Java string processing Part II: Pattern, Matcher
Introduction
What do you know about string handling in Java? How much of this knowledge and how deep and relevant are they? Let's try with me to sort out all the issues related to this important, fundamental and often used part of the language. Our small guide will be divided into two publications:
Today we will talk about regular expressions in Java, consider their mechanism and approach to processing. Also consider the functionality of the java.util.regex package.
Regular expressions
Regular expressions ( regular expressions , hereinafter referred to as PB) are a powerful and effective text processing tool. They were first used in text editors of the UNIX operating system ( ed and QED ) and made a breakthrough in electronic text processing of the end of the 20th century. In 1987, more complex RVs appeared in the first version of the Perl language and were based on the Henry Spencer package (1986) written in C. And in 1997, Philip Hazel developed the Perl Compatible Regular Expressions (PCRE) library, which exactly inherits RV in Perl. Now PCRE is used by many modern tools, for example Apache HTTP Server .
Most modern programming languages support RV, Java is no exception.
Mechanism
There are two basic technologies on the basis of which RV mechanisms are built:
')
- Nondeterministic finite state machine (NKA) - “mechanism controlled by a regular expression”
- Deterministic finite state machine (DFA) - “text driven mechanism”
NKA is a mechanism in which control inside the RV is transferred from component to component. The NCA looks at the PBs one by one and checks if the component matches the text. If it is the same, the next component is checked. The procedure is repeated until a match is found for all components of the RT (until we get a general match).
DKA is a mechanism that analyzes a string and monitors all “possible matches.” Its operation depends on each scanned character of the text (that is, the DFA is “text driven”). The Denmark mechanism scans the text symbol, updates the “potential match” and reserves it. If the next character cancels the “potential match”, then the DFA returns to the reserve. No reserve - no match.
It is logical that the DFA should work faster than the NKA (the DKA checks every character of the text no more than once, the NKA - as many times as it needs until the analysis of the RT is completed). But the NCA provides the ability to determine the course of further events. We can largely manage the process by properly writing RVs.
Regular expressions in Java use the NCA mechanism.
These types of finite automata are discussed in more detail in the article “Regular expressions from the inside” .
Treatment approach
In programming languages, there are three approaches to the processing of PB:
- integrated
- procedural
- object oriented
Integrated approach - embedding RV in the low-level syntax of the language. This approach hides all the mechanics, tuning and, as a result, simplifies the work of the programmer.
The functionality of the RV in the procedural and object-oriented approach is provided by functions and methods, respectively. Instead of special language constructions, functions and methods take strings as parameters and interpret them as PBs.
For processing regular expressions in Java, they use an object-oriented approach.
Implementation
To work with regular expressions in Java, the java.util.regex package is presented. The package was added in version 1.4 and already then contained a powerful and modern application interface for working with regular expressions. Provides good flexibility due to the use of objects that implement the CharSequence interest .
All functionalities are represented by two classes, an interface and an exception:
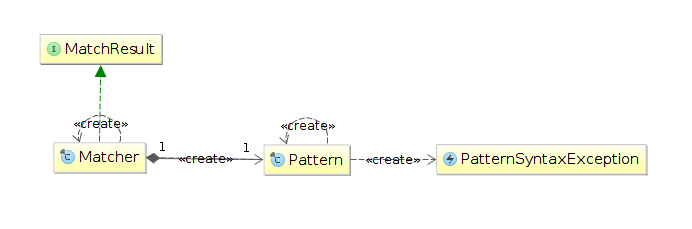
Pattern
The Pattern class is a compiled representation of the PB. The class does not have public constructors, so to create an object of this class, you must call the static compile method and pass the string with the PB as the first argument:
// XML <xxx></xxx> Pattern pattern = Pattern.compile("^<([az]+)([^>]+)*(?:>(.*)<\\/\\1>|\\s+\\/>)$"); Also, as a second parameter, a flag can be passed to the compile method as a static constant for the Pattern class, for example:
// email xxx@xxx.xxx ( ) Pattern pattern = Pattern.compile("^([a-z0-9_\\.-]+)@([a-z0-9_\\.-]+)\\.([az\\.]{2,6})$", Pattern.CASE_INSENSITIVE); Table of all available constants and their equivalent flags:
| No | Constant | Equivalent Embedded Flag Expression |
|---|---|---|
| one | Pattern.CANON_EQ | - |
| 2 | Pattern.CASE_INSENSITIVE | (? i) |
| 3 | Pattern.COMMENTS | (? x) |
| four | Pattern.MULTILINE | (? m) |
| five | Pattern.DOTALL | (? s) |
| 6 | Pattern.LITERAL | - |
| 7 | Pattern.UNICODE_CASE | (? u) |
| eight | Pattern.UNIX_LINES | (? d) |
// hex ? if (Pattern.matches("^#?([a-f0-9]{6}|[a-f0-9]{3})$", "#8b2323")) { // true // - } It is also sometimes necessary to split a string into an array of substrings using RVs. The split method will help us with this:
Pattern pattern = Pattern.compile(":|;"); String[] animals = pattern.split("cat:dog;bird:cow"); Arrays.asList(animals).forEach(animal -> System.out.print(animal + " ")); // cat dog bird cow Matcher and MatchResult
Matcher - a class that represents a string, implements a matching mechanism ( matching ) with the RT and stores the results of this matching (using the implementation of the MatchResult interface methods). It does not have public constructors, so to create an object of this class, use the matcher method of the Pattern class:
// URL String regexp = "^(https?:\\/\\/)?([\\da-z\\.-]+)\\.([az\\.]{2,6})([\\/\\w \\.-]*)*\\/?$"; String url = "http://habrahabr.ru/post/260767/"; Pattern pattern = Pattern.compile(regexp); Matcher matcher = pattern.matcher(url); But we have no results yet. To get them you need to use the find method. You can use matches - this method returns true only when the entire string matches the specified PB, unlike find , which tries to find a substring that satisfies the PB. For more detailed information on the results of matching, you can use the implementation of the methods of the MatchResult interface, for example:
// IP String regexp = "(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"; // find() matches() String goodIp = "192.168.0.3"; String badIp = "192.168.0.3g"; Pattern pattern = Pattern.compile(regexp); Matcher matcher = pattern.matcher(goodIp); // matches() - true, find() - true matcher = pattern.matcher(badIp); // matches() - false, find() - true // System.out.println(matcher.find() ? "I found '"+matcher.group()+"' starting at index "+matcher.start()+" and ending at index "+matcher.end()+"." : "I found nothing!"); // I found the text '192.168.0.3' starting at index 0 and ending at index 11. You can also start the search from the desired position using find (int start) . It is worth noting that there is another way to search - the method lookingAt . It starts checking the matches of the RV from the beginning of the string, but does not require full compliance, in contrast to matches .
The class provides methods for replacing text in the specified line:
| appendReplacement (StringBuffer sb, String replacement) | Implements the add-and-replace mechanism ( append-and-replace ). Creates a StringBuffer object (obtained as a parameter) by adding a replacement to the right places. Sets the position that matches the end () of the last search result. After this position adds nothing. |
| appendTail (StringBuffer sb) | It is used after one or several appendReplacement calls and is used to add the rest of the string to an object of the StringBuffer class, received as a parameter. |
| replaceFirst (String replacement) | Replaces the first sequence that corresponds to the PB with the replacement. Uses calls to the appendReplacement and appendTail methods . |
| replaceAll (String replacement) | Replaces each sequence that corresponds to the PB with the replacement. It also uses the appendReplacement and appendTail methods . |
| quoteReplacement (String s) | Returns a string in which the dash ( '\' ) and the dollar sign ( '$' ) will have no special meaning. |
Pattern pattern = Pattern.compile("a*b"); Matcher matcher = pattern.matcher("aabtextaabtextabtextb the end"); StringBuffer buffer = new StringBuffer(); while (matcher.find()) { matcher.appendReplacement(buffer, "-"); // buffer = "-" -> "-text-" -> "-text-text-" -> "-text-text-text-" } matcher.appendTail(buffer); // buffer = "-text-text-text- the end" PatternSyntaxException
Uncontrolled ( unchecked ) exception, which occurs when a regular expression syntax error occurs. The table below lists all the methods and their description.
| getDescription () | Returns a description of the error. |
| getIndex () | Returns the index of the line where the error was found in the PB |
| getPattern () | Returns the erroneous rv. |
| getMessage () | getDescription () + getIndex () + getPattern () |
Source: https://habr.com/ru/post/260773/
All Articles