GrabDuck: integration with StackOverflow via StackExchange API
Greetings reader,
Today, we will look at how the StackExchange API can be used to retrieve data from sites in this collection, such as StackOverflow. Also, we will look at what opportunities exist for promoting applications / sites using this API on StackExchange and, finally, we will show how the integration with SO looks on GrabDuck.
Interested? We ask under the cat.
')
For those who are not familiar with what GrabDuck is, let's take a quick look at (for more details, see the previous article - GrabDuck: a new look at bookmarks ).
So, on GrabDuck, users store their bookmarks and can search for the documents they need using full-text search. The system in return will return what was saved by the user, and will also show the bookmarks of other users if it considers that these materials may also be interesting.
The main idea of the service is to act as a sort of center, collecting the pending from different sources of the page in one place and provide a universal search mechanism.
Why StackExchange? Analyzing the statistics on the saved documents, we came to the conclusion that we have a lot of bookmarks from IT-oriented sites, such as Habr or StackOverflow. These sites allow users to form their favorites from articles or questions. “Here,” we thought, “another source that our users can configure and receive periodic updates of their bookmarks from these services on GrabDuck.” They decided to start with StackOverflow - this is a popular resource not only in our country, but also abroad, it has a clear and simple public API, as well as a large community.
So, our task is to make synchronization of questions from your favorite StackOverflow. Let's return the site closer to us - StackOverflow in Russian.
As everyone probably knows, StackExchange is not one, but a whole group of sites (or, in the terminology of StackExchange — communities) united by one idea: questions and answers. The most popular ones are related to IT topics in one way or another; these are StackOverflow, the Russian version of StackOverflow, AskUbuntu, ThinkDifferent, SuperUser and many others.
The starting point for exploring the API is https://api.stackexchange.com/docs
What is convenient, does not play a role with which site you need to communicate - StackExchange provides a single API for all its sites. That is, we can generate the same request for all sites and send to api.stackexchange.com, and in order to determine which of the sites should work it out, we need to set a special parameter ( site parameter). As a result, we can receive different answers from each site separately.
You can send requests in two ways.
The API is open, which means it can be used without any prior registration, although the number of requests is limited to 300 per day. In order to be able to send more requests (up to 10,000 per day), it is better to register all the same and get a special key for your application. In the case of working with the API through a form on the website, the number of API calls is also limited to 10,000 per day.
But enough words, let's get down to business. Let me remind you once again that our task is to get a list of favorites saved by the user in Russian StackOverflow (aka HashCode.ru in the recent past). We will work through the form on the site.
First we need to understand how to set that we want to work with stackoverflow.ru or, in other words, what the site parameter in our request should be equal to. See a list of all sites related to StackExchange. To do this, go to the documentation section Sites , run the query:
https://api.stackexchange.com/2.2/sites
and look for StackOverflow in Russian in the results
The resulting object contains all the necessary information about the site we need. For example, how the creators ( audience ), Favicon and a large image for the site ( favicon_url and ison_url ) position , the color gamut, which we may need for some purposes ( styling ) and much more. In addition, we see the parameter we need for the API call ( api_site_parameter ), this is ru.stackoverflow .
Now we have all the data to form a request for a list of favorites of a particular user. For example, choose an arbitrary user with id 16095 who has questions in his favorites.
go to the Users - Favorites page (also available from the documentation section)
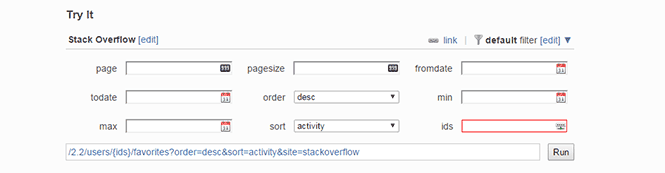
Correct the request for the parameters we need and run:
https://api.stackexchange.com/2.2/users/16095/fainted?order=desc&sort=activity&site=ru.stackoverflow
as a result, we get what we needed - a list of the "favorites" of a particular user:
Problem solved. It's simple, is not it?
So, our application is ready, what next? It is necessary to somehow tell people about him. And here StackExchange is again to help us.
The fact is that there is an official way to describe your application on the SE itself. A detailed description of how to do this (though only in English) can be found at stackapps.com
As an example of what a posted ad looks like, here’s a description of GrabDuck on StackApps.com .
I hope the above information will be useful to those who have ideas on what can be done on the basis of StackExchange sites.
Let's see what synchronization looks like with us. We will work under the same user with ID 16095
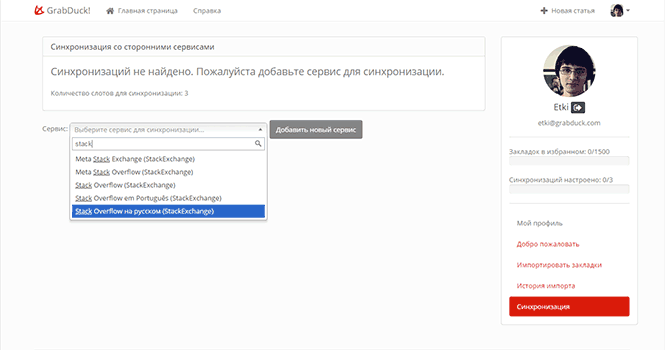
So after registration, go to your personal account and select the item "Synchronization".
At the moment, the user has 3 slots for synchronization. We select the service we need (this is StackOverflow in Russian) and click on the “Add new service” button.
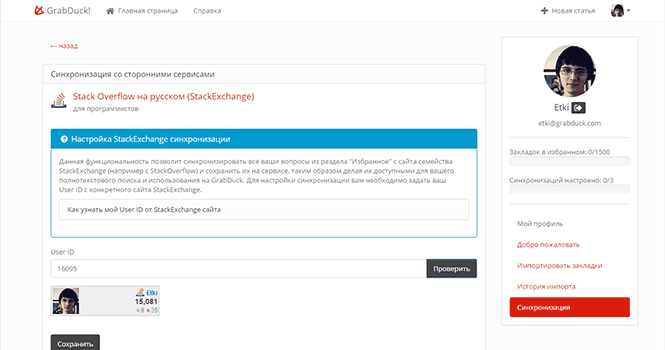
Enter user ID. By clicking on the "Check" button, you can make sure that the ID is entered correctly. We save. All synchronization is configured.
The current status of synchronization can always be viewed in your account. And questions added to StackOverflow are available along with tags for search on GrabDuck.
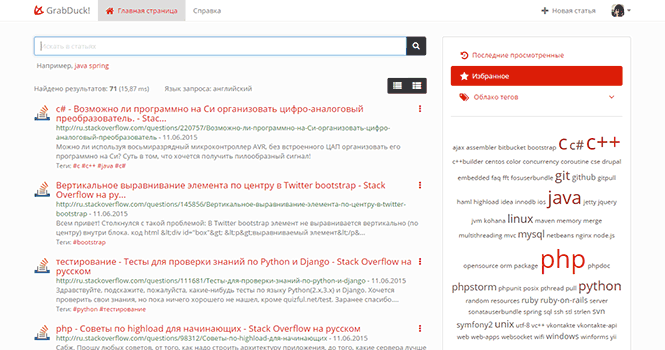
An inquisitive reader here may ask - why do we need it at all? I already can go to StackOverflow and find what I need there.
Yes, this is true, but what else do we offer on GD. The search takes place not only on the favorites with SO, but also on other user bookmarks, which may also contain the necessary information. Or the user can set up additional services for synchronization and search documents from other sites at the same time (and we have plans to synchronize with habr, rss, delicious and many other popular services). And note all this without any active participation by the user - all the syncs once set up automatically load the pending materials onto GD.
And at the end of the article, for those who follow us - a small overview of what is new from last time.
A little more than a month has passed since the last article. What has changed during this time with us.
We have an extension for "Fox". From personal impressions - for chrome somehow everything looks much simpler and more logical. Initially, I just wanted to transfer the code from Chrome without any alterations to FF. Therefore, when making an extension for Chrome, we tried to use only HTML + CSS + JavaScript, so that it could be transferred in the future without any modifications to other browsers. It was not there. In FF, almost everything can be done only using its own specific API. A seemingly trivial example, to send a request to the server, it simply won't work here - you need to use a special function from the FireFox Addon API. Therefore it was necessary to redo almost everything again. With the confirmation of extensions the same song. If for Chrome everything went relatively easily and smoothly, then in FF they promise to complete the approval procedure in 3-5 days, but in practice they are placed in a queue that practically does not move. Initially, we were there at number 136, for a month and a little we moved by 106. So, apparently, by winter our expansion will still be considered. In general, how something works for them in general is not clear, but it becomes clear why Chrome takes away from the FF market (no matter how sad it would be).
It became possible to add tags when adding bookmarks. It is available, as when adding through the site, and from all extensions. We still do not like this method, and we believe that over time we will be able to offer users that tags are assigned automatically. But after the first article there were many requests to add this functionality, so for now we decided to go forward and do it.
When parsing websites, we try to pick up the displayed image from the page. Sometimes this fails, sometimes there are simply no images, and sometimes only small images can be taken from the site, which do not look very beautiful when stretched. Therefore, we began to take screenshots of sites. Unfortunately, the number of bookmarks is huge and it is not physically possible to generate images for everything in one approach. Therefore, we corrected the parsing algorithm and so far we are trying to take screenshots only where it is really necessary. For the curious, we use Page2Images . On “try”, there is a free account with a limit of 100 urls per day and a large processing time for each url. If there are any better alternatives, please leave in the comments.
No, we did not redraw the buttons on the site and did not change colors, but gradually came to the conclusion that it was inconvenient to jump from page to page between bookmarks, tags and recent documents and decided to combine everything on one screen. Now the user can immediately take a look at all that he has and decide which way to find what he needs. “Redesign” is not completed yet, we want to redo the very logic of access to documents, to make it simpler and more understandable. But the first step in this direction has already been taken.
Actually this is all about this article. In addition to the synchronization itself, GrabDuck also learned how to correctly place tags from all questions of the StackExchange communities, as well as from all Habr sites. We will continue to work on this idea, and in the future we plan to add synchronization with other useful sites and learn how to fill out meta information for users.
Implemented the history of views. What it is? The simplest explanation is made like on YouTube - when there is a “watch later” list / favorites and a list of everything viewed. For us, in practice, this means that now there are two lists - the user's bookmarks, sorted by the date of addition (the so-called favorites) and the history of views, sorted by the date of reading, where all the user used, including documents from the recommendations.
Fixed a bunch of errors and refined the mechanism of parsing, page recognition and search for duplicates. Honestly, we didn’t even realize how many disruptions of websites can be made. The most “scary” example, which was never figured out how to handle - the page is and comes back with actual content, but with 500 (server error) response from the server. For the browser, this does not matter, it simply displays what has come, and for us this means that the page is not valid.
That's all for today. We invite everyone to try how the new functionality works and share impressions.
Subscribe to our twitter to keep abreast of all updates.
See you at GrabDuck!
Today, we will look at how the StackExchange API can be used to retrieve data from sites in this collection, such as StackOverflow. Also, we will look at what opportunities exist for promoting applications / sites using this API on StackExchange and, finally, we will show how the integration with SO looks on GrabDuck.
Interested? We ask under the cat.
')
Entry, or why StackExchange
For those who are not familiar with what GrabDuck is, let's take a quick look at (for more details, see the previous article - GrabDuck: a new look at bookmarks ).
So, on GrabDuck, users store their bookmarks and can search for the documents they need using full-text search. The system in return will return what was saved by the user, and will also show the bookmarks of other users if it considers that these materials may also be interesting.
The main idea of the service is to act as a sort of center, collecting the pending from different sources of the page in one place and provide a universal search mechanism.
Why StackExchange? Analyzing the statistics on the saved documents, we came to the conclusion that we have a lot of bookmarks from IT-oriented sites, such as Habr or StackOverflow. These sites allow users to form their favorites from articles or questions. “Here,” we thought, “another source that our users can configure and receive periodic updates of their bookmarks from these services on GrabDuck.” They decided to start with StackOverflow - this is a popular resource not only in our country, but also abroad, it has a clear and simple public API, as well as a large community.
So, our task is to make synchronization of questions from your favorite StackOverflow. Let's return the site closer to us - StackOverflow in Russian.
StackExchange API
As everyone probably knows, StackExchange is not one, but a whole group of sites (or, in the terminology of StackExchange — communities) united by one idea: questions and answers. The most popular ones are related to IT topics in one way or another; these are StackOverflow, the Russian version of StackOverflow, AskUbuntu, ThinkDifferent, SuperUser and many others.
The starting point for exploring the API is https://api.stackexchange.com/docs
What is convenient, does not play a role with which site you need to communicate - StackExchange provides a single API for all its sites. That is, we can generate the same request for all sites and send to api.stackexchange.com, and in order to determine which of the sites should work it out, we need to set a special parameter ( site parameter). As a result, we can receive different answers from each site separately.
You can send requests in two ways.
- As usual, sending HTTP requests to api.stackexchange.com and receiving a JSON response or
- using a special form on stackexchange.com itself, which you can use to preview how this or that functionality works, or you can easily type in a request and then simply transfer it to your application.
The API is open, which means it can be used without any prior registration, although the number of requests is limited to 300 per day. In order to be able to send more requests (up to 10,000 per day), it is better to register all the same and get a special key for your application. In the case of working with the API through a form on the website, the number of API calls is also limited to 10,000 per day.
But enough words, let's get down to business. Let me remind you once again that our task is to get a list of favorites saved by the user in Russian StackOverflow (aka HashCode.ru in the recent past). We will work through the form on the site.
First we need to understand how to set that we want to work with stackoverflow.ru or, in other words, what the site parameter in our request should be equal to. See a list of all sites related to StackExchange. To do this, go to the documentation section Sites , run the query:
https://api.stackexchange.com/2.2/sites
and look for StackOverflow in Russian in the results
..., { "styling": { "tag_background_color": "#FFF", "tag_foreground_color": "#000", "link_color": "#0077CC" }, "related_sites": [ { "relation": "meta", "api_site_parameter": "meta.ru.stackoverflow", "site_url": "http://meta.ru.stackoverflow.com", "name": "Stack Overflow Meta" }, { "relation": "chat", "site_url": "http://chat.stackexchange.com?tab=site&host=ru.stackoverflow.com", "name": "Chat Stack Exchange" } ], "aliases": [ "http://hashcode.ru", "http://stackoverflow.ru" ], "markdown_extensions": [ "Prettify" ], "open_beta_date": 1427414400, "closed_beta_date": 1427414400, "site_state": "open_beta", "favicon_url": "http://cdn.sstatic.net/ru/img/favicon.ico", "icon_url": "http://cdn.sstatic.net/ru/img/apple-touch-icon.png", "audience": "", "site_url": "http://ru.stackoverflow.com", "api_site_parameter": "ru.stackoverflow", "logo_url": "http://cdn.sstatic.net/ru/img/logo.png", "name": "Stack Overflow ", "site_type": "main_site" },... The resulting object contains all the necessary information about the site we need. For example, how the creators ( audience ), Favicon and a large image for the site ( favicon_url and ison_url ) position , the color gamut, which we may need for some purposes ( styling ) and much more. In addition, we see the parameter we need for the API call ( api_site_parameter ), this is ru.stackoverflow .
Now we have all the data to form a request for a list of favorites of a particular user. For example, choose an arbitrary user with id 16095 who has questions in his favorites.
go to the Users - Favorites page (also available from the documentation section)
Correct the request for the parameters we need and run:
https://api.stackexchange.com/2.2/users/16095/fainted?order=desc&sort=activity&site=ru.stackoverflow
as a result, we get what we needed - a list of the "favorites" of a particular user:
{ "items": [ { "tags": ["maven","java","idea","resources"], "owner": { "reputation": 11, "user_id": 25194, "user_type": "registered", "profile_image": "https://www.gravatar.com/avatar/7b745015819bd1d9dbc17ac3f64a40f1?s=128&d=identicon&r=PG", "display_name": "Slayfi", "link": "http://ru.stackoverflow.com/users/25194/slayfi" }, "is_answered": false, "view_count": 162, "answer_count": 0, "score": 2, "last_activity_date": 1433402068, "creation_date": 1416248008, "last_edit_date": 1433402068, "question_id": 376200, "link": "http://ru.stackoverflow.com/questions/376200/class-path-resourse-applicationcontext-xml-cannot-be-opened-because-it-does-no", "title": "Class path resourse [ApplicationContext.xml] cannot be opened because it does not exist" },{ "tags": ["php","websocket"], "owner": { "reputation": 300, "user_id": 19768, "user_type": "registered", "accept_rate": 93, "profile_image": "https://www.gravatar.com/avatar/fa8fae6547dd2415a143680d337b1758?s=128&d=identicon&r=PG", "display_name": "duhon", "link": "http://ru.stackoverflow.com/users/19768/duhon" }, "is_answered": false, "view_count": 197, "answer_count": 0, "score": 4, "last_activity_date": 1432902435, "creation_date": 1414136622, "last_edit_date": 1432902435, "question_id": 370273, "link": "http://ru.stackoverflow.com/questions/370273/%d0%9f%d1%80%d0%b0%d0%b2%d0%b8%d0%bb%d1%8c%d0%bd%d0%b0%d1%8f-%d0%b0%d1%80%d1%85%d0%b8%d1%82%d0%b5%d0%ba%d1%82%d1%83%d1%80%d0%b0-%d0%b4%d0%bb%d1%8f-wamp-%d1%87%d0%b0%d1%82%d0%b0", "title": " wamp " },... Problem solved. It's simple, is not it?
Promotional opportunities
So, our application is ready, what next? It is necessary to somehow tell people about him. And here StackExchange is again to help us.
The fact is that there is an official way to describe your application on the SE itself. A detailed description of how to do this (though only in English) can be found at stackapps.com
As an example of what a posted ad looks like, here’s a description of GrabDuck on StackApps.com .
I hope the above information will be useful to those who have ideas on what can be done on the basis of StackExchange sites.
How did sync with StackOverflow we at GrabDuck
Let's see what synchronization looks like with us. We will work under the same user with ID 16095
So after registration, go to your personal account and select the item "Synchronization".
At the moment, the user has 3 slots for synchronization. We select the service we need (this is StackOverflow in Russian) and click on the “Add new service” button.
Enter user ID. By clicking on the "Check" button, you can make sure that the ID is entered correctly. We save. All synchronization is configured.
The current status of synchronization can always be viewed in your account. And questions added to StackOverflow are available along with tags for search on GrabDuck.
The advantages of this approach, or why synchronize your favorites from SO to GD
An inquisitive reader here may ask - why do we need it at all? I already can go to StackOverflow and find what I need there.
Yes, this is true, but what else do we offer on GD. The search takes place not only on the favorites with SO, but also on other user bookmarks, which may also contain the necessary information. Or the user can set up additional services for synchronization and search documents from other sites at the same time (and we have plans to synchronize with habr, rss, delicious and many other popular services). And note all this without any active participation by the user - all the syncs once set up automatically load the pending materials onto GD.
And at the end of the article, for those who follow us - a small overview of what is new from last time.
GrabDuck Update Log
A little more than a month has passed since the last article. What has changed during this time with us.
FireFox extension
We have an extension for "Fox". From personal impressions - for chrome somehow everything looks much simpler and more logical. Initially, I just wanted to transfer the code from Chrome without any alterations to FF. Therefore, when making an extension for Chrome, we tried to use only HTML + CSS + JavaScript, so that it could be transferred in the future without any modifications to other browsers. It was not there. In FF, almost everything can be done only using its own specific API. A seemingly trivial example, to send a request to the server, it simply won't work here - you need to use a special function from the FireFox Addon API. Therefore it was necessary to redo almost everything again. With the confirmation of extensions the same song. If for Chrome everything went relatively easily and smoothly, then in FF they promise to complete the approval procedure in 3-5 days, but in practice they are placed in a queue that practically does not move. Initially, we were there at number 136, for a month and a little we moved by 106. So, apparently, by winter our expansion will still be considered. In general, how something works for them in general is not clear, but it becomes clear why Chrome takes away from the FF market (no matter how sad it would be).
Tags when adding bookmarks
It became possible to add tags when adding bookmarks. It is available, as when adding through the site, and from all extensions. We still do not like this method, and we believe that over time we will be able to offer users that tags are assigned automatically. But after the first article there were many requests to add this functionality, so for now we decided to go forward and do it.
Screenshots of sites
When parsing websites, we try to pick up the displayed image from the page. Sometimes this fails, sometimes there are simply no images, and sometimes only small images can be taken from the site, which do not look very beautiful when stretched. Therefore, we began to take screenshots of sites. Unfortunately, the number of bookmarks is huge and it is not physically possible to generate images for everything in one approach. Therefore, we corrected the parsing algorithm and so far we are trying to take screenshots only where it is really necessary. For the curious, we use Page2Images . On “try”, there is a free account with a limit of 100 urls per day and a large processing time for each url. If there are any better alternatives, please leave in the comments.
New design
No, we did not redraw the buttons on the site and did not change colors, but gradually came to the conclusion that it was inconvenient to jump from page to page between bookmarks, tags and recent documents and decided to combine everything on one screen. Now the user can immediately take a look at all that he has and decide which way to find what he needs. “Redesign” is not completed yet, we want to redo the very logic of access to documents, to make it simpler and more understandable. But the first step in this direction has already been taken.
Synchronization with StackExchange
Actually this is all about this article. In addition to the synchronization itself, GrabDuck also learned how to correctly place tags from all questions of the StackExchange communities, as well as from all Habr sites. We will continue to work on this idea, and in the future we plan to add synchronization with other useful sites and learn how to fill out meta information for users.
Browsing history
Implemented the history of views. What it is? The simplest explanation is made like on YouTube - when there is a “watch later” list / favorites and a list of everything viewed. For us, in practice, this means that now there are two lists - the user's bookmarks, sorted by the date of addition (the so-called favorites) and the history of views, sorted by the date of reading, where all the user used, including documents from the recommendations.
Minor improvements and bugs
Fixed a bunch of errors and refined the mechanism of parsing, page recognition and search for duplicates. Honestly, we didn’t even realize how many disruptions of websites can be made. The most “scary” example, which was never figured out how to handle - the page is and comes back with actual content, but with 500 (server error) response from the server. For the browser, this does not matter, it simply displays what has come, and for us this means that the page is not valid.
That's all for today. We invite everyone to try how the new functionality works and share impressions.
Subscribe to our twitter to keep abreast of all updates.
See you at GrabDuck!
Source: https://habr.com/ru/post/260129/
All Articles