As I was increasing machine learning conversion
In this article I will try to answer these questions:
The answer to the first question will be the most concise - "yes." After hearing this bobuk performance at YaC / M, I admired the elegance of the approach and wondered how to implement a similar solution. I then worked as a product manager in the company Wargaming and was just engaged in the so-called. user acquisition services - technological solutions to attract users, which included a system for A / B testing of landings. So the grain lay on fertile soil.
Unfortunately, for all reasons I could not tightly engage in this project in the normal operating mode. But when I burned out a bit at work and decided to make myself a long creative vacation, my obsession turned into a desire to make such a service of intelligent landing page rotation on my own.
The concept of the service was quite simple: at the prototype stage, I decided to limit myself to a router that would predict a conversion for each new user on different landings and send it to the best. All whistles postponed for later, because it was necessary to hone the predictive technology first.

')
The level of my knowledge of machine learning was somewhere between "absent" and "scarce". Because I had to start with a minimum educational program:
Python was a good fit for implementation, since on the one hand, it is a general-purpose language, on the other - its ecosystem has generated quite a few data libraries (in particular, scikit-learn, pandas, Lasagne came in handy to me). For web wrappers, I used Django - this is clearly a non-optimal choice, but on the other hand, this did not require additional time to master the new framework. Looking ahead, I note that there were no problems with Django speed, and on my relatively small load up to 3000 RPM server requests were processed for 20-30 ms.

What happens if you suddenly connect to the test client with a large amount of traffic.
Workflow was this:
To select the best landing pages, you need to start to find the right classifier. For each project (a set of landing pages for one client), the classifiers would most likely differ, so I needed:
The undoubted advantage was that it is possible to train classifiers in the background, regardless of the part of the system that directly assigned users to the landings. For example, at the beginning of the experiments, users were distributed in the a / b test mode in order to simultaneously collect data for training the model and not to spoil the existing conversion.
Learning a classifier with scikit-learn is a fairly simple thing. It is enough first to vectorize the data with the help of DictVectorizer from scikit-learn, divide the sample into training and test, train the classifier, make predictions and evaluate their accuracy.
And something like this - transformed into the numpy array:
By the way, for many classification methods it is more rational to leave the data in the form of a sparse-matrix, and not a numpy array, since This reduces memory consumption.
The result to be predicted from this data is a list of zeros (no conversion has happened) and units (hooray, the user has registered!).
Let's make the simplest logistic regression:
Let's estimate the quality of predictions. The choice of the evaluation criterion is perhaps the most difficult part of the project. Intuitively, it seems that there is no need to invent anything and it is enough to estimate the proportion of correct predictions, but this is an incorrect approach. The simplest counterargument: if our landings have an average conversion of 1%, then the most stupid classifier, predicting the lack of conversion for any user, will show 99% accuracy.
For binary classification problems, such metrics as f1-score or Matthews coefficient are often used. But in my case, it is not so much the correctness of the binary prediction that is important (conversion happens or not), but how close the predicted probability is. In such cases, you can use the ROC AUC score or log_loss ; If you study similar tasks on Kaggle (for example, the Avazu or Avito contest), you can see that it is these metrics that are often used.
Hmm, the quality is so-so. Why not try to iterate over the hyperparameters of the model? For this, scikit-learn also has a ready-made tool - the grid_search module and the GridSearchCV classes for brute force and RandomizedSearchCV for many random selections (useful if the number of possible options is too large).
This code snippet, like the others, is simplified as much as possible for clarity: for example, it is recommended to transfer scipy.stats distributions, not lists, as numeric parameters for iteration into RandomizedSearchCV.
In principle, it would be possible not to stop at what has been accomplished and fasten genetic algorithms to this happiness. But it seems that the quality of predictions is already becoming more or less adequate:
Unfortunately, there is no clear criterion when the model is already good or still needs tuning. The possibilities for tuning are endless: you can add polynomial combinations of features, you can construct features based on existing ones (for example, determine the topics of the referrer site). However, when various kinds of manipulations no longer give a tangible effect, it is time to proceed to the next stage, otherwise you can spend a lot of time improving the classifier by another 0.00001%.
After the hyperparameters are defined, the classifier can be trained on the entire sample and put in the cache for quick access.
So, we have some working classifiers. It's time for production! Just before that, you need to decide what is good and what is bad - no longer from the point of view of mathematics and machine learning, but for business.
Since the whole project is about increasing the conversion, you must again arrange the A / B test. More precisely, the metattest:
Depla, discussion of the launch with test clients, debugging minor bugs - and you can look forward to the result.
For me personally, the most unpleasant thing in the process of A / B tests is intermediate results. The situation regularly happens that at first one option gets ahead, it seems that a good result has been achieved, although there is still no statistical significance. After some time, the data becomes more, and comes the understanding that everything is not so rosy.
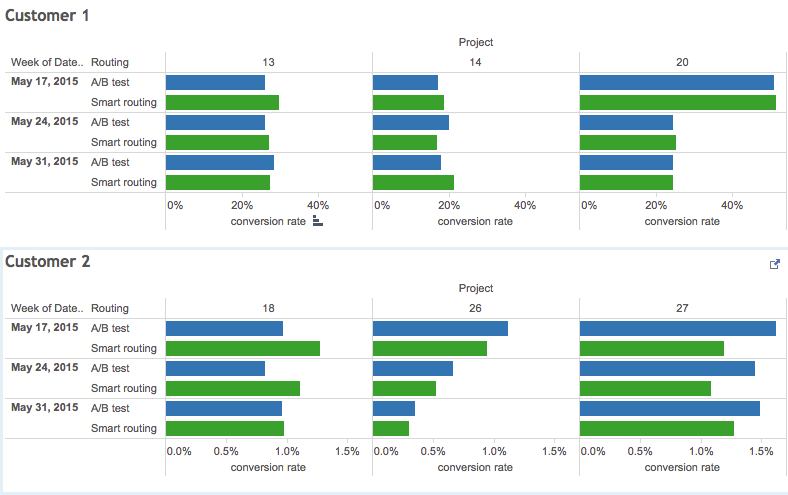
It was about the same this time. “Smart” routing with the help of classifiers first got ahead, and then the results were almost equal to the multi-armed gangster. Both models of a choice of a landing proved to be approximately equally effective, having left random behind (it is not surprising). Only one of the six experiments showed a statistically significant advantage of such routing over the A / B test.
Separately, I want to note that I did not notice any correlation between the quality of the classifier (ROC AUC / log_loss) and conversion, which made it very difficult to somehow improve the situation.
More relevant is the question, can this technology bring tangible benefits, and not fluctuate on the verge of statistical error? I cannot confirm or disprove this hypothesis, but it looks as if such an approach with machine learning may be useful when working with the whole chain of attracting users.
Probably, if you make a variety of landings (I tested the system on very similar pages), integrate more data sources (ad network macros, client CRM and even DMP), the technology may be useful and increase the conversion in situations where usual a / b tests do not give effect. To make a silver bullet, so that anyone who wants to get on level ground + N% conversion from existing pages without thoughtful work is more likely unrealistic.
Some scikit-learn classifiers (in particular, based on decision trees) have an interesting attribute feature_importances_, which shows the weight of a particular attribute for the final prediction. My test classifiers rarely gave a selected landing page a weight of more than 2% and have never broken the threshold of 5%. At the same time, such parameters as country, referrer and browser could select 20-25% for themselves. I tend to interpret it this way: the importance of a good landing page is somewhat exaggerated, and working with targeting in an advertising campaign could have been better.
Nevertheless, if among the readers there are those who wish to try my development on their project, write, I will be happy to conduct some more joint experiments. For the test, you will need several options for transactional pages and a sufficient number of users (from 10 thousand).
I plan to finish my sabbatical on this and return to normal work, therefore I would like to know the opinion of the community about the relevance of such a project in order to reach a logical conclusion.
- Can one report from an intelligent person make another person obsessed?
- how to dip into machine learning (almost) from scratch?
- why not underestimate the many-armed gangsters?
- Is there a silver bullet for a / b tests?
The answer to the first question will be the most concise - "yes." After hearing this bobuk performance at YaC / M, I admired the elegance of the approach and wondered how to implement a similar solution. I then worked as a product manager in the company Wargaming and was just engaged in the so-called. user acquisition services - technological solutions to attract users, which included a system for A / B testing of landings. So the grain lay on fertile soil.
Unfortunately, for all reasons I could not tightly engage in this project in the normal operating mode. But when I burned out a bit at work and decided to make myself a long creative vacation, my obsession turned into a desire to make such a service of intelligent landing page rotation on my own.
What is it all about?
The concept of the service was quite simple: at the prototype stage, I decided to limit myself to a router that would predict a conversion for each new user on different landings and send it to the best. All whistles postponed for later, because it was necessary to hone the predictive technology first.
')
The level of my knowledge of machine learning was somewhere between "absent" and "scarce". Because I had to start with a minimum educational program:
- “We program the collective mind ”;
- Mastering Machine Learning With scikit-learn ;
- scikit-learn Cookbook ;
- classic course on Coursera from Andrew Ng ;
- scikit-learn documentation (perhaps the most valuable source of information);
Python was a good fit for implementation, since on the one hand, it is a general-purpose language, on the other - its ecosystem has generated quite a few data libraries (in particular, scikit-learn, pandas, Lasagne came in handy to me). For web wrappers, I used Django - this is clearly a non-optimal choice, but on the other hand, this did not require additional time to master the new framework. Looking ahead, I note that there were no problems with Django speed, and on my relatively small load up to 3000 RPM server requests were processed for 20-30 ms.
What happens if you suddenly connect to the test client with a large amount of traffic.
Workflow was this:
- user comes to the router;
- the service collects the maximum amount of information about it (since at the prototype stage it would be foolish to integrate with information providers like DMP, I started with technical data — HTTP headers, geolocation, screen resolution, etc.);
- classifier predicts conversion on possible landing options;
- the router gives 302 Redirect to a potentially better landing page.
Classifying classifiers
To select the best landing pages, you need to start to find the right classifier. For each project (a set of landing pages for one client), the classifiers would most likely differ, so I needed:
- to train a number of classifiers on historical data, selecting hyper parameters ;
- choose the best classifier at the moment;
- periodically repeat this operation.
The undoubted advantage was that it is possible to train classifiers in the background, regardless of the part of the system that directly assigned users to the landings. For example, at the beginning of the experiments, users were distributed in the a / b test mode in order to simultaneously collect data for training the model and not to spoil the existing conversion.
Learning a classifier with scikit-learn is a fairly simple thing. It is enough first to vectorize the data with the help of DictVectorizer from scikit-learn, divide the sample into training and test, train the classifier, make predictions and evaluate their accuracy.
This is the basic data:
(part of key-value pairs removed)
[{'1_lang': 'pl-PL', 'browser_full': 'IE8', 'country': 'Poland', 'day': '5', 'hour': '9', 'is_bot': False, 'is_mobile': False, 'is_pc': True, 'is_tablet': False, 'is_touch_capable': False, 'month': '6', 'os': 'Windows 7', 'timezone': '+0200', 'utm_campaign': '11766_', 'utm_medium': '543', 'used_landing' : '1' }, {'1_lang': 'en-US', 'REFERER_HOST': 'somedomain.com', 'browser': 'Firefox', 'browser_full': 'Firefox38', 'city': 'Raleigh', 'country': 'United States', 'day': '5', 'hour': '3', 'is_bot': False, 'is_mobile': False, 'is_pc': True, 'is_tablet': False, 'is_touch_capable': False, 'month': '6', 'os': 'Windows 8.1', 'timezone': '-0400', 'utm_campaign': 'pff_r.search.yahoo.com', 'utm_medium': '1822', 'used_landing' : '2' }, ..., {'1_lang': 'ru-RU', 'HTTP_REFERER': 'somedomain.ru', 'browser': 'IE', 'browser_full': 'IE11', 'screen': '1280x960x24', 'country': 'Ukraine', 'day': '5', 'hour': '7', 'is_bot': False, 'is_mobile': False, 'is_pc': True, 'is_tablet': False, 'is_touch_capable': False, 'month': '6', 'os': 'Windows 7', 'timezone': 'N/A', 'utm_campaign': '62099', 'utm_medium': '1077', 'used_landing' : '1' }] (part of key-value pairs removed)
And something like this - transformed into the numpy array:
[[ 0. 0. 0. ..., 0. 0. 1.] [ 0. 0. 0. ..., 0. 0. 1.] [ 0. 0. 0. ..., 0. 1. 0.] ..., [ 0. 0. 0. ..., 0. 1. 0.] [ 0. 0. 0. ..., 0. 0. 1.] [ 0. 0. 0. ..., 0. 0. 1.]] By the way, for many classification methods it is more rational to leave the data in the form of a sparse-matrix, and not a numpy array, since This reduces memory consumption.
The result to be predicted from this data is a list of zeros (no conversion has happened) and units (hooray, the user has registered!).
from sklearn.feature_extraction import DictVectorizer from sklearn.cross_validation import train_test_split import json clicks = Click.objects.filter(project=42) # deserializing data stored as json X = DictVectorizer().fit_transform([json.loads(x.data) for x in clicks]) Y = [1 if click.conversion_time else 0 for click in clicks] # getting train and test subsets for model fitting and scoring X1, X2, Y1, Y2 = train_test_split(X, Y, test_size=0.3) Let's make the simplest logistic regression:
from sklearn.linear_model import LogisticRegression clf = LogisticRegression(class_weight='auto') clf.fit(X1, Y1) predicted = clf.predict(X2) Let's estimate the quality of predictions. The choice of the evaluation criterion is perhaps the most difficult part of the project. Intuitively, it seems that there is no need to invent anything and it is enough to estimate the proportion of correct predictions, but this is an incorrect approach. The simplest counterargument: if our landings have an average conversion of 1%, then the most stupid classifier, predicting the lack of conversion for any user, will show 99% accuracy.
For binary classification problems, such metrics as f1-score or Matthews coefficient are often used. But in my case, it is not so much the correctness of the binary prediction that is important (conversion happens or not), but how close the predicted probability is. In such cases, you can use the ROC AUC score or log_loss ; If you study similar tasks on Kaggle (for example, the Avazu or Avito contest), you can see that it is these metrics that are often used.
In [21]: roc_auc_score(Y2, clf.predict(X2)) Out[21]: 0.76443388650963591 Hmm, the quality is so-so. Why not try to iterate over the hyperparameters of the model? For this, scikit-learn also has a ready-made tool - the grid_search module and the GridSearchCV classes for brute force and RandomizedSearchCV for many random selections (useful if the number of possible options is too large).
from sklearn.metrics import roc_auc_score, make_scorer from sklearn.grid_search import RandomizedSearchCV clfs = ((DecisionTreeClassifier(), {'max_features': ['auto', 'sqrt', 'log2', None], 'max_depth': range(3, 15), 'criterion': ['gini', 'entropy'], 'splitter': ['best', 'random'], 'min_samples_leaf': range(1, 10), 'class_weight': ['auto'], 'min_samples_split': range(1, 10), }), (LogisticRegression(), {'penalty': ['l1', 'l2'], 'C': [x / 10.0 for x in range(1, 50)], 'fit_intercept': [True, False], 'class_weight': ['auto'], }), (SGDClassifier(), {'loss': ['modified_huber', 'log'], 'alpha': [1.0 / 10 ** x for x in range(1, 6)], 'penalty': ['l2', 'l1', 'elasticnet'], 'n_iter': range(4, 12), 'learning_rate': ['constant', 'optimal', 'invscaling'], 'class_weight': ['auto'], 'eta0': [0.01], })) for clf, param in clfs: logger.debug('Parameters search started for {0}'.format(clf.__class__.__name__)) grid = RandomizedSearchCV(estimator=clf, param_distributions=param, scoring=make_scorer(roc_auc_score), n_iter=200, n_jobs=2, iid=True, refit=True, cv=2, verbose=0, pre_dispatch='2*n_jobs', error_score=0) grid.fit(X, Y) logger.info('Best estimator is {} with score {} using params {}'.format(clf.__class__.__name__, grid.best_score_, grid.best_params_)) This code snippet, like the others, is simplified as much as possible for clarity: for example, it is recommended to transfer scipy.stats distributions, not lists, as numeric parameters for iteration into RandomizedSearchCV.
In principle, it would be possible not to stop at what has been accomplished and fasten genetic algorithms to this happiness. But it seems that the quality of predictions is already becoming more or less adequate:
In [27]: roc_auc_score(Y2, clf.predict(X2)) Out[27]: 0.95225886338947252 Unfortunately, there is no clear criterion when the model is already good or still needs tuning. The possibilities for tuning are endless: you can add polynomial combinations of features, you can construct features based on existing ones (for example, determine the topics of the referrer site). However, when various kinds of manipulations no longer give a tangible effect, it is time to proceed to the next stage, otherwise you can spend a lot of time improving the classifier by another 0.00001%.
After the hyperparameters are defined, the classifier can be trained on the entire sample and put in the cache for quick access.
From sandbox to production
So, we have some working classifiers. It's time for production! Just before that, you need to decide what is good and what is bad - no longer from the point of view of mathematics and machine learning, but for business.
Since the whole project is about increasing the conversion, you must again arrange the A / B test. More precisely, the metattest:
- Part of the traffic will be distributed between the landing pages randomly;
- for the part, the A / B test will work on the simplest model of a multi-armed bandit ;
- and finally, the remaining traffic will be distributed using classifiers.
Depla, discussion of the launch with test clients, debugging minor bugs - and you can look forward to the result.
For me personally, the most unpleasant thing in the process of A / B tests is intermediate results. The situation regularly happens that at first one option gets ahead, it seems that a good result has been achieved, although there is still no statistical significance. After some time, the data becomes more, and comes the understanding that everything is not so rosy.
It was about the same this time. “Smart” routing with the help of classifiers first got ahead, and then the results were almost equal to the multi-armed gangster. Both models of a choice of a landing proved to be approximately equally effective, having left random behind (it is not surprising). Only one of the six experiments showed a statistically significant advantage of such routing over the A / B test.
Separately, I want to note that I did not notice any correlation between the quality of the classifier (ROC AUC / log_loss) and conversion, which made it very difficult to somehow improve the situation.
Is there life on Mars?
More relevant is the question, can this technology bring tangible benefits, and not fluctuate on the verge of statistical error? I cannot confirm or disprove this hypothesis, but it looks as if such an approach with machine learning may be useful when working with the whole chain of attracting users.
Probably, if you make a variety of landings (I tested the system on very similar pages), integrate more data sources (ad network macros, client CRM and even DMP), the technology may be useful and increase the conversion in situations where usual a / b tests do not give effect. To make a silver bullet, so that anyone who wants to get on level ground + N% conversion from existing pages without thoughtful work is more likely unrealistic.
Some scikit-learn classifiers (in particular, based on decision trees) have an interesting attribute feature_importances_, which shows the weight of a particular attribute for the final prediction. My test classifiers rarely gave a selected landing page a weight of more than 2% and have never broken the threshold of 5%. At the same time, such parameters as country, referrer and browser could select 20-25% for themselves. I tend to interpret it this way: the importance of a good landing page is somewhat exaggerated, and working with targeting in an advertising campaign could have been better.
Nevertheless, if among the readers there are those who wish to try my development on their project, write, I will be happy to conduct some more joint experiments. For the test, you will need several options for transactional pages and a sufficient number of users (from 10 thousand).
I plan to finish my sabbatical on this and return to normal work, therefore I would like to know the opinion of the community about the relevance of such a project in order to reach a logical conclusion.
Source: https://habr.com/ru/post/259771/
All Articles