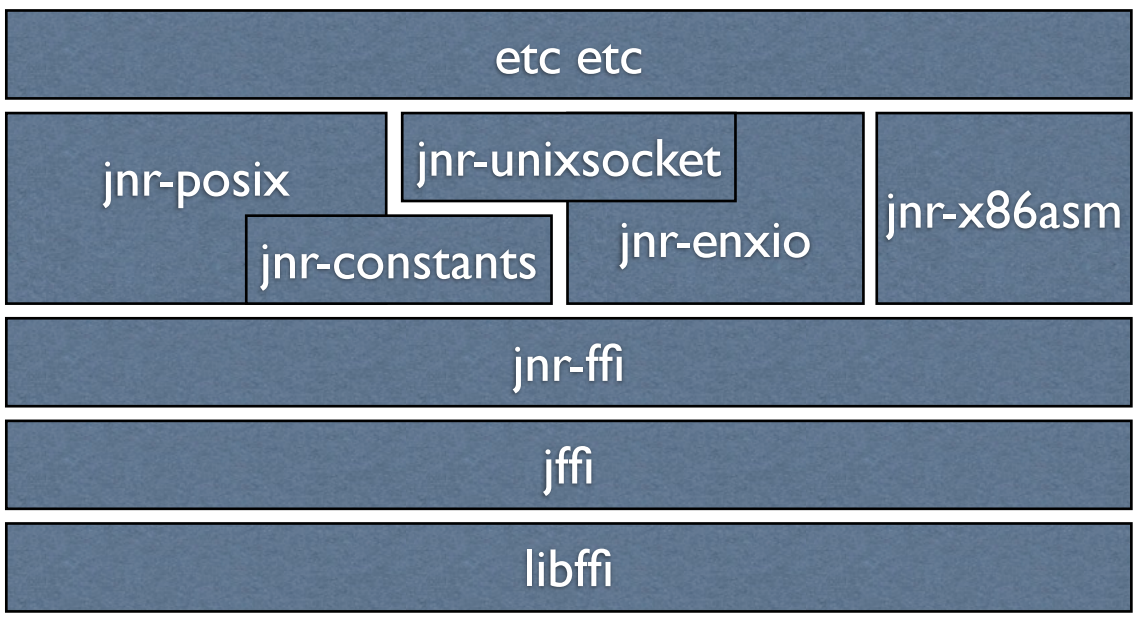
It is JNR that is the basis for developing the JEP 191 - Foreign Function Interface, which targets java 10.
Unlike JNA, JNR does not have any documentation, all the answers to the questions have to be found in the source code, this was the main reason for writing a small guide.
The easiest binding to libc looks like this:
Via LibraryLoader, we load by name the library that corresponds to the passed interface.
In the case of FUSE, you need an interface with the fuse_main_real method, to which the FuseOperations structure is passed, which contains all callbacks.
It is often necessary to work with structures located at a specific address, for example, the fuse_bufvec structure:
To implement it in JNR, you must inherit from jnr.ffi.Struct.
Inside each structure is stored a pointer, according to which it is placed in memory. Most of the API for working with structures can be seen by looking at the static methods of Struct.
size_t is an inner Struct class and when it is created, for each field, the offset with which this field is located in memory is remembered, due to which each field knows by which offset it lies in memory. There are already many such inner classes (for example, Signed64, Unsigned32, time_t, etc.), you can always implement your own.
There is an annotation for working with callbacks in JNR.
After that, you can set the required callback implementation in the getattr field, for example.
Of some non-obvious things, it is also worth noting a wrapper over enum, for this you need to inherit your enum from jnr.ffi.util.EnumMapper.IntegerEnum and implement the intValue method
This knowledge is enough to easily implement a simple cross-platform wrapper over some native library.
What I actually did with FUSE in my jnr-fuse project. Initially, the fuse-jna library was used, but it was she who was the bottleneck in the implementation of the file system. When developing the API, I tried to keep compatibility with fuse-jna as well as with the native implementation (<fuse.h>) as much as possible.
To implement your file system in user space, it is necessary to follow from ru.serce.jnrfuse.FuseStubFS and implement the necessary methods. Fuse_operations contains a lot of methods , however, in order to get a working file system, you only need to implement a few basic ones.
It's pretty simple, here are some examples of working FS .
Linux is currently supported (x86 and x64).
The library is in jcenter, in the near future I will add a mirror in the maven central.
In my case, FS was read-only and I was interested in specifically throughput. The performance will depend heavily on the implementation of your file system, so if all of a sudden you are already using fuse-jna, you can easily connect jnr-fuse, write a test based on your load profile and see the difference. (This test will come in handy anyway, we all love to chase performance, right?)
To show the difference order, I transferred the MemoryFS implementation from fuse-jna to fuse-jnr with minimal changes and started the fio reading test. For the test, I used the fio framework, about which not so long ago there was a good article on Habré .
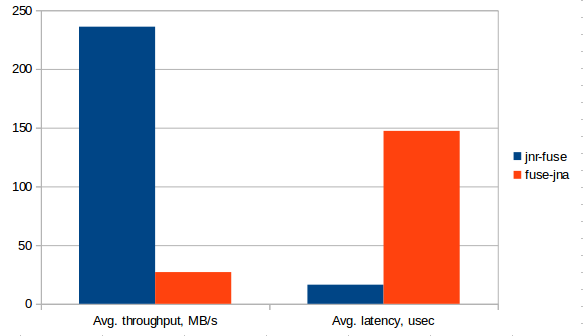
The test only demonstrates the difference in the speed of reading the file in fuse-jna and fuse-jnr, however, based on it, you can get an idea of the difference in the speed of JNA and JNR. Those who wish can always write more detailed tests for native calls with the help of JMH , taking into account all the features, I myself would be interested to look at these tests.
The difference in throughput and latency in JNR and JNA is expected, as in the presentation from Charles Nutter, is ~ 10 times.
The jnr-fuse project is hosted on github . I will once be asterisks, pull requests, suggestions for improving the project.
And also I will be happy to answer all your questions about JNR and jnr-fuse.
Interesting? Welcome under the cut!
Before starting to implement the wrapper, you need to understand what FUSE is.
FUSE (Filesystem in Userspace) is a file system in user space that allows users to create their own file systems without privileges and without having to rewrite kernel code. This is achieved by running the file system code in user space, while the FUSE module only provides a bridge for the actual kernel interfaces. FUSE was officially included in the main Linux code tree in version 2.6.14.
')
Those. You can easily create your own file system with the implementation of several methods ( an example of the simplest file system). Applications to this million, you can, for example, quickly write a file system, the backend for which is Dropbox or GitHub.
Or, consider such a case, you have a business application where all user files are stored in the database, but the client suddenly needed direct access to the directory on the server where all the files are located. Of course, duplicating files in the database and file system is not the best solution, and then the virtual file system comes to the rescue. You simply write your FUSE wrapper, which, when accessing files, follows them to the database.
Java and native code
Great, but the FUSE implementation starts with “include the header <fuse.h>”, and your business application is written in Java. Obviously, you need to interact in some way with the native code.
Jni
The standard tool is JNI, but it introduces a lot of complexity into the project, especially considering that to implement FUSE we will have to make callbacks from native code into Java classes. Yes, and “write once” actually suffers, although in the case of FUSE this is less important to us.
Actually, if you try to find projects that implement the wrapper for FUSE on JNI, you can find several projects that, however, have not been supported for a long time and provide an API curve.
Jna
Another option is the JNA library . JNA (Java Native Access) makes it quite easy to access native code without using JNI, limiting yourself to writing java-code. Everything is quite simple, we declare an interface that corresponds to the native code, we get its implementation through “Native.loadLibrary” and we use everything. Separate plus JNA is the most detailed documentation. The project is alive and actively developing.
Moreover, there is already a great project for FUSE that implements a wrapper on JNA.
However, JNA has certain performance issues. JNA is based on reflection, and the transition from native code with the conversion of all structures into java objects is very expensive. This is not very noticeable if native calls are rare, but this is not the case with the file system. The only way to speed up fuse-jna is to try to read files in large chunks, but this does not always work. For example, when there is no access to client code, or all files are small, a large number of text files.
Obviously, there should have been a library that would combine JNI performance and JNA convenience.
Jnr
This is where the JNR (Java Native Runtime) comes. JNR, like JNA, is based on libffi, but instead of reflection, bytecode generation is used, thereby achieving a huge performance advantage.
Any information about JNR is quite small, the most detailed is the performance of Charles Nutter at JVMLS 2013 ( presentation ). However, JNR is already a fairly large ecosystem, which is actively used by JRuby. Many of its parts, for example, unix-sockets, posix-api are also actively used by third-party projects.
It is JNR that is the basis for developing the JEP 191 - Foreign Function Interface, which targets java 10.
Unlike JNA, JNR does not have any documentation, all the answers to the questions have to be found in the source code, this was the main reason for writing a small guide.
Feature writing code for Java Native Runtime
Binding functions
The easiest binding to libc looks like this:
import jnr.ffi.*; import jnr.ffi.types.pid_t; /** * Gets the process ID of the current process, and that of its parent. */ public class Getpid { public interface LibC { public @pid_t long getpid(); public @pid_t long getppid(); } public static void main(String[] args) { LibC libc = LibraryLoader.create(LibC.class).load("c"); System.out.println("pid=" + libc.getpid() + " parent pid=" + libc.getppid()); } } Via LibraryLoader, we load by name the library that corresponds to the passed interface.
In the case of FUSE, you need an interface with the fuse_main_real method, to which the FuseOperations structure is passed, which contains all callbacks.
public interface LibFuse { int fuse_main_real(int argc, String argv[], FuseOperations op, int op_size, Pointer user_data); } Struct implementation
It is often necessary to work with structures located at a specific address, for example, the fuse_bufvec structure:
struct fuse_bufvec { size_t count; size_t idx; size_t off; struct fuse_buf buf[1]; }; To implement it in JNR, you must inherit from jnr.ffi.Struct.
import jnr.ffi.*; public class FuseBufvec extends Struct { public FuseBufvec(jnr.ffi.Runtime runtime) { super(runtime); } public final size_t count = new size_t(); public final size_t idx = new size_t(); public final size_t off = new size_t(); public final FuseBuf buf = inner(new FuseBuf(getRuntime())); } Inside each structure is stored a pointer, according to which it is placed in memory. Most of the API for working with structures can be seen by looking at the static methods of Struct.
size_t is an inner Struct class and when it is created, for each field, the offset with which this field is located in memory is remembered, due to which each field knows by which offset it lies in memory. There are already many such inner classes (for example, Signed64, Unsigned32, time_t, etc.), you can always implement your own.
Kolbeki
struct fuse_operations { int (*getattr) (const char *, struct stat *); } There is an annotation for working with callbacks in JNR.
@Delegate
public interface GetAttrCallback { @Delegate int getattr(String path, Pointer stbuf); } public class FuseOperations extends Struct { public FuseOperations(Runtime runtime) { super(runtime); } public final Func<GetAttrCallback> getattr = func(GetAttrCallback.class); } After that, you can set the required callback implementation in the getattr field, for example.
fuseOperations.getattr.set((path, stbuf) -> 0); Enum
Of some non-obvious things, it is also worth noting a wrapper over enum, for this you need to inherit your enum from jnr.ffi.util.EnumMapper.IntegerEnum and implement the intValue method
enum fuse_buf_flags { FUSE_BUF_IS_FD = (1 << 1), FUSE_BUF_FD_SEEK = (1 << 2), FUSE_BUF_FD_RETRY = (1 << 3), }; public enum FuseBufFlags implements EnumMapper.IntegerEnum { FUSE_BUF_IS_FD(1 << 1), FUSE_BUF_FD_SEEK(1 << 2), FUSE_BUF_FD_RETRY(1 << 3); private final int value; FuseBufFlags(int value) { this.value = value; } @Override public int intValue() { return value; } } Work with memory
- For direct work with memory, there is a wrapper over the raw pointer jnr.ffi.Pointer
- Memory can be allocated using jnr.ffi.Memory
- The starting point of the JNR API can be considered jnr.ffi.Runtime
This knowledge is enough to easily implement a simple cross-platform wrapper over some native library.
jnr-fuse
What I actually did with FUSE in my jnr-fuse project. Initially, the fuse-jna library was used, but it was she who was the bottleneck in the implementation of the file system. When developing the API, I tried to keep compatibility with fuse-jna as well as with the native implementation (<fuse.h>) as much as possible.
To implement your file system in user space, it is necessary to follow from ru.serce.jnrfuse.FuseStubFS and implement the necessary methods. Fuse_operations contains a lot of methods , however, in order to get a working file system, you only need to implement a few basic ones.
It's pretty simple, here are some examples of working FS .
Linux is currently supported (x86 and x64).
The library is in jcenter, in the near future I will add a mirror in the maven central.
Gradle
repositories { jcenter() } dependencies { compile 'com.github.serceman:jnr-fuse:0.1' } Maven
<repositories> <repository> <id>central</id> <name>bintray</name> <url>http://jcenter.bintray.com</url> </repository> </repositories> <dependencies> <dependency> <groupId>com.github.serceman</groupId> <artifactId>jnr-fuse</artifactId> <version>0.1</version> </dependency> </dependencies> Compare the performance of fuse-jna and jnr-fuse
In my case, FS was read-only and I was interested in specifically throughput. The performance will depend heavily on the implementation of your file system, so if all of a sudden you are already using fuse-jna, you can easily connect jnr-fuse, write a test based on your load profile and see the difference. (This test will come in handy anyway, we all love to chase performance, right?)
To show the difference order, I transferred the MemoryFS implementation from fuse-jna to fuse-jnr with minimal changes and started the fio reading test. For the test, I used the fio framework, about which not so long ago there was a good article on Habré .
Test configuration
[readtest]
blocksize = 4k
directory = / tmp / mnt /
rw = randread
direct = 1
buffered = 0
ioengine = libaio
time_based = 60
size = 16M
runtime = 60
blocksize = 4k
directory = / tmp / mnt /
rw = randread
direct = 1
buffered = 0
ioengine = libaio
time_based = 60
size = 16M
runtime = 60
Fuse-jna result
serce @ SerCe-FastLinux: ~ / git / jnr-fuse / bench $ fio read.ini
readtest: (g = 0): rw = randread, bs = 4K-4K / 4K-4K / 4K-4K, ioengine = libaio, iodepth = 1
fio-2.1.3
Starting 1 process
readtest: Laying out IO file (s) (1 file (s) / 16MB)
Jobs: 1 (f = 1): [r] [100.0% done] [24492KB / 0KB / 0KB / s] [6123/0/0 iops] [eta 00m: 00s]
readtest: (groupid = 0, jobs = 1): err = 0: pid = 10442: Sun Jun 21 14:49:13 2015
read: io = 1580.2MB, bw = 26967KB / s, iops = 6741, runt = 60000msec
slat (usec): min = 46, max = 29997, avg = 146.55, stdev = 327.68
clat (usec): min = 0, max = 69, avg = 0.47, stdev = 0.66
lat (usec): min = 47, max = 30002, avg = 147.26, stdev = 327.88
clat percentiles (usec):
| 1.00th = [0], 5.00th = [0], 10.00th = [0], 20.00th = [0],
| 30.00th = [0], 40.00th = [0], 50.00th = [0], 60.00th = [1],
| 70.00th = [1], 80.00th = [1], 90.00th = [1], 95.00th = [1],
| 99.00th = [2], 99.50th = [2], 99.90th = [3], 99.95th = [12],
| 99.99th = [14]
bw (KB / s): min = 17680, max = 32606, per = 96.09%, avg = 25913.26, stdev = 3156.20
lat (usec): 2 = 97.95%, 4 = 1.96%, 10 = 0.02%, 20 = 0.06%, 50 = 0.01%
lat (usec): 100 = 0.01%
cpu: usr = 1.98%, sys = 5.94%, ctx = 405302, majf = 0, minf = 28
IO depths: 1 = 100.0%, 2 = 0.0%, 4 = 0.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%,> = 64 = 0.0%
submit: 0 = 0.0%, 4 = 100.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%, 64 = 0.0%,> = 64 = 0.0%
complete: 0 = 0.0%, 4 = 100.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%, 64 = 0.0%,> = 64 = 0.0%
issued: total = r = 404511 / w = 0 / d = 0, short = r = 0 / w = 0 / d = 0
Run status group 0 (all jobs):
READ: io = 1580.2MB, aggrb = 26967KB / s, minb = 26967KB / s, maxb = 26967KB / s, mint = 60000msec, maxt = 60000msec
readtest: (g = 0): rw = randread, bs = 4K-4K / 4K-4K / 4K-4K, ioengine = libaio, iodepth = 1
fio-2.1.3
Starting 1 process
readtest: Laying out IO file (s) (1 file (s) / 16MB)
Jobs: 1 (f = 1): [r] [100.0% done] [24492KB / 0KB / 0KB / s] [6123/0/0 iops] [eta 00m: 00s]
readtest: (groupid = 0, jobs = 1): err = 0: pid = 10442: Sun Jun 21 14:49:13 2015
read: io = 1580.2MB, bw = 26967KB / s, iops = 6741, runt = 60000msec
slat (usec): min = 46, max = 29997, avg = 146.55, stdev = 327.68
clat (usec): min = 0, max = 69, avg = 0.47, stdev = 0.66
lat (usec): min = 47, max = 30002, avg = 147.26, stdev = 327.88
clat percentiles (usec):
| 1.00th = [0], 5.00th = [0], 10.00th = [0], 20.00th = [0],
| 30.00th = [0], 40.00th = [0], 50.00th = [0], 60.00th = [1],
| 70.00th = [1], 80.00th = [1], 90.00th = [1], 95.00th = [1],
| 99.00th = [2], 99.50th = [2], 99.90th = [3], 99.95th = [12],
| 99.99th = [14]
bw (KB / s): min = 17680, max = 32606, per = 96.09%, avg = 25913.26, stdev = 3156.20
lat (usec): 2 = 97.95%, 4 = 1.96%, 10 = 0.02%, 20 = 0.06%, 50 = 0.01%
lat (usec): 100 = 0.01%
cpu: usr = 1.98%, sys = 5.94%, ctx = 405302, majf = 0, minf = 28
IO depths: 1 = 100.0%, 2 = 0.0%, 4 = 0.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%,> = 64 = 0.0%
submit: 0 = 0.0%, 4 = 100.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%, 64 = 0.0%,> = 64 = 0.0%
complete: 0 = 0.0%, 4 = 100.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%, 64 = 0.0%,> = 64 = 0.0%
issued: total = r = 404511 / w = 0 / d = 0, short = r = 0 / w = 0 / d = 0
Run status group 0 (all jobs):
READ: io = 1580.2MB, aggrb = 26967KB / s, minb = 26967KB / s, maxb = 26967KB / s, mint = 60000msec, maxt = 60000msec
Jnr-fuse result
serce @ SerCe-FastLinux: ~ / git / jnr-fuse / bench $ fio read.ini
readtest: (g = 0): rw = randread, bs = 4K-4K / 4K-4K / 4K-4K, ioengine = libaio, iodepth = 1
fio-2.1.3
Starting 1 process
readtest: Laying out IO file (s) (1 file (s) / 16MB)
Jobs: 1 (f = 1): [r] [100.0% done] [208.5MB / 0KB / 0KB / s] [53.4K / 0/0 iops] [eta 00m: 00s]
readtest: (groupid = 0, jobs = 1): err = 0: pid = 10153: Sun Jun 21 14:45:17 2015
read: io = 13826MB, bw = 235955KB / s, iops = 58988, runt = 60002msec
slat (usec): min = 6, max = 23671, avg = 15.80, stdev = 19.97
clat (usec): min = 0, max = 1028, avg = 0.37, stdev = 0.78
lat (usec): min = 7, max = 23688, avg = 16.29, stdev = 20.03
clat percentiles (usec):
| 1.00th = [0], 5.00th = [0], 10.00th = [0], 20.00th = [0],
| 30.00th = [0], 40.00th = [0], 50.00th = [0], 60.00th = [0],
| 70.00th = [1], 80.00th = [1], 90.00th = [1], 95.00th = [1],
| 99.00th = [1], 99.50th = [1], 99.90th = [2], 99.95th = [2],
| 99.99th = [10]
lat (usec): 2 = 99.88%, 4 = 0.10%, 10 = 0.01%, 20 = 0.01%, 50 = 0.01%
lat (usec): 100 = 0.01%, 250 = 0.01%
lat (msec): 2 = 0.01%
cpu: usr = 9.33%, sys = 34.01%, ctx = 3543137, majf = 0, minf = 28
IO depths: 1 = 100.0%, 2 = 0.0%, 4 = 0.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%,> = 64 = 0.0%
submit: 0 = 0.0%, 4 = 100.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%, 64 = 0.0%,> = 64 = 0.0%
complete: 0 = 0.0%, 4 = 100.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%, 64 = 0.0%,> = 64 = 0.0%
issued: total = r = 3539449 / w = 0 / d = 0, short = r = 0 / w = 0 / d = 0
Run status group 0 (all jobs):
READ: io = 13826MB, aggrb = 235955KB / s, minb = 235955KB / s, maxb = 235955KB / s, mint = 60002msec, maxt = 60002msec
readtest: (g = 0): rw = randread, bs = 4K-4K / 4K-4K / 4K-4K, ioengine = libaio, iodepth = 1
fio-2.1.3
Starting 1 process
readtest: Laying out IO file (s) (1 file (s) / 16MB)
Jobs: 1 (f = 1): [r] [100.0% done] [208.5MB / 0KB / 0KB / s] [53.4K / 0/0 iops] [eta 00m: 00s]
readtest: (groupid = 0, jobs = 1): err = 0: pid = 10153: Sun Jun 21 14:45:17 2015
read: io = 13826MB, bw = 235955KB / s, iops = 58988, runt = 60002msec
slat (usec): min = 6, max = 23671, avg = 15.80, stdev = 19.97
clat (usec): min = 0, max = 1028, avg = 0.37, stdev = 0.78
lat (usec): min = 7, max = 23688, avg = 16.29, stdev = 20.03
clat percentiles (usec):
| 1.00th = [0], 5.00th = [0], 10.00th = [0], 20.00th = [0],
| 30.00th = [0], 40.00th = [0], 50.00th = [0], 60.00th = [0],
| 70.00th = [1], 80.00th = [1], 90.00th = [1], 95.00th = [1],
| 99.00th = [1], 99.50th = [1], 99.90th = [2], 99.95th = [2],
| 99.99th = [10]
lat (usec): 2 = 99.88%, 4 = 0.10%, 10 = 0.01%, 20 = 0.01%, 50 = 0.01%
lat (usec): 100 = 0.01%, 250 = 0.01%
lat (msec): 2 = 0.01%
cpu: usr = 9.33%, sys = 34.01%, ctx = 3543137, majf = 0, minf = 28
IO depths: 1 = 100.0%, 2 = 0.0%, 4 = 0.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%,> = 64 = 0.0%
submit: 0 = 0.0%, 4 = 100.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%, 64 = 0.0%,> = 64 = 0.0%
complete: 0 = 0.0%, 4 = 100.0%, 8 = 0.0%, 16 = 0.0%, 32 = 0.0%, 64 = 0.0%,> = 64 = 0.0%
issued: total = r = 3539449 / w = 0 / d = 0, short = r = 0 / w = 0 / d = 0
Run status group 0 (all jobs):
READ: io = 13826MB, aggrb = 235955KB / s, minb = 235955KB / s, maxb = 235955KB / s, mint = 60002msec, maxt = 60002msec
The test only demonstrates the difference in the speed of reading the file in fuse-jna and fuse-jnr, however, based on it, you can get an idea of the difference in the speed of JNA and JNR. Those who wish can always write more detailed tests for native calls with the help of JMH , taking into account all the features, I myself would be interested to look at these tests.
The difference in throughput and latency in JNR and JNA is expected, as in the presentation from Charles Nutter, is ~ 10 times.
Links
- Fuse on sourceforge
- JNR on github
- Presentation from Charles Nutter about JNR
- JEP 191
- hello-fuse on java / hello-fuse on C
The jnr-fuse project is hosted on github . I will once be asterisks, pull requests, suggestions for improving the project.
And also I will be happy to answer all your questions about JNR and jnr-fuse.
Source: https://habr.com/ru/post/260801/
All Articles