Collection and visualization of application metrics in Graphite and Graph-Explorer
Often there is a need to track the various parameters of the application / service. For example, interest is the number of requests per second, the average server response time, the number of server responses with different HTTP status (technical metrics), the number of user registrations per hour, the number of payment transactions per minute (business metrics), etc. Without the metrics collection system product development and maintenance is almost blind.
This article is a guide to setting up a system for collecting and analyzing application metrics based on Graphite and vimeo / graph-explorer .
The metrics collection system is not a monolith. When deploying, you have to deal with a significant number of components, each of which somehow interacts with the others, has its own configuration file and a unique launch method. Even Graphite, in itself, consists of at least three subsystems - a metrics (carbon) daemon, a database with metrics (whisper, etc.) and a web application for visualization. When it is necessary to add graph-explorer support, everything becomes more interesting. Each of the subsystems has its own separate documentation, but nowhere is there a document describing the whole picture.
')
A metric is a sequence of (numeric) values over time. Very simple thing in essence. In fact, there is some string key and its corresponding row (sample 1 , time 1 ), (sample 2 , time 2 ), ... A typical way for Graphite to name metrics is to split string keys into parts using the " . " Symbol, for example, stats.web .request.GET.time . Graphite allows you to group metrics with a common prefix, using the " * " symbol when plotting graphs. Obviously, this is not the most flexible way to work with keys. If you need to add another component to the key, it can break the construction of graphs. For example, casting the key from the example above to the form stats.web. server1 .request.GET.time will break the common prefix for historical data. The second significant disadvantage of such naming of metrics is the potential ambiguity of their interpretation. Much more self-sufficient would be metrics that have keys of the form service = web server = server1 what = request_time unit = ms with the further ability to build combined charts using common tags, and not just general prefixes. Fortunately, the guys from vimeo came up with metrics 2.0 and started their graph-explorer running on top of graphite. The main idea is a logical representation of metrics, like entities with a set of tag-value pairs. Each metric in the 2.0 format still eventually is converted into a regular string key, separated by dots and placed in carbon, but previously an “index” is created in a separate storage that stores information about the correspondence of these keys and tag-value pairs. Thus, using information from indexes, graph-explorer and implements the combination of different metrics on the same graph.
In general, the metrics collection system can be represented by the following diagram:
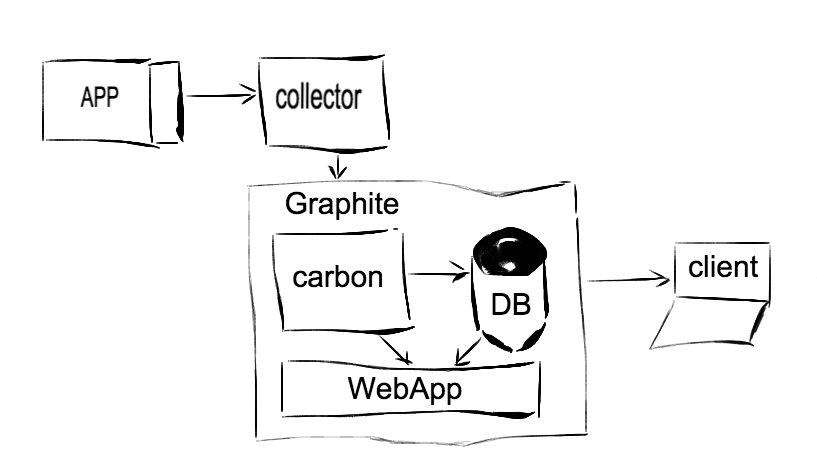
Thus, an application (web service, daemon, etc.), written not in any language, sends metrics to a collector through a certain interface (layer), collects them partially, aggregates, calculates the update frequency (optional), and sends them in a certain amount of time. in carbon, which gradually puts them in storage. The web application pulls data from the repository (and partially from carbon itself) and builds graphs for us. The carbon daemon is actually 3 whole daemons: carbon-cache, carbon-relay and carbon-aggregator. In the simplest case, you can use carbon-cache. The carbon-relay implementation can be used for the purpose of sharding (load distribution among several carbon-cache) or replication (sending the same metrics to carbon-cache only). The carbon-aggregator daemon is able to perform intermediate processing of metrics before sending them to the repository. Metrics data in carbon can be transferred in one of two formats: plain text (so-called line protocol) to port 2003 and serialized to pickle to port 2004. At the same time, carbon-relay only returns data to the pickle (important! ).
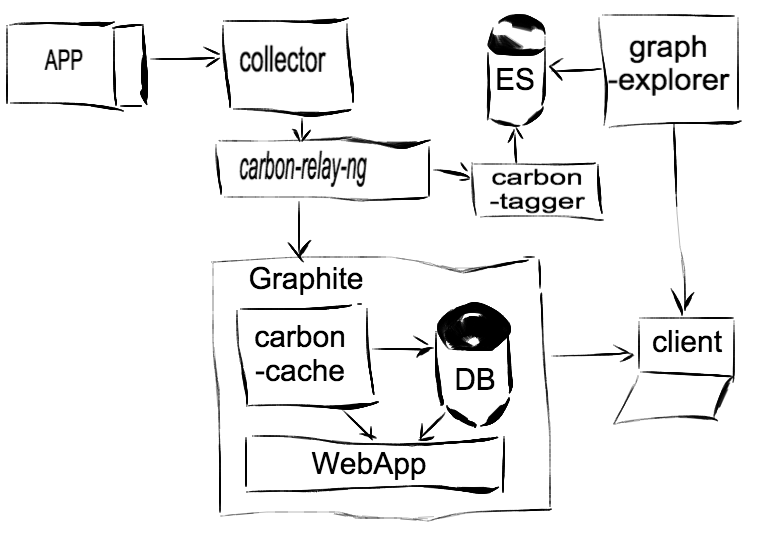
The graph-explorer add-in adds another storage for the so-called. indexes of metrics. Elastic search is used as such storage. It is obvious that in some place of the system represented in the diagram it is necessary to add a link that will “index” the metrics. This link is carbon-tagger . As a result, the system takes the following form:
Next comes the specifics, in your case, perhaps some of the components will be replaced by another solution.
The system is designed to collect metrics 2.0 and then use them in graph-explorer.
The installation will take place in the / opt / graphite directory, which is the default directory. Some of the components are written in Go, so it will also have to be preset and set the corresponding environment variables. Installation implies that Go is one in the system. If you have several versions of Go installed, then you can skip this step and configure the required version at your own discretion.
Another important point when deploying the system is to closely monitor the ports. It is a lot of components, everyone uses on several ports and it is easy to be mistaken, with whom to connect. Plus, most components do not have any built-in authorization mechanism and at the same time listen to the interface 0.0.0.0 by default. Therefore, I highly recommend wherever it is possible to change the interface to the local one and close all ports on the server via iptables.
The most popular statsd was chosen as the client involved in sending metrics from the application. Its implementation is infinitely simple. In fact, this is sending text data to the specified UDP / TCP port with the addition of minimal protocol service data.
An example of use in the application code:
In the “classic” graphite installation scheme, statsd is often used as an intermediate collector. In our case, the statsdaemon is used, as it out of the box can work with metrics 2.0, while maintaining backward compatibility with the statsd protocol. It is written on Go and its installation is extremely simple (caution, now in README.md an annoying error in the installation team):
After that, the statsdaemon executable file should appear in the / opt / go / bin directory. The settings for this daemon are quite simple:
Running statsdaemon:
At this stage, it is already possible to start statsdaemon and send several packages to it from the application using the statsd client. The console output will speak for itself.
The current installation guide is here . Installation is best done inside the virtual environment, located in / opt / graphite.
After installation, the graphite will be located in / opt / graphite. Next, you need to perform its configuration. Sample configuration files are in / opt / graphite / conf. The minimum that needs to be done is to create the carbon and whisper settings file.
Next you need to run carbon-cache:
And graphite webapp using uwsgi + any web server (for example, nginx):
Nginx settings:
It remains only to install carbon-tagger (it is he who fills in the index base for graph-explorer) and set up duplicate sending of metrics to carbon-cache and carbon-tagger using carbon-relay. But unfortunately, carbon-tagger does not know how to work using the pickle protocol, and carbon-relay only sends data in this format. Therefore, you need to install a drop-in replacement for carbon-relay from vimeo - carbon-relay-ng :
The carbon-tagger daemon is written in Go and deals with sending indexes of metrics to Elastic Search for later use in graph-explorer. First of all, it is necessary to install java and Elastic Search on the server. Carbon-tagger setting:
Running carbon-tagger:
And finally, the installation of the nail program:
Running graph-explorer:
After that, the graph-explorer web interface will be available at metrics.yourproject.net .
Stopliving with your eyes closed,% habrauser%! Expand metrics collection systems and share interesting schedules from your projects! Thanks for attention!
This article is a guide to setting up a system for collecting and analyzing application metrics based on Graphite and vimeo / graph-explorer .
Motivation
The metrics collection system is not a monolith. When deploying, you have to deal with a significant number of components, each of which somehow interacts with the others, has its own configuration file and a unique launch method. Even Graphite, in itself, consists of at least three subsystems - a metrics (carbon) daemon, a database with metrics (whisper, etc.) and a web application for visualization. When it is necessary to add graph-explorer support, everything becomes more interesting. Each of the subsystems has its own separate documentation, but nowhere is there a document describing the whole picture.
')
Metrics
A metric is a sequence of (numeric) values over time. Very simple thing in essence. In fact, there is some string key and its corresponding row (sample 1 , time 1 ), (sample 2 , time 2 ), ... A typical way for Graphite to name metrics is to split string keys into parts using the " . " Symbol, for example, stats.web .request.GET.time . Graphite allows you to group metrics with a common prefix, using the " * " symbol when plotting graphs. Obviously, this is not the most flexible way to work with keys. If you need to add another component to the key, it can break the construction of graphs. For example, casting the key from the example above to the form stats.web. server1 .request.GET.time will break the common prefix for historical data. The second significant disadvantage of such naming of metrics is the potential ambiguity of their interpretation. Much more self-sufficient would be metrics that have keys of the form service = web server = server1 what = request_time unit = ms with the further ability to build combined charts using common tags, and not just general prefixes. Fortunately, the guys from vimeo came up with metrics 2.0 and started their graph-explorer running on top of graphite. The main idea is a logical representation of metrics, like entities with a set of tag-value pairs. Each metric in the 2.0 format still eventually is converted into a regular string key, separated by dots and placed in carbon, but previously an “index” is created in a separate storage that stores information about the correspondence of these keys and tag-value pairs. Thus, using information from indexes, graph-explorer and implements the combination of different metrics on the same graph.
General view
In general, the metrics collection system can be represented by the following diagram:
Thus, an application (web service, daemon, etc.), written not in any language, sends metrics to a collector through a certain interface (layer), collects them partially, aggregates, calculates the update frequency (optional), and sends them in a certain amount of time. in carbon, which gradually puts them in storage. The web application pulls data from the repository (and partially from carbon itself) and builds graphs for us. The carbon daemon is actually 3 whole daemons: carbon-cache, carbon-relay and carbon-aggregator. In the simplest case, you can use carbon-cache. The carbon-relay implementation can be used for the purpose of sharding (load distribution among several carbon-cache) or replication (sending the same metrics to carbon-cache only). The carbon-aggregator daemon is able to perform intermediate processing of metrics before sending them to the repository. Metrics data in carbon can be transferred in one of two formats: plain text (so-called line protocol) to port 2003 and serialized to pickle to port 2004. At the same time, carbon-relay only returns data to the pickle (important! ).
The graph-explorer add-in adds another storage for the so-called. indexes of metrics. Elastic search is used as such storage. It is obvious that in some place of the system represented in the diagram it is necessary to add a link that will “index” the metrics. This link is carbon-tagger . As a result, the system takes the following form:
Technology stack
Next comes the specifics, in your case, perhaps some of the components will be replaced by another solution.
- Python application
- statsd client for Python
- statsd / statsdaemon
- graphite
- carbon-relay / carbon-relay-ng
- carbon-cache
- whisper
- webapp
- carbon-tagger
- graph explorer
The system is designed to collect metrics 2.0 and then use them in graph-explorer.
Installation
The installation will take place in the / opt / graphite directory, which is the default directory. Some of the components are written in Go, so it will also have to be preset and set the corresponding environment variables. Installation implies that Go is one in the system. If you have several versions of Go installed, then you can skip this step and configure the required version at your own discretion.
cd /opt wget https://storage.googleapis.com/golang/go1.4.2.linux-amd64.tar.gz tar -C /usr/local -xzf go1.4.2.linux-amd64.tar.gz echo 'export PATH=$PATH:/usr/local/go/bin' >> /etc/profile echo 'export GOPATH=/opt/go' >> /etc/profile echo 'export GOBIN="$GOPATH/bin"' >> /etc/profile echo 'export PATH=$PATH:$GOBIN' >> /etc/profile source /etc/profile go env # #GOBIN="/opt/go/bin" #GOPATH="/opt/go" #GOROOT="/usr/local/go" Another important point when deploying the system is to closely monitor the ports. It is a lot of components, everyone uses on several ports and it is easy to be mistaken, with whom to connect. Plus, most components do not have any built-in authorization mechanism and at the same time listen to the interface 0.0.0.0 by default. Therefore, I highly recommend wherever it is possible to change the interface to the local one and close all ports on the server via iptables.
statsd python client
The most popular statsd was chosen as the client involved in sending metrics from the application. Its implementation is infinitely simple. In fact, this is sending text data to the specified UDP / TCP port with the addition of minimal protocol service data.
# pip install statsd An example of use in the application code:
import statsd client = statsd.StatsClient(host='statsdaemon.local', port=8125) # metrics 2.0 tag_is_value client.gauge('service_is_myapp.server_is_web1.what_is_http_request.unit_is_ms', <execution_time>) statsd
In the “classic” graphite installation scheme, statsd is often used as an intermediate collector. In our case, the statsdaemon is used, as it out of the box can work with metrics 2.0, while maintaining backward compatibility with the statsd protocol. It is written on Go and its installation is extremely simple (caution, now in README.md an annoying error in the installation team):
go get github.com/Vimeo/statsdaemon/statsdaemon After that, the statsdaemon executable file should appear in the / opt / go / bin directory. The settings for this daemon are quite simple:
statsdaemon.ini
# --- /etc/statsdaemon.ini --- listen_addr = ":8125" # statsd- () admin_addr = ":8126" graphite_addr = "carbon.local:2013" # carbon , flush_interval flush_interval = 30 prefix_rates = "stats." prefix_timers = "stats.timers." prefix_gauges = "stats.gauges." percentile_thresholds = "90,75" max_timers_per_s = 1000 Running statsdaemon:
statsdaemon -config_file="/etc/statsdaemon.ini" -debug=true At this stage, it is already possible to start statsdaemon and send several packages to it from the application using the statsd client. The console output will speak for itself.
Graphite
The current installation guide is here . Installation is best done inside the virtual environment, located in / opt / graphite.
sudo apt-get install python-pip python-dev pip install pip --upgrade pip install virtualenv mkdir /opt/graphite virtualenv /opt/graphite cd /opt/graphite source bin/activate sudo apt-get install libcairo2 python-cairo libffi-dev # graphite pip install https://github.com/graphite-project/ceres/tarball/master pip install whisper pip install carbon # pip install carbon --install-option="--prefix=/opt/graphite" --install-option="--install-lib=/opt/graphite/lib" pip install graphite-web # pip install graphite-web --install-option="--prefix=/opt/graphite" --install-option="--install-lib=/opt/graphite/webapp" # Graphite WebApp pip install uwsgi pip install django pip install cairocffi pip install django-tagging # webapp (cd /opt/graphite/webapp/graphite; python manage.py syncdb) After installation, the graphite will be located in / opt / graphite. Next, you need to perform its configuration. Sample configuration files are in / opt / graphite / conf. The minimum that needs to be done is to create the carbon and whisper settings file.
cp /opt/graphite/conf/carbon.conf.example /opt/graphite/conf/carbon.conf # carbon.conf carbon-cache, carbon-relay carbon-aggregator. # carbon-cache: # LINE_RECEIVER_INTERFACE = 127.0.0.1 # LINE_RECEIVER_PORT = 2003 cp /opt/graphite/conf/storage-schemas.conf.example /opt/graphite/storage-schemas.conf # storage-schemas.conf whisper, - fixed-size db. # 1 , ( # ), . ... Next you need to run carbon-cache:
carbon-cache.py --conf=conf/carbon.conf start # --debug tail -f /opt/graphite/storage/log/carbon-cache/carbon-cache-a/*.log And graphite webapp using uwsgi + any web server (for example, nginx):
cp /opt/graphite/webapp/graphite/local_settings.py.example /opt/graphite/webapp/graphite/local_settings.py # local_settings.py SECRET_KEY TIME_ZONE. /opt/graphite/bin/uwsgi --socket localhost:6001 --master --processes 4 --home /opt/graphite --pythonpath /opt/graphite/webapp/graphite --wsgi-file=/opt/graphite/conf/graphite.wsgi.example --daemonize=/var/log/graphite-uwsgi.log Nginx settings:
graphite.conf
upstream graphite_upstream { server 127.0.0.1:6001; } server { listen 8085; server_name graphite.local; location / { include uwsgi_params; uwsgi_pass graphite_upstream; add_header 'Access-Control-Allow-Origin' '*'; add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS'; add_header 'Access-Control-Allow-Headers' 'origin, authorization, accept'; add_header 'Access-Control-Allow-Credentials' 'true'; proxy_redirect off; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Host $server_name; } } It remains only to install carbon-tagger (it is he who fills in the index base for graph-explorer) and set up duplicate sending of metrics to carbon-cache and carbon-tagger using carbon-relay. But unfortunately, carbon-tagger does not know how to work using the pickle protocol, and carbon-relay only sends data in this format. Therefore, you need to install a drop-in replacement for carbon-relay from vimeo - carbon-relay-ng :
go get -d github.com/graphite-ng/carbon-relay-ng go get github.com/jteeuwen/go-bindata/... cd "/opt/go/src/github.com/graphite-ng/carbon-relay-ng" make cp carbon-relay-ng /opt/go/bin/carbon-relay-ng touch /opt/graphite/conf/carbon-relay-ng.ini cd /opt/graphite carbon-relay-ng conf/carbon-relay-ng.ini carbon-relay-ng.ini
instance = "default" listen_addr = "127.0.0.1:2013" admin_addr = "127.0.0.1:2014" http_addr = "127.0.0.1:8081" spool_dir = "spool" log_level = "notice" bad_metrics_max_age = "24h" init = [ 'addRoute sendAllMatch carbon-default 127.0.0.1:2003 spool=true pickle=false', # carbon-cache 'addRoute sendAllMatch carbon-tagger 127.0.0.1:2023 spool=true pickle=false' # carbon-tagger ] [instrumentation] graphite_addr = "" graphite_interval = 1000 carbon-tagger
The carbon-tagger daemon is written in Go and deals with sending indexes of metrics to Elastic Search for later use in graph-explorer. First of all, it is necessary to install java and Elastic Search on the server. Carbon-tagger setting:
go get github.com/Vimeo/carbon-tagger go get github.com/mjibson/party go build github.com/Vimeo/carbon-tagger carbon-tagger.conf
[in] port = 2023 # carbon-relay-ng [elasticsearch] host = "esearch.local" port = 9200 index = "graphite_metrics2" flush_interval = 2 max_backlog = 10000 max_pending = 5000 [stats] host = "localhost" port = 2003 # carbon-tagger ( ) id = "default" flush_interval = 10 http_addr = "127.0.0.1:8123" Running carbon-tagger:
(cd /opt/go/src/github.com/Vimeo/carbon-tagger/; ./recreate_index.sh) # ES carbon-tagger -config="/opt/graphite/conf/carbon-tagger.conf" -verbose=true graph explorer
And finally, the installation of the nail program:
pip install graph-explorer graph-explorer.conf
[graph_explorer] listen_host = 127.0.0.1 # , HTTP Basic Auth nginx listen_port = 8080 filename_metrics = metrics.json log_file = /var/log/graph-explorer/graph-explorer.log [graphite] url_server = http://localhost url_client = http://graphite.local:8085 # graphite webapp nginx / graph-explorer.conf
server { listen 80; server_name metrics.yourproject.net; location / { auth_basic "Who are you?"; auth_basic_user_file /etc/nginx/.htpasswd; proxy_pass http://localhost:8080; } } Running graph-explorer:
mkdir /var/log/graph-explorer run_graph_explorer.py /opt/graphite/conf/graph_explorer.conf After that, the graph-explorer web interface will be available at metrics.yourproject.net .
Instead of conclusion
Stop
Source: https://habr.com/ru/post/260753/
All Articles