Complete CROC cloud translation to Violin Memory's All-Flash data storage.
We at KROK launched one of the first public cloud platform in Russia at the end of 2009. We needed to grow exponentially from year to year. To provide this dynamic, the cloud platform architecture had to be extremely flexible and scalable, and the platform itself was well managed. At some point, we began to rest on the architectural constraints laid down at the dawn of cloud development, namely, the data storage subsystem.
')
One of the most important tasks of growth is to meet the needs of customers not only in terms of volumes of disk capacity, but also in terms of guaranteed performance of used disks. It was necessary to avoid the mutual influence of storage system neighbors, to make the situation completely manageable, to give guarantees on disk performance within the framework of SLAs ranging from 400 IOPS to 100,000 IOPS per disk.
On top of that, the topic with guaranteed disks in the cloud was also warmed up by the law on personal data, which comes into force on September 1, 2015. Many customers placed and placed their IT services abroad, often on dedicated physical high-performance equipment in the data center providers. The data now needs to be transferred to the territory of Russia, but customers don’t want to or simply don’t want to give up the high guaranteed disk performance, and there is no longer a chance to wait for the delivery of equipment to the Russian Federation. The cloud in this case is, perhaps, one and, possibly, the only way to manage to transfer data to the Russian Federation and to obtain similar technical parameters of performance, as on the provider’s physical equipment previously used.
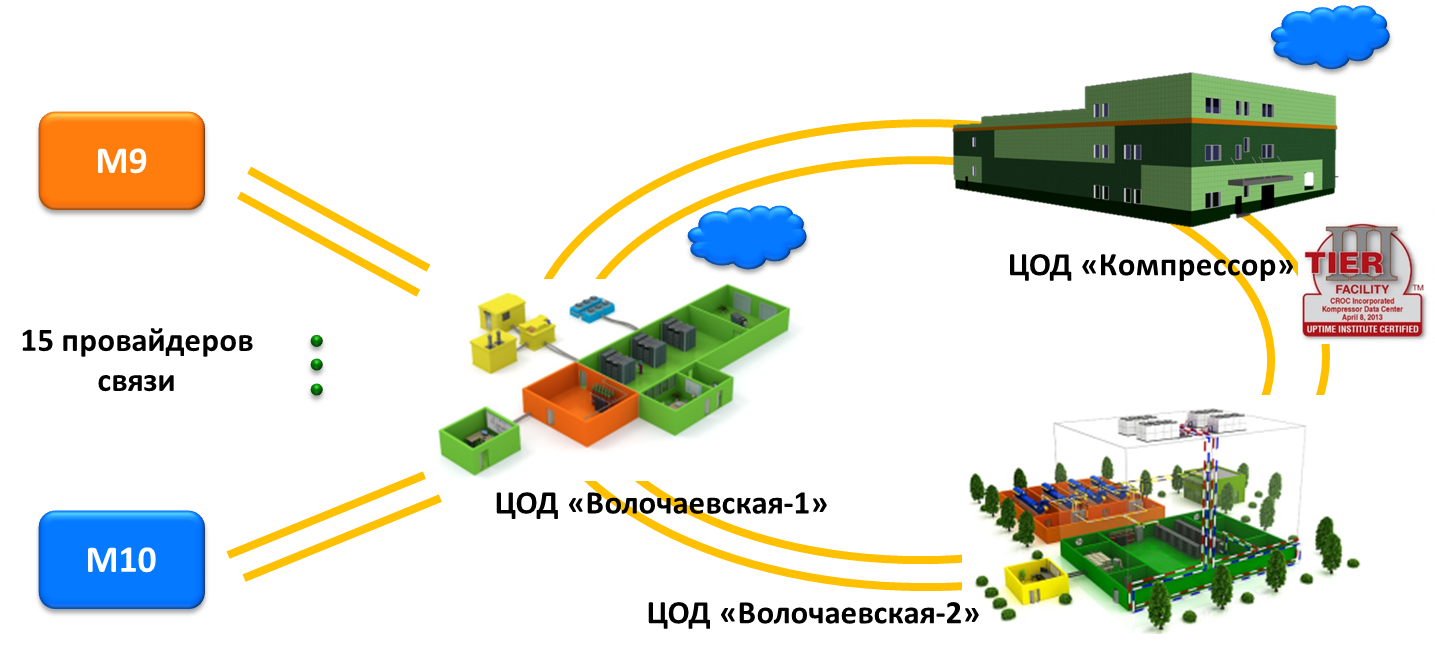
CROC cloud now has more than 500 physical servers and 12 data warehouses distributed between two remote sites. About 70% of the virtual servers located in the cloud are productive environments of large corporate clients and medium-sized companies. Test environments and development environments total about 30%. We have a number of fairly heavy installations of Oracle, SAP and various high-loaded OLAP-systems of customers.
Classic disk arrays have a historically established architectural feature, which is most clearly manifested from the negative side when using them as centralized repositories as part of a public cloud platform. On the basis of classic disk arrays with disk shelves and a controller pair, we started and lived until recently. On storage facilities of this type there were practically no intelligible mechanisms for managing the quality of service provision. Classic disk storage systems, as a rule, only allow you to create priorities for output performance on certain virtual disks. When the number of such disks on each of the arrays reaches hundreds and thousands, you can forget about setting any priorities. Such performance management mechanisms on storage systems not only did not work, but simply worsened an already complicated situation with a lack of performance and controllability.
The second major architectural problem was the tight binding of the parameters of capacity and performance of disk arrays. Simply put, there are 8 physical disks of 150 GB each with a rotation speed of 15k. We want to collect from them RAID10. The effective capacity of the logical drive will turn out to be 600 GB. By itself, each disk separately issues up to 150 IOPS, which means that the logical disk will generate about 1000 IOPS. As a result, we get the situation: for every TB of effective disk capacity, there are about 1,500 IOPS of performance.
Now let's look at the most common tasks for customers: we want to place a 2 TB database in the cloud and get a performance of 10,000–50,000 IOPS. So, in order to get such performance, you need to take a lot more disk capacity than you actually need (10–50 TB). You can object to me that there is a controller pair with a cache on the arrays and that you can add a shelf with solid-state disks, etc. The cache of controllers on random read / write will not improve the situation much. Solid state drives only partly save the situation with performance, and the solution to the problem with controllability only pushes it into the future. In addition, the classic controller cannot reveal all the performance of an SSD.
The situation with disk performance in the KROK cloud became critical, customers began to complain about unpredictable subsidence in disk subsystem performance. It was necessary to make a decision on the further development of the cloud. Considered various solutions, including the transition to High-End arrays. But we realized that this was not a solution to the problem, but simply an expensive “crutch” that would allow us to live for another couple of years until we come to a similar situation. I already wrote about the “uncontrollability” of such decisions above. Also, Hi-End arrays are not designed for very frequent creation and deletion of disk moons - these operations take a lot of time and turn into long queues from requests that are not suitable for working in the cloud. In general, the task was not taken with little blood, and we were forced to start everything from scratch, to conduct a local revolution in the part of data storage in the cloud.
From a clean slate - so from a blank slate. We decided to build on the needs of customers. What do the customers want?
- Drives with guaranteed performance without the possibility of mutual influence of neighbors in an array on each other. Warranties must be recorded in an SLA or contract.
- Transparent increase and decrease the performance of disk resources on the fly with changes in tariffs for the use of different disks.
- The ability to place high-load databases in the cloud (20 000–100 000 IOPS per disk).
- Provision of capacities on the territory of the Russian Federation (delays and political factors). The law on the transfer of personal data in the Russian Federation until September 1, 2015 only spurred.
- High availability data storage.
We have long been looking towards the use of All-Flash arrays. It so happened that it was on the basis of this class of solutions that our cloud storage problem was solved most beautifully, and that the most interesting thing was financially justified. We tested almost all the enterprise-level solutions available on the market, and also worked with the most visible startups. When choosing a solution, the main criteria were:
- All-Flash - high performance and no dependence of disk capacity on the number of IOPS.
- IOPS'ov should be so many that, firstly, enough for all, and secondly, to be able to guarantee their selection at any time.
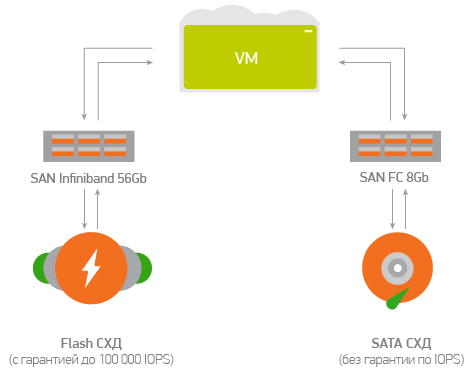
- Arrays must have Infiniband adapters to connect to an existing SAN. The fact is that as a SAN network and transport for virtual networks of customers in a cloud platform, we use 56GB Infiniband. Connecting arrays using the same technology would help preserve the monotony of the SAN and would simplify the management of the platform as a whole. It would not be necessary to build complex factories in setting up and operating, as in the case of FC SAN, since when using Infiniband all these questions are already automatically closed.
- Documented and understandable means of managing arrays through the API. This requirement would help to approach the problem of controllability.
We stopped in the end on the arrays of Violin Memory 6264. They fully met our requirements. As a result, a total of 8 purchased arrays received 0.56 PB of raw / 0.32 PB of usable flash capacity with a total capacity of 8,000,000 IOPS.
Performance guarantees are implemented by setting limits at the hypervisor level on each disk separately. The array management software automatically determines the current utilization of each of them and selects the least busy arrays for placing new disks. The array is quite compact. Just think: 1,000,000 IOPS in just 3 units!
It was a safe choice, given that Violin Memory created the All-Flash market in 2007 and advanced further into improving the product. The company developed the system from scratch with Toshiba - the inventor of NAND-Flash - and holds key patents for working with flash. There are no SAS loops, batteries and other archaisms inherited from disk systems in the array, without compromises in the form of SSD. Instead, the modern FFA architecture on the PCI bus uses native VIMM 1.1TB storage media. The output is a nominal response time of 250 µs, 7-digit IOPS, dozens of TBs in 3 units. According to the manufacturer, it’s impossible to catch up with Violin Memory: what’s needed is not a reworking of an existing product, but years of development from scratch and access to undocumented NAND-Flash functions.
We admit honestly: during migration not everything went smoothly, and we faced integration problems of our cloud and arrays. Their essence was that we could realize the potential of arrays by about 10% of their capabilities, namely, we rested against the maximum number of created disks on one array. In the CROC cloud, we use Infiniband both for storage area network and for communication between virtual machines. Violin Memory arrays use SRP (SCSI over RDMA) to connect LUNs to Infiniband servers. This protocol has the following feature: control commands use the subnet manager of the Infiniband network. In a normal situation, when the number of LUNs and servers is not very large, as well as the connections between them, this is not a problem. But not in the case of the cloud. Due to the fact that there are a lot of connections, that is, paths between servers and LUNs, the subnet managers of the Inifiniband network went off when rebuilding the network topology. Just not enough processor power. A large number of paths also created difficulties on the storage access controllers - they started to work very slowly, causing errors in the drivers, who believed that the path had fallen off.
How did we solve the problem? Together with the vendor, we did a great job of optimizing the number of paths: we began to connect each individual LUN, that is, export it, to a separate physical server. The difficulty was that it had to be done using the ReST API array, which was also not easy. If LUN is exported to all hosts and to one more specific host, then it is exported from that particular LUN. This requires performing a live migration of all LUNs in order to eventually get rid of the export to all hosts. Since each time the server was turned on / off, a new request for the array API passed, we increased the performance requirements of this API. Here, we could not do without a vendor. It was necessary to initiate the release of new firmware versions for the equipment.
For our part, three programmers and three DEVOPSs have been engaged in solving this issue for more than six months. We wrote a huge number of tests (unit-tests) for our program code, optimized the system of automated assembly and testing. This task was handled by the rest of the team. As a result, we have added thousands of lines of tested software code. It may seem as if the optimization of the number of paths is a simple task, but in reality there is nothing simple in it: we needed serious effort and more than ten months to complete it.

VIMM (Violin Intelligent Memory Module) - flash media, the main component of All Flash system
So, the range of available disk performance that can be created on arrays is up to 100,000 IOPS per disk. Moreover, this performance is guaranteed, but not floating, as is customary in the market for public cloud platforms.
We provide customers with default disks with the following performance: 400, 1000, 3000, 5000, 10000 IOPS, respectively. Customers through the self-service portal have the ability to run disks of different performance, as well as change the parameters of their number of IOPS on the fly. And disks with a capacity from 10,000 IOPS to 100,000 IOPS are added to the self-service portal upon request to the technical support service. As a rule, these are individual storage levels, the parameters of which are determined for each customer individually based on the results of load testing. We do not hide them, just really, not everyone needs such high-performance storage levels. We do not mind, because the average number of IOPS per 1TB of capacity in our cloud is 25,000. This is really a fantastic indicator.
The arrays are distributed between two CROC cloud platforms in distributed data centers on the territory of Moscow: in one 5 storages, in the other - 3. This allows customers to build Disaster recovery solutions using high-loaded systems both on one site and on the other. Moreover, the management of arrays at both sites is carried out through a single self-service portal.
Many may notice: "But other communication providers say that they also have guaranteed channels, and how it comes to SLA, they lower their eyes." So, CROC has a completely separate SLA on disk performance, in addition to the standard SLA on the availability of virtual servers. I will give below a short excerpt from it, namely the determination of the inaccessibility of the performance of guaranteed disks. "The inaccessibility of flash disk performance - the state of the flash disk when within five minutes the processor of the virtual machine to which it is connected expects data from the disk subsystem more than 10% of the time, or the delay in receiving data from the disk subsystem is more than 5 ms and the number of requests IOPS on a flash disk is less than the declared performance of a flash disk by 3%. "
Under the stated flash disk performance, here we mean just standard storage levels of 400, 1000, 3000, 5000, 10000 IOPS, respectively, or individual storage levels from 10,000 IOPS to 100,000 IOPS. As soon as we take off for the declared performance parameters, inaccessible minutes begin to drip. As soon as we take off for SLA 99.9, we immediately fall into fines. So we drive ourselves into a situation where working badly is not at all in our interests.
What to do if guaranteed disk performance is not needed, and you just need to store a large amount of data at reasonable prices? The cloud also has SATA data storage, where you can place the least hot data at optimized rates. And migration between different types of repositories is done on the fly.
By the way, I can add from myself that the service was so demanded and timely that we sold our eight flash arrays for 60% in 4 months and just ordered eight more of the same. This will be the first cloud in Russia with> 1 PB of correct flush. So we will be ready to accept a new stream of customers, which will rush towards the middle and end of summer on the eve of the Day of Knowledge about Personal Data. Many customers, by the way, have already moved to us without too much difficulty. Especially convenient for those who used to use the power of Amazon - we have a similar architecture, compatible API and a close approach to building a public cloud.
If you have questions on the organization of disk resources for loaded IT systems in the Russian Federation, I am ready to answer in the comments or in detail with the miscalculation of your task by mail: MBerezin@croc.ru
References:
- Server insurance company refactoring - when there is less physical space than data
- Violin overview - flash storage with speeds close to DRAM
Source: https://habr.com/ru/post/260387/
All Articles