Oracle Database In-Memory
This article was prepared by Alexey Struchenko, the head of the department for optimizing the DBMS and applications of Jet Infosystems
Released in July 2014, Database In-Memory is the most anticipated and most discussed Oracle innovation in the Oracle Database product family. Over the past few months, Oracle employees regularly acquainted the Russian Oracle community with the features of the new option.
At Oracle Day 2014 in Moscow, I had the honor of supplementing the theoretical presentation by Igor Melnikov (Oracle) on Database In-Memory with a practical demonstration. It was not possible to show this demonstration in full - it was not so easy to connect the projector to a laptop connected to the demonstration base. Therefore, I decided to take advantage of the Habrahabr podium and still bring the essence of the Database In-Memory demonstration to the community.
So, there are two tables - PERSONS and CREDITS, - in which the number of fields is significantly different. The structure of the PERSONS table is given entirely, because There are only four fields in it (COUNTRY_ID - link to the country, SALARY - field for analytics):
')
There are twenty three fields in the CREDITS table, so we’ll only list a substantial part of its structure (COUNTRY is a country reference, CREDIT_LIMIT is a field for analytics):
The directory of countries is taken from the Internet, the PERSONS and CREDITS tables are randomly filled in so that their records refer only to European countries - the total number in the PERSONS and CREDITS tables is 21248349 records.
The role of analytic queries in the demonstration will be played by queries of the form:
Specifically, this query considers the amount of SALARY for all records of the PERSONS table that are associated with countries with the letter R - in Europe it is Russia and Romania. Moreover, both the fields involved in the query are folded in in-memory for both the PERSONS and CREDITS tables:
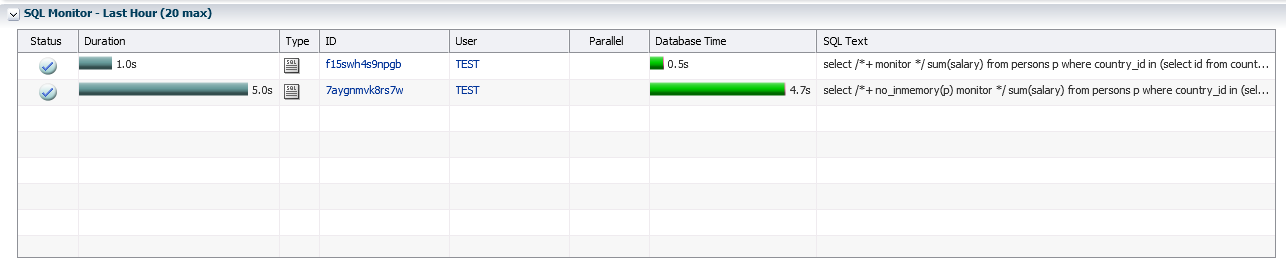
The result of an analytical query from the PERSONS table using Database In-Memory is FIVE times faster (the timings from SQL * Plus and SQL Monitor from Enterprise Manager are shown below):
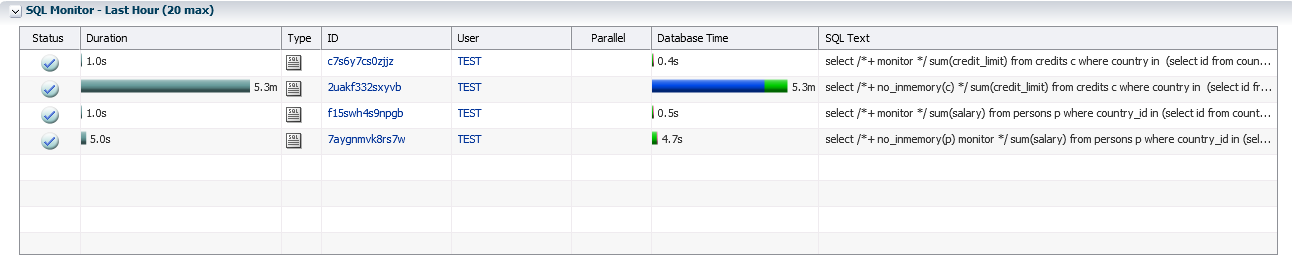
The result of executing such an analytical query from the CREDITS table using Database In-Memory turns out to be faster more than Seven times:
The PERSONS table has few fields, and it is deliberately placed in memory without using Database In-Memory. In the first experience, we compare the performance of Oracle Database with string (traditional buffer cache) and column (In-Memory) data storage in memory. The column method of storage in this experiment gives a gain of five times due to a number of mechanisms implemented in In-Memory.
There are many fields in the CREDITS table, and it either does not fit in memory, or Oracle itself refuses to put it in memory, for fear of "washing out" the cache. In the second experiment, we compare reading from memory and reading from disk, which is clearly seen in SQL Monitor (input-output is blue). Reading from memory is indeed hundreds of times faster, and the gain obtained in this experience is 700 times quite expected.
What is the conclusion? Database In-Memory really implements a beautiful science that can show query accelerations hundreds and thousands of times. But these must be special queries — for example, on such large tables that only a few fields needed for analytics are placed in memory.
And if, when testing In-Memory, requests from tables of the PERSONS type are used, the result may be different, which may lead to deceived expectations. In some ways, this post can be considered an instruction “How to and how not to demonstrate the operation of the Database In-Memory option”.
We welcome your constructive comments.
Released in July 2014, Database In-Memory is the most anticipated and most discussed Oracle innovation in the Oracle Database product family. Over the past few months, Oracle employees regularly acquainted the Russian Oracle community with the features of the new option.
At Oracle Day 2014 in Moscow, I had the honor of supplementing the theoretical presentation by Igor Melnikov (Oracle) on Database In-Memory with a practical demonstration. It was not possible to show this demonstration in full - it was not so easy to connect the projector to a laptop connected to the demonstration base. Therefore, I decided to take advantage of the Habrahabr podium and still bring the essence of the Database In-Memory demonstration to the community.
So, there are two tables - PERSONS and CREDITS, - in which the number of fields is significantly different. The structure of the PERSONS table is given entirely, because There are only four fields in it (COUNTRY_ID - link to the country, SALARY - field for analytics):
')
| ID | NOT NULL | NUMBER |
| COUNTRY_ID | NUMBER | |
| NAME | VARCHAR 2 (50) | |
| Salary | NUMBER |
There are twenty three fields in the CREDITS table, so we’ll only list a substantial part of its structure (COUNTRY is a country reference, CREDIT_LIMIT is a field for analytics):
| ID | NOT NULL | NUMBER |
| NAME | VARCHAR 2 (50) | |
| COUNTRY | NUMBER | |
| CREDIT_LIMIT | NUMBER |
The directory of countries is taken from the Internet, the PERSONS and CREDITS tables are randomly filled in so that their records refer only to European countries - the total number in the PERSONS and CREDITS tables is 21248349 records.
The role of analytic queries in the demonstration will be played by queries of the form:
SQL> select sum(salary) from persons where country_id in (select id from countries where name like 'R%'); Specifically, this query considers the amount of SALARY for all records of the PERSONS table that are associated with countries with the letter R - in Europe it is Russia and Romania. Moreover, both the fields involved in the query are folded in in-memory for both the PERSONS and CREDITS tables:
SQL> select table_name,COLUMN_NAME,INMEMORY_COMPRESSION from v$im_column_level where table_name in ('PERSONS','CREDITS'); | Persons | COUNTRY_ID | FOR QUERY HIGH |
| Persons | Salary | FOR QUERY HIGH |
| CREDITS | COUNTRY | FOR QUERY HIGH |
| CREDITS | CREDIT_LIMIT | FOR QUERY HIGH |
The result of an analytical query from the PERSONS table using Database In-Memory is FIVE times faster (the timings from SQL * Plus and SQL Monitor from Enterprise Manager are shown below):
SQL> select /*+ no_inmemory(p) monitor */ sum(salary) from persons p where country_id in (select id from countries where name like 'R%'); Elapsed: 00:00:04.68 SQL> select /*+ monitor */ sum(salary) from persons p where country_id in (select id from countries where name like 'R%'); Elapsed: 00:00:00.48 The result of executing such an analytical query from the CREDITS table using Database In-Memory turns out to be faster more than Seven times:
SQL> select /*+ no_inmemory(c) */ sum(credit_limit) from credits c where country in (select id from countries where name like 'R%'); Elapsed: 00:05:16.35 SQL> select /*+ monitor */ sum(credit_limit) from credits c where country in (select id from countries where name like 'R%'); Elapsed: 00:00:00.43 The PERSONS table has few fields, and it is deliberately placed in memory without using Database In-Memory. In the first experience, we compare the performance of Oracle Database with string (traditional buffer cache) and column (In-Memory) data storage in memory. The column method of storage in this experiment gives a gain of five times due to a number of mechanisms implemented in In-Memory.
There are many fields in the CREDITS table, and it either does not fit in memory, or Oracle itself refuses to put it in memory, for fear of "washing out" the cache. In the second experiment, we compare reading from memory and reading from disk, which is clearly seen in SQL Monitor (input-output is blue). Reading from memory is indeed hundreds of times faster, and the gain obtained in this experience is 700 times quite expected.
What is the conclusion? Database In-Memory really implements a beautiful science that can show query accelerations hundreds and thousands of times. But these must be special queries — for example, on such large tables that only a few fields needed for analytics are placed in memory.
And if, when testing In-Memory, requests from tables of the PERSONS type are used, the result may be different, which may lead to deceived expectations. In some ways, this post can be considered an instruction “How to and how not to demonstrate the operation of the Database In-Memory option”.
We welcome your constructive comments.
Source: https://habr.com/ru/post/260455/
All Articles