Backup, Archive and Restore Architecture
Based on the EMC Data Domain administration course, Kuzma Pashkov made an impressive review of deduplication types, backup and recovery systems architecture using the example of EMC products, made an overview of EMC products, elaborated on Data Domain, and also made an overview of the Data Domain administration course.
Why is Data Domain so expensive? Why is this not storage? What you need to know about the design / commissioning / configuration / technical documentation of these systems? What to pay attention to? - these and other questions are given comprehensive answers.

')
Under the review of the cut-based decoding and video.
Family of technologies and products Backup Recovery Solutions
I, as an engineer, are not ashamed to say that this product is good, because of all the listed analogues, the Data Domain appeared on the market first, as I recall. According to the results of tests and competitions choose this solution. The notion of “old” can be applied to these complexes of even the lowest ruler very conditionally, since the life span of these decisions is 5-7 years, which is very much.
Our training course is built in the format of training - 50% of theory and 50% of practice, of course, in the beginning I will talk more. The laboratory itself is physically located in the USA, there for each of you, the participant of the training, there is a high-grade Data Domain.
Let's start with the necessary input on the EMC storage systems. As I understand it, this is not the first time you come across EMC products, and remember that EMC, VMware, RSASecruity is one conglomerate. Therefore, the products of all these corporations can be considered in the framework of a single nomenclature, not in the sense of managing companies, but in the sense that all these products are integrated with each other. This has achieved a very deep degree of integration. We will only consider EMC products. We are interested in the part called Backup Recovery Solutions. A part of these decisions is borrowed, at the expense of absorbed companies. For example, the head product, called Networker, is a full-featured enterprise-class backup tool that fights with its competitors in this market - where does it come from? - from the company Legata, which has been developing this product since the late 80s, now it is already EMC.
Further, the product that we are going to study - Data Domain - was a company of the same name, which was the first on the market to launch a similar hardware and software system for storing backup copies, EMC absorbed it. The next is Avamar. I specifically list the main products, because they are all interconnected with each other. Avamar was the name of a California company that once again released enterprise-class backup tools with source deduplication, a very specific solution that revolutionized the backup strategy, the product used to be called Axion, if I remember correctly. And there is Data Protection Adviser , about this product I don’t remember whether it was the development of the EMC, or it was a takeover of the company.
In fact, this is not a complete list, why did I list all these products? In order to tell you that these are all parts of a single whole - right now, in the yard 2015, EMC in price lists, in the work of its followers, positions all these products as parts of a single product package within Backup Recovery Solutions - a single a product that allows you to unify the protection of any data that may occur in any corporation. By combining these products for a long time, EMC has taught these products to integrate very deeply. Networker can work either on its own or delegate part of the functions to Data Domain or Avamar, Avamar can directly integrate with Data Domain without Networker, and can all work together in one “band-watering”. About Data Protection Advisor - generally a separate conversation.

In this regard, it is impossible not to talk about this in the courses on these products, because a significant part of the functionality is tied to this integration. If we talk about our Data Domain, then a significant part of its functions has not changed over the years, because everything is already good there, even before absorption. But after that, most of the improvements are due to the fact that the Data Domain must be able to “be friends” with its “brothers” in order for it to become one. If we consider each product separately, then this is a set of functions or services. But when these products are integrated, this is not a mathematical addition of functions, there appear some unique superproperties that cannot be ignored. Even in our course, which is the first in the list of authorized training, we will talk a lot about these functions. Therefore, these things need to be positioned: what is what and what role it takes. Products will be listed and described in a certain, not random, order.
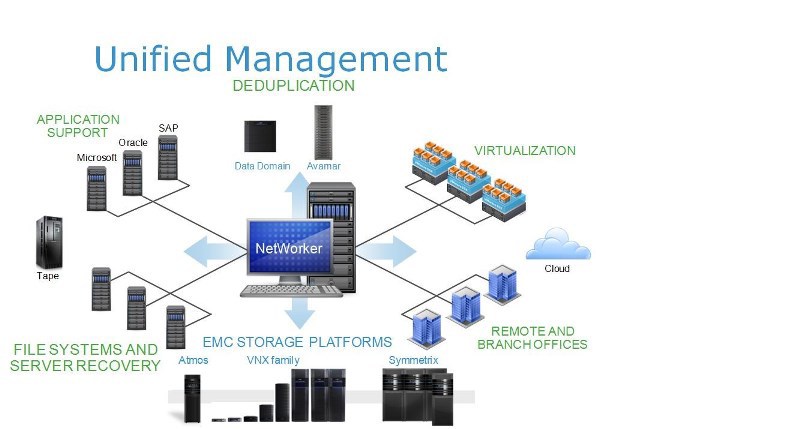
First talk about Networker. This is the main product - the core, data protection systems in terms of system copying and archiving. In fact, this is a classic multi-tier client-server backup tool, a software package. A distribution kit, elements whose links are decomposed into: backup copies in the form of clients, a backup server in the form of storage nodes, to which some storages are connected that are connected to clients by some kind of transmission medium. Launching it will be LAN or SAN, something like that. And there is a master server, which we call a backup directory. There are centralized tools, where there is a server that keeps a single record of backups, storage media on which they hit, where backup policies are stored, rules that automate the whole process. In fact, on this link, which is called the Networker server, the backup bodies themselves are not stored, only their accounting and control. Here "tyrka" various admin consoles, etc. The connection of all links is carried out, of course, via the TCP / IP protocol through a local network, via a global network - it does not matter. We are naturally interested in the issues of traffic backup traffic.
Here we have a backup source - whatever it is, and we have a destination. As already mentioned, Networker’s backup tools are enterprise class, which means that it can separate one from the other. Backup traffic can be transmitted through selected segments - intellectually and consciously. A typical local ethernet network or any kind of a network server working over a fiberchannel is any method of communication. This means that Networker knows what LAN Free Backup is, heard about it, right? What else can a networker do? For example, backup the backup source without loading it. I will not specifically apply, this is called a serverless or proxy backup. The fact that I list these functions does not mean that only Networker can do them, it means that he owns them like his competitors. Networker can backup NASes, because it knows what NDMP is, NDMP protocol freeware backup - who does not know what it is? This is the implementation of lanfree serverless for dedicated file dumps. Networker, born in 1989, has a long history and its matrix of compatible software and hardware is very large. It is designed for a heterogeneous network, it can have anything in its sources, a very large compatibility matrix: various operating systems and business applications, which it can backup without stopping, what is called an online backup, it has a huge number of different integrations, including various Microsoft and others.
Traditionally, Networker, as a backup, used robotic tape libraries in the first place - in this it is good enough, it has a very large matrix of compatible libraries. No one says that he can not backup to discs - of course it can! But we know that it is a little expensive to store backups on disks, especially at current volumes. I say this to the point that initially Networker was designed to work with tape libraries and still works best with them. And for the traditional approach to the protection of data centers - this is quite normal. It is economically easy to prove the feasibility of using Networker to protect combat servers that sit in the data center: all sorts of Orakly, Sequel, application server, huge data that is within the data center, on a high-speed, dedicated network, we drive to some backup storage. All is well, but Networker, as it happens, knows what deduplication is, but does not know how to do it on its own. Not because the developers did not think about it, but because by that time someone already knew how to do this deduplication. Therefore, if you want to organize efficient streaming compression for some part of backup sources, you can use Data Domain as one of the many storages with which Networker can work, because it is actually a disk shelf with hard drives which We will consider hardware deduplication, which makes it very efficient to compress backup archive streams that fall on this shelf.
Accordingly, this box has a lot of interfaces, which we will talk about in detail. The idea remains the same - a single owner, a single accounting of backups, some of them fall on some traditional repositories, and some falls on a repository with deduplication, disk deduplication. It should be understood that deduplication is not a panacea and it is economically feasible to use it as a whole, and such products in particular. If we use the traditional campaign - tapes, alienable media with sequential access, then there the recovery rate, as you do not fizzle out, will be measured in hours. If this Recovery Time Objective indicator needs to be reduced to some acceptable minimum - then you need to store backup copies on disks - but this is expensive, so let's apply deduplication if it is applicable, of course - the source of backup copies may be contraindicated to compression - not zhmyetsya and everything, and at least kill. Here a reasonable thought immediately comes to mind: when they talk about using something with deduplication, a customer’s automated system survey is required as part of some methodology and justification — an assessment of this achievable coefficient. If there is no survey, what can you expect? Someone says that he can "guarantee" some kind of compression ratio - it's amazing to hear that! Of course, pure marketing. But in real life is not so simple.

Data Domain can perform deduplication independently, using its own resources, wasting its processor ticks, its processor power, RAM - without straining the source. It is very good. DD can receive backup streams via LAN, via ethernet - 10 gigabits, 40 gigabits is declared. Or, if necessary, delegate some of the functions related to compression to the source itself, if this is permissible. Data Domain has many interfaces - to accept a simultaneous stream of multiple backup archives, but the most effective one is the licensed DD Boost interface, this protocol and Data Domain are inseparable. DD can be used without DD Boost, but this interface itself can only be used in DD.
The Data Domain is economically viable, it is easy to prove, to use for protection, after all the servers that are sitting in the data center, which are connected to the DD by some kind of common, high-speed data transfer medium, are not VAN, this is LAN or SAN. Again, we are talking only about servers for which deduplication is acceptable, and if not, then we need disks. This is the prose of life, in general.
The combat servers for which deduplication is not applicable, for which the RTO indicator is not so cruel, it is quite normal to back them up to robotic tape libraries, etc. There are backup sources for which the RTO is critical, they need to be able to quickly recover, this is required by the security policy and there are no deduplication contraindications for them - they bought Data Domain and told Networker some of the backup streams from these sources to send to such storage
And what about the third category of backup sources and the most numerous? - with jobs? And if they are connected to the repository unreliable communication channels? Then work intermittently, the bandwidth is weak, etc. It is useless, very inconvenient to backup them in the traditional way and with deduplication to the repositories. Here EMC says, ok, we have such a product - Avamar, which of course can be used independently - and for the protection of servers and it is suitable, and for the protection of anything. But its peculiarity is that it always performs compression on the source. First, straining the source, compressing, as far as possible, the data to be backed up, and then only in compressed form transmits a unique delta, a copy to some kind of storage. Avamar, in terms of integration, can work with all products of the family, can also work very effectively under the control of Networker.
Considering that it integrates everything with each other, all categories of backup sources can be protected - it is possible with technologies from a single supplier. Just left? - Correlation of events that occur in these complex software and hardware complexes, with events that occur on network equipment, storage, data storage systems, etc. In order to comply with what is called SLA, secondly in order to be able to organize billing. The idea is very simple - all of the above products, individually and collectively, are what is called cloud ready. This means that you can build a cloud backup service from them and rent it. I am an operator, I built my own data center servers, put these products in there and rent them to you as legal entities. In order for you to guarantee the level of quality of service and to invoice everyone, as you use my infrastructure you need billing. To organize this part, we need such a product - Data Protection Adviser (DPA), advisor. This is a separate software package whose clients are placed on all information sources, which has a centralized database, where all the information is collected, where it is semantically enlarged, checked against a certain database of signatures of some events. Well, then someone is sitting, looking at the monitor, and he is shown in red - everything is bad, or he is told, advice is given - what to do? And he either writes reports or bills his superiors - a great thing.
What does Data Domain consist of?
I have listed not all modules of a single modular product, since we do not have much time. But if there are those who want to show themselves RTO reduced to zero. There is a product Recover Point, which again integrates with everyone, in particular with Networker, which implement the concept of continuous protection.
In our course, the focus will be on a small part of this software and hardware complex - only Data Domain. But we will always talk about it in the light of integration with other products from the family, or from third-party manufacturers, which is also not a problem.
There are many experienced guys among you who have already worked with Data Domain competitors. If you try to determine what Data Domain is, then it may turn out like this: disk storage of deduplications for storing backup copies of archives. No more and no less. This is a very important point. This is not a storage system, comparing it with something like that makes no sense. Because it is a storage for storing working data, for which the load profile is, in general, as it were, universal: sequential reading, writing, and random reading and writing are possible there. There these serious indicators of iops, those who work with DSS knows about it. In DSS, whatever they are: weak, medium, high-end - all other things being equal, there is some kind of common architecture. Front-end, there is some kind of cache, backend, fault tolerance, multi-looping, and the like. Data Domain is not a storage system, never call it that way - it's a sin :)
Data Domain is a server. If I take this hardware, then I see a software and hardware complex, there is hardware, in the form of computer hardware, software in the form of system software, this is the OS, there is some kind of application software.
The hardware is what? Intel's chipset, as much memory as possible, a couple of power supplies, there is a PCI express bus, some slots, 4 network cards with gigabit interfaces and 2 copper with 10 gigabits are built into the motherboard. By default, there are already more than 1 redundant network interfaces for connecting to the external environment in order to receive control traffic, in order to receive backup streams and issue recovery streams. Already good. In the slots, we can plug in more network cards, depending on the models, the power may also be limited by the chipset. You can plug in the fiber channel host bace adapter, though for some money, I saw such an adapter 4x and 8 gigabit, 16gigabit someone saw? I saw that they were declared, like 40 Gigabit Ethernet, but as yet there are none, you can expect them.
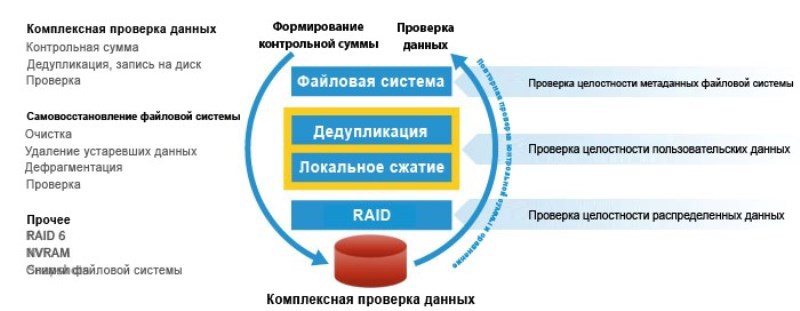
What else is on the bus? There, by default, there is already a disk controller, SAS and more than one, there should be 2. On the bus which hang any disks, disk array. In the younger Data Domain models, this is right in the case of the server itself, which is mounted in a rack. How many winchesters are there? Minimum - 7, maximum - 15. If you have a more serious Data Domain model, you can add one or more disk shelves to the SAS controller bus. In the disk shelves are spinning, before it was miserable sata-hard drives, now it's NL SAS-hard drives. How does NL SAS differ from SAS?NL SAS is like a cheap SAS (a satin screw made through the SAS bus, the exchange rate was increased, but the screw architecture itself was left as it was). SAS, roughly speaking, this is the good old scsi. NL SAS is Sasovskiy Vinci, which, according to the results of the production, did not pass any cruel tests for performance, reliability, but have some acceptable level, so they are cheaper. Roughly speaking, Sasovskiy Vinci have a time between failures of the NL SAS. I'm not talking about performance, but about reliability. These winchesters, of which there are many, tens or hundreds, are naturally collected in some sort of raid arrays. (Each regiment is going to a separate raid array) it is also called a disk group (there are no iron controllers there, in fact this is a software raid, this is neither bad nor good, it just works that way,and in each shelf another hot spare disk). I saw that in the head a couple of disks are allocated for the OS. (Previously, this was not the case; now, in the older Data Domain models, 4 disks are used for this Data Domain OS. They are taken out separately, there are mixed raids). There useful data is not stored, there is only official.
If you recall the logic of building a raid 6 arrays. What is there overhead? One logical write operation of some data block is how many physical operations (I'm talking about iops)? 3 readings + 3 records. That is, overhead is wild! The 6th raid has the largest overhead, the 5th has less overhead: 2 reads + 2 entries. The disk system in this server is very slow, so we remember that we said that this is not storage.
OS is a kind of Linux-like OS, called DD OS (Data Domain Operating System). In general, for an ordinary customer, consumer, it is brought to an unrecognizable form - you are not there traditional shells. There is a simple command interpreter, with a system of commands with a simple syntax. And if you are not an engineer, but you do not have technical support service or engineering access, then forget about most of the unix-based commands and utilities you know. As an application, there will be a terminal of various daemons: Daemon VTL, Deamon DDBoost, Deamon NTP, Deamon NFS and so on. The set of which is built into this Linux distribution, in order to receive / send backup streams through a variety of these application-level protocols.

Why is Data Domain so expensive?
Well, then I ask why Data Domain is so expensive? What is so special about the parts that I cannot assemble from? We do not take into account marketing, etc., if we take into account the technical part - in one of the PCI slots there is one or several special cards, which are called NVRAM cards. Specialized card, with some amount of RAM in the chip, 1 gigabyte, 2, 4 gigabytes, with some, we will consider a specialized microprocessor. This is the board with which these streams of incoming backup archives are compressed using the central processor. The same board, where the same deduplication takes place. This is what allows older models of DD to “run down” dozens of terabytes of data per hour. Imagine 10 terabytes per hour of incoming traffic, and what should be the performance of the disk subsystem,collected from NL SASov in raid 6? Yes, there must be an insane amount of them!
But as in the older and younger Data Domain models, the disk subsystem is no different in performance. The total number of iops that it can produce is small. Absolutely inadequate to the set of functions that are required for such a volume of data. All these "hellish" terabytes are compressed at the input to an acceptable level, and only acceptable load reaches the disk subsystem. The deduplication technology, or rather its implementation in the Data Domain, is patented.
If you fly to California, Santa Clara, where this division is, it is now called Data Protection and Availability Division, formerly BRS, then there is a “hall of fame” in the hall, where all these patents and their copies hang. And this is an expensive pleasure. When you buy a Data Domain, you pay all these patents, to the patent owner, for his super-development, which is kept secret in a certain part, we will also talk about this later. I do not want to say that other vendors do not have similar technologies, but the price order is the same as for Data Domain. They all fight hard for the consumer. The main competitor is HP Storeonce and IBM Protectier.
That is, the Data Domain will look like this: a server, with or without shelves, connected via ethernet only, or both via ethernet and via fiberchannel, receiving backup streams through a variety of different protocols. It turns out that the main competitive advantage of this product is, in fact, deduplication.

Deduplication
You need to deal with this in order to go further. Roughly speaking, this is compression. What is the essence of compression - to reduce the amount of data. Only when they say “compression” in the general case, it means that we are looking for a repeating data sets and replace them with some kind of links, in some local data set. When we say "deduplication" - then we are talking about global compression, I am looking not only for repeating data on this source of backup copies, but in general everywhere, on all general backup sources.
Accordingly, we have deduplication at different levels of abstraction. What I am saying is not new, but it is necessary to speak in the same vocabulary.
1) Filebased. At the file level. You are all backing up some data on me, and I'm looking for some duplicate files. Some file came from someone, it turned out that he had never met me, he was unique - I put it in the repository. I spent some resources, a place in the storage, to place the body of this file there. Another copy of the same file came from someone, I somehow became convinced of this. And instead of wasting resources, I save the meta-information that such a file is found there and there. And the overhead will be 2 orders of magnitude less, instead of storing the file body in the storage.
How to check files? The simplest is bitwise reconciliation, it cannot be discounted, in certain cases it is more effective than calculating the reference characteristic, hashes, etc. Therefore, never miss it, I will tell about it a little later. Most backup systems use this approach: let's run this data set through some function, and no matter what size of the source data set, we will get some kind of hash, a reference characteristic of a fixed size. And within the framework of this mathematical dependence, we will have a definite guarantee that if one bit changes in the initial set, the result of the hashing will be completely different. I specifically raise this question, in the course materials you will not see this, to tell you the following: yes,The hashing function is directly related to symmetric cryptography, it is a separate class of mathematical functions. And for them the problem of collisions is urgent. The probability that different data sets will have the same hash is not zero. But it can be reduced to an acceptable minimum. And for those cases when these collisions happen by some compensating measures to guarantee that the integrity of the data will not be compromised. I specifically voiced it, because, in particular, in the Data Domain, the developers paid attention to this question, and provide a mathematical guarantee, proof that these collisions are not a problem, and they are dealt with by compensating means.But it can be reduced to an acceptable minimum. And for those cases when these collisions happen by some compensating measures to guarantee that the integrity of the data will not be compromised. I specifically voiced it, because, in particular, in the Data Domain, the developers paid attention to this question, and provide a mathematical guarantee, proof that these collisions are not a problem, and they are dealt with by compensating means.But it can be reduced to an acceptable minimum. And for those cases when these collisions happen by some compensating measures to guarantee that the integrity of the data will not be compromised. I specifically voiced it, because, in particular, in the Data Domain, the developers paid attention to this question, and provide a mathematical guarantee, proof that these collisions are not a problem, and they are dealt with by compensating means.and cope with them using compensating means.and cope with them using compensating means.
In this case, all unique data sets have unique hashes. If collisions occur, this can be neglected. This is proven, it is a patented technology, not from the ceiling it is taken. What algorithm, what to check or not to check - we do not know. I specifically repeat, the deduplication algorithm (it is large, if you draw a diagram - the room is not enough), this takes into account. And developers are talking about this.
This technology is so stupid, but God forbid if you can get a compression ratio of 1.5-2 times. This is an average figure, but to expect at least something here is extremely difficult. Even if you have some kind of file “garbage” as a backup source, there are many duplicate files.
2) If I have a compression ratio at the head, then let's search for not files, but data blocks of fixed length. Let's give all the data that we fall to crumb into fixed pieces, usually in kilobytes. For each piece we calculate the hash, and check with the hashes of those pieces whose bodies lie in our storage. There is a hit - ok, it is preserved, we will not save it, there is no hit - this is a piece unique, it's time to put it in the vault.
This approach is good than that the brain does not need much to include. But it works best for backup sources where the data is already structured. If the dataset where we are looking for changed blocks, it is already initially modified by fixed transactions, of a fixed size, then this is very convenient. On Monday there were only blocks, then on Tuesday the block changed so-and-so. When the backup tool crumbles this file into bits of fixed size on Tuesday, it strictly localizes the changes.
The compression ratios that can be achieved with this approach are already greater. On average, it can be 2-5 times. But here it is important that the source meets certain requirements, where the data is already structured and changes are made by fixed transactions of a certain size. Most often it is a DBMS. For such data are given good performance. And if unstructured winnigret? The algorithm will not be able to localize these changes, because everything is moving there.
3) Therefore, there is an deduplication algorithm for data blocks of varying size. The essence of this algorithm is to localize the changes. Even if the file has changed at the beginning or in the middle, the system will understand that it is only these blocks that have changed, and the rest have remained the same. Typically, such algorithms use data whose blocks vary 4k-32k. There is a guarantee that if the original data set has not changed, the result of its “kroshilov” will be the same. And he will be able to localize only the changed part of the data. All these algorithms of this kind are patented. They are all kept secret. In fact, these are all variations of what is called Bloom's filter- if you want to strain your mathematical apparatus. Therefore, part of the patents in Santa Clara, they are about it. On the patented implementation of the system of theorems. Someone really strained his brain.
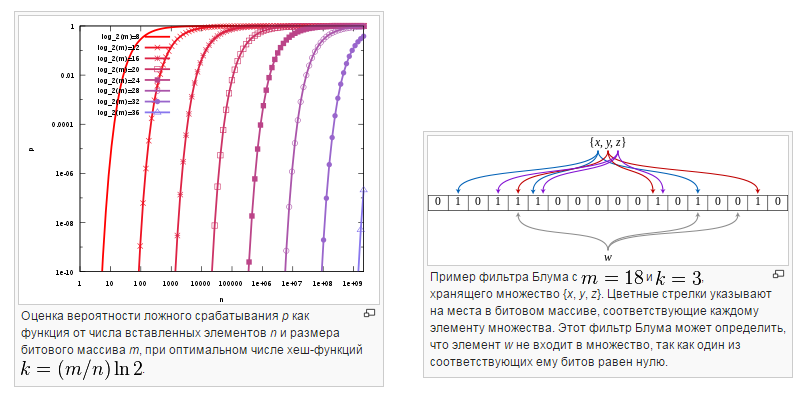
Now, if we talk about deduplication at all, at what level of abstraction is it better to perform it? 1st, 2nd, 3rd way ... no, wrong, no "correct" answer. An approximate correct answer is: the ideal backup tool should be able to perform deduplication at all levels of abstraction, adjusting to the features of backup sources.
In simple terms: I have a file "trash", unstructured information backed up? Let me first quickly, without straining anyone: I will find duplicate files and throw them away, those that are unique - ok, I'll start to chop up. If this file is the database body, then I will crush it of a certain size into structured files, and if unstructured blocks, I will crush it into data blocks of varying size. Because you always have to find a compromise between the compression ratio and overhead, the load on this compression.
It is necessary to calculate these hashes, it is necessary to compare them, and this annoys someone, we haven’t yet specified whom. And the greater the load, the greater the rate of the backup window. We have to look for some kind of compromise. The better squeezed, the slower will be some kind of RTO, etc. Therefore, companies are looking for a compromise between these parameters. And I would very much like the backup tool, on the one hand, to tell him: you yourself intellectually understand what deduplication, at what level of abstraction, for what source to perform. On the other hand, say to him: here is such a framework for you.
For example, for this data - I need to compress it as much as possible, I for this it is important that when compressing it fit into the backup window, and for this the recovery time is important. And so, Networker in combination with Data Domain and Avamar represents such an intelligent backup system.
There was a question about Microsoft
In the Microsoft, in the OS, 2012 version in the case of the installation of the role of the file server there is an option that implements the deduplication of data blocks of varying length at the volume level. And there are coefficients of 1.5-2%. If we are talking about Avamar, then it performs deduplication at all 3 levels of abstraction, if about Data Domain, then it performs deduplication always at the 3rd level - data blocks of varying length. The hashing algorithm that is used — Industrial — Secure Hash Algoritm, and the reference characteristic size is 160 bits.
Go ahead.We have already visualized the architecture of a classic modern enterprise-class backup tool - client-based, multi-link. There are many sources - customers, there is some kind of data transfer medium that connects these sources with what is called a media server, storage nodes that are connected to the repositories. And there is some backup directory that conducts all of this.
So, in terms of deduplication. It can be performed by whom? Who is this hero? There is a postbased option. There is a terabyte of data, it was transferred through some kind of environment to the storage, into the allotted backup window, it ate up terabytes of data, for this it needs a lot of spindles, the terabyte was spent, and then, probably, outside the backup window this compression begins: files, fixed data blocks, etc. - but this is tense storage itself. And here it went down 10 times, there are 100 gigs. Good or bad - I do not say. For example, Windows Server 2012 does just that. VNX works similarly, but the latest models can do deduplication, not only at the level of file blocks, but also at the level of the moon - and it does this on its own schedule, and we save our expensive place.
There is deduplication on the go. A terabyte was read, transmitted through the transmission medium, there is no savings, but before getting into the disk storage subsystem, this terabyte is compressed using a processor, RAM, and we remove this insane number of iops, and get some adequate amount of them, which can be written to the disk subsystem. Do not need a lot of spindles, do not need a lot of space. Here we have it - Data Domain. It can do this through any software interfaces.
The third option.Deduplication at the source. I read the terabyte and immediately strained the source. He is already tense reading a large array of data, transferring them somewhere, and here they still need to be compressed. Here he gave it up to 100 gigs and already unfortunate 100 gigs passed over the data transfer system to the storage. Avamar and Data Domain can do this when using the DDboost interface with DCP functionality enabled. That is, the Data Domain knows what deduplication is at the source. The most interesting thing is that he knows and what is post-deduplication, the first type we talked about. Data Domain has a time when it understands itself, and this also implies postbased deduplication.
The set of threads that fall on the Data Domain, it crumbles them, into pieces of varying size, counts them into hashes, checks their arrays. But there is a mathematical guarantee that for 99% of these pieces, it can be understood whether they are unique or not. And for 1% he will not be able to do it in time. Consider that he will put these pieces somewhere in order to be in time, and then they will be able to do it after the fact. How and why this happens I will explain later. There is nothing wrong with that, no one declares it, but no one refuses it. The performance data for each Data Domain model posted on the EMC website is not pure marketing. They made a laboratory, a program of test methods, set up a live Data Domain, and began to backup something on it and achieved these results, measured them strictly. Clear,that under certain conditions, perhaps even ideal, but no one promises manna from heaven. Everyone says: do research, justify, prove to the customer that exactly this coefficient will be obtained, this absorption rate will be obtained in his situation - and then sell it.

What I have said is some kind of educational program for backup tools. education.emc.com- learning portal, you probably know about it, it's good to go there more often. There is an excellent Backup Recovery Systems and Architecture course that takes 40 hours. A course on the basics of backup and archiving, there is about this multi-tier, about serverless proxy backups, deduplication, there are a lot of things written. The course is actually a university one, it is taught in senior courses of technical universities, partners of the EMC academic program, masters are taught, as part of the second higher education. In the St. Petersburg Polytechnic, in Moscow universities, I read this course. The course itself is very interesting, I specifically speak about it, because it would be desirable for each of you to at least look through it and look at it. Because everyone has white spots in education. Being engaged in protection systems for more than 10 years, I thought that I had eaten a dog on this, that it was no surprise for me - but no.5 days - 40 hours, just about these basics.
Go ahead.On the EMC website in the data protection section, I look at the product range. Data protection means their integrity and availability in the first place. Not privacy! When it comes to all sorts of secrets, we go to RSASecurity. I have a dozen products here and in the backup recovery section I have the EMC Data Protection Suite - this is a single hardware and software system for protecting all categories of data.

I want to look at the Data Domain models and look at their characteristics. There are a lot of models for every taste and wallet. I want to see the weakest model - Data Domain DD160. It has 7 disks by default, or you can expand to 12. The architecture of all Data Domain models is the same, but those that are cheaper have certain limitations. For example, you will not add a shelf - the possibility of scaling is limited, you cannot install many network interfaces there, hostbased adapters. And here configuration maximum - 160 model is ready to totally absorb backup streams at speeds up to 1 terabyte / hour. How to interpret this indicator? Provided? That the stream goes through ethernet and DDboost, DCP is enabled, with deduplication at the source. If there is no DDboost, then you can safely divide by 2: incoming and outgoing. DDboost is already working a lot with anyoneeven HP Data Protector can work with it, Netbackup has known for a long time, Backup Exec has known for a long time - this is an industry standard, because it hasn’t been invented for other alternatives.
What is the 195 TB Logical capacity? How to interpret this? That is, before compression, almost 200 tb, and its capacity is 1.7. What is needed compression ratio? If roughly rounded - 20 times? I have customers who have: 3 times sorry - cool!

Contraindications
Why I pay attention to it - I say it again - it all depends on the data. When talking about deduplication I did not specifically mention contraindications. If, for example, my data is encrypted, initially presented in the form of a cryptogram, and I backup it. What we get compression ratios? Encryption algorithms and compression algorithms are from the same category of mathematical functions. They do about the same thing, but they have different goals. Some provide confidentiality, while others reduce their volume. All that is encrypted is contraindicated for compression, since after it the data will take even more space.
Well, if the data is compressed already. Media, anything. What ratios can you expect? It can be expected, but it all depends on the backup scheme. If I have a media archive with a capacity of 10 TB, which does not press, but every day I do a full backup, this is not an option - no one does.
Therefore, it is necessary to identify contraindications, where there are none - to conduct surveys. And calculate this achievable compression ratio. To some extent, it can be calculated empirically, look at the data, EMC has statistics and say: shake 5 times. From this one can make a start. Do you have SQL and Exchange, so many mailboxes of such and such size? There is a formula where you drive it in and get the result.
Everyone touched Backup System Sizer? He gives an approximate estimate. My customers are divided into 2 categories, some say: write us in detail on the documents, justify, technical justification, etc. And others say: we do not need anything from the documents, but are you personally responsible for what you promised? Ideally, of course, to be responsible for your words, you need to make sure for yourself that this compression ratio will turn out exactly.
Then it is better to do what integrators do not like to do very much: give the customer into trial operation at least a weak, even second-hand, Data Domain. Let it be there for some time, and we will in fact see what the coefficient is. And we will make a start of this, develop a technical and commercial proposal.
Documentation and training
What is it all about? Without the design phase - not enough. Someone must conduct a survey in the framework of some developed methodology, write a technical task for the protection system. Protection plan, position and categorization of information resources. Plan for job security, disaster recovery. All these documents should be. Someone has to evaluate, say, for example, that this category - deduplication is not needed there, it is possible here - but not to load the source, here it is possible, there is such a coefficient, here it is.
This job is done by the integrator, or partner, as EMC calls them. EMC has a special training program for architects, for those designs, for design engineers. Where all this is taught: survey and the preparation of technical documentation. EMC works at the planet level - everything is standardized for them. Engineer and in the United States and in Ukraine works on the same samples. Nothing to invent.
But not every customer asks for it. Therefore, if you are a customer, you should ask the integrator to request this package of documents. Not reference infu from the site, and descriptions of the technology of manufacture and maintenance of this product. If you work in the integrator - everything is there, just need to ask.
For the start-ups, those who produce the product according to the documentation, have their own training courses, we are at one of them. These are usually engineers from partners and from the EMC itself.
For custom owners, those who, after commissioning, work with and serve this, have their own courses - for admins, our course can also be called for admins.
All this is painted on the EMC learning portal. Even if you are a customer, there are a lot of things available to you. Personally, I can share examples of design documentation, because it is difficult to write them from scratch. Therefore, it is necessary to support the engineering intelligentsia, because the owners do not like to pay money for it, but this is necessary, because it is a separate activity.
Either you are sitting in the integrator and you are creating these sets of documents in a stream, or you are in a large customer and this is for you the first time. Even if you act as a representative of the customer and control the actions of the contractor, you need to understand what is required of him. Therefore, it is better to know what to do.
For all stages of the life cycle of an automated system in terms of its protection system - EMC has a training and certification program for all their products. Will you consider other courses - it is already necessary to look.
Administration of EMC Data Domain: introduction to the course
Introductory we dealt with the basics of system copying and archiving. We, in fact, quickly ran through the contents of a university course, or a 5-day course on the architecture of these systems. At the same time looked deduplication. Strictly positioned Data Domain in the EMC product range. They drew conclusions - what to expect from him and what should not be expected from him - what is most important.
From the name of our course it is obvious what we are going to talk about. If you look at our life cycle model, then we are talking about support, maintenance, already, in fact, a finished black box. Someone who: designed how it will be built into the existing or new environment, painted a set of design and operational documentation. Someone on this kit carried out the assembly, installation, commissioning of this product, at least in the general part and then it was transferred to the customer’s personnel along with the documentation. The customer administers, in a small, narrow degree, in some corridor, he carries out an additional adjustment. But the main task of this staff is monitoring. We check the current status of this box, with the reference, which was recorded at the stage of commissioning.
Trabshuting
If the current state does not match the reference state - we identify the cause, we eliminate the malfunction. And then it all goes through the cycle. Newly finalizing the TZ - version 2.0. Because something has changed, the risks have changed, life has changed. And according to this cycle, and develops a system of protection. A normal, mature company, this cycle is already the 5th or 7th time, not doing everything from scratch, but developing. This is true for any other products.
Our course is a specific project, there is a beginning, there is a result. And so I need to define the boundaries of this project: what are we going to talk about, what are we not going to talk about. We will not talk about design, as there are other courses about it. We will talk about start-up only in the part concerning the customer. There are separate courses for EMC engineers and integrating partners where it is written: how to assemble this Data Domain, mount it with a set of shelves in a rack, how to tag, connect all these connections, how to create raid arrays, how to fill in the OS image, how to implement engineering maintenance that is not free.
We, as customers, say that we have collected someone, assigned IP for the control interface, someone set the password for the built-in administrator account and gave us these access attributes. And we will add something in the framework of the available documentation. We have an emphasis on administration, in some part on the setting.

What course is clear. Target audience - I have already voiced, it is also clear: both the customers, and partners, and the guys from EMC. Everyone goes here because they need to approach everyone under the same educational standards. Entrance requirements - I have already voiced: this is a university course, it is there, where you can find it and what you can already do with it.

Since this course is a project, we remember that as a result of this small project, you should have some kind of understanding, theoretical knowledge, practical, very specific skills related to this product. This means that there must be a comprehensive understanding of deduplication: what it is, and how it is specifically implemented in a particular product. What a set of patented technologies is, not necessarily related to the deduplication implemented in the Data Domain, it is worth the money for you to see what these patents are.
How to monitor this black box, how to manage it, through what administrative interfaces you can connect to it and you can start to do something with it. Here is the command line and GUI. How to differentiate access to this product. Data Domain is a multiplayer appl, there are many people who should have access to it. Accordingly, it is necessary to distinguish between this access and control, it is impossible to allow someone to spoil something - this is expensive equipment.
How to perform an initial setup is when there is a ready black box that you configure for your structure. Based on the design documentation that someone has developed for you. An example of such documentation you have in the form of a training manual for the lab. The format you have for example is ideal for such documentation. If you want to develop such documents for your start-up engineers - do it in this form, you have a good example.
Identify and configure Data Domain data paths - through which interfaces are physical, logical, Data Domain can receive backup archive copies — there are a lot of them. Let's list them all, and for each of them we will write a setup procedure, we will carry out tests on the stand, so that this description corresponds to reality, so that there is some kind of evidence. We have a stand for this.
Configure and manage Data Domain network interfaces - configure the Data Domain network subsystem. The simplest model has an excessive amount of network interfaces built into the motherboard. This is good, because it is possible to ensure at a minimum - fault tolerance, the interfaces break, the wires break, and it works. And as a maximum - to aggregate its bandwidth, to summarize the interfaces to achieve some results.

It's one thing to initialize Data Domain, another thing is to start throwing some data at it through different interfaces. We will follow a simple logic: from simple to complex, from general to specific. At the beginning, we will touch simple interfaces that are easy to configure and do not require separate licenses. And then it will all be difficult to complicate. For example, take the Data Domain internal file system and start structuring. We will make a structured system from some large piece of data so that it is convenient to manage.
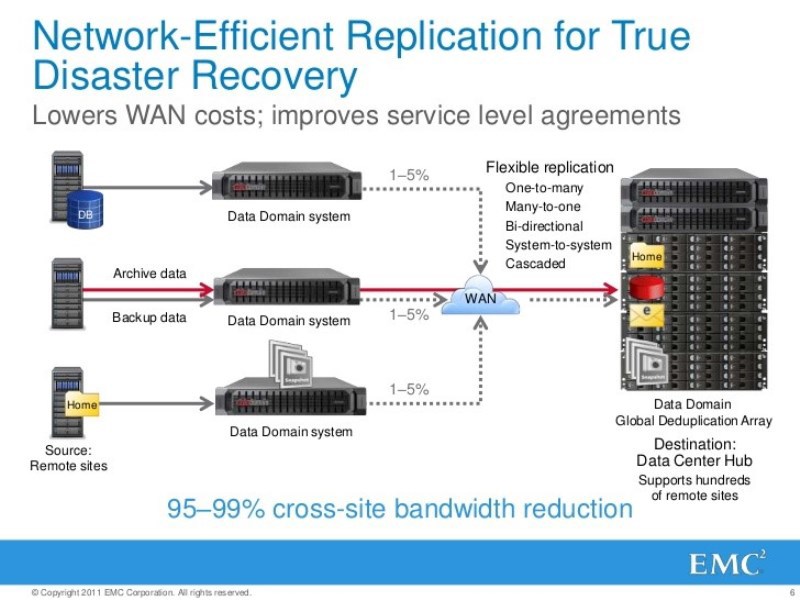
Recall that the Data Domain in the general case - a disaster-resistant product. When they wrote TZ to its developers, they gave the task so that the Data Domain could survive complete destruction. What does it mean? - in time to reset the replica of critical data backups to another Data Domain. True, this thing is licensed.
The issues of business continuity are very relevant, especially after 9/11. And people thought: what will happen if I have a fire or something?
Remember the RTO indicator - no matter what happens, just as much will be lost - no more, and no matter what happens, you can return everything back for so long.
There was a question about what, one of the reasons to use disk storage for backups is an improvement in the RTO, recovery time. For example, we did all the backups to tape libraries, now the security requirements have changed, now the data needs to be restored even faster, the libraries do not work, what to do? Let's replace the Data Domain library, which will look like a library on the front end, but with a better RTO. How to make one or more virtual robotic tape libraries out of one or two Data Domain? How to present them to existing backup tools so that they are minimally strained?
The most important thing to understand here is how to tune up the backup tools so that they write something to the virtual tape library correctly. Because to write in the old manner, as they are used to, physically, there is no longer worth it, due to the very same deduplication.

If you are not tied to libraries, if you do not have a task to replace the virtual physical library with a virtual one, buy a Data Domain with the licensed function DDboost. Since this is for the Data Domain native interface, which reveals all its features. This is the best way to use Data Domain. This means that backup tools know what DDboost is, in the worst case, at best, combat business applications that back up know it, this is the coolest.
In my opinion, the best-selling configuration is Networker with Data Domain via DDboost, they look very organic. But we understand that DDboost is an open interface. EMC says: let your backup tool be yours, but let them know what DDboost is and use our optimized interface to store backup copies. How to set it up - we'll see.
In our course, there will be a lab as a friend of Data Domain with Networker through DDboost, and a lab of friendship with Symantek netback through DDboost with a Data Domain. To demonstrate this flexibility Data Domain.
There will be a primer on the design of backup systems for the architects that we talked about. Some elements of the methodology for selecting the appropriate Data Domain model to the requirements of a particular customer, their range is large. We will understand that the work in this even prisile - not easy.
Who will be interested in further deepening the design issues - you know who to ask.
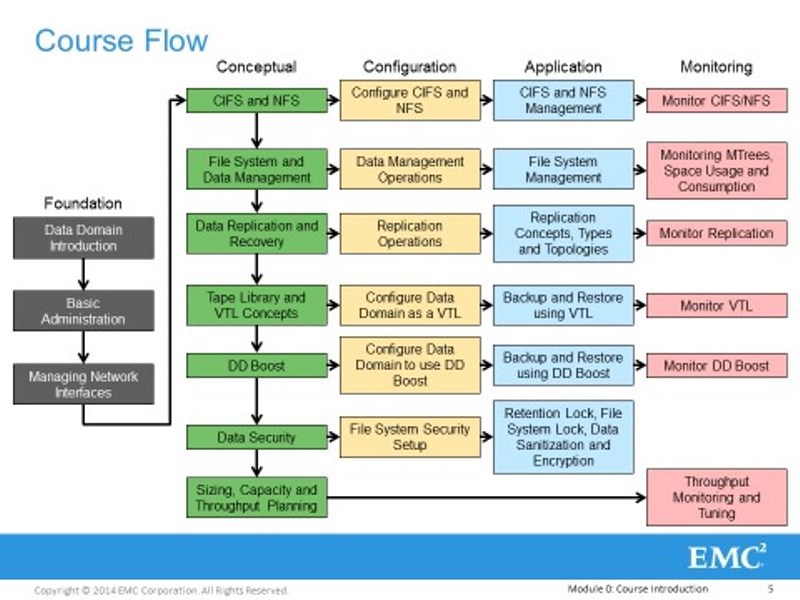
Here are our modules. From simple to complex, from general to specific. We have 10 modules, but we will also make the 11th optional module. Let's start with an introduction, the basics of administration, and the configuration of the network subsystem. Let's continue with simple, license-free interfaces - CIFS, NFS, which can drive backup and archiving traffic. And we will continue to complicate all this further. Moving to VTL and DDboost and to such a protection that is in the Data Domain, with which you can provide an acceptable level of information security. In accordance with the requirements of laws and regulators.

To determine the boundaries of our course, let us say once again that - this is a software and hardware complex. There is hardware, there is software. The hardware has its own identification system - three-digit models, for example, 160 are older, 4-digit ones are newer. And the software part is determined by the OS version - DD OS, the current DD OS version, which can be downloaded from the site - 5.5, and our course is still designed for 5.4. So the 11th module out of 10 will be about significant changes in 5.5. Each hardware hardware has its own software update limit.
In this part, while all.
Videotape
EMC courses at MUK TC
On July 6-9, the MUK TC center will have a course on Data Domain System Administration that this instructor will take - enroll in a course
And:
July 15-17 - VNX Block Storage Management
July 21-25 - EMC NetWorker Microsoft Applications Implementation and Management
Distribution of EMC solutions in Ukraine , Tajikistan , Belarus , Moldova , CIS countries .
MUK-Service - all types of IT repair: warranty, non-warranty repair, sale of spare parts, contract service
Why is Data Domain so expensive? Why is this not storage? What you need to know about the design / commissioning / configuration / technical documentation of these systems? What to pay attention to? - these and other questions are given comprehensive answers.
')
Under the review of the cut-based decoding and video.
Family of technologies and products Backup Recovery Solutions
I, as an engineer, are not ashamed to say that this product is good, because of all the listed analogues, the Data Domain appeared on the market first, as I recall. According to the results of tests and competitions choose this solution. The notion of “old” can be applied to these complexes of even the lowest ruler very conditionally, since the life span of these decisions is 5-7 years, which is very much.
Our training course is built in the format of training - 50% of theory and 50% of practice, of course, in the beginning I will talk more. The laboratory itself is physically located in the USA, there for each of you, the participant of the training, there is a high-grade Data Domain.
Let's start with the necessary input on the EMC storage systems. As I understand it, this is not the first time you come across EMC products, and remember that EMC, VMware, RSASecruity is one conglomerate. Therefore, the products of all these corporations can be considered in the framework of a single nomenclature, not in the sense of managing companies, but in the sense that all these products are integrated with each other. This has achieved a very deep degree of integration. We will only consider EMC products. We are interested in the part called Backup Recovery Solutions. A part of these decisions is borrowed, at the expense of absorbed companies. For example, the head product, called Networker, is a full-featured enterprise-class backup tool that fights with its competitors in this market - where does it come from? - from the company Legata, which has been developing this product since the late 80s, now it is already EMC.
Further, the product that we are going to study - Data Domain - was a company of the same name, which was the first on the market to launch a similar hardware and software system for storing backup copies, EMC absorbed it. The next is Avamar. I specifically list the main products, because they are all interconnected with each other. Avamar was the name of a California company that once again released enterprise-class backup tools with source deduplication, a very specific solution that revolutionized the backup strategy, the product used to be called Axion, if I remember correctly. And there is Data Protection Adviser , about this product I don’t remember whether it was the development of the EMC, or it was a takeover of the company.
In fact, this is not a complete list, why did I list all these products? In order to tell you that these are all parts of a single whole - right now, in the yard 2015, EMC in price lists, in the work of its followers, positions all these products as parts of a single product package within Backup Recovery Solutions - a single a product that allows you to unify the protection of any data that may occur in any corporation. By combining these products for a long time, EMC has taught these products to integrate very deeply. Networker can work either on its own or delegate part of the functions to Data Domain or Avamar, Avamar can directly integrate with Data Domain without Networker, and can all work together in one “band-watering”. About Data Protection Advisor - generally a separate conversation.
In this regard, it is impossible not to talk about this in the courses on these products, because a significant part of the functionality is tied to this integration. If we talk about our Data Domain, then a significant part of its functions has not changed over the years, because everything is already good there, even before absorption. But after that, most of the improvements are due to the fact that the Data Domain must be able to “be friends” with its “brothers” in order for it to become one. If we consider each product separately, then this is a set of functions or services. But when these products are integrated, this is not a mathematical addition of functions, there appear some unique superproperties that cannot be ignored. Even in our course, which is the first in the list of authorized training, we will talk a lot about these functions. Therefore, these things need to be positioned: what is what and what role it takes. Products will be listed and described in a certain, not random, order.
First talk about Networker. This is the main product - the core, data protection systems in terms of system copying and archiving. In fact, this is a classic multi-tier client-server backup tool, a software package. A distribution kit, elements whose links are decomposed into: backup copies in the form of clients, a backup server in the form of storage nodes, to which some storages are connected that are connected to clients by some kind of transmission medium. Launching it will be LAN or SAN, something like that. And there is a master server, which we call a backup directory. There are centralized tools, where there is a server that keeps a single record of backups, storage media on which they hit, where backup policies are stored, rules that automate the whole process. In fact, on this link, which is called the Networker server, the backup bodies themselves are not stored, only their accounting and control. Here "tyrka" various admin consoles, etc. The connection of all links is carried out, of course, via the TCP / IP protocol through a local network, via a global network - it does not matter. We are naturally interested in the issues of traffic backup traffic.
Here we have a backup source - whatever it is, and we have a destination. As already mentioned, Networker’s backup tools are enterprise class, which means that it can separate one from the other. Backup traffic can be transmitted through selected segments - intellectually and consciously. A typical local ethernet network or any kind of a network server working over a fiberchannel is any method of communication. This means that Networker knows what LAN Free Backup is, heard about it, right? What else can a networker do? For example, backup the backup source without loading it. I will not specifically apply, this is called a serverless or proxy backup. The fact that I list these functions does not mean that only Networker can do them, it means that he owns them like his competitors. Networker can backup NASes, because it knows what NDMP is, NDMP protocol freeware backup - who does not know what it is? This is the implementation of lanfree serverless for dedicated file dumps. Networker, born in 1989, has a long history and its matrix of compatible software and hardware is very large. It is designed for a heterogeneous network, it can have anything in its sources, a very large compatibility matrix: various operating systems and business applications, which it can backup without stopping, what is called an online backup, it has a huge number of different integrations, including various Microsoft and others.
Traditionally, Networker, as a backup, used robotic tape libraries in the first place - in this it is good enough, it has a very large matrix of compatible libraries. No one says that he can not backup to discs - of course it can! But we know that it is a little expensive to store backups on disks, especially at current volumes. I say this to the point that initially Networker was designed to work with tape libraries and still works best with them. And for the traditional approach to the protection of data centers - this is quite normal. It is economically easy to prove the feasibility of using Networker to protect combat servers that sit in the data center: all sorts of Orakly, Sequel, application server, huge data that is within the data center, on a high-speed, dedicated network, we drive to some backup storage. All is well, but Networker, as it happens, knows what deduplication is, but does not know how to do it on its own. Not because the developers did not think about it, but because by that time someone already knew how to do this deduplication. Therefore, if you want to organize efficient streaming compression for some part of backup sources, you can use Data Domain as one of the many storages with which Networker can work, because it is actually a disk shelf with hard drives which We will consider hardware deduplication, which makes it very efficient to compress backup archive streams that fall on this shelf.
Accordingly, this box has a lot of interfaces, which we will talk about in detail. The idea remains the same - a single owner, a single accounting of backups, some of them fall on some traditional repositories, and some falls on a repository with deduplication, disk deduplication. It should be understood that deduplication is not a panacea and it is economically feasible to use it as a whole, and such products in particular. If we use the traditional campaign - tapes, alienable media with sequential access, then there the recovery rate, as you do not fizzle out, will be measured in hours. If this Recovery Time Objective indicator needs to be reduced to some acceptable minimum - then you need to store backup copies on disks - but this is expensive, so let's apply deduplication if it is applicable, of course - the source of backup copies may be contraindicated to compression - not zhmyetsya and everything, and at least kill. Here a reasonable thought immediately comes to mind: when they talk about using something with deduplication, a customer’s automated system survey is required as part of some methodology and justification — an assessment of this achievable coefficient. If there is no survey, what can you expect? Someone says that he can "guarantee" some kind of compression ratio - it's amazing to hear that! Of course, pure marketing. But in real life is not so simple.
Data Domain can perform deduplication independently, using its own resources, wasting its processor ticks, its processor power, RAM - without straining the source. It is very good. DD can receive backup streams via LAN, via ethernet - 10 gigabits, 40 gigabits is declared. Or, if necessary, delegate some of the functions related to compression to the source itself, if this is permissible. Data Domain has many interfaces - to accept a simultaneous stream of multiple backup archives, but the most effective one is the licensed DD Boost interface, this protocol and Data Domain are inseparable. DD can be used without DD Boost, but this interface itself can only be used in DD.
The Data Domain is economically viable, it is easy to prove, to use for protection, after all the servers that are sitting in the data center, which are connected to the DD by some kind of common, high-speed data transfer medium, are not VAN, this is LAN or SAN. Again, we are talking only about servers for which deduplication is acceptable, and if not, then we need disks. This is the prose of life, in general.
The combat servers for which deduplication is not applicable, for which the RTO indicator is not so cruel, it is quite normal to back them up to robotic tape libraries, etc. There are backup sources for which the RTO is critical, they need to be able to quickly recover, this is required by the security policy and there are no deduplication contraindications for them - they bought Data Domain and told Networker some of the backup streams from these sources to send to such storage
And what about the third category of backup sources and the most numerous? - with jobs? And if they are connected to the repository unreliable communication channels? Then work intermittently, the bandwidth is weak, etc. It is useless, very inconvenient to backup them in the traditional way and with deduplication to the repositories. Here EMC says, ok, we have such a product - Avamar, which of course can be used independently - and for the protection of servers and it is suitable, and for the protection of anything. But its peculiarity is that it always performs compression on the source. First, straining the source, compressing, as far as possible, the data to be backed up, and then only in compressed form transmits a unique delta, a copy to some kind of storage. Avamar, in terms of integration, can work with all products of the family, can also work very effectively under the control of Networker.
Considering that it integrates everything with each other, all categories of backup sources can be protected - it is possible with technologies from a single supplier. Just left? - Correlation of events that occur in these complex software and hardware complexes, with events that occur on network equipment, storage, data storage systems, etc. In order to comply with what is called SLA, secondly in order to be able to organize billing. The idea is very simple - all of the above products, individually and collectively, are what is called cloud ready. This means that you can build a cloud backup service from them and rent it. I am an operator, I built my own data center servers, put these products in there and rent them to you as legal entities. In order for you to guarantee the level of quality of service and to invoice everyone, as you use my infrastructure you need billing. To organize this part, we need such a product - Data Protection Adviser (DPA), advisor. This is a separate software package whose clients are placed on all information sources, which has a centralized database, where all the information is collected, where it is semantically enlarged, checked against a certain database of signatures of some events. Well, then someone is sitting, looking at the monitor, and he is shown in red - everything is bad, or he is told, advice is given - what to do? And he either writes reports or bills his superiors - a great thing.
What does Data Domain consist of?
I have listed not all modules of a single modular product, since we do not have much time. But if there are those who want to show themselves RTO reduced to zero. There is a product Recover Point, which again integrates with everyone, in particular with Networker, which implement the concept of continuous protection.
In our course, the focus will be on a small part of this software and hardware complex - only Data Domain. But we will always talk about it in the light of integration with other products from the family, or from third-party manufacturers, which is also not a problem.
There are many experienced guys among you who have already worked with Data Domain competitors. If you try to determine what Data Domain is, then it may turn out like this: disk storage of deduplications for storing backup copies of archives. No more and no less. This is a very important point. This is not a storage system, comparing it with something like that makes no sense. Because it is a storage for storing working data, for which the load profile is, in general, as it were, universal: sequential reading, writing, and random reading and writing are possible there. There these serious indicators of iops, those who work with DSS knows about it. In DSS, whatever they are: weak, medium, high-end - all other things being equal, there is some kind of common architecture. Front-end, there is some kind of cache, backend, fault tolerance, multi-looping, and the like. Data Domain is not a storage system, never call it that way - it's a sin :)
Data Domain is a server. If I take this hardware, then I see a software and hardware complex, there is hardware, in the form of computer hardware, software in the form of system software, this is the OS, there is some kind of application software.
The hardware is what? Intel's chipset, as much memory as possible, a couple of power supplies, there is a PCI express bus, some slots, 4 network cards with gigabit interfaces and 2 copper with 10 gigabits are built into the motherboard. By default, there are already more than 1 redundant network interfaces for connecting to the external environment in order to receive control traffic, in order to receive backup streams and issue recovery streams. Already good. In the slots, we can plug in more network cards, depending on the models, the power may also be limited by the chipset. You can plug in the fiber channel host bace adapter, though for some money, I saw such an adapter 4x and 8 gigabit, 16gigabit someone saw? I saw that they were declared, like 40 Gigabit Ethernet, but as yet there are none, you can expect them.
What else is on the bus? There, by default, there is already a disk controller, SAS and more than one, there should be 2. On the bus which hang any disks, disk array. In the younger Data Domain models, this is right in the case of the server itself, which is mounted in a rack. How many winchesters are there? Minimum - 7, maximum - 15. If you have a more serious Data Domain model, you can add one or more disk shelves to the SAS controller bus. In the disk shelves are spinning, before it was miserable sata-hard drives, now it's NL SAS-hard drives. How does NL SAS differ from SAS?NL SAS is like a cheap SAS (a satin screw made through the SAS bus, the exchange rate was increased, but the screw architecture itself was left as it was). SAS, roughly speaking, this is the good old scsi. NL SAS is Sasovskiy Vinci, which, according to the results of the production, did not pass any cruel tests for performance, reliability, but have some acceptable level, so they are cheaper. Roughly speaking, Sasovskiy Vinci have a time between failures of the NL SAS. I'm not talking about performance, but about reliability. These winchesters, of which there are many, tens or hundreds, are naturally collected in some sort of raid arrays. (Each regiment is going to a separate raid array) it is also called a disk group (there are no iron controllers there, in fact this is a software raid, this is neither bad nor good, it just works that way,and in each shelf another hot spare disk). I saw that in the head a couple of disks are allocated for the OS. (Previously, this was not the case; now, in the older Data Domain models, 4 disks are used for this Data Domain OS. They are taken out separately, there are mixed raids). There useful data is not stored, there is only official.
If you recall the logic of building a raid 6 arrays. What is there overhead? One logical write operation of some data block is how many physical operations (I'm talking about iops)? 3 readings + 3 records. That is, overhead is wild! The 6th raid has the largest overhead, the 5th has less overhead: 2 reads + 2 entries. The disk system in this server is very slow, so we remember that we said that this is not storage.
OS is a kind of Linux-like OS, called DD OS (Data Domain Operating System). In general, for an ordinary customer, consumer, it is brought to an unrecognizable form - you are not there traditional shells. There is a simple command interpreter, with a system of commands with a simple syntax. And if you are not an engineer, but you do not have technical support service or engineering access, then forget about most of the unix-based commands and utilities you know. As an application, there will be a terminal of various daemons: Daemon VTL, Deamon DDBoost, Deamon NTP, Deamon NFS and so on. The set of which is built into this Linux distribution, in order to receive / send backup streams through a variety of these application-level protocols.
Why is Data Domain so expensive?
Well, then I ask why Data Domain is so expensive? What is so special about the parts that I cannot assemble from? We do not take into account marketing, etc., if we take into account the technical part - in one of the PCI slots there is one or several special cards, which are called NVRAM cards. Specialized card, with some amount of RAM in the chip, 1 gigabyte, 2, 4 gigabytes, with some, we will consider a specialized microprocessor. This is the board with which these streams of incoming backup archives are compressed using the central processor. The same board, where the same deduplication takes place. This is what allows older models of DD to “run down” dozens of terabytes of data per hour. Imagine 10 terabytes per hour of incoming traffic, and what should be the performance of the disk subsystem,collected from NL SASov in raid 6? Yes, there must be an insane amount of them!
But as in the older and younger Data Domain models, the disk subsystem is no different in performance. The total number of iops that it can produce is small. Absolutely inadequate to the set of functions that are required for such a volume of data. All these "hellish" terabytes are compressed at the input to an acceptable level, and only acceptable load reaches the disk subsystem. The deduplication technology, or rather its implementation in the Data Domain, is patented.
If you fly to California, Santa Clara, where this division is, it is now called Data Protection and Availability Division, formerly BRS, then there is a “hall of fame” in the hall, where all these patents and their copies hang. And this is an expensive pleasure. When you buy a Data Domain, you pay all these patents, to the patent owner, for his super-development, which is kept secret in a certain part, we will also talk about this later. I do not want to say that other vendors do not have similar technologies, but the price order is the same as for Data Domain. They all fight hard for the consumer. The main competitor is HP Storeonce and IBM Protectier.
That is, the Data Domain will look like this: a server, with or without shelves, connected via ethernet only, or both via ethernet and via fiberchannel, receiving backup streams through a variety of different protocols. It turns out that the main competitive advantage of this product is, in fact, deduplication.
Deduplication
You need to deal with this in order to go further. Roughly speaking, this is compression. What is the essence of compression - to reduce the amount of data. Only when they say “compression” in the general case, it means that we are looking for a repeating data sets and replace them with some kind of links, in some local data set. When we say "deduplication" - then we are talking about global compression, I am looking not only for repeating data on this source of backup copies, but in general everywhere, on all general backup sources.
Accordingly, we have deduplication at different levels of abstraction. What I am saying is not new, but it is necessary to speak in the same vocabulary.
1) Filebased. At the file level. You are all backing up some data on me, and I'm looking for some duplicate files. Some file came from someone, it turned out that he had never met me, he was unique - I put it in the repository. I spent some resources, a place in the storage, to place the body of this file there. Another copy of the same file came from someone, I somehow became convinced of this. And instead of wasting resources, I save the meta-information that such a file is found there and there. And the overhead will be 2 orders of magnitude less, instead of storing the file body in the storage.
How to check files? The simplest is bitwise reconciliation, it cannot be discounted, in certain cases it is more effective than calculating the reference characteristic, hashes, etc. Therefore, never miss it, I will tell about it a little later. Most backup systems use this approach: let's run this data set through some function, and no matter what size of the source data set, we will get some kind of hash, a reference characteristic of a fixed size. And within the framework of this mathematical dependence, we will have a definite guarantee that if one bit changes in the initial set, the result of the hashing will be completely different. I specifically raise this question, in the course materials you will not see this, to tell you the following: yes,The hashing function is directly related to symmetric cryptography, it is a separate class of mathematical functions. And for them the problem of collisions is urgent. The probability that different data sets will have the same hash is not zero. But it can be reduced to an acceptable minimum. And for those cases when these collisions happen by some compensating measures to guarantee that the integrity of the data will not be compromised. I specifically voiced it, because, in particular, in the Data Domain, the developers paid attention to this question, and provide a mathematical guarantee, proof that these collisions are not a problem, and they are dealt with by compensating means.But it can be reduced to an acceptable minimum. And for those cases when these collisions happen by some compensating measures to guarantee that the integrity of the data will not be compromised. I specifically voiced it, because, in particular, in the Data Domain, the developers paid attention to this question, and provide a mathematical guarantee, proof that these collisions are not a problem, and they are dealt with by compensating means.But it can be reduced to an acceptable minimum. And for those cases when these collisions happen by some compensating measures to guarantee that the integrity of the data will not be compromised. I specifically voiced it, because, in particular, in the Data Domain, the developers paid attention to this question, and provide a mathematical guarantee, proof that these collisions are not a problem, and they are dealt with by compensating means.and cope with them using compensating means.and cope with them using compensating means.
In this case, all unique data sets have unique hashes. If collisions occur, this can be neglected. This is proven, it is a patented technology, not from the ceiling it is taken. What algorithm, what to check or not to check - we do not know. I specifically repeat, the deduplication algorithm (it is large, if you draw a diagram - the room is not enough), this takes into account. And developers are talking about this.
This technology is so stupid, but God forbid if you can get a compression ratio of 1.5-2 times. This is an average figure, but to expect at least something here is extremely difficult. Even if you have some kind of file “garbage” as a backup source, there are many duplicate files.
2) If I have a compression ratio at the head, then let's search for not files, but data blocks of fixed length. Let's give all the data that we fall to crumb into fixed pieces, usually in kilobytes. For each piece we calculate the hash, and check with the hashes of those pieces whose bodies lie in our storage. There is a hit - ok, it is preserved, we will not save it, there is no hit - this is a piece unique, it's time to put it in the vault.
This approach is good than that the brain does not need much to include. But it works best for backup sources where the data is already structured. If the dataset where we are looking for changed blocks, it is already initially modified by fixed transactions, of a fixed size, then this is very convenient. On Monday there were only blocks, then on Tuesday the block changed so-and-so. When the backup tool crumbles this file into bits of fixed size on Tuesday, it strictly localizes the changes.
The compression ratios that can be achieved with this approach are already greater. On average, it can be 2-5 times. But here it is important that the source meets certain requirements, where the data is already structured and changes are made by fixed transactions of a certain size. Most often it is a DBMS. For such data are given good performance. And if unstructured winnigret? The algorithm will not be able to localize these changes, because everything is moving there.
3) Therefore, there is an deduplication algorithm for data blocks of varying size. The essence of this algorithm is to localize the changes. Even if the file has changed at the beginning or in the middle, the system will understand that it is only these blocks that have changed, and the rest have remained the same. Typically, such algorithms use data whose blocks vary 4k-32k. There is a guarantee that if the original data set has not changed, the result of its “kroshilov” will be the same. And he will be able to localize only the changed part of the data. All these algorithms of this kind are patented. They are all kept secret. In fact, these are all variations of what is called Bloom's filter- if you want to strain your mathematical apparatus. Therefore, part of the patents in Santa Clara, they are about it. On the patented implementation of the system of theorems. Someone really strained his brain.
Now, if we talk about deduplication at all, at what level of abstraction is it better to perform it? 1st, 2nd, 3rd way ... no, wrong, no "correct" answer. An approximate correct answer is: the ideal backup tool should be able to perform deduplication at all levels of abstraction, adjusting to the features of backup sources.
In simple terms: I have a file "trash", unstructured information backed up? Let me first quickly, without straining anyone: I will find duplicate files and throw them away, those that are unique - ok, I'll start to chop up. If this file is the database body, then I will crush it of a certain size into structured files, and if unstructured blocks, I will crush it into data blocks of varying size. Because you always have to find a compromise between the compression ratio and overhead, the load on this compression.
It is necessary to calculate these hashes, it is necessary to compare them, and this annoys someone, we haven’t yet specified whom. And the greater the load, the greater the rate of the backup window. We have to look for some kind of compromise. The better squeezed, the slower will be some kind of RTO, etc. Therefore, companies are looking for a compromise between these parameters. And I would very much like the backup tool, on the one hand, to tell him: you yourself intellectually understand what deduplication, at what level of abstraction, for what source to perform. On the other hand, say to him: here is such a framework for you.
For example, for this data - I need to compress it as much as possible, I for this it is important that when compressing it fit into the backup window, and for this the recovery time is important. And so, Networker in combination with Data Domain and Avamar represents such an intelligent backup system.
There was a question about Microsoft
In the Microsoft, in the OS, 2012 version in the case of the installation of the role of the file server there is an option that implements the deduplication of data blocks of varying length at the volume level. And there are coefficients of 1.5-2%. If we are talking about Avamar, then it performs deduplication at all 3 levels of abstraction, if about Data Domain, then it performs deduplication always at the 3rd level - data blocks of varying length. The hashing algorithm that is used — Industrial — Secure Hash Algoritm, and the reference characteristic size is 160 bits.
Go ahead.We have already visualized the architecture of a classic modern enterprise-class backup tool - client-based, multi-link. There are many sources - customers, there is some kind of data transfer medium that connects these sources with what is called a media server, storage nodes that are connected to the repositories. And there is some backup directory that conducts all of this.
So, in terms of deduplication. It can be performed by whom? Who is this hero? There is a postbased option. There is a terabyte of data, it was transferred through some kind of environment to the storage, into the allotted backup window, it ate up terabytes of data, for this it needs a lot of spindles, the terabyte was spent, and then, probably, outside the backup window this compression begins: files, fixed data blocks, etc. - but this is tense storage itself. And here it went down 10 times, there are 100 gigs. Good or bad - I do not say. For example, Windows Server 2012 does just that. VNX works similarly, but the latest models can do deduplication, not only at the level of file blocks, but also at the level of the moon - and it does this on its own schedule, and we save our expensive place.
There is deduplication on the go. A terabyte was read, transmitted through the transmission medium, there is no savings, but before getting into the disk storage subsystem, this terabyte is compressed using a processor, RAM, and we remove this insane number of iops, and get some adequate amount of them, which can be written to the disk subsystem. Do not need a lot of spindles, do not need a lot of space. Here we have it - Data Domain. It can do this through any software interfaces.
The third option.Deduplication at the source. I read the terabyte and immediately strained the source. He is already tense reading a large array of data, transferring them somewhere, and here they still need to be compressed. Here he gave it up to 100 gigs and already unfortunate 100 gigs passed over the data transfer system to the storage. Avamar and Data Domain can do this when using the DDboost interface with DCP functionality enabled. That is, the Data Domain knows what deduplication is at the source. The most interesting thing is that he knows and what is post-deduplication, the first type we talked about. Data Domain has a time when it understands itself, and this also implies postbased deduplication.
The set of threads that fall on the Data Domain, it crumbles them, into pieces of varying size, counts them into hashes, checks their arrays. But there is a mathematical guarantee that for 99% of these pieces, it can be understood whether they are unique or not. And for 1% he will not be able to do it in time. Consider that he will put these pieces somewhere in order to be in time, and then they will be able to do it after the fact. How and why this happens I will explain later. There is nothing wrong with that, no one declares it, but no one refuses it. The performance data for each Data Domain model posted on the EMC website is not pure marketing. They made a laboratory, a program of test methods, set up a live Data Domain, and began to backup something on it and achieved these results, measured them strictly. Clear,that under certain conditions, perhaps even ideal, but no one promises manna from heaven. Everyone says: do research, justify, prove to the customer that exactly this coefficient will be obtained, this absorption rate will be obtained in his situation - and then sell it.
What I have said is some kind of educational program for backup tools. education.emc.com- learning portal, you probably know about it, it's good to go there more often. There is an excellent Backup Recovery Systems and Architecture course that takes 40 hours. A course on the basics of backup and archiving, there is about this multi-tier, about serverless proxy backups, deduplication, there are a lot of things written. The course is actually a university one, it is taught in senior courses of technical universities, partners of the EMC academic program, masters are taught, as part of the second higher education. In the St. Petersburg Polytechnic, in Moscow universities, I read this course. The course itself is very interesting, I specifically speak about it, because it would be desirable for each of you to at least look through it and look at it. Because everyone has white spots in education. Being engaged in protection systems for more than 10 years, I thought that I had eaten a dog on this, that it was no surprise for me - but no.5 days - 40 hours, just about these basics.
Go ahead.On the EMC website in the data protection section, I look at the product range. Data protection means their integrity and availability in the first place. Not privacy! When it comes to all sorts of secrets, we go to RSASecurity. I have a dozen products here and in the backup recovery section I have the EMC Data Protection Suite - this is a single hardware and software system for protecting all categories of data.
I want to look at the Data Domain models and look at their characteristics. There are a lot of models for every taste and wallet. I want to see the weakest model - Data Domain DD160. It has 7 disks by default, or you can expand to 12. The architecture of all Data Domain models is the same, but those that are cheaper have certain limitations. For example, you will not add a shelf - the possibility of scaling is limited, you cannot install many network interfaces there, hostbased adapters. And here configuration maximum - 160 model is ready to totally absorb backup streams at speeds up to 1 terabyte / hour. How to interpret this indicator? Provided? That the stream goes through ethernet and DDboost, DCP is enabled, with deduplication at the source. If there is no DDboost, then you can safely divide by 2: incoming and outgoing. DDboost is already working a lot with anyoneeven HP Data Protector can work with it, Netbackup has known for a long time, Backup Exec has known for a long time - this is an industry standard, because it hasn’t been invented for other alternatives.
What is the 195 TB Logical capacity? How to interpret this? That is, before compression, almost 200 tb, and its capacity is 1.7. What is needed compression ratio? If roughly rounded - 20 times? I have customers who have: 3 times sorry - cool!
Contraindications
Why I pay attention to it - I say it again - it all depends on the data. When talking about deduplication I did not specifically mention contraindications. If, for example, my data is encrypted, initially presented in the form of a cryptogram, and I backup it. What we get compression ratios? Encryption algorithms and compression algorithms are from the same category of mathematical functions. They do about the same thing, but they have different goals. Some provide confidentiality, while others reduce their volume. All that is encrypted is contraindicated for compression, since after it the data will take even more space.
Well, if the data is compressed already. Media, anything. What ratios can you expect? It can be expected, but it all depends on the backup scheme. If I have a media archive with a capacity of 10 TB, which does not press, but every day I do a full backup, this is not an option - no one does.
Therefore, it is necessary to identify contraindications, where there are none - to conduct surveys. And calculate this achievable compression ratio. To some extent, it can be calculated empirically, look at the data, EMC has statistics and say: shake 5 times. From this one can make a start. Do you have SQL and Exchange, so many mailboxes of such and such size? There is a formula where you drive it in and get the result.
Everyone touched Backup System Sizer? He gives an approximate estimate. My customers are divided into 2 categories, some say: write us in detail on the documents, justify, technical justification, etc. And others say: we do not need anything from the documents, but are you personally responsible for what you promised? Ideally, of course, to be responsible for your words, you need to make sure for yourself that this compression ratio will turn out exactly.
Then it is better to do what integrators do not like to do very much: give the customer into trial operation at least a weak, even second-hand, Data Domain. Let it be there for some time, and we will in fact see what the coefficient is. And we will make a start of this, develop a technical and commercial proposal.
Documentation and training
What is it all about? Without the design phase - not enough. Someone must conduct a survey in the framework of some developed methodology, write a technical task for the protection system. Protection plan, position and categorization of information resources. Plan for job security, disaster recovery. All these documents should be. Someone has to evaluate, say, for example, that this category - deduplication is not needed there, it is possible here - but not to load the source, here it is possible, there is such a coefficient, here it is.
This job is done by the integrator, or partner, as EMC calls them. EMC has a special training program for architects, for those designs, for design engineers. Where all this is taught: survey and the preparation of technical documentation. EMC works at the planet level - everything is standardized for them. Engineer and in the United States and in Ukraine works on the same samples. Nothing to invent.
But not every customer asks for it. Therefore, if you are a customer, you should ask the integrator to request this package of documents. Not reference infu from the site, and descriptions of the technology of manufacture and maintenance of this product. If you work in the integrator - everything is there, just need to ask.
For the start-ups, those who produce the product according to the documentation, have their own training courses, we are at one of them. These are usually engineers from partners and from the EMC itself.
For custom owners, those who, after commissioning, work with and serve this, have their own courses - for admins, our course can also be called for admins.
All this is painted on the EMC learning portal. Even if you are a customer, there are a lot of things available to you. Personally, I can share examples of design documentation, because it is difficult to write them from scratch. Therefore, it is necessary to support the engineering intelligentsia, because the owners do not like to pay money for it, but this is necessary, because it is a separate activity.
Either you are sitting in the integrator and you are creating these sets of documents in a stream, or you are in a large customer and this is for you the first time. Even if you act as a representative of the customer and control the actions of the contractor, you need to understand what is required of him. Therefore, it is better to know what to do.
For all stages of the life cycle of an automated system in terms of its protection system - EMC has a training and certification program for all their products. Will you consider other courses - it is already necessary to look.
Administration of EMC Data Domain: introduction to the course
Introductory we dealt with the basics of system copying and archiving. We, in fact, quickly ran through the contents of a university course, or a 5-day course on the architecture of these systems. At the same time looked deduplication. Strictly positioned Data Domain in the EMC product range. They drew conclusions - what to expect from him and what should not be expected from him - what is most important.
From the name of our course it is obvious what we are going to talk about. If you look at our life cycle model, then we are talking about support, maintenance, already, in fact, a finished black box. Someone who: designed how it will be built into the existing or new environment, painted a set of design and operational documentation. Someone on this kit carried out the assembly, installation, commissioning of this product, at least in the general part and then it was transferred to the customer’s personnel along with the documentation. The customer administers, in a small, narrow degree, in some corridor, he carries out an additional adjustment. But the main task of this staff is monitoring. We check the current status of this box, with the reference, which was recorded at the stage of commissioning.
Trabshuting
If the current state does not match the reference state - we identify the cause, we eliminate the malfunction. And then it all goes through the cycle. Newly finalizing the TZ - version 2.0. Because something has changed, the risks have changed, life has changed. And according to this cycle, and develops a system of protection. A normal, mature company, this cycle is already the 5th or 7th time, not doing everything from scratch, but developing. This is true for any other products.
Our course is a specific project, there is a beginning, there is a result. And so I need to define the boundaries of this project: what are we going to talk about, what are we not going to talk about. We will not talk about design, as there are other courses about it. We will talk about start-up only in the part concerning the customer. There are separate courses for EMC engineers and integrating partners where it is written: how to assemble this Data Domain, mount it with a set of shelves in a rack, how to tag, connect all these connections, how to create raid arrays, how to fill in the OS image, how to implement engineering maintenance that is not free.
We, as customers, say that we have collected someone, assigned IP for the control interface, someone set the password for the built-in administrator account and gave us these access attributes. And we will add something in the framework of the available documentation. We have an emphasis on administration, in some part on the setting.
What course is clear. Target audience - I have already voiced, it is also clear: both the customers, and partners, and the guys from EMC. Everyone goes here because they need to approach everyone under the same educational standards. Entrance requirements - I have already voiced: this is a university course, it is there, where you can find it and what you can already do with it.
Since this course is a project, we remember that as a result of this small project, you should have some kind of understanding, theoretical knowledge, practical, very specific skills related to this product. This means that there must be a comprehensive understanding of deduplication: what it is, and how it is specifically implemented in a particular product. What a set of patented technologies is, not necessarily related to the deduplication implemented in the Data Domain, it is worth the money for you to see what these patents are.
How to monitor this black box, how to manage it, through what administrative interfaces you can connect to it and you can start to do something with it. Here is the command line and GUI. How to differentiate access to this product. Data Domain is a multiplayer appl, there are many people who should have access to it. Accordingly, it is necessary to distinguish between this access and control, it is impossible to allow someone to spoil something - this is expensive equipment.
How to perform an initial setup is when there is a ready black box that you configure for your structure. Based on the design documentation that someone has developed for you. An example of such documentation you have in the form of a training manual for the lab. The format you have for example is ideal for such documentation. If you want to develop such documents for your start-up engineers - do it in this form, you have a good example.
Identify and configure Data Domain data paths - through which interfaces are physical, logical, Data Domain can receive backup archive copies — there are a lot of them. Let's list them all, and for each of them we will write a setup procedure, we will carry out tests on the stand, so that this description corresponds to reality, so that there is some kind of evidence. We have a stand for this.
Configure and manage Data Domain network interfaces - configure the Data Domain network subsystem. The simplest model has an excessive amount of network interfaces built into the motherboard. This is good, because it is possible to ensure at a minimum - fault tolerance, the interfaces break, the wires break, and it works. And as a maximum - to aggregate its bandwidth, to summarize the interfaces to achieve some results.
It's one thing to initialize Data Domain, another thing is to start throwing some data at it through different interfaces. We will follow a simple logic: from simple to complex, from general to specific. At the beginning, we will touch simple interfaces that are easy to configure and do not require separate licenses. And then it will all be difficult to complicate. For example, take the Data Domain internal file system and start structuring. We will make a structured system from some large piece of data so that it is convenient to manage.
Recall that the Data Domain in the general case - a disaster-resistant product. When they wrote TZ to its developers, they gave the task so that the Data Domain could survive complete destruction. What does it mean? - in time to reset the replica of critical data backups to another Data Domain. True, this thing is licensed.
The issues of business continuity are very relevant, especially after 9/11. And people thought: what will happen if I have a fire or something?
Remember the RTO indicator - no matter what happens, just as much will be lost - no more, and no matter what happens, you can return everything back for so long.
There was a question about what, one of the reasons to use disk storage for backups is an improvement in the RTO, recovery time. For example, we did all the backups to tape libraries, now the security requirements have changed, now the data needs to be restored even faster, the libraries do not work, what to do? Let's replace the Data Domain library, which will look like a library on the front end, but with a better RTO. How to make one or more virtual robotic tape libraries out of one or two Data Domain? How to present them to existing backup tools so that they are minimally strained?
The most important thing to understand here is how to tune up the backup tools so that they write something to the virtual tape library correctly. Because to write in the old manner, as they are used to, physically, there is no longer worth it, due to the very same deduplication.
If you are not tied to libraries, if you do not have a task to replace the virtual physical library with a virtual one, buy a Data Domain with the licensed function DDboost. Since this is for the Data Domain native interface, which reveals all its features. This is the best way to use Data Domain. This means that backup tools know what DDboost is, in the worst case, at best, combat business applications that back up know it, this is the coolest.
In my opinion, the best-selling configuration is Networker with Data Domain via DDboost, they look very organic. But we understand that DDboost is an open interface. EMC says: let your backup tool be yours, but let them know what DDboost is and use our optimized interface to store backup copies. How to set it up - we'll see.
In our course, there will be a lab as a friend of Data Domain with Networker through DDboost, and a lab of friendship with Symantek netback through DDboost with a Data Domain. To demonstrate this flexibility Data Domain.
There will be a primer on the design of backup systems for the architects that we talked about. Some elements of the methodology for selecting the appropriate Data Domain model to the requirements of a particular customer, their range is large. We will understand that the work in this even prisile - not easy.
Who will be interested in further deepening the design issues - you know who to ask.
Here are our modules. From simple to complex, from general to specific. We have 10 modules, but we will also make the 11th optional module. Let's start with an introduction, the basics of administration, and the configuration of the network subsystem. Let's continue with simple, license-free interfaces - CIFS, NFS, which can drive backup and archiving traffic. And we will continue to complicate all this further. Moving to VTL and DDboost and to such a protection that is in the Data Domain, with which you can provide an acceptable level of information security. In accordance with the requirements of laws and regulators.
To determine the boundaries of our course, let us say once again that - this is a software and hardware complex. There is hardware, there is software. The hardware has its own identification system - three-digit models, for example, 160 are older, 4-digit ones are newer. And the software part is determined by the OS version - DD OS, the current DD OS version, which can be downloaded from the site - 5.5, and our course is still designed for 5.4. So the 11th module out of 10 will be about significant changes in 5.5. Each hardware hardware has its own software update limit.
In this part, while all.
Videotape
EMC courses at MUK TC
On July 6-9, the MUK TC center will have a course on Data Domain System Administration that this instructor will take - enroll in a course
And:
July 15-17 - VNX Block Storage Management
July 21-25 - EMC NetWorker Microsoft Applications Implementation and Management
Distribution of EMC solutions in Ukraine , Tajikistan , Belarus , Moldova , CIS countries .
MUK-Service - all types of IT repair: warranty, non-warranty repair, sale of spare parts, contract service
Source: https://habr.com/ru/post/260595/
All Articles