ECP and process management API
The technology of load sharing between multiple servers of relatively low power has been a standard feature of Caché DBMS for quite some time. It is based on the distributed cache protocol ECP (Enterprise Cache Protocol); what is meant here is “cache” (“cache”), and not “Caché” (“cache”). ECP opens up rich possibilities for horizontal scaling of the application system, providing high performance with equally high resilience to failures, while leaving the project budget in a fairly modest framework. The advantages of the ECP network will fairly include the possibility of hiding the features of its architecture in the depths of the DBMS configuration, so application programs originally developed for the traditional (vertical) architecture are usually easily transferred to the horizontal ECP environment. This lightness is so fascinating that I want it to be so forever. For example, everyone is accustomed to the ability to control not only the current, but also “alien” Caché processes: the $ Job system variable and the associated functions and classes in skillful hands allow “to work wonders”. Stop, but now the processes can appear on different Caché servers ... Below is how it was possible to achieve almost the same transparency in managing processes in the ECP environment as it was without it.
Before we delve into the topic, let us recall the basic concepts related to ECP.
ECP , or the distributed cache protocol, is the basis of the interaction between data servers and application servers. It runs on top of TCP / IP, which provides reliable packet transport. The ECP protocol is proprietary to InterSystems.
Data servers (SBDs), sometimes called ECP servers, are typical Caché installations that host local application databases. The verb “are” should not be taken literally: databases can be physically located, for example, on network storage systems accessible via iSCSI or FC; it is important that the DBMS considers them local.
Application servers (SPs), sometimes referred to as ECP clients, are typical Caché installations that run processes that serve users of an application system. In other words, application code is executed on the application servers (hence their name). Since these are typical Caché installations, they have a standard set of system local databases: CACHESYS, CACHELIB, CACHETEMP, etc. This is important, but not the main thing. More importantly, application databases that are local to data servers are mounted as remote databases on application servers. In general, the interaction scheme is shown in the figure.
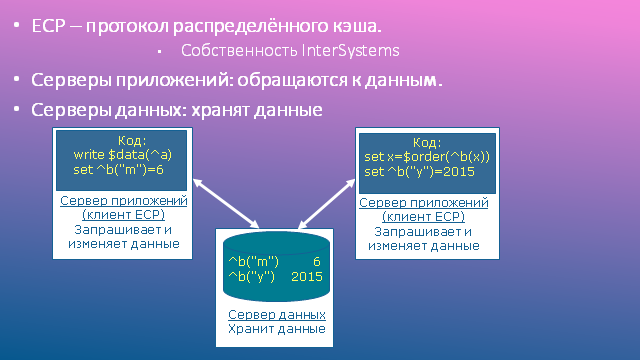
Main components of ECP
I hope, there is no need to explain what a data cache is. Distributed cache, appearing in the name of the ECP protocol, is in general nothing more than a metaphor: the cache, of course, is always local. But if the remote global node is read on the application server, the corresponding block is copied from the data server cache to the application server cache, so that repeated calls to the neighboring nodes of the same global will occur locally, without re-accessing the network and the data server. The longer the system is running, the more urgent is the filling of the local cache on the SP (as they say, the better it “warms up”), and the less often network access operations occur. Ideally, only modified data will require repeated readings from the data server; the illusion exists of the existence of a distributed (between servers) cache.
The recording is somewhat more complicated: the write request goes to the data server. The data server sends to the response the command “delete the block from the cache”, and only to those application servers that previously read the previous state of this block into their cache. It is important that the modified block itself is not forcibly sent, since perhaps it is no longer needed by anyone. If there is a need for it again, the block is re-requested from the data server and again gets into the local cache of the application server, as described earlier.
')
Commercial break: a little about the advantages of horizontal scaling by means of ECP. Imagine that you need to plan a system for 10,000 users, and it is known that for every 50 users, computing resources in the amount of 1 CPU core and 10 GB RAM are required. Compare alternatives. In the SBD & SP table, the traditional Caché server (data and application server “in one bottle”). For reasons of resilience to failures, they need to plan two.
In the scheme with horizontal scaling from the same considerations, we plan two data servers, but I think no one should be convinced of the price advantage of this scheme over the previous one ... As a bonus, we get the remarkable feature of sharing ECP and Mirroring: when switching data servers - nodes of the mirror pair - application server users experience only a brief pause in the work (measured in seconds), after which their sessions continue. In the vertical diagram, client processes are connected directly to the data server, so when switching servers, gaps in user sessions are inevitable.

Sharing ECP and "Mirror"
Recall that on each application server there are local databases, so the storage of intermediate data is naturally transferred to these databases. Such work can be quite intensive, which means that the involvement of a large number of even inexpensive disks can unload the central storage system (DSS), reducing the service time (await) of disk operations without using another expensive storage system for intermediate data.
“Normal programs work in areas, therefore, you don’t have to change the constructions of the form ^ |" ^^ c: \ intersystems \ cache \ mgr \ qmsperf "| QNaz to ^ |" ^ PERF ^ c: \ intersystems \ cache \ mgr \ qmsperf "| QNaz. All these particulars are hidden in the Caché configuration in the definitions of the remote data server and remote database. Even if you sometimes have to refer to globals of areas other than the current process area, the syntax of such references (^ | "qmsperf" | QNaz) remains the same.
The semantics of working with global data also practically does not change, just by working with local databases, we usually don’t think about it. I will list the main provisions:
• All operations are divided into synchronous (all reading functions: $ Get, $ Order, etc., as well as Lock and $ Increment) and asynchronous (data writing: Set, Kill, etc.). Further program execution does not require waiting for the completion of the asynchronous operation. For synchronous operations, this is not the case. In the case of ECP, they may require additional access to the data server if the data block is not in the local cache.
• Synchronous operations do not wait for the completion of asynchronous operations initiated by the same application server.
• The Lock command waits for the completion of the data recording started by the previous lock master.
• Timeout Lock does not guarantee that someone else owns the lock.
Here are some unusual moments:
• Lines longer than half the block size are not cached on application servers. In fact, this threshold is somewhat lower, for 8 KB-blocks - 3900 bytes. Such a decision was made by the developers in order not to fill the cache with BLOBs and CLOBs: it is known that such data is usually written once and subsequently rarely read. Unfortunately, this decision negatively affected the processing of bitmap indexes, which, as a rule, are also long strings. If you use them, you will have to either reduce the size of the chunk, or increase the size of the block; optimal choice can be made only on the basis of test results.
• Assignment
set i = $ Increment (^ a)
may be more expensive than its functionally close analogue:
lock + ^ a set ( i , ^ a) = ^ a + 1 lock - ^ a
The fact is that the $ Increment function is always performed on the data server, therefore, waiting for the completion of the round trip is inevitable, and the lock (lock) causes a similar effect only when it is requested by processes from different application servers.
• It is necessary to handle <NETWORK> errors. Such errors occur when the application server cannot restore the lost ECP connection during Time to Wait for recovery (by default, 1200 seconds). The correct way of processing is to roll back the started transaction and try again.
Refreshing the basic concepts of ECP, let's move on to the main topic of the article. Process management will be interpreted in a broad sense. The real needs of application programmers that we have to face, and the system tools that are available to meet them “right out of the box,” see below.
The answer to these “challenges” was the development of a process management API, implemented as a Util.Proc class.
To make it more interesting for you to read further, I will give a couple of simple code examples using the API.
• Display a list of processes with an indication of the area and username of the medical information system (MIS), marking the "*" own (current) process:
set cnt = 0
for {
set proc = ## class ( Util.Proc ). NextProc ( proc ,. Sc ) quit : proc = "" || ' sc // next process
write proc _ $ select ( ## class ( Util.Proc ). ProcIsMy ( proc ): "*" , 1: "" ) // mark ourselves with "*"
write "area:"
write ## class ( Util.Proc ). GetProcProp ( proc , "NameSpace" ) // process property: current area
write "user:"
write ## class ( Util.Proc ). GetProcVar ( proc , $ name ( qARM ( "User" ))) ,! // process variable: username MIS
set cnt = cnt +1
}
write "Total:" _ cnt _ "processes."
• Delete a process other than the current one if it is running under the same username of the MIS (to prevent users from re-entering):
if ' ## class ( Util.Proc ). ProcIsMy ( proc ),
## class ( Util.Proc ). GetProcVar ( proc , $ name ( qARM ( "User" ))) = $ name ( qARM ( "User" )) {
set res = ## class ( Util.Proc ). KillProc ( proc )
}
When developing the API, it was necessary to choose the way of addressing processes in the ECP network, and I wanted to get:
• uniqueness of the address in the local network,
• the ability to directly use the address with minimal conversion,
• easy to read format.
To address the server on the network, you can use its name (hostname) or IP address. The choice of a name as an identifier, although tempting, imposes additional requirements on the impeccability of the work of the name service. Since such requirements are usually not imposed when setting up a Caché configuration, I did not want to introduce new restrictions. In addition, in different operating systems, the hostname can have a different format, which makes it difficult to further analyze the process descriptor. Based on these considerations, I chose to use an IPv4 address.
To identify the Caché installation on the server, you can use its name (“CACHE”, “CACHEQMS”, etc.) or the port number of the superserver (1972, 56773, etc.). But you cannot connect to the Caché installation by its name, so we select the port.
As a result, as a descriptor (unique identifier) of the process, it was decided to use a string in the format of a decimal number: xx.yy.zz.uu.Port.PID, where
xx.yy.zz.uu - Caché server IPv4 address,
Port - tcp-port superserver Caché,
PID is the process number on the Caché server.
Examples of valid process descriptors:
192.168.11.19.56773.1760 - a process with PID = 1760 on a Caché installation with IP = 192.168.11.19 and Port = 56773.
192.168.11.77.1972.62801 - the process with PID = 62801 on a Caché installation with IP = 192.168.11.77 and Port = 1972.
As a result, the Util.Proc class was developed, the public methods of which are listed below. All methods are class methods (ClassMethod).
Comparing the summary of methods with the table Basic application needs for managing processes , we see that we have already succeeded in satisfying them in the network environment. The CCM () method was added later: in the process of transferring our application (regional medical information system qMS) to the ECP environment, it turned out that some functional blocks are more convenient and more efficient to execute directly on the data server. The reasons may be different:
• The desire to avoid a one-time transfer of a large amount of data to an application server, which is typical, for example, when generating a report.
• The need to centrally maintain a shared resource, for example, message queuing with another system (in our case, with HealthShare).
I note that most API methods are designed to work in the ECP environment. Without ECP, they are still efficient, but only accept / return little meaningful process descriptors of the type 127.0.0.1.Port.pid. Exceptions are the methods oriented to work with the data server: RunJob (), CheckJob (), CCM (), since they return / accept not the process descriptor (proc), but its number (pid) on the data server. Therefore, these methods are made universal from the point of view of the application programmer: their interface is the same both in the ECP environment and without it, although they work, of course, in different ways.
It was necessary to choose the method of interaction between processes running on different servers. The following alternatives were considered:
•% SYSTEM.Event class.
o Officially not working on the network, so support for its network operation may be terminated by InterSystems at any time.
• Own TCP server.
o Basically, a good idea.
o It is necessary to use an additional TCP port (except for the super-server port), which inevitably entails additional efforts to install and configure in addition to the standard Caché settings. And I wanted to do a minimum of settings.
• Web services.
•% Net.RemoteConnection class. For those who forgot: this class provides remote code execution on other servers using the same protocol as the clients of the% Service_Bindings service. If this service is already used in the system to connect clients, no additional settings are required, and this is our case. The overhead of data exchange is insignificant, as a rule, it is less than in the case of web services.
For these reasons, I chose% Net.RemoteConnection. Of its shortcomings, the most serious, in my opinion, is that it does not allow returning rows longer than 32KB, but this did not prevent much.
Another no less interesting problem faced was: how to determine if the code is working on the network or not? The answer to this question is needed both for the internal needs of the API (in order to correctly form the process descriptors) and for writing the IsECP () method, which is highly demanded by application programmers. The reason for this popularity is quite obvious: there were not very many people who wanted to rewrite parts of their code related to the interaction between processes on a kind of universal API (although this API was implemented). It was much easier and more natural to add a code branch for ECP. But how to determine in which environment the code works? Considered options:
1. The main database of the area is remote.
2. 1 or (the main database of the region is mounted by someone as remote). Minuses:
3. 1 or (one of the network interfaces connected to the data server application server).
I stopped at option 3, as it allows you to quickly get the desired answer to the question and correctly
populate process descriptors on both the application server and the data server. I note that to further speed up this test, its positive result for each server is recorded in the global.
The successful implementation of the process management API as part of the regional medical information system of the Krasnoyarsk Territory showed, if not perfect accuracy, then at least the viability of the chosen approaches. Using this API, our specialists managed to solve a number of important tasks. I will list only some of them:
• Elimination of duplicate user logins.
• Getting a network-wide list of working users.
• Messaging between users.
• Launch and control of background processes serving laboratory analyzers.
In conclusion, I would like to thank my colleagues from SP.ARM for helping to test the code, prompt reaction to the errors I noticed, and especially for correcting some of them. Part of the methods of the Util.Proc class (CCM (), RunJob (), CheckJob ()) could be made independent of our application software; they can be downloaded from the repository on the githaba or from the user database of the InterSystems code .
Yes, I am not an employee of InterSystems, but not without benefit and with pleasure I use the technologies of this company, which I wish also the patient reader who has read this far.
ECP terminology
Before we delve into the topic, let us recall the basic concepts related to ECP.
ECP , or the distributed cache protocol, is the basis of the interaction between data servers and application servers. It runs on top of TCP / IP, which provides reliable packet transport. The ECP protocol is proprietary to InterSystems.
Data servers (SBDs), sometimes called ECP servers, are typical Caché installations that host local application databases. The verb “are” should not be taken literally: databases can be physically located, for example, on network storage systems accessible via iSCSI or FC; it is important that the DBMS considers them local.
Application servers (SPs), sometimes referred to as ECP clients, are typical Caché installations that run processes that serve users of an application system. In other words, application code is executed on the application servers (hence their name). Since these are typical Caché installations, they have a standard set of system local databases: CACHESYS, CACHELIB, CACHETEMP, etc. This is important, but not the main thing. More importantly, application databases that are local to data servers are mounted as remote databases on application servers. In general, the interaction scheme is shown in the figure.
Main components of ECP
I hope, there is no need to explain what a data cache is. Distributed cache, appearing in the name of the ECP protocol, is in general nothing more than a metaphor: the cache, of course, is always local. But if the remote global node is read on the application server, the corresponding block is copied from the data server cache to the application server cache, so that repeated calls to the neighboring nodes of the same global will occur locally, without re-accessing the network and the data server. The longer the system is running, the more urgent is the filling of the local cache on the SP (as they say, the better it “warms up”), and the less often network access operations occur. Ideally, only modified data will require repeated readings from the data server; the illusion exists of the existence of a distributed (between servers) cache.
The recording is somewhat more complicated: the write request goes to the data server. The data server sends to the response the command “delete the block from the cache”, and only to those application servers that previously read the previous state of this block into their cache. It is important that the modified block itself is not forcibly sent, since perhaps it is no longer needed by anyone. If there is a need for it again, the block is re-requested from the data server and again gets into the local cache of the application server, as described earlier.
')
ECP in the eyes of the architect
Commercial break: a little about the advantages of horizontal scaling by means of ECP. Imagine that you need to plan a system for 10,000 users, and it is known that for every 50 users, computing resources in the amount of 1 CPU core and 10 GB RAM are required. Compare alternatives. In the SBD & SP table, the traditional Caché server (data and application server “in one bottle”). For reasons of resilience to failures, they need to plan two.
Vertical vs. horizontal scaling
| Vertical scaling | Horizontal scaling | ||
|---|---|---|---|
| Server options | Number of servers | Server options | Number of servers |
| 200 CPU cores, 2 TB RAM | 2 SBD & SP | 16 CPU cores, 160 GB RAM | 13 SP, 2 SBD |
In the scheme with horizontal scaling from the same considerations, we plan two data servers, but I think no one should be convinced of the price advantage of this scheme over the previous one ... As a bonus, we get the remarkable feature of sharing ECP and Mirroring: when switching data servers - nodes of the mirror pair - application server users experience only a brief pause in the work (measured in seconds), after which their sessions continue. In the vertical diagram, client processes are connected directly to the data server, so when switching servers, gaps in user sessions are inevitable.
Sharing ECP and "Mirror"
Recall that on each application server there are local databases, so the storage of intermediate data is naturally transferred to these databases. Such work can be quite intensive, which means that the involvement of a large number of even inexpensive disks can unload the central storage system (DSS), reducing the service time (await) of disk operations without using another expensive storage system for intermediate data.
ECP through the eyes of a programmer
“Normal programs work in areas, therefore, you don’t have to change the constructions of the form ^ |" ^^ c: \ intersystems \ cache \ mgr \ qmsperf "| QNaz to ^ |" ^ PERF ^ c: \ intersystems \ cache \ mgr \ qmsperf "| QNaz. All these particulars are hidden in the Caché configuration in the definitions of the remote data server and remote database. Even if you sometimes have to refer to globals of areas other than the current process area, the syntax of such references (^ | "qmsperf" | QNaz) remains the same.
The semantics of working with global data also practically does not change, just by working with local databases, we usually don’t think about it. I will list the main provisions:
• All operations are divided into synchronous (all reading functions: $ Get, $ Order, etc., as well as Lock and $ Increment) and asynchronous (data writing: Set, Kill, etc.). Further program execution does not require waiting for the completion of the asynchronous operation. For synchronous operations, this is not the case. In the case of ECP, they may require additional access to the data server if the data block is not in the local cache.
• Synchronous operations do not wait for the completion of asynchronous operations initiated by the same application server.
• The Lock command waits for the completion of the data recording started by the previous lock master.
• Timeout Lock does not guarantee that someone else owns the lock.
Here are some unusual moments:
• Lines longer than half the block size are not cached on application servers. In fact, this threshold is somewhat lower, for 8 KB-blocks - 3900 bytes. Such a decision was made by the developers in order not to fill the cache with BLOBs and CLOBs: it is known that such data is usually written once and subsequently rarely read. Unfortunately, this decision negatively affected the processing of bitmap indexes, which, as a rule, are also long strings. If you use them, you will have to either reduce the size of the chunk, or increase the size of the block; optimal choice can be made only on the basis of test results.
• Assignment
set i = $ Increment (^ a)
may be more expensive than its functionally close analogue:
lock + ^ a set ( i , ^ a) = ^ a + 1 lock - ^ a
The fact is that the $ Increment function is always performed on the data server, therefore, waiting for the completion of the round trip is inevitable, and the lock (lock) causes a similar effect only when it is requested by processes from different application servers.
• It is necessary to handle <NETWORK> errors. Such errors occur when the application server cannot restore the lost ECP connection during Time to Wait for recovery (by default, 1200 seconds). The correct way of processing is to roll back the started transaction and try again.
ECP and process management
Refreshing the basic concepts of ECP, let's move on to the main topic of the article. Process management will be interpreted in a broad sense. The real needs of application programmers that we have to face, and the system tools that are available to meet them “right out of the box,” see below.
Primary Application Requirements for Process Management
| Function | Without ECP | With ECP |
|---|---|---|
| Run background processes. | job $ job, $ zchild, $ zparent | The Job command works online, but without passing parameters. Process numbers are unique only within each server. |
| Tracking "liveliness" processes. | $ data (^ $ job (pid)) | There is no access to the process table of another server. |
| Getting a list of processes. | $ order (^ $ job (pid)) $ zjob (pid) | See above. |
| Access to the properties of other processes. | See above. | |
| Completion of another process. | Class SYS.Process | You cannot complete the process on another server. |
The answer to these “challenges” was the development of a process management API, implemented as a Util.Proc class.
To make it more interesting for you to read further, I will give a couple of simple code examples using the API.
API Util.Proc Examples
• Display a list of processes with an indication of the area and username of the medical information system (MIS), marking the "*" own (current) process:
set cnt = 0
for {
set proc = ## class ( Util.Proc ). NextProc ( proc ,. Sc ) quit : proc = "" || ' sc // next process
write proc _ $ select ( ## class ( Util.Proc ). ProcIsMy ( proc ): "*" , 1: "" ) // mark ourselves with "*"
write "area:"
write ## class ( Util.Proc ). GetProcProp ( proc , "NameSpace" ) // process property: current area
write "user:"
write ## class ( Util.Proc ). GetProcVar ( proc , $ name ( qARM ( "User" ))) ,! // process variable: username MIS
set cnt = cnt +1
}
write "Total:" _ cnt _ "processes."
• Delete a process other than the current one if it is running under the same username of the MIS (to prevent users from re-entering):
if ' ## class ( Util.Proc ). ProcIsMy ( proc ),
## class ( Util.Proc ). GetProcVar ( proc , $ name ( qARM ( "User" ))) = $ name ( qARM ( "User" )) {
set res = ## class ( Util.Proc ). KillProc ( proc )
}
Network addressing
When developing the API, it was necessary to choose the way of addressing processes in the ECP network, and I wanted to get:
• uniqueness of the address in the local network,
• the ability to directly use the address with minimal conversion,
• easy to read format.
To address the server on the network, you can use its name (hostname) or IP address. The choice of a name as an identifier, although tempting, imposes additional requirements on the impeccability of the work of the name service. Since such requirements are usually not imposed when setting up a Caché configuration, I did not want to introduce new restrictions. In addition, in different operating systems, the hostname can have a different format, which makes it difficult to further analyze the process descriptor. Based on these considerations, I chose to use an IPv4 address.
To identify the Caché installation on the server, you can use its name (“CACHE”, “CACHEQMS”, etc.) or the port number of the superserver (1972, 56773, etc.). But you cannot connect to the Caché installation by its name, so we select the port.
As a result, as a descriptor (unique identifier) of the process, it was decided to use a string in the format of a decimal number: xx.yy.zz.uu.Port.PID, where
xx.yy.zz.uu - Caché server IPv4 address,
Port - tcp-port superserver Caché,
PID is the process number on the Caché server.
Examples of valid process descriptors:
192.168.11.19.56773.1760 - a process with PID = 1760 on a Caché installation with IP = 192.168.11.19 and Port = 56773.
192.168.11.77.1972.62801 - the process with PID = 62801 on a Caché installation with IP = 192.168.11.77 and Port = 1972.
Methods of the Util.Proc class
As a result, the Util.Proc class was developed, the public methods of which are listed below. All methods are class methods (ClassMethod).
Summary of Process Management APIs
| Method | Function |
|---|---|
| IsECP () As% Bolean | ECP code is running or not. |
| NextProc (proc, ByRef sc As% Status) As% String | The next process is after the process with the proc descriptor. |
| DataProc (proc, ByRef sc As% Status) As% Integer | If ## class (Util.Proc) .DataProc (proc), a process with a proc handle exists. |
| Get the property named process Prop with the proc descriptor. You can poll the following properties (see class% SYS.ProcessQuery): Pid, ClientNodeName, UserName, ClientIPAddress, NameSpace, MemoryUsed, State, ClientExecutableName | |
| GetProcVar (proc, var, ByRef sc As% Status) As% String | Get the value of the var variable of the process with the proc descriptor. |
| KillProc (proc, ByRef sc As% Status) As% String | Complete the process with the proc descriptor. |
| RunJob (EntryRef, Argv ...) As% List | Start the process on the data server from the entry point EntryRef, passing it the required number of actual parameters (Argv). Returns $ lb (% Status, pid), where pid is the process number on the data server. |
| CheckJob (pid) As% List | Check whether the process with the pid number on the data server is “alive”. |
| CCM (ClassMethodName, Argv ...) As% String | Run an arbitrary method of class ClassMethodName (or $$ - function) on the data server, transferring the required number of actual parameters (Argv), and receiving the result of the execution. |
Comparing the summary of methods with the table Basic application needs for managing processes , we see that we have already succeeded in satisfying them in the network environment. The CCM () method was added later: in the process of transferring our application (regional medical information system qMS) to the ECP environment, it turned out that some functional blocks are more convenient and more efficient to execute directly on the data server. The reasons may be different:
• The desire to avoid a one-time transfer of a large amount of data to an application server, which is typical, for example, when generating a report.
• The need to centrally maintain a shared resource, for example, message queuing with another system (in our case, with HealthShare).
I note that most API methods are designed to work in the ECP environment. Without ECP, they are still efficient, but only accept / return little meaningful process descriptors of the type 127.0.0.1.Port.pid. Exceptions are the methods oriented to work with the data server: RunJob (), CheckJob (), CCM (), since they return / accept not the process descriptor (proc), but its number (pid) on the data server. Therefore, these methods are made universal from the point of view of the application programmer: their interface is the same both in the ECP environment and without it, although they work, of course, in different ways.
Little about implementation
It was necessary to choose the method of interaction between processes running on different servers. The following alternatives were considered:
•% SYSTEM.Event class.
o Officially not working on the network, so support for its network operation may be terminated by InterSystems at any time.
• Own TCP server.
o Basically, a good idea.
o It is necessary to use an additional TCP port (except for the super-server port), which inevitably entails additional efforts to install and configure in addition to the standard Caché settings. And I wanted to do a minimum of settings.
• Web services.
•% Net.RemoteConnection class. For those who forgot: this class provides remote code execution on other servers using the same protocol as the clients of the% Service_Bindings service. If this service is already used in the system to connect clients, no additional settings are required, and this is our case. The overhead of data exchange is insignificant, as a rule, it is less than in the case of web services.
For these reasons, I chose% Net.RemoteConnection. Of its shortcomings, the most serious, in my opinion, is that it does not allow returning rows longer than 32KB, but this did not prevent much.
Another no less interesting problem faced was: how to determine if the code is working on the network or not? The answer to this question is needed both for the internal needs of the API (in order to correctly form the process descriptors) and for writing the IsECP () method, which is highly demanded by application programmers. The reason for this popularity is quite obvious: there were not very many people who wanted to rewrite parts of their code related to the interaction between processes on a kind of universal API (although this API was implemented). It was much easier and more natural to add a code branch for ECP. But how to determine in which environment the code works? Considered options:
1. The main database of the area is remote.
- Pros: it is very simple, only:
- Cons: this is valid only on the application server and excludes network work on the data server.
2. 1 or (the main database of the region is mounted by someone as remote). Minuses:
- It is expensive.
- This is unreliable due to the dynamic nature of the ECP.
3. 1 or (one of the network interfaces connected to the data server application server).
I stopped at option 3, as it allows you to quickly get the desired answer to the question and correctly
populate process descriptors on both the application server and the data server. I note that to further speed up this test, its positive result for each server is recorded in the global.
Some conclusions
The successful implementation of the process management API as part of the regional medical information system of the Krasnoyarsk Territory showed, if not perfect accuracy, then at least the viability of the chosen approaches. Using this API, our specialists managed to solve a number of important tasks. I will list only some of them:
• Elimination of duplicate user logins.
• Getting a network-wide list of working users.
• Messaging between users.
• Launch and control of background processes serving laboratory analyzers.
In conclusion, I would like to thank my colleagues from SP.ARM for helping to test the code, prompt reaction to the errors I noticed, and especially for correcting some of them. Part of the methods of the Util.Proc class (CCM (), RunJob (), CheckJob ()) could be made independent of our application software; they can be downloaded from the repository on the githaba or from the user database of the InterSystems code .
Yes, I am not an employee of InterSystems, but not without benefit and with pleasure I use the technologies of this company, which I wish also the patient reader who has read this far.
Source: https://habr.com/ru/post/260419/
All Articles