Cost-effective code 2: crouching DDD, Hidden CQRS

Three programmers were asked to cross the field, and walk to the house on the other side. The novice programmer looked at a short distance and said, “This is not far away! It will take me ten minutes. ” An experienced programmer looked at the field, thought a little, and said: "I could get there in a day." The newcomer looked at him in surprise. The guru programmer looked at the field and said. "It seems about ten minutes, but I think fifteen will be enough." An experienced programmer laughed.
The novice programmer set off, but within a few moments, mines began to explode, leaving behind large pits. From the explosions, he flew back, and he had to start over and over again and again. It took him two days to reach the goal. In addition, he was all shaking and was wounded when he came.
An experienced programmer crawled on all fours. Carefully touching the ground and looking for mines, moving only if I was sure that it was safe. Slowly and carefully he crossed the field during the day. Just hitting a couple of minutes.
')
Guru programmer set off, and went straight across the field. Purposeful and straight. He reached the goal in just ten minutes.
“How did you manage to do this?” Asked two others. “How did you manage not to catch a single mine?”
“Easy,” he replied. "I did not lay mines on my way."
Sadly, you have to admit - we are laying our own mines. In the first part, I detailed the main risks in software development and described the technological and methodological ways to mitigate these risks. Over the past year, I received many comments, the main meaning of which was as follows: “everything is cool, but where to start and how it will look in the real world”. Indeed, the first text is rather theoretical and represents a catalog of links. In this article I will try to give as many examples as possible.
Programmers who do not have sufficient experience may not understand many of the problems described in the first article , because they manifest themselves only in a long run: there is not much difference in how a website is written on ten pages with a pair of filter forms and a CRUD admin panel, all code can be rewritten from scratch in a couple of days. But what will happen in a year or two?
Our site begins to develop, new functionality appears, there are already a few dozen pages and molds, affiliate programs with external resources are added. We advertised on the million-plus Vkontakte public and the main page “developed” under load. Do not worry, stick cache. Now you need to quickly start with friendly service. Copy-paste integration code with a partner from its code base, we write to synchronize "our" and "external" data.
Changes in business rules begin, which have to be duplicated in the code and stored in the subject area, the cache of the main page needs to be updated periodically, the number of bugs and configuration problems in the backlog is growing.
6-7 iterations of changes in business rules, integrations, optimization of performance and expansion of functionality take place, and now we have the Frankenstein monster, stitched from sample code from Stack Overflow, SDK code of partners, crutches and hotpatches, various incredibly useful 3rd party components and own bicycles .
The main problems that I have to fix in the code 2-3 years old
- repeating the boiler-plate-code (all sorts of using, try-catch, log, etc.): makes it difficult to make changes to the code base and refatoring, imperceptibly eats up the time to write the same constructions (seconds at the beginning of the project, days after a year or two the existence of a code base)
- code duplication, including implicit, mindless creation of identical classes of Entity, DTO and ViewModel, duplication of Linq-requests, creation of similar interfaces ITEntityRepository: IRepository <TEntity>, having only one implementation
- SRP violation: stuffing properties into Entity from different contexts and even not related to the home model, creating various managers, services and helper ones with unclear responsibility
- LSP violation
- NullReferenceException
- data errors
- creating feedback, mixing application layers, infrastructure code and domain model code
Usually the excuses for all this disgrace are:
- short release dates
- no time to refactor
- lack of time to plan and design (what architecture? Need to figure out!)
In general, all this is true, but it must be admitted that even experienced developers often lack the “matte part” to quickly make the right decisions. By true, I understand the following state of things: 80% of you write code that performs a business case, and 20% a small reserve for the future, each time guessing exactly what 20% should be written (in other words, how the requirements change). To guess what the stakeholders want (as the domain model of the application will change) usually requires management experience and / or experience in the subject area.
However, there are a number of requirements arising in many growing projects:
- multi-user access (notorious habr-effect), counting viewing hits, likes, etc.
- analytics and personalization (building sales funnels, analyzing user preferences in order to offer more relevant content)
- full text search
- performing pending tasks and scheduled tasks
- filtering, conversion and pagination
- logging, notification system, monitoring, self-diagnostics, self-recovery after failures and error handling
In this article I will focus on the separation of the domain (business rules) from the application infrastructure. Every AOP, dynamic compilation and other magic will be left for the next time.
10 application layers should be enough for everyone
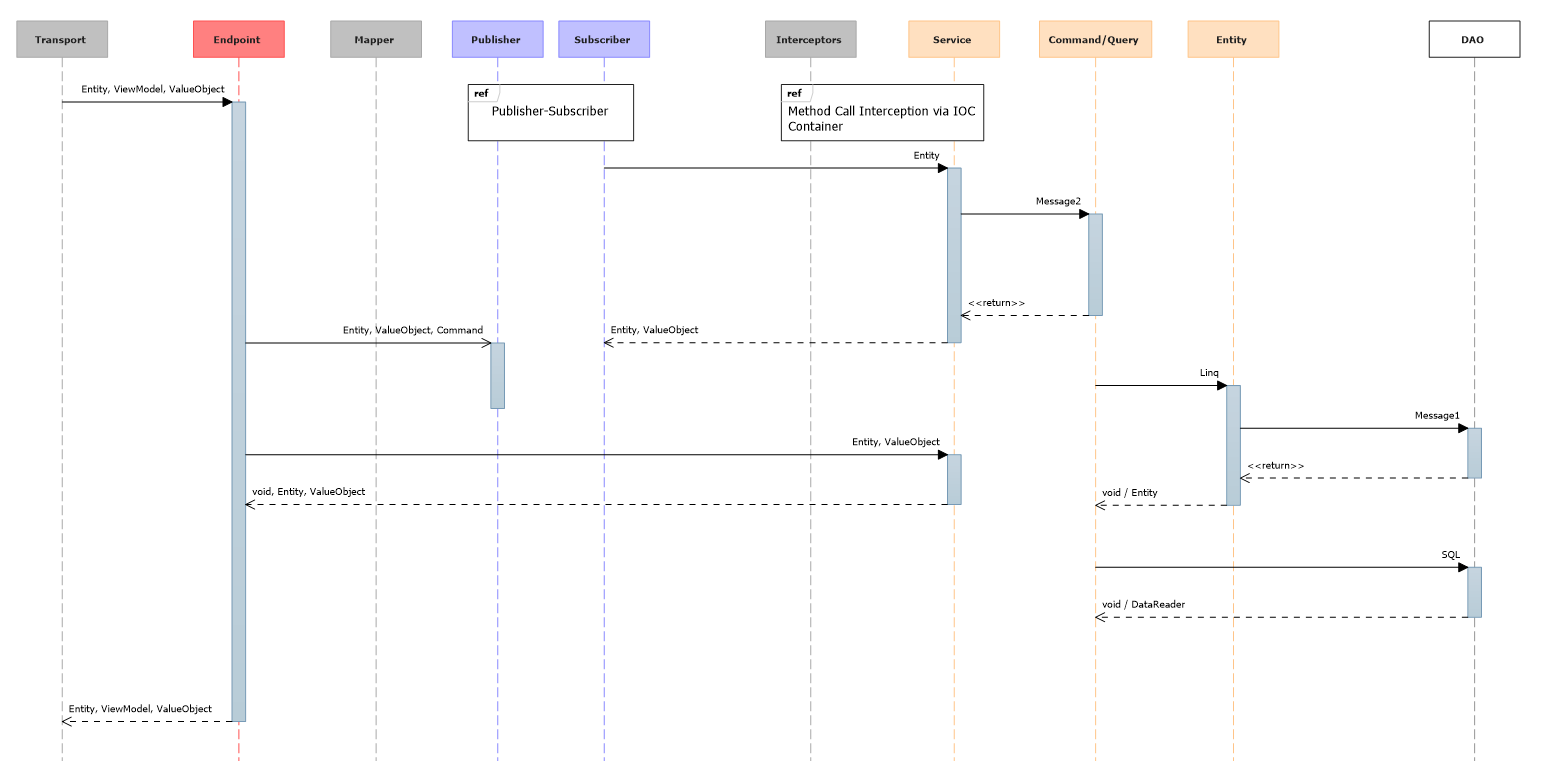
For a “regular web application in a vacuum,” I counted a maximum of 10 layers. Is it a lot or a little? Given that you can "cut corners" and get along with the classic three, I think that is just right. We take out for brackets endpoits, a deyte-mapper, a publisher-subskrayber, intceptors. Remained:
- Services
- Command / Query
- Entity
- DAO
In order to put everything in its place, let's start with the simplest case of a web application - landing page.
The landing page (English “landing page”) is a web page built in a certain way, the main task of which is to collect contact information of the target audience. Used to enhance the effectiveness of advertising, increasing the audience ...
We have one page and it collects "leads". Lead must have email. Optional fields on the form will be the phone and name. Create a Lida class:
public interface IEntity { string GetId(); } public class Lead : IEntity { public static Expression<Func<Lead, bool>> ProcessedRule = x => x.Processed; private string _email; [Key, Required, Index("IX_Email", 1, IsUnique = true)] public string Email { get { return _email; } set { if (string.IsNullOrEmpty(value)) { throw new ArgumentNullException("email"); } _email = value; } } public string Phone { get; set; } public bool Processed { get; set; } public DateTime CreatedDate { get; set; } [Obsolete("Only for model binders and EF, don't use it in your code", true)] internal Lead() { } public Lead([NotNull] string email, string phone = null) { Email = email; Phone = phone; CreatedDate = DateTime.Now; } public bool IsProcessed() { return this.Is(ProcessedRule); } public string GetId() { return Email; } } Entity, Rich Domain Model and defensive programming (aka encapsulation)
Controversy: samolisov.blogspot.ru/2012/10/anemic-domain-model.htmlI am a supporter of a rich domain model (Rich Domain Model) and I don’t like an anemic one, so Lead has the right designer and does not allow himself to be transferred to an inconsistent state (break the invariant). Modern ORM frameworks, whose ancestors spawned anemic models, already allow you to follow the principles of encapsulation (well, almost). The access modifier internal comes to the rescue. Especially for those who do not wash their hands and within the domain assembly uses the default constructor there is an attribute [Obsolete]. The second parameter will break the build when trying to use this constructor explicitly, while your ORM and ModelBinder will easily take advantage of this constructor.
[Obsolete("Only for model binders and EF, don't use it in your code", true)] internal Lead() { } public Lead([NotNull] string email, string phone = null) { Email = email; Phone = phone; CreatedDate = DateTime.Now; } There is no guarantee that the junior will not remove it, but such things can be solved in the course of the code review.
Properties in .NET were invented not only in order to map them to the database. With such an organization code, you will fall exactly in the place where you try to set the wrong email, and not while saving to the database, which can be very far from the moment of setting the value, especially during mass operations.
[Key, Required, Index("IX_Email", 1, IsUnique = true)] public string Email { get { return _email; } set { if (string.IsNullOrEmpty(value)) { throw new ArgumentNullException("email"); } _email = value; } } The constructor also uses the Email property, so the invariant is securely protected.
It's easier for me to work this way, the rule follows from here - Code First. First, I write a domain model, and then I create an auto-migration (so I use the Entity Framework) and execute it.
From my point of view, there is nothing wrong with replacing an access to a designer without parameters with a public one (public) and writing like this without creating unnecessary DTO and ViewModel of the same type:
[HttpPost] public ActionResult Index(Lead lead) { if (!ModelState.IsValid) { return View(lead); } //… } Under the conditions:
- Lead class is not an aggregation root
- application form has one-to-one mapping to the lead class
- no-parameter constructor protected by the Obsolete attribute
Otherwise, create a DTO and / or ViewModel and use DataMapper.
Monad Maybe
While Visual Studio 2015 comes out of CTP with new operators, this monad helps keep the code readable. Using Maybe in conjunction with JetBrains.Annotations and Possible NullReferenceException as error in R # ensures that there is no NullReferenceException in your code. In fact, this is the implementation of the NullObject pattern in a functional style.Business Logic and Infrastructure Separation (DDD)
The main controversy around DDD revolves around the following theses:- C too few publicly available examples with DDD on the network, it is not clear what it is all about
- what to consider as a domain, and what infrastructure
- DDD is very long and expensive compared to the “op-op, ready code” methodology
Reading the book of Evans was for me the second sharp turn in understanding the code, after The Art of Unit Testing . For 10 years in software development, I managed to get a good look at a large number of code bases. Thank God, already in all programming languages there is a basic platform (framework) and a package manager and it never occurs to anyone to write their MVC framework with blackjack and courtesans.
However, business logic can be found in various places of the application: in stored procedures, helperes, managers, services, telecontrollers, repositories, linq queries. In the absence of clear rules, each developer will organize the business logic in accordance with his ideas of beauty.
This creates a whole bunch of problems:
- it is not clear where to look for a business rule
- it is impossible to clearly answer the question of what is the test coverage of a domain model code,
- code to procedural style, encapsulation broken
- there is a danger of duplicating a business rule in two or more places (for example, in the c # code and stored procedure code. If requirements change, you are more likely to remember to change the rule only in one place. As a result, the discrepancy will remain and may emerge in a few months. Deal with the problem will be other people and not the fact that they know how to “must be right.” In addition, managers and helperies are classes with vague responsibility, most likely turning into God-objects with time
- dependencies between assemblies are not regulated in any way. Classes of domain models with the light hand of junior can easily begin to depend on the web context and build Common.Web
At a higher level, this translates into:
- slowing down the pace of development, down to the state when the entire full time team is busy supporting and eliminating bugs
- permanent bugfixing and crushing
- the need to allocate additional resources to support and eliminate errors in the application database
For me, Evans DDD is a way to standardize work with business logic. DDD offers a set of patterns for this. Let's look at the main ones. At the same time, let's “marry” them with another “fashionable” concept - CQRS.
How is this related to DDD?
DDD tells us theEntity
public interface IEntity { string GetId(); } An entity is anything that has a unique identifier. Two nails in the bag - not Entity, because you can not distinguish one from the other. In terms of domain, they are identical. But Vasya and Peter for our tax - Entity. They have a TIN (taxpayer identification number).
In modern applications, the auto-incrementable integer value or GUID is most often used as an Id. Despite the prevalence of this approach, in some cases it can create situations that require special handling. If you have ever bought tickets from an aggregator, then you know that the aggregator reservation number may not match the airline's reservation number. This is due to the fact that the carrier has its own IT system, and the aggregator has its own.
Let's go back to the landing page example and the lead. My most abstract IEntity implementation is a method that returns an Id as a string. I intentionally use a method, not a property. All properties of the class Lead are mapped on the database fields. This will help avoid ambiguity and the need to peek into the mapping. The primary key is Email, not Id. If I implemented the Id property, I would have to explicitly indicate that the Id property is mapped on the Email field in the database, besides that, it would create problems with other types of primary keys (integer and guid)
public class Lead : IEntity { private string _email; [Key, Required, Index("IX_Email", 1, IsUnique = true)] public string Email { get { return _email; } set { if (string.IsNullOrEmpty(value)) { throw new ArgumentNullException("value"); } _email = value; } } public string Phone { get; set; } public bool Processed { get; set; } public DateTime CreatedDate { get; set; } // IEntity Implementation public string GetId() { return Email; } I have already said that I use as the main, but not the only, ORM Entity Framework. Main reasons:
- automatic generation of migrations (saves a lot of time and frees you from writing routine code)
- best linq support in .NET
- developing faster than NHibernate
- supports DataAnnotation-attributes for data mapping and creating migrations
Fluent mapping VS Atribute mapping
The taste and color of all markers of course are different. Fluent mapping is cleaner and allows you not to drag EF depending on the domain assembly, but I do not like its verbosity and the need to support 2 classes: entities and mapping. Someone might say, they say this is a violation of the SRP. My opinion - the attributes are not imperative code and such a comparison is not correct. I see the difference only in the form of the record and the extra dependence on EF, which, however, is easily cut when necessary.Persistence ignorance
So, we have domain entities and they need to be created, processed, saved, filtered, obtained from some data source and deleted. In common people this is called CRUD-operations. We can create an entity with the help of the operator new, not forgetting that we need to use the "correct" constructor that does not violate the invariant of the object. We have declared the default constructor only for ORM support and were protected from dirty hands with the [Obsolete] attribute.How can we save an object and get it from a data source? In modern frameworks, two approaches are used: Active Record (AR) and Unit of Work (UoW). I am a categorical opponent of Active Record. It is possible that in interpreted PLs AR it gives advantages, but not in compiled ones. AR most horribly violates SRP by adding the Entity Save method to everyone. The task of Entity is to implement business logic and encapsulate data, and not to save itself in the database. Therefore, my choice is UoW.
public interface IUnitOfWork: IDisposable { void Commit(); void Save<TEntity>(TEntity entity) where TEntity : class, IEntity; void Delete<TEntity>(TEntity entity) where TEntity : class, IEntity; } For EF, the implementation of UoW will be the DataContext of your application. However, the DataContext itself will not stick into the domain assemblies. First, why do we need a dependence on EF here? Secondly, it is often enough to implement the Bounded Context in order to separate the development teams, while migration is better left within the same DataContext to eliminate the option of desynchronization of the data schema.
How to save, edit and delete is understandable. There is a function to get data. Traditionally this function is implemented using repositories. And traditionally implemented "sloppy". Details of the problem are described in the article “ problem repository pattern ”.
In short, first you do this:
public interface IRepository<T> { T GetById(int id); IEnumerable<T> GetAll(); bool Add(T entity); bool Remove(T entity); } The result is:
class AccountRepository : IRepository<Account> { public Account GetByName(string name); public Account GetByEmail(string email); public Account GetByAge(int age); public Account GetByNameAndEmail(string name, string email); public Account GetByNameOrEmail(string name, string email); // ... public Account GetByAreYouFuckingKiddingMe(SomeCriteria c); } You get out of this situation (I do not consider the option with extension-methods, for the reasons stated below):
public interface IRepository<T> { T GetById(int id); // IQueryable<T> Query(); bool Add(T entity); bool Remove(T entity); } But break off like this:
// - repo.Query().Where(a => a.IsDeleted = false); // , repo.Query().Where(a => a.IsDeleted = false && a.Balance > 0); // runtime error repo.Query().Where(a => a.CreationDate < getCurrentDate()); In the last example, the first two linq queries illustrate changes to the “active account” business rule. At first, we considered active not deleted, and then the requirement “the balance should be greater than zero” was added. Since linq queries are very easy to write, they are likely to be copied to a dozen places in the code base. Almost certainly somewhere will change, but somewhere will be forgotten.
The third example will compile perfectly, but crash at runtime because ORM will not understand how to translate your getCurrentDate function to SQL. If time is running out, and the junior has got the task, he quickly “finished” the code with a file like this:
repo.Query().ToEnumerable().Where(a => a.CreationDate < getCurrentDate()); And all 3 million accounts will rise into RAM.
There are still implicit problems with providing IQueryable to the outside:
- IQueryable “leaks” and clearly violates the LSP . The only IQueryable implementation that "digests" any exploits you feed it is in-memory. But for in-memory, you have a linq2object, which removes any meaning from IQueryable. Any where request is a potential point of failure for your code.
- linq. - , Sphinx' Elastic'. , « linq-» ( , ). , , ,
- , NOSQL-. , -, ..
The first problem is not solved in principle. This is in linq by-design. And sin to complain, linq is very convenient. Points two and three hint that IQueryable is not suitable as an abstraction for all occasions, because in the real world not all .NET developers have a half-kick to parse the expression trees and write their linq provider during the day to any data source.
Well, that all have come up with for us
Specification aka Filter
public interface ISpecification<in T> where T:IEntity { bool IsSatisfiedBy(T o); } public interface IRepository<T> { T GetById(int id); // IEnumerable<T> GetBySpecification(ISpecification<T> spec); bool Add(T entity); bool Remove(T entity); } The specification is a business filtering rule. Only one method, or the object satisfies the condition, or - no. In the current form, the specification solves the problem of duplicating the code: now you do not have Linq and you have to write your own specification class for each filter rule.
But, excuse me, why is this necessary? We cannot translate IsSatisfiedBy into SQL, which means we will have to raise all records from the database again and filter by them. Now we need to write a specification for each sneeze, and therefore create a set of classes that are used exactly once (in the interface where you need to filter the data in a certain way).
Indeed, the whole discussion is underway, they say the “specification” pattern is outdated with the advent of linq .
The first thing that astronauts offer architecture:
public interface IExpressionSpecification<T> : ISpecification<T> where T:class,IEntity { Expression<Func<T, bool>> Expression { get; } } public interface IRepository<T> { T GetById(int id); // IEnumerable<T> GetBySpecification(IExpressionSpecification<T> spec); bool Add(T entity); bool Remove(T entity); } You do not need to have super-abilities to see the same eggs, a profile view with an additional unnecessary layer in the form of a specification. Moreover, the problem of duplicating linq requests in code can be elegantly solved like this:
public class Account : IEntity { [BusinessRule] public static Expression<Func<Lead, bool>> ActiveRule = x => x.IsDeleted && x.Ballance > 0; } Eventually
- The repository will not be able to effectively use as a base abstraction for all data sources.
- linq is very convenient, but not suitable everywhere for economic reasons or performance restrictions
CQ [R] S - Command, Query [Responsibility] Segregation
Or in Russian, the division of reading and writing. The principle has found the greatest application in the loaded systems. A classic example is a feed on social networks: you need to pull data from a pile of tables for all your friends and remember to take into account how everyone likes and reposits your photos. The classic implementation is not suitable for this task - too many joins and read / write locks.The usual solution is to separate read and write to avoid blocking. Denormalization strategies may be different, but the main point comes down to:
- get rid of joins, read flat data
- avoid read / write locks
- synchronize data "in the background", accumulating changes
Thus, the classic repository is divided into two interfaces: Command and Query.
Command implements add, edit, and delete, and Query reads data.
public interface IQuery<TEntity, in TSpecification> where TEntity : class, IEntity where TSpecification : ISpecification<TEntity> { IQuery<TEntity, TSpecification> Where([NotNull] TSpecification specification); IQuery<TEntity, TSpecification> OrderBy<TProperty>( [NotNull] Expression<Func<TEntity, TProperty>> expression, SortOrder sortOrder = SortOrder.Asc); IQuery<TEntity, TSpecification> Include<TProperty>([NotNull] Expression<Func<TEntity, TProperty>> expression); [NotNull] TEntity Single(); [CanBeNull] TEntity FirstOrDefault(); [NotNull] IEnumerable<TEntity> All(); [NotNull] IPagedEnumerable<TEntity> Paged(int pageNumber, int take); long Count(); } public interface ICommand { void Execute(); } public interface ICommand<in T> { void Execute(T context); } public interface IPagedEnumerable<out T> : IEnumerable<T> { long TotalCount { get; } } public class CreateEntityCommand<T> : UnitOfWorkScopeCommand<T> where T: class, IEntity { public override void Execute(T context) { UnitOfWorkScope.GetFromScope().Save(context); UnitOfWorkScope.GetFromScope().Commit(); } public CreateEntityCommand([NotNull] IScope<IUnitOfWork> unitOfWorkScope) : base(unitOfWorkScope) { } } public class DeleteEntityCommand<T> : UnitOfWorkScopeCommand<T> where T: class, IEntity { public DeleteEntityCommand([NotNull] IScope<IUnitOfWork> unitOfWorkScope) : base(unitOfWorkScope) { } public override void Execute(T context) { UnitOfWorkScope.GetFromScope().Delete(context); UnitOfWorkScope.GetFromScope().Commit(); } } The primary responsibility of Query is to translate a specification (domain filtering rule) into a request to a data source (infrastructure). Query provides an abstraction from the data source - to us it doesn't matter where we get the data from, and the specification is a kind of linq +. For data sources that support linq, you can use ExpressionSpecification. In cases when using linq is difficult (there is no provider, for example, as in the case of Elastic Search), we throw out the Expression and use our specification.
public interface IExpressionSpecification<T> : ISpecification<T> where T:class,IEntity { Expression<Func<T, bool>> Expression { get; } } public static IQuery<TEntity, IExpressionSpecification<TEntity>> Where<TEntity>( this IQuery<TEntity, IExpressionSpecification<TEntity>> query, Expression<Func<TEntity, bool>> expression) where TEntity : class, IEntity { return query.Where(new ExpressionSpecification<TEntity>(expression)); } To filter data in RAM, you can use an instance of the specification, and the translation of the specification in the query to the data source go to Query.
ICommandFactory, IQueryFactory
Creating a large number of small command and query objects can be a tedious task; it is logical to register them in an IOC container by convention. In order not to drag your container to all assemblies and not to create a ServiceLocator, we will assign this responsibility to the factories. public interface ICommandFactory { TCommand GetCommand<TEntity, TCommand>() where TCommand : ICommand<TEntity>; T GetCommand<T>() where T : ICommand; CreateEntityCommand<T> GetCreateCommand<T>() where T : class, IEntity; DeleteEntityCommand<T> GetDeleteCommand<T>() where T : class, IEntity; } public interface IQueryFactory { IQuery<TEntity, IExpressionSpecification<TEntity>> GetQuery<TEntity>() where TEntity : class, IEntity; IQuery<TEntity, TSpecification> GetQuery<TEntity, TSpecification>() where TEntity : class, IEntity where TSpecification : ISpecification<TEntity>; TQuery GetQuery<TEntity, TSpecification, TQuery>() where TEntity : class, IEntity where TSpecification: ISpecification<TEntity> where TQuery : IQuery<TEntity, TSpecification>; } Then work with query will look like this.
_queryFactory.GetQuery<Product>() .Where(Product.ActiveRule) // , Account. ExpressionSpecification .OrderBy(x => x.Id) .Paged(0, 10) // 10 // ElasticSearch, : _queryFactory.GetQuery<Product, FullTextSpecification>() .Where(new FullTextSpecification(«»)) .All() // EF Dapper _queryFactory.GetQuery<Product, DictionarySpecification, DapperQuery>() .Where(new DictionarySpecification (someDirctionary)) .All() In all cases, we use the same code, and the _queryFactory.GetQuery construction <Product, DictionarySpecification, DapperQuery> () clearly indicates to us that this is an optimization. This line appeared in the code only in the course of evolutionary refactoring, because first we wrote on ORM, for the sake of speed of development. If there is a person in the team who is well versed in expression trees, you can gradually translate all queries to linq (although in real life it is almost impossible for economic reasons).
In the case of _queryFactory.GetQuery <Product, FullTextSpecification> (), we specify the “full-text specification”, but the domain code does not know that the returned instance is ElasticSearchQuery. For him, this is just a “full text search” filtering rule.
Controversy on the topic:habrahabr.ru/post/125720
Some syntactic sugar
Let's go back to the example: public class Account : IEntity { [BusinessRule] public static Expression<Func<Lead, bool>> ActiveRule = x => x.IsDeleted && x.Ballance > 0; bool IsActive() { // ??? } } The “active account” business rule is in a logical place and reused. No need to fear scattered throughout the project lambda.
Sometimes this requirement is needed in the form of Expression <Func <Lead, bool >> - for translation into a query to a data source, and sometimes in the form of Func <Lead, bool >> - for filtering objects in memory and providing properties like IsActive. Creating a specification class for every sneeze doesn't seem like a good idea. When can use the following implementation:
public static class Extensions { private static readonly ConcurrentDictionary<Expression, object> _cachedFunctions = new ConcurrentDictionary<Expression, object>(); public static Func<TEntity, bool> AsFunc<TEntity>(this object entity, Expression<Func<TEntity, bool>> expr) where TEntity: class, IEntity { //@see http://sergeyteplyakov.blogspot.ru/2015/06/lazy-trick-with-concurrentdictionary.html return (Func<TEntity, bool>)_cache.GetOrAdd(expr, id => new Lazy<object>( () => _cache.GetOrAdd(id, expr.Compile()))); } public static bool Is<TEntity>(this TEntity entity, Expression<Func<TEntity, bool>> expr) where TEntity: class, IEntity { return AsFunc(entity, expr).Invoke(entity); } public static IQuery<TEntity, IExpressionSpecification<TEntity>> Where<TEntity>( this IQuery<TEntity, IExpressionSpecification<TEntity>> query, Expression<Func<TEntity, bool>> expression) where TEntity : class, IEntity { return query .Where(new ExpressionSpecification<TEntity>(expression)); } } public class ExpressionSpecification<T> : IExpressionSpecification<T> where T:class,IEntity { public Expression<Func<T, bool>> Expression { get; private set; } private Func<T, bool> _func; private Func<T, bool> Func { get { return this.AsFunc(Expression); } } public ExpressionSpecification([NotNull] Expression<Func<T, bool>> expression) { if (expression == null) throw new ArgumentNullException("expression"); Expression = expression; } public bool IsSatisfiedBy(T o) { return Func(o); } } public class Account : IEntity { [BusinessRule] public static Expression<Func<Lead, bool>> ActiveRule = x => x.IsDeleted && x.Ballance > 0; bool IsActive() { this.Is(ActiveRule); } } Where are the services, the managers, and the helper?
With proper code organization, you don’t have any helper in the domain. Maybe there is something in the presentation layer. Manager and Service are the same thing, so the name Manager is better not to use at all. Service is a purely technical term. Use Service only as postfix or do not use at all (leave only the namespace in order to register by convention in the IOC).In the real business there are no “services”, there are “cash desks”, “postings”, “quotas” and all that. So it is better to group your business logic and name the classes according to the application domain and create them only as needed. CRUD operations do not need any services. The UoW + Command + Query + Specification + Validator bundles are enough to cover 90% of the accounting system needs. By the way, this requires only one controller class.
Conclusion
Such an architecture may seem overloaded. Indeed, this approach imposes certain limitations:- Qualification of developers: requires an understanding of programming patterns and a good knowledge of the platform
- initial investments in the infrastructure code (it took me almost 4 days to complete the full time in order to pull interfaces out of my projects, untie unnecessary dependencies and make the infrastructure as abstract and lightweight as possible, a lot of code went under the knife)
- it is this assembly that is still being tested in a real project, I have no metrics on hand and guarantees that this approach gives a performance benefit due to standardization (although subjectively, I am 100% sure of this)
Benefits
- clear separation of the domain from the infrastructure
- , , , , ,
- -
- repair-kit
- ,
To be continued...
Source: https://habr.com/ru/post/259829/
All Articles