How to identify duplicate pictures using PHP
In any project, the human factor has not been canceled, and if users upload pictures to the site themselves, duplicates cannot be avoided. When it comes to thousands of files, it’s not through the eyes of everything, and repeated pictures are not only unnecessary, they also take up space, spend resources and eventually slow down the work.

Therefore, sooner or later the question arises of automating the process of searching for repetitions, and here we will consider the main ones, as well as try it out.
One way to identify duplicates is to compare files by generating a hash value from the contents of a given file.
')
A simple example of an image hash calculation:
The result looks like this: bff8b4bc8b5c1c1d5b3211dfb21d1e76
If the hashes of the two images match, the images are the same.
The method is far from the most accurate, since it works only for identical pictures, with the slightest difference - zero sense.
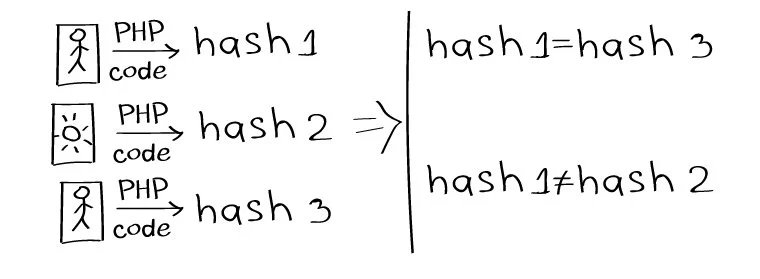
Imagick :: compareImages image processing function returns an array that contains the reconstructed image and the difference between images.
Example of use when comparing two images:
As a result, two compared pictures are molded into one, on which differences are visible.
You can also get a numeric expression of differences for each parameter (example from off.site ):
To quickly find duplicates, you must install the gd2 and libpuzzle libraries .
Installation:
Libpuzzle is designed to quickly find visual similarity of images ( GIF , PNG , JPEG ). First, the raster image is divided into blocks - the frames that do not carry particularly relevant information are automatically discarded. The difference between adjacent blocks forms a vector - this is the so-called image caption. The similarity of the pictures is determined by the distance between two such vectors. Therefore, usually a change in color, resize or compression does not affect the results produced by libpuzzle.

Libpuzzle is quite easy to use. Signature calculation for two images:
Calculating the distance between signatures:
Image verification for similarity:
Compress signatures to be stored in the database:
Most likely, the most accurate way to find duplicates is by comparing files through a perceptual hash . Check for similarity is carried out by counting the number of different positions between two hashes, this is Hamming distance . The smaller the distance, the greater the coincidence.

It differs from the first method in that it indicates not only the sameness / dissimilarity, but also the degree of difference. More information about this principle can be found in a good translation .
Installation for UNIX platforms looks like this:
You can actually try through i.onthe.io/phash . Upload images through the interface and output indicator of "sameness".
We get the hash of the first image:
We get the hash of the second image:
We get the Hamming distance between two images:
We have done almost all possible manipulations with the same photo in order to check which changes make it difficult to determine duplicates via pHash, and which ones don’t.
For example, when mirroring - the picture remains unrecognized .
But with flowers you can play as much as you want - it will not affect the result of the comparison .
What can not be said about the manipulation of RGB channels, John again did not know , although the Hamming distance for such a case is much less.
The remaining results look like this:
* depends on the size of the cropped area. When cutting a small frame several pixels thick from the picture, the Hamming distance will be zero, hence the similarity is 100%. But the tangible the crop - the greater the distance - the less chance of finding a duplicate. You can read about searching for duplicate duplicates through perceptual hashes here .
** the same as with a crop. When turning a couple of degrees, the distance is insignificant, but the greater the angle of inclination - the greater the difference.
Therefore, sooner or later the question arises of automating the process of searching for repetitions, and here we will consider the main ones, as well as try it out.
Comparing files through the hash function
One way to identify duplicates is to compare files by generating a hash value from the contents of a given file.
')
A simple example of an image hash calculation:
<?php imagecreatefrompng('image.png'); echo hash_file('md5', 'image.png'); ?> The result looks like this: bff8b4bc8b5c1c1d5b3211dfb21d1e76
If the hashes of the two images match, the images are the same.
The method is far from the most accurate, since it works only for identical pictures, with the slightest difference - zero sense.
Imagemagick
Imagick :: compareImages image processing function returns an array that contains the reconstructed image and the difference between images.
Example of use when comparing two images:
<?php header("Content-Type: image/png"); $image1 = new imagick("image1.png"); $image2 = new imagick("image2.png"); $result = $image1->compareImages($image2, Imagick::METRIC_MEANSQUAREERROR); $result[0]->setImageFormat("png"); echo $result[0]; ?> As a result, two compared pictures are molded into one, on which differences are visible.
You can also get a numeric expression of differences for each parameter (example from off.site ):
-> compare -verbose -metric mae rose.jpg reconstruct.jpg difference.png Image: rose.jpg Channel distortion: MAE red: 2282.91 (0.034835) green: 1853.99 (0.0282901) blue: 2008.67 (0.0306503) all: 1536.39 (0.0234439) gd2 and libpuzzle
To quickly find duplicates, you must install the gd2 and libpuzzle libraries .
Installation:
apt-get install libpuzzle-php php5-gd Libpuzzle is designed to quickly find visual similarity of images ( GIF , PNG , JPEG ). First, the raster image is divided into blocks - the frames that do not carry particularly relevant information are automatically discarded. The difference between adjacent blocks forms a vector - this is the so-called image caption. The similarity of the pictures is determined by the distance between two such vectors. Therefore, usually a change in color, resize or compression does not affect the results produced by libpuzzle.
Libpuzzle is quite easy to use. Signature calculation for two images:
$cvec1 = puzzle_fill_cvec_from_file('img1.jpg'); $cvec2 = puzzle_fill_cvec_from_file('img2.jpg'); Calculating the distance between signatures:
$d = puzzle_vector_normalized_distance($cvec1, $cvec2); Image verification for similarity:
if ($d < PUZZLE_CVEC_SIMILARITY_LOWER_THRESHOLD) { echo "Pictures are looking similar\n"; } else { echo "Pictures are different, distance=$d\n"; } Compress signatures to be stored in the database:
$compress_cvec1 = puzzle_compress_cvec($cvec1); $compress_cvec2 = puzzle_compress_cvec($cvec2); Perceptual Hash
Most likely, the most accurate way to find duplicates is by comparing files through a perceptual hash . Check for similarity is carried out by counting the number of different positions between two hashes, this is Hamming distance . The smaller the distance, the greater the coincidence.
It differs from the first method in that it indicates not only the sameness / dissimilarity, but also the degree of difference. More information about this principle can be found in a good translation .
Installation for UNIX platforms looks like this:
$ ./phpize $ ./configure [--with-pHash=...] $ make $ make test $ [sudo] make install You can actually try through i.onthe.io/phash . Upload images through the interface and output indicator of "sameness".
How it works
We get the hash of the first image:
$phash1 = ph_dct_imagehash($file1); We get the hash of the second image:
$phash2 = ph_dct_imagehash($file2); We get the Hamming distance between two images:
$dist = ph_image_dist($phash1,$phash2); We have done almost all possible manipulations with the same photo in order to check which changes make it difficult to determine duplicates via pHash, and which ones don’t.
For example, when mirroring - the picture remains unrecognized .
But with flowers you can play as much as you want - it will not affect the result of the comparison .
What can not be said about the manipulation of RGB channels, John again did not know , although the Hamming distance for such a case is much less.
The remaining results look like this:
| Do not interfere (Hamming distance = 0) | Interfere (Hamming distance - in brackets) |
|---|---|
| Modified file name | Crop (34) * |
| Format (JPEG, PNG, GIF) | Rotate 90 ° (32) ** |
| Google PageSpeed Optimization | Mirror Image (36) |
| Resize with preservation of proportions and without | Changing the position of the curves in the RGB-channels (18) |
| Changing colors and clarity |
* depends on the size of the cropped area. When cutting a small frame several pixels thick from the picture, the Hamming distance will be zero, hence the similarity is 100%. But the tangible the crop - the greater the distance - the less chance of finding a duplicate. You can read about searching for duplicate duplicates through perceptual hashes here .
** the same as with a crop. When turning a couple of degrees, the distance is insignificant, but the greater the angle of inclination - the greater the difference.
Abstract
- To compare images, use ImageMagick , and to search for completely identical ones, use the hash comparison.
- To find slightly modified images, use the libpuzzle library.
- Comparison through perceptual hash is one of the most reliable, you can try it here .
Source: https://habr.com/ru/post/259549/
All Articles