Examples of using MongoDB in e-commerce (part 2)

[ First part ]
This post will be something that does not fit in the first part. These are some operators that are in the
aggregation framework and a rather loose translation of three articles from the ecosystem section of the site with help to MongoDB , describing some use cases for Internet commerce.')
The use cases are divided there into eight articles, which can be divided into three groups. It seemed to me the most interesting for translation are three materials related to
e-commerce .Operators in the aggregation framework
As a rule, in the
aggregation framework there are basic operators, such as $project or $group from which the pipeline chains are formed.But there are also such operators as
$cond , which are always located inside the main operators.$ cond approximate analogue of the usual if
It appeared from version
2.6 and it has two forms of writing: { $cond: { if: <boolean-expression>, then: <true-case>, else: <false-case-> } } { $cond: [ <boolean-expression>, <true-case>, <false-case> ] } An example is the following documents:
{ "_id" : 1, "item" : "abc1", qty: 300 } { "_id" : 2, "item" : "abc2", qty: 200 } { "_id" : 3, "item" : "xyz1", qty: 250 } Set
discount to 30 if the qty field is greater than or equal to 250 , otherwise the discount will be equal to 20 db.test.aggregate( [ { $project:{ item: 1, discount: { $cond: { if: { $gte: [ "$qty", 250 ] }, then: 30, else: 20 } } } } ] ) The result:
{ "_id" : 1, "item" : "abc1", "discount" : 30 } { "_id" : 2, "item" : "abc2", "discount" : 20 } { "_id" : 3, "item" : "xyz1", "discount" : 30 } $ ifNull checks that the field exists and is not null
If there is no field, it replaces it with the desired value
{ "_id" : 1, "item" : "abc1", description: "product 1", qty: 300 } { "_id" : 2, "item" : "abc2", description: null, qty: 200 } { "_id" : 3, "item" : "xyz1", qty: 250 } Returns Unspecified if the description field does not exist or is null . db.test.aggregate( [ { $project: { item: 1, description: { $ifNull: [ "$description", "Unspecified" ]}} } ] ) Result: { "_id" : 1, "item" : "abc1", "description" : "product 1" } { "_id" : 2, "item" : "abc2", "description" : "Unspecified" } { "_id" : 3, "item" : "xyz1", "description" : "Unspecified" } $ let creates variables
The
$let operator can create variables and then perform some operations with them.In the example, we create two variables,
total assign the value of the sum of two price, tax fields. And variable discounted result, which returns a logical operator cond .After that we multiply the variables
total and discounted and return their product. { _id: 1, price: 10, tax: 0.50, applyDiscount: true } { _id: 2, price: 10, tax: 0.25, applyDiscount: false } db.test.aggregate( [ { $project: { finalTotal: { $let: { vars: { total: { $add: [ '$price', '$tax' ] }, discounted: { $cond: { if: '$applyDiscount', then: 0.9, else: 1 } } }, in: { $multiply: [ "$$total", "$$discounted" ] } } } } }] ) { "_id" : 1, "finalTotal" : 9.450000000000001 } { "_id" : 2, "finalTotal" : 10.25 } $ map applies a specific expression to each element.
Applies any expression to each element, in this example, each element of the array is added
+2 . { _id: 1, quizzes: [ 5, 6, 7 ] } { _id: 2, quizzes: [ ] } db.grades.aggregate([{ $project:{ adjustedGrades: {$map: {input: "$quizzes", as: "grade", in: { $add: [ "$$grade", 2 ] } } } } }]) { "_id" : 1, "adjustedGrades" : [ 7, 8, 9 ] } { "_id" : 2, "adjustedGrades" : [ ] } $ setEquals compares arrays
Compares two or more arrays and returns
true if they have similar elements.| Example | Result |
| {$ setEquals: [["a", "b", "a"], ["b", "a"]]} | true |
| {$ setEquals: [["a", "b"], [["a", "b"]]]} | false |
$ setIntersection returns matched items
It takes two or more arrays and returns an array containing the elements that are present in each of the input arrays. If one of the arrays is empty or contains nested arrays, then returns an empty array.
| Example | Result |
| {$ setIntersection: [["a", "b", "a"], ["b", "a"]]} | ["B", "a"] |
| {$ setIntersection: [["a", "b"], [["a", "b"]]]} | [] |
$ setUnion returns the elements present in any of the input parameters.
Accepts two or more arrays and returns an array containing the elements that appear in any input array.
| Example | Result |
| {$ setUnion: [["a", "b", "a"], ["b", "a"]]} | ["B", "a"] |
| {$ setUnion: [["a", "b"], [["a", "b"]]]} | [["A", "b"], "b", "a"] |
$ setDifference is also setUnion but vice versa
| Example | Result |
| {$ setDifference: [["a", "b", "a"], ["b", "a"]]} | [] |
| {$ setDifference: [["a", "b"], [["a", "b"]]]} | ["A", "b"] |
$ setIsSubset checks for a subset
Takes two arrays and returns True if the first array is a subset of the second, including when the first array is equal to the second, and false if vice versa.
| Example | Result |
| {$ setIsSubset: [["a", "b", "a"], ["b", "a"]]} | true |
| {$ setIsSubset: [["a", "b"], [["a", "b"]]]} | false |
$ anyElementTrue
Evaluates an array as a set of elements and returns True if any of the elements is True and false if vice versa. An empty array returns false. Takes one argument.
| Example | Result |
| {$ anyElementTrue: [[true, false]]} | |
| {$ anyElementTrue: [[[false]]]} | |
| {$ anyElementTrue: [[null, false, 0]]} | |
| {$ anyElementTrue: [[]]} |
$ allElementsTrue
Checks an array and returns True if not one element of the array is false. Otherwise, returns false. An empty array returns true.
| Example | Result |
| {$ allElementsTrue: [[true, 1, "someString"]]} | |
| {$ allElementsTrue: [[[false]]]} | |
| {$ allElementsTrue: [[]]} | |
| {$ allElementsTrue: [[null, false, 0]]} |
$ cmp - compares two items
Compares two items and returns:
- -1 if the first value is less than the second.
- 1 if the first value is greater than the second.
- 0 if both values are equal.
{ "_id" : 1, "item" : "abc1", description: "product 1", qty: 300 } { "_id" : 2, "item" : "abc2", description: "product 2", qty: 200 } { "_id" : 3, "item" : "xyz1", description: "product 3", qty: 250 } Using
$cmp compare the value of the qty field with 250 : db.test.aggregate( [ { $project:{ _id: 0, item: 1,qty: 1, cmpTo250: { $cmp: [ "$qty", 250 ] } } } ] ) Result:
{ "item" : "abc1", "qty" : 300, "cmpTo250" : 1 } { "item" : "abc2", "qty" : 200, "cmpTo250" : -1 } { "item" : "xyz1", "qty" : 250, "cmpTo250" : 0 } $ add adds
{ "_id" : 1, "item" : "abc", "price" : 10, "fee" : 2 } { "_id" : 2, "item" : "jkl", "price" : 20, "fee" : 1 } db.test.aggregate([ { $project: { item: 1, total: { $add: [ "$price", "$fee" ] } } } ]) { "_id" : 1, "item" : "abc", "total" : 12 } { "_id" : 2, "item" : "jkl", "total" : 21 } $ subtract deducts
It can return the difference of dates in milliseconds.
{ "_id" : 1, "item" : "abc", "price" : 10, "fee" : 2, "discount" : 5 } { "_id" : 2, "item" : "jkl", "price" : 20, "fee" : 1, "discount" : 2 } db.test.aggregate( [ { $project: { item: 1, total: { $subtract: [ { $add: [ "$price", "$fee" ] }, "$discount" ] } } } ] ) { "_id" : 1, "item" : "abc", "total" : 7 } { "_id" : 2, "item" : "jkl", "total" : 19 } $ multiply multiplies
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity": 2 } { "_id" : 2, "item" : "jkl", "price" : 20, "quantity": 1 } db.test.aggregate([ { $project: { item: 1, total: { $multiply: [ "$price", "$quantity" ] } } } ]) { "_id" : 1, "item" : "abc", "total" : 20 } { "_id" : 2, "item" : "jkl", "total" : 20 } $ divide division operator
{ "_id" : 1, "name" : "A", "hours" : 80, "resources" : 7 }, { "_id" : 2, "name" : "B", "hours" : 40, "resources" : 4 } db.test.aggregate([ { $project: { name: 1, workdays: { $divide: [ "$hours", 8 ] } } } ]) { "_id" : 1, "name" : "A", "workdays" : 10 } { "_id" : 2, "name" : "B", "workdays" : 5 } $ concat - string concatenation
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "product 1" } db.test.aggregate([ { $project: { itemDescription: { $concat: [ "$item", " - ", "$description" ] } } } ]) { "_id" : 1, "itemDescription" : "ABC1 - product 1" } $ substr returns a substring
Gets the index of the beginning and the number of characters from the beginning. The index starts from scratch.
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "product 1" } { "_id" : 2, "item" : "ABC2", quarter: "13Q4", "description" : "product 2" } db.inventory.aggregate([{ $project:{ item: 1, yearSubstring: { $substr: [ "$quarter", 0, 2 ] }, quarterSubtring: { $substr: [ "$quarter", 2, -1 ] } } }]) { "_id" : 1, "item" : "ABC1", "yearSubstring" : "13", "quarterSubtring" : "Q1" } { "_id" : 2, "item" : "ABC2", "yearSubstring" : "13", "quarterSubtring" : "Q4" } $ toLower - converts to lower case
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "PRODUCT 1" } db.test.aggregate([{ $project:{ item: { $toLower: "$item" }, description: { $toLower: "$description" }} }]) { "_id" : 1, "item" : "abc1", "description" : "product 1" } $ toUpper converts to upper case
{ "_id" : 2, "item" : "abc2", quarter: "13Q4", "description" : "Product 2" } db.inventory.aggregate( [ { $project:{ item: { $toUpper: "$item" }, description: { $toUpper: "$description" } } } ] ) { "_id" : 2, "item" : "ABC2", "description" : "PRODUCT 2" } $ strcasecmp compares strings
Compares two strings and returns:
- 1 if the first line is “larger” than the second line.
- 0 if two strings are equal.
- -1 if the first line is less than the second line.
The operator is not case sensitive.
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "product 1" } { "_id" : 2, "item" : "ABC2", quarter: "13Q4", "description" : "product 2" } { "_id" : 3, "item" : "XYZ1", quarter: "14Q2", "description" : null } db.inventory.aggregate([{ $project:{ item: 1, comparisonResult: { $strcasecmp: [ "$quarter", "13q4" ] } } }]) { "_id" : 1, "item" : "ABC1", "comparisonResult" : -1 } { "_id" : 2, "item" : "ABC2", "comparisonResult" : 0 } { "_id" : 3, "item" : "XYZ1", "comparisonResult" : 1 } Work with dates
$ dayOfYear day of the year in a row
$ dayOfMonth day in month by account
$ dayOfWeek returns the day of the week in a row, 1 (Saturday) - 7 (Sunday).
$ year returns the year
$ month returns the month in a row
$ week returns the week number of the year as a number from 0 to 53
$ hour returns the hour as a number between 0 and 23
$ minute returns a minute as a number between 0 and 59
$ second returns seconds as a number between 0 and 23
$ millisecond returns milliseconds as a number between 0 and 999
Returns the day of the year for a date as a number between 1 and 366.
For example, for January 1 will return 1.
{ "_id": 1, "item": "abc", "date" : ISODate("2014-01-01T08:15:39.736Z") } db.sales.aggregate( [ { $project: { year: { $year: "$date" }, month: { $month: "$date" }, day: { $dayOfMonth: "$date" }, hour: { $hour: "$date" }, minutes: { $minute: "$date" }, seconds: { $second: "$date" }, milliseconds: { $millisecond: "$date" }, dayOfYear: { $dayOfYear: "$date" }, dayOfWeek: { $dayOfWeek: "$date" }, week: { $week: "$date" } } } ] ) { "_id" : 1, "year" : 2014, "month" : 1, "day" : 1, "hour" : 8, "minutes" : 15, "seconds" : 39, "milliseconds" : 736, "dayOfYear" : 1, "dayOfWeek" : 4, "week" : 0 } $ dateToString converts to string
Converts a date object to a string according to the specified format.
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity" : 2, "date" : ISODate("2014-01-01T08:15:39.736Z") } db.test.aggregate( [ { $project: { yearMonthDay: { $dateToString: { format: "%Y-%m-%d", date: "$date" } }, time: { $dateToString: { format: "%H:%M:%S:%L", date: "$date" } } } } ] ) { "_id" : 1, "yearMonthDay" : "2014-01-01", "time" : "08:15:39:736" } Product Catalog
This chapter describes the basic principles for designing a product catalog in an e-commerce system using
MongoDB .The product catalog should be able to store different types of objects, each of which should have its own list of characteristics.
For relational databases, there are several solutions to similar problems, differing in performance as well. We will look at some of these options, and then see how this will be resolved in
MongoDB .SQL and relational data model
Concrete Table Inheritance (Inheritance with tables of finite classes)
The first option in the relational model is to create your own table for each category of goods:
CREATE TABLE `product_audio_album` ( `sku` char(8) NOT NULL, ... `artist` varchar(255) DEFAULT NULL, `genre_0` varchar(255) DEFAULT NULL, `genre_1` varchar(255) DEFAULT NULL, ..., PRIMARY KEY(`sku`)) ... CREATE TABLE `product_film` ( `sku` char(8) NOT NULL, ... `title` varchar(255) DEFAULT NULL, `rating` char(8) DEFAULT NULL, ..., PRIMARY KEY(`sku`)) ... This approach has two main limitations related to flexibility.
- Actually creating every time a new table for each new product category.
- Explicit adaptation of requests for a specific type of product.
Single Table Inheritance (Inheritance with a single table)
The second option in the relational model is to use a single table for all categories of goods. And adding new columns at any time you need to save data about the types of goods:
CREATE TABLE `product` ( `sku` char(8) NOT NULL, ... `artist` varchar(255) DEFAULT NULL, `genre_0` varchar(255) DEFAULT NULL, `genre_1` varchar(255) DEFAULT NULL, ... `title` varchar(255) DEFAULT NULL, `rating` char(8) DEFAULT NULL, ..., PRIMARY KEY(`sku`)) This approach is more flexible and allows you to make single requests based on different types of products.
Multiple Table Inheritance (multiple inheritance tables)
Also in the relational model, one can use “multiple inheritance of tables”, a pattern in which attributes common to all product categories are in the main
product table and separate tables (for each category have their own) will contain different attributes.Consider the following
SQL example: CREATE TABLE `product` ( `sku` char(8) NOT NULL, `title` varchar(255) DEFAULT NULL, `description` varchar(255) DEFAULT NULL, `price`, ... PRIMARY KEY(`sku`)) CREATE TABLE `product_audio_album` ( `sku` char(8) NOT NULL, ... `artist` varchar(255) DEFAULT NULL, `genre_0` varchar(255) DEFAULT NULL, `genre_1` varchar(255) DEFAULT NULL, ..., PRIMARY KEY(`sku`), FOREIGN KEY(`sku`) REFERENCES `product`(`sku`)) ... CREATE TABLE `product_film` ( `sku` char(8) NOT NULL, ... `title` varchar(255) DEFAULT NULL, `rating` char(8) DEFAULT NULL, ..., PRIMARY KEY(`sku`), FOREIGN KEY(`sku`) REFERENCES `product`(`sku`)) ... This option is more efficient than inheriting a single table and slightly more flexible than creating a table for each category. This option requires the use of an “expensive”
JOIN to get all the attributes related to a particular product.Attribute values for each entity
And the last pattern in the relational model is the
entity-attribute-value schema. In accordance with this scheme, we will have a table with three columns, for example, entity_id , attribute_id , value with which each product will be described.Consider an example of storing audio recordings:
| Entity | Attribute | Value |
| sku_00e8da9b | type | Audio album |
| sku_00e8da9b | title | A love supreme |
| sku_00e8da9b | ... | ... |
| sku_00e8da9b | artist | John coltrane |
| sku_00e8da9b | genre | Jazz |
| sku_00e8da9b | genre | General |
| ... | ... | ... |
This scheme is quite flexible:
Any product can have any set of attributes. New product categories do not require changes to the database.
The disadvantage of this option is that it takes a lot of queries containing a
JOIN , which in turn is not very good for performance.In addition, some
e-commerce solutions with relational database systems serialize this data in the BLOB column. And the attributes of goods become difficult to search and sort.Non relational data model
Since
mongodb not a relational database, we have additional flexibility in creating a product catalog.The best option is to use one collection to store all kinds of documents. And since for each document there can be any scheme, it is possible to store all the characteristics (attributes) of the goods in one document.
At the root of the document should be general information about the product to facilitate searching the entire catalog. And already in the subdocuments there should be fields that are unique for each document. Consider an example:
{ sku: "00e8da9b", type: "Audio Album", title: "A Love Supreme", description: "by John Coltrane", asin: "B0000A118M", shipping: { weight: 6, dimensions: { width: 10, height: 10, depth: 1 }, }, pricing: { list: 1200, retail: 1100, savings: 100, pct_savings: 8 }, details: { title: "A Love Supreme [Original Recording Reissued]", artist: "John Coltrane", genre: [ "Jazz", "General" ], ... tracks: [ "A Love Supreme Part I: Acknowledgement", "A Love Supreme Part II - Resolution", "A Love Supreme, Part III: Pursuance", "A Love Supreme, Part IV-Psalm" ], }, } For documents that store information about films
{ type: "Film" } The main fields are price, delivery, etc. remain the same. But the contents of the sub-document will be different. For example: { sku: "00e8da9d", type: "Film", ..., asin: "B000P0J0AQ", shipping: { ... }, pricing: { ... }, details: { title: "The Matrix", director: [ "Andy Wachowski", "Larry Wachowski" ], writer: [ "Andy Wachowski", "Larry Wachowski" ], ..., aspect_ratio: "1.66:1" }, } In most cases, the basic operations for the product catalog is a search. Below we will see various types of queries that may come in handy. All examples will be in
Python/PyMongo .Find albums by genre and sort by release year
This request returns documents with goods corresponding to a particular genre and sorted in reverse chronological order:
query = db.products.find({'type':'Audio Album', 'details.genre': 'jazz'}).sort([('details.issue_date', -1)]) This query requires an index for the fields used in the query and in the sort:
db.products.ensure_index([ ('type', 1), ('details.genre', 1), ('details.issue_date', -1)]) Find products sorted by discount percentage in descending order.
While most requests will be for a specific type of product (for example, albums, movies, etc.), we may often need to return all products in a certain price range.
We will find products that have a good discount. We will use the price field in all documents for the search.
query = db.products.find( { 'pricing.pct_savings': {'$gt': 25 }).sort([('pricing.pct_savings', -1)]) For this request, create an index across the field
pricing.pct_savings : db.products.ensure_index('pricing.pct_savings') MongoDB can read indexes in ascending or descending order.Find all the movies that famous actors played
Find documents whose document type is
"Film" and the document attributes have the value { 'actor': 'Keanu Reeves' } . Result will be sorted by date in descending order. query = db.products.find({'type': 'Film', 'details.actor': 'Keanu Reeves'}).sort([('details.issue_date', -1)]) For this query, create the following index:
db.products.ensure_index([ ('type', 1), ('details.actor', 1), ('details.issue_date', -1)]) The index begins with the
type field which is in all documents and goes further along the details.actor field. By this we narrow down the search area. Thus, the index will be as efficient as possible.Find all the movies that have a certain word in the title.
In order to perform a word search query regardless of the type of database, the database will have to scan some part of the documents to get the result.
Mongodb supports regular expressions in queries. In Python, you can use the re module to construct regular expressions. import re re_hacker = re.compile(r'.*hacker.*', re.IGNORECASE) query = db.products.find({'type': 'Film', 'title': re_hacker}).sort([('details.issue_date', -1)]) Mongodb provides a special syntax for regular expressions, so querying is possible for queries without the
re module. Consider the following example, an alternative to the previous one. query = db.products.find({ 'type': 'Film', 'title': {'$regex': '.*hacker.*', '$options':'i'}}).sort([('details.issue_date', -1)]) $options special operator, in this case it indicates that the search word is not case sensitive.Create an index:
db.products.ensure_index([ ('type', 1), ('details.issue_date', -1), ('title', 1) ]) This index allows you to avoid scanning entire documents, thanks to the index only the
title field will be scanned.Sharding
Database performance when scaling depends on indexes. You can use sharding to improve performance, then large indexes will fit into the RAM.
In the configuration of shards, select the
shard key , this will allow mongos route requests directly to the shard we need or a small group of shards.Since most requests have a
type field, you can include it in the shard key . For the rest of the shard key you need to consider:details.issue_datewe will not include in theshard key, because this field is not present in requests but only in sorting.- You need to include one or more fields that are contained in
detailand are often requested.
In the following example, assume that the
details.genre field is the second most important field after type . Initialize sharding with Python/PyMongo >>> db.command('shardCollection', 'product', { key : { 'type': 1, 'details.genre' : 1, 'sku':1 } } ) { "collectionsharded" : "details.genre", "ok" : 1 } Even if we create an unsuccessful
shard key , it will still benefit from sharding:- Sharding will provide a large amount of RAM available for storing indexes.
MongoDBwill parallelize requests for shards, reducing latency.
Reading
Although sharding is a good way to scale, some datasets cannot be divided in such a way that
mongos directs requests to the right shards.In this case,
mongos sends requests to all shards at once, and then returns to the client with the result.We can slightly increase performance due to the fact that we explicitly indicate from which shard it is preferable to read.
The
SECONDARY property in the following example allows you to read from the secondary node (as well as the primary) for the entire connection. conn = pymongo.MongoClient(read_preference=pymongo.SECONDARY) SECONDARY_ONLY means that the client will only read from the secondary member. conn = pymongo.MongoClient(read_preference=pymongo.SECONDARY_ONLY) You can also specify a
read_preference for specific requests, for example: results = db.product.find(..., read_preference=pymongo.SECONDARY) or
results = db.product.find(..., read_preference=pymongo.SECONDARY_ONLY) Cart and stock management
Users of online stores regularly add and remove items from their “basket”, and therefore the quantity of goods in stock may constantly change during the purchase several times, besides, the store user may refuse to buy at any time, and sometimes other unforeseen problems may arise. To solve which you will need to cancel the order.
All this may slightly complicate the accounting of goods in stock, and we need to make sure that users cannot “buy” those goods of which are already reserved.
Therefore, the basket will have time during which, if it was inactive, the reserved goods will again be available to everyone else and the basket will be cleared.
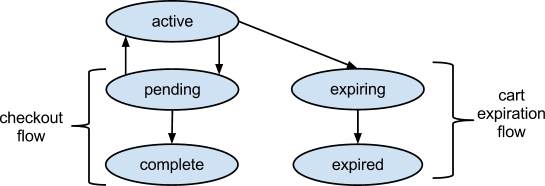
Documents containing the current quantity of stocks for each inventory unit ( SKU ; or item), as well as a list of baskets with the quantity of goods in each, should be saved to the
Inventory collection. Then we can return the available balances if they were in the basket, but the client did not use the basket for a while.In the following example,
_id field storing a SKU. # _id:SKU, , 16 , 1 . # id 42, 2 . c id 43. 19 . { _id: '00e8da9b', qty: 16, carted: [ { qty: 1, cart_id: 42, timestamp: ISODate("2012-03-09T20:55:36Z") }, { qty: 2, cart_id: 43, timestamp: ISODate("2012-03-09T21:55:36Z") }, ] } , .
SKU ,
quantity , , item_details # item_details # , . { _id: 42, last_modified: ISODate("2012-03-09T20:55:36Z"), status: 'active', items: [ { sku: '00e8da9b', qty: 1, item_details: {...} }, { sku: '0ab42f88', qty: 4, item_details: {...} } ] } Operations
.
. add_item_to_cart .
def add_item_to_cart(cart_id, sku, qty, details): now = datetime.utcnow() # , result = db.cart.update( {'_id': cart_id, 'status': 'active' }, {'$set': {'last_modified':now}, '$push': {'items': {'sku':sku, 'qty':qty, 'details':details}}}, w=1 ) if not result['updatedExisting']: raise CartInactive() # result = db.inventory.update( {'_id':sku, 'qty': {'$gte': qty}}, {'$inc': {'qty':-qty}, '$push': {'carted': {'qty':qty, 'cart_id':cart_id, 'timestamp':now}}}, w=1 ) if not result['updatedExisting']: # , , . db.cart.update( {'_id': cart_id }, { '$pull': { 'items': {'sku': sku } } }) raise InadequateInventory()
, _id .
— , . , .
, .
, , .
def update_quantity(cart_id, sku, old_qty, new_qty): # _id . now = datetime.utcnow() delta_qty = new_qty - old_qty # , . result = db.cart.update( {'_id': cart_id, 'status': 'active', 'items.sku': sku }, {'$set': { 'last_modified': now, 'items.$.qty': new_qty } }, w=1 ) if not result['updatedExisting']: raise CartInactive() # result = db.inventory.update( {'_id':sku, 'carted.cart_id': cart_id, 'qty': {'$gte': delta_qty} }, {'$inc': {'qty': -delta_qty },'$set': { 'carted.$.qty': new_qty, 'timestamp': now } }, w=1 ) if not result['updatedExisting']: # db.cart.update( {'_id': cart_id, 'items.sku': sku }, {'$set': { 'items.$.qty': old_qty } } ) raise InadequateInventory()
, , .
def checkout(cart_id): now = datetime.utcnow() # <code>active</code> <code>pending</code>. # cart = db.cart.find_and_modify( {'_id': cart_id, 'status': 'active' }, update={'$set': { 'status': 'pending','last_modified': now } } ) if cart is None: raise CartInactive() # ; payment try: collect_payment(cart) db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'complete' } } ) db.inventory.update( {'carted.cart_id': cart_id}, {'$pull': {'cart_id': cart_id} }, multi=True) except: db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'active' } } ) raise
, pending . , .
- ,
cart_id inventory . complete . - , , .
.
.
timeout .
def expire_carts(timeout): now = datetime.utcnow() threshold = now - timedelta(seconds=timeout) # db.cart.update( {'status': 'active', 'last_modified': { '$lt': threshold } }, {'$set': { 'status': 'expiring' } }, multi=True ) # for cart in db.cart.find({'status': 'expiring'}): # for item in cart['items']: db.inventory.update( { '_id': item['sku'], 'carted.cart_id': cart['id'], 'carted.qty': item['qty'] }, {'$inc': { 'qty': item['qty'] }, '$pull': { 'carted': { 'cart_id': cart['id'] } } } ) db.cart.update( {'_id': cart['id'] }, {'$set': { 'status': 'expired' })
:
- , .
- , .
- ,
expired .
status last_modified .
db.cart.ensure_index([('status', 1), ('last_modified', 1)])
.
: , inventory , , , .
, inventory carted .
def cleanup_inventory(timeout): now = datetime.utcnow() threshold = now - timedelta(seconds=timeout) # for item in db.inventory.find( {'carted.timestamp': {'$lt': threshold }}): carted = dict( (carted_item['cart_id'], carted_item) for carted_item in item['carted'] if carted_item['timestamp'] < threshold ) # : carted, inventory for cart in db.cart.find( { '_id': {'$in': carted.keys() }, 'status':'active'}): cart = carted[cart['_id']] db.inventory.update( {'_id': item['_id'], 'carted.cart_id':cart['_id'] }, { '$set': {'carted.$.timestamp':now }} ) del carted[cart['_id']] # : carted . for cart_id, carted_item in carted.items(): db.inventory.update( { '_id': item['_id'], 'carted.cart_id': cart_id, 'carted.qty': carted_item['qty'] }, { '$inc': { 'qty': carted_item['qty'] }, '$pull': { 'carted': { 'cart_id': cart_id } } } )
«carted» , , timeout . :
timeout , - , .- , , .
, shard key _id , _id .
mongos _id mongod .
_id shard key .
_id cart , .
, , ( MD5 SHA-1) ObjectID, _id.
:
import hashlib import bson cart_id = bson.ObjectId() cart_id_hash = hashlib.md5(str(cart_id)).hexdigest() cart = { "_id": cart_id, "cart_hash": cart_id_hash } db.cart.insert(cart)
, , _id shard key .
, , ( Sleep () ), .
Python/PyMongo :
>>> db.command('shardCollection', 'inventory', 'key': { '_id': 1 } ) { "collectionsharded" : "inventory", "ok" : 1 } >>> db.command('shardCollection', 'cart', 'key': { '_id': 1 } ) { "collectionsharded" : "cart", "ok" : 1 }
def add_item_to_cart(cart_id, sku, qty, details): now = datetime.utcnow() # , result = db.cart.update( {'_id': cart_id, 'status': 'active' }, {'$set': {'last_modified':now}, '$push': {'items': {'sku':sku, 'qty':qty, 'details':details}}}, w=1 ) if not result['updatedExisting']: raise CartInactive() # result = db.inventory.update( {'_id':sku, 'qty': {'$gte': qty}}, {'$inc': {'qty':-qty}, '$push': {'carted': {'qty':qty, 'cart_id':cart_id, 'timestamp':now}}}, w=1 ) if not result['updatedExisting']: # , , . db.cart.update( {'_id': cart_id }, { '$pull': { 'items': {'sku': sku } } }) raise InadequateInventory() def update_quantity(cart_id, sku, old_qty, new_qty): # _id . now = datetime.utcnow() delta_qty = new_qty - old_qty # , . result = db.cart.update( {'_id': cart_id, 'status': 'active', 'items.sku': sku }, {'$set': { 'last_modified': now, 'items.$.qty': new_qty } }, w=1 ) if not result['updatedExisting']: raise CartInactive() # result = db.inventory.update( {'_id':sku, 'carted.cart_id': cart_id, 'qty': {'$gte': delta_qty} }, {'$inc': {'qty': -delta_qty },'$set': { 'carted.$.qty': new_qty, 'timestamp': now } }, w=1 ) if not result['updatedExisting']: # db.cart.update( {'_id': cart_id, 'items.sku': sku }, {'$set': { 'items.$.qty': old_qty } } ) raise InadequateInventory() def checkout(cart_id): now = datetime.utcnow() # <code>active</code> <code>pending</code>. # cart = db.cart.find_and_modify( {'_id': cart_id, 'status': 'active' }, update={'$set': { 'status': 'pending','last_modified': now } } ) if cart is None: raise CartInactive() # ; payment try: collect_payment(cart) db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'complete' } } ) db.inventory.update( {'carted.cart_id': cart_id}, {'$pull': {'cart_id': cart_id} }, multi=True) except: db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'active' } } ) raise cart_id inventory . complete .def expire_carts(timeout): now = datetime.utcnow() threshold = now - timedelta(seconds=timeout) # db.cart.update( {'status': 'active', 'last_modified': { '$lt': threshold } }, {'$set': { 'status': 'expiring' } }, multi=True ) # for cart in db.cart.find({'status': 'expiring'}): # for item in cart['items']: db.inventory.update( { '_id': item['sku'], 'carted.cart_id': cart['id'], 'carted.qty': item['qty'] }, {'$inc': { 'qty': item['qty'] }, '$pull': { 'carted': { 'cart_id': cart['id'] } } } ) db.cart.update( {'_id': cart['id'] }, {'$set': { 'status': 'expired' }) expired .db.cart.ensure_index([('status', 1), ('last_modified', 1)]) def cleanup_inventory(timeout): now = datetime.utcnow() threshold = now - timedelta(seconds=timeout) # for item in db.inventory.find( {'carted.timestamp': {'$lt': threshold }}): carted = dict( (carted_item['cart_id'], carted_item) for carted_item in item['carted'] if carted_item['timestamp'] < threshold ) # : carted, inventory for cart in db.cart.find( { '_id': {'$in': carted.keys() }, 'status':'active'}): cart = carted[cart['_id']] db.inventory.update( {'_id': item['_id'], 'carted.cart_id':cart['_id'] }, { '$set': {'carted.$.timestamp':now }} ) del carted[cart['_id']] # : carted . for cart_id, carted_item in carted.items(): db.inventory.update( { '_id': item['_id'], 'carted.cart_id': cart_id, 'carted.qty': carted_item['qty'] }, { '$inc': { 'qty': carted_item['qty'] }, '$pull': { 'carted': { 'cart_id': cart_id } } } ) timeout , - , .import hashlib import bson cart_id = bson.ObjectId() cart_id_hash = hashlib.md5(str(cart_id)).hexdigest() cart = { "_id": cart_id, "cart_hash": cart_id_hash } db.cart.insert(cart) >>> db.command('shardCollection', 'inventory', 'key': { '_id': 1 } ) { "collectionsharded" : "inventory", "ok" : 1 } >>> db.command('shardCollection', 'cart', 'key': { '_id': 1 } ) { "collectionsharded" : "cart", "ok" : 1 } . .
:

, , .
:
Objectid.- URL-.
- , .
:
{ "_id" : ObjectId("4f5ec858eb03303a11000002"), "name" : "Modal Jazz", "parent" : ObjectId("4f5ec858eb03303a11000001"), "slug" : "modal-jazz", "ancestors" : [ { "_id" : ObjectId("4f5ec858eb03303a11000001"), "slug" : "bop", "name" : "Bop" }, { "_id" : ObjectId("4f5ec858eb03303a11000000"), "slug" : "ragtime", "name" : "Ragtime" } ] } , E-Commerce .
Python/PyMongo.
.
slug “bread crumb” category = db.categories.find({'slug':slug}, {'_id':0, 'name':1, 'ancestors.slug':1, 'ancestors.name':1 }) slug . >>> db.categories.ensure_index('slug', unique=True) , . -
Swing Ragtime , :
, . , :
def build_ancestors(_id, parent_id): parent = db.categories.find_one({'_id': parent_id}, {'name': 1, 'slug': 1, 'ancestors':1}) parent_ancestors = parent.pop('ancestors') ancestors = [ parent ] + parent_ancestors db.categories.update({'_id': _id}, {'$set': { 'ancestors': ancestors } }) Ragtime , Swing .:
doc = dict(name='Swing', slug='swing', parent=ragtime_id) swing_id = db.categories.insert(doc) build_ancestors(swing_id, ragtime_id) _id,
bop swing .
bop : db.categories.update({'_id':bop_id}, {'$set': { 'parent': swing_id } } ) .
def build_ancestors_full(_id, parent_id): ancestors = [] while parent_id is not None: parent = db.categories.find_one({'_id': parent_id}, {'parent': 1, 'name': 1, 'slug': 1, 'ancestors':1}) parent_id = parent.pop('parent') ancestors.append(parent) db.categories.update({'_id': _id}, {'$set': { 'ancestors': ancestors } }) bop for cat in db.categories.find({'ancestors._id': bop_id}, {'parent': 1}): build_ancestors_full(cat['_id'], cat['parent']) ancestors._id . db.categories.ensure_index('ancestors._id') .
“Bop” “BeBop” :

— :
db.categories.update({'_id':bop_id}, {'$set': { 'name': 'BeBop' } }) :
db.categories.update({'ancestors._id': bop_id}, {'$set': { 'ancestors.$.name': 'BeBop' } }, multi=True) :
- $
_id. multi.
ancestors._id ., .
shard key _id . >>> db.command('shardCollection', 'categories', { 'key': {'_id': 1} }) { "collectionsharded" : "categories", "ok" : 1 } PS Request for grammatical errors and translation errors to write to the PM.
Materials used:
MongoDB
aggregation framework
« » (ru)
Source: https://habr.com/ru/post/260291/
All Articles