Sudden sofa of a leopard coloring
If you are interested in artificial intelligence and other recognition, you probably already saw this picture:

And if you have not seen it, then these are the results of Hinton and Krizhevsky according to the ImageNet-2010 classification by a deep convolutional network
Let's take a look at its right corner, where the algorithm identified the leopard with reasonable confidence, placing the jaguar and the cheetah in the second and third place by a large margin.
')
This is generally quite a curious result, if you think about it. Because ... let's say you know how to distinguish one big spotted cat from another big spotted cat? I, for example, no. Surely there are some zoological, rather subtle differences, such as general slimness / massiveness and body proportions, but we are still talking about a computer algorithm that still make some kind of mistakes that are stupid enough from a human point of view. How does he do it, damn it? Maybe there is something related to the context and background (leopard is more likely to be found on a tree or in the bushes, and a cheetah in the savannah)? In general, when I first thought about this particular result, it seemed to me that it is very cool and powerful, intelligent machines are just around the corner waiting for us, long live deep learning and all that.
So, in fact, everything is completely wrong.
So let's look at our cats a little closer. This is the jaguar:

The biggest cat on the continents of both Americas, with the only one that periodically kills the victim by piercing the scalp with the fangs and biting into the brain. This is not a zoological fact that is important for our topic, but nonetheless. Among the characteristic signs are eye color, large jaw and in general they are the most massive of the whole trio. As you can see, quite subtle details.
Here it is - a leopard:

He lives in Africa, second only to a lion on this continent. They have light (yellow) eyes, and significantly smaller paws than the jaguar.
And finally, the cheetah:

Perceptibly smaller in size than his two fellows. It has a long, slender body, and at last at least something that can serve as a visually noticeable sign - a distinctive pattern on the face, similar to a dark path of tears from one eye to the other.
And here he is the same zoological fact: it turns out that the spots on the skin of these cats are not at all randomly located. They are assembled in several pieces in small groups, which are called "sockets". Moreover, the leopard has conditionally small sockets, the jaguar has much more (and with small black dots inside), and the cheetah does not have them at all - just a scattering of lonely standing spots.

Here it is seen better. Spontaneous education sponsor is Imgur , and I apologize in case I misrepresented something from the materiel.
Somewhere at that moment a terrible guess starts to sneak into the brain - what if this difference in the texture of the spots is the main criterion by which the algorithm distinguishes three possible recognition classes from each other? That is, in fact, the convolutional network does not pay attention to the shape of the depicted object, the number of paws, the thickness of the jaw, the peculiarities of the posture and all these subtle differences that, as we have assumed, it can understand - and simply compares the pictures as two pieces of texture?
This assumption needs to be verified. Let's take to check a simple, unsophisticated image, without any noise, distortion and other factors that complicate the life of recognition. I am sure that at first sight any person can easily recognize this picture.

For the test, we will use Caffe and the tutorial on recognition on pre-trained models, which lies right on their website. Here we are using not the same model, which is mentioned at the beginning of the post, but similar (CaffeNet), and in general for our purposes all convolution networks will show approximately the same result.
What happened:


Oops.
But hey, maybe this is a problem of a single model? Let's do more checks:
Clarifai
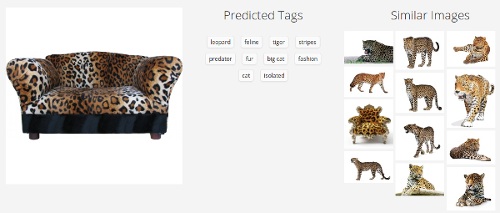
Steven Wolfram's recent mega-service
Here the picture is turned to the side - this means that the service coped with the correctly oriented sofa, but it broke when turning 90 degrees. In a sense, it is even worse than if he could not cope at all - such a simple transformation should not radically change the result. It seems that our guess about the texture is close to the truth.
Surprisingly, there are not so many open web recognition services. I made a couple of checks ( Microsoft , Google ) - some of them behave better without slipping a jaguar, but no one could win the sofa. A good result in a world where headlines in the spirit of "{Somebody} 's Deep Learning Project Outperforms Humans In Image Recognition" are already flashing.
Here is one of the guesses. Let's imagine ourselves in the place of an ordinary supervised classifier, without going into details of the architecture. We receive many, many pictures at the entrance, each of which is marked with the corresponding class, and further we adjust our parameters so that for each picture the output data correspond to this very class. Thus, we hope to extract some internal structure, distinctive features from the image, to formulate an analytically inexpressible recognition rule - so that later new, unfamiliar images that have these characteristics fall into the desired class. In the process of learning, we are guided by the magnitude of our prediction error, and here the size and proportions of the sample are important - if we have 99 images of class A and one image of class B, then at the very stupid behavior of the classifier (“always say A”) the error will be equal to 1 %, despite the fact that we especially have not learned anything.
So, from this point of view, there is no problem here. The algorithm behaves as it should behave. The sudden leopard sofa is an anomaly, a rarity in the ImageNet sample, and in our everyday experience too. On the other hand, the distinctive pattern of dark spots on a light background is a wonderful distinguishing feature of large spotted cats. Where else in the end will you see such a pattern? Moreover, taking into account that the classifier is charged with devilishly difficult tasks in the spirit of distinguishing different types of cats - the use of the pattern becomes even greater. If we had enough of the number of leopard sofas in the sample, he would have to invent new criteria for the difference (I wonder what the result would be), but if there are none, then the error in such a rare case is completely natural.
Or not?
Remember the first school classes when you were learning to write numbers.
Each of the students was then brought in a weighty book called “MNIST database”, where sixty thousand numbers were written out on hundreds of pages, all with different handwritings and styles, bold and slightly noticeable italics. Especially stubborn reached the even more huge application “Permutation MNIST”, where these same figures were rotated at different angles, stretched up and down and to the sides, and shifted right and left - without this it was impossible to learn how to determine the figure by looking at it at an angle. Then, when the long and tedious training ended, everyone was given a small (comparatively) list of 10,000 digits, which had to be correctly identified in the general class testing. But after mathematics came the next lesson, where you had to learn a much more voluminous alphabet ...
Hm Say, it was all wrong?
It is curious, but it seems that you and I do not really need a sample in the learning process. At least, if it is needed, then not for the purpose of why it is used now when training classifiers — to develop resistance to spatial permutations and distortions. We perceive the same handwritten numbers as abstract Platonic concepts - a vertical stick, two circles one above the other. If, for example, we get an image where there is none of these concepts, we will reject it as “not a digit”, but the supervised classifier will never do that. Our computer algorithms do not look for concepts - they rake up a pile of data, stuffing them into heaps, and in the end every picture should end up in a handful with which it has a little more in common than with the others.
Have you seen leopards in your life? Maybe decently, but certainly less than the "glasses", "computers" and "persons" (other classes from ImageNet). Have you ever met sofas of this color? For example, I almost never think. And yet, none of those who read this text thought for a moment before correctly classifying the above picture.

Convolutional networks constantly show consistently high results in competitions based on ImageNet, and as of 2014, they seem to be second only to ensembles from convolutional networks. You can read about them in more detail in many places - for now we will limit ourselves only to the fact that these are networks that form small “filters” (or kernels) in the learning process by which they go over the image, activating in those places where there is an element corresponding to a particular filter. They are very fond of using them when recognizing images - firstly, because there are often local signs that can appear in different places of the picture, and secondly, because it is significantly computationally cheaper than cramming huge (1024x768 = ~ 800,000 parameters) picture in a regular network.
Let's imagine our leopards again. These are quite complex physical bodies that can take a bunch of different positions in space, and also photographed from different angles. Each picture of a leopard is likely to contain a unique, almost non-repeating outline - somewhere you can see a mustache, paws and a tail, and somewhere only a slurred back. In such situations, the convolutional network is simply our savior, because instead of trying to come up with one rule for this whole set of forms, we simply say "take this set of small distinctive signs, run them through the picture and summarize the number of matches." Naturally, the texture of leopard spots becomes a good sign - it exists in many places, and practically does not change when the object's position changes. That is why models like CaffeNet perfectly respond to spatial variations of objects in the pictures - and that is why, ahem, the sofa happens to them.
This is actually a very unpleasant property. Refusing to fully analyze the shape of an object in the picture, we begin to perceive it simply as a set of signs, each of which can be anywhere without any connection with the others. Using convolutional nets, we immediately refuse to distinguish between a cat sitting on the floor and an inverted cat sitting on the ceiling. This is good and great when recognizing individual pictures somewhere on the Internet, but if such computer vision coordinates your behavior in real life, it will not be great at all.
If this argument does not sound very convincing to you, take a look at Hinton’s article , which has been around for several years, and where the phrase “convolutional networks are doomed” sounds distinctly - for this very reason. The main part of the article is devoted to the development of an alternative concept - “capsule theory” (on which he is working right now ), and is also very worthwhile to read.
Think about it for a while (and not very seriously) - we are doing everything wrong.
Stuffing huge datasets with pictures, annual competitions, even deeper networks, even more GPUs. We improved the recognition of MNIST digits from an error of 0.87 to 0.23 ( proof ) - in three years (no one still knows exactly what kind of mistake a person can make). In ImageNet Challenges, the competitors' account goes to tenths of a percent - it seems, here is a little bit more, and we will definitely win, and we will get real computer vision. And yet at the same time - no. All that we are doing is trying to scatter a bunch of pictures into categories as accurately as possible, without understanding this (I realize that the word “understand” is dangerous to use here, but) what is depicted on them. Something must be different. Our algorithms should be able to determine the spatial position of the object, and still rotated on the side of the sofa still recognize as a sofa, but with a slight warning on the topic "owner, you take out the furniture." They should be able to learn quickly, with just a few examples - like you and me - and not require multi-class sampling while extracting the necessary attributes from the objects themselves.
In general, we clearly have something to do.
And if you have not seen it, then these are the results of Hinton and Krizhevsky according to the ImageNet-2010 classification by a deep convolutional network
Let's take a look at its right corner, where the algorithm identified the leopard with reasonable confidence, placing the jaguar and the cheetah in the second and third place by a large margin.
')
This is generally quite a curious result, if you think about it. Because ... let's say you know how to distinguish one big spotted cat from another big spotted cat? I, for example, no. Surely there are some zoological, rather subtle differences, such as general slimness / massiveness and body proportions, but we are still talking about a computer algorithm that still make some kind of mistakes that are stupid enough from a human point of view. How does he do it, damn it? Maybe there is something related to the context and background (leopard is more likely to be found on a tree or in the bushes, and a cheetah in the savannah)? In general, when I first thought about this particular result, it seemed to me that it is very cool and powerful, intelligent machines are just around the corner waiting for us, long live deep learning and all that.
So, in fact, everything is completely wrong.
One small zoological fact
So let's look at our cats a little closer. This is the jaguar:
The biggest cat on the continents of both Americas, with the only one that periodically kills the victim by piercing the scalp with the fangs and biting into the brain. This is not a zoological fact that is important for our topic, but nonetheless. Among the characteristic signs are eye color, large jaw and in general they are the most massive of the whole trio. As you can see, quite subtle details.
Here it is - a leopard:
He lives in Africa, second only to a lion on this continent. They have light (yellow) eyes, and significantly smaller paws than the jaguar.
And finally, the cheetah:
Perceptibly smaller in size than his two fellows. It has a long, slender body, and at last at least something that can serve as a visually noticeable sign - a distinctive pattern on the face, similar to a dark path of tears from one eye to the other.
And here he is the same zoological fact: it turns out that the spots on the skin of these cats are not at all randomly located. They are assembled in several pieces in small groups, which are called "sockets". Moreover, the leopard has conditionally small sockets, the jaguar has much more (and with small black dots inside), and the cheetah does not have them at all - just a scattering of lonely standing spots.
Here it is seen better. Spontaneous education sponsor is Imgur , and I apologize in case I misrepresented something from the materiel.
Bees are beginning to suspect
Somewhere at that moment a terrible guess starts to sneak into the brain - what if this difference in the texture of the spots is the main criterion by which the algorithm distinguishes three possible recognition classes from each other? That is, in fact, the convolutional network does not pay attention to the shape of the depicted object, the number of paws, the thickness of the jaw, the peculiarities of the posture and all these subtle differences that, as we have assumed, it can understand - and simply compares the pictures as two pieces of texture?
This assumption needs to be verified. Let's take to check a simple, unsophisticated image, without any noise, distortion and other factors that complicate the life of recognition. I am sure that at first sight any person can easily recognize this picture.
For the test, we will use Caffe and the tutorial on recognition on pre-trained models, which lies right on their website. Here we are using not the same model, which is mentioned at the beginning of the post, but similar (CaffeNet), and in general for our purposes all convolution networks will show approximately the same result.
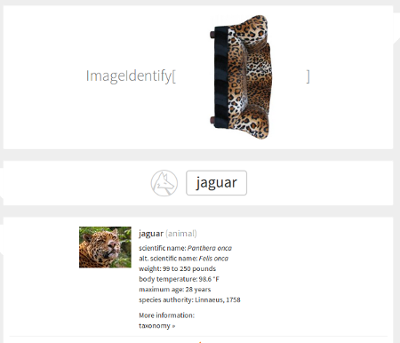
import numpy as np import matplotlib.pyplot as plt caffe_root = '../' import sys sys.path.insert(0, caffe_root + 'python') import caffe MODEL_FILE = '../models/bvlc_reference_caffenet/deploy.prototxt' PRETRAINED = '../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel' IMAGE_FILE = '../sofa.jpg' caffe.set_mode_cpu() net = caffe.Classifier(MODEL_FILE, PRETRAINED, mean=np.load(caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy').mean(1).mean(1), channel_swap=(2, 1, 0), raw_scale=255, image_dims=(500, 500)) input_image = caffe.io.load_image(IMAGE_FILE) prediction = net.predict([input_image]) plt.plot(prediction[0]) print 'predicted class:', prediction[0].argmax() plt.show() What happened:
>> predicted class: 290 Oops.
But hey, maybe this is a problem of a single model? Let's do more checks:
Clarifai
Steven Wolfram's recent mega-service
Here the picture is turned to the side - this means that the service coped with the correctly oriented sofa, but it broke when turning 90 degrees. In a sense, it is even worse than if he could not cope at all - such a simple transformation should not radically change the result. It seems that our guess about the texture is close to the truth.
Surprisingly, there are not so many open web recognition services. I made a couple of checks ( Microsoft , Google ) - some of them behave better without slipping a jaguar, but no one could win the sofa. A good result in a world where headlines in the spirit of "{Somebody} 's Deep Learning Project Outperforms Humans In Image Recognition" are already flashing.
Why it happens?
Here is one of the guesses. Let's imagine ourselves in the place of an ordinary supervised classifier, without going into details of the architecture. We receive many, many pictures at the entrance, each of which is marked with the corresponding class, and further we adjust our parameters so that for each picture the output data correspond to this very class. Thus, we hope to extract some internal structure, distinctive features from the image, to formulate an analytically inexpressible recognition rule - so that later new, unfamiliar images that have these characteristics fall into the desired class. In the process of learning, we are guided by the magnitude of our prediction error, and here the size and proportions of the sample are important - if we have 99 images of class A and one image of class B, then at the very stupid behavior of the classifier (“always say A”) the error will be equal to 1 %, despite the fact that we especially have not learned anything.
So, from this point of view, there is no problem here. The algorithm behaves as it should behave. The sudden leopard sofa is an anomaly, a rarity in the ImageNet sample, and in our everyday experience too. On the other hand, the distinctive pattern of dark spots on a light background is a wonderful distinguishing feature of large spotted cats. Where else in the end will you see such a pattern? Moreover, taking into account that the classifier is charged with devilishly difficult tasks in the spirit of distinguishing different types of cats - the use of the pattern becomes even greater. If we had enough of the number of leopard sofas in the sample, he would have to invent new criteria for the difference (I wonder what the result would be), but if there are none, then the error in such a rare case is completely natural.
Or not?
What we humans do
Remember the first school classes when you were learning to write numbers.
Each of the students was then brought in a weighty book called “MNIST database”, where sixty thousand numbers were written out on hundreds of pages, all with different handwritings and styles, bold and slightly noticeable italics. Especially stubborn reached the even more huge application “Permutation MNIST”, where these same figures were rotated at different angles, stretched up and down and to the sides, and shifted right and left - without this it was impossible to learn how to determine the figure by looking at it at an angle. Then, when the long and tedious training ended, everyone was given a small (comparatively) list of 10,000 digits, which had to be correctly identified in the general class testing. But after mathematics came the next lesson, where you had to learn a much more voluminous alphabet ...
Hm Say, it was all wrong?
It is curious, but it seems that you and I do not really need a sample in the learning process. At least, if it is needed, then not for the purpose of why it is used now when training classifiers — to develop resistance to spatial permutations and distortions. We perceive the same handwritten numbers as abstract Platonic concepts - a vertical stick, two circles one above the other. If, for example, we get an image where there is none of these concepts, we will reject it as “not a digit”, but the supervised classifier will never do that. Our computer algorithms do not look for concepts - they rake up a pile of data, stuffing them into heaps, and in the end every picture should end up in a handful with which it has a little more in common than with the others.
Have you seen leopards in your life? Maybe decently, but certainly less than the "glasses", "computers" and "persons" (other classes from ImageNet). Have you ever met sofas of this color? For example, I almost never think. And yet, none of those who read this text thought for a moment before correctly classifying the above picture.
Convolution networks exacerbate the situation.
Convolutional networks constantly show consistently high results in competitions based on ImageNet, and as of 2014, they seem to be second only to ensembles from convolutional networks. You can read about them in more detail in many places - for now we will limit ourselves only to the fact that these are networks that form small “filters” (or kernels) in the learning process by which they go over the image, activating in those places where there is an element corresponding to a particular filter. They are very fond of using them when recognizing images - firstly, because there are often local signs that can appear in different places of the picture, and secondly, because it is significantly computationally cheaper than cramming huge (1024x768 = ~ 800,000 parameters) picture in a regular network.
Let's imagine our leopards again. These are quite complex physical bodies that can take a bunch of different positions in space, and also photographed from different angles. Each picture of a leopard is likely to contain a unique, almost non-repeating outline - somewhere you can see a mustache, paws and a tail, and somewhere only a slurred back. In such situations, the convolutional network is simply our savior, because instead of trying to come up with one rule for this whole set of forms, we simply say "take this set of small distinctive signs, run them through the picture and summarize the number of matches." Naturally, the texture of leopard spots becomes a good sign - it exists in many places, and practically does not change when the object's position changes. That is why models like CaffeNet perfectly respond to spatial variations of objects in the pictures - and that is why, ahem, the sofa happens to them.
This is actually a very unpleasant property. Refusing to fully analyze the shape of an object in the picture, we begin to perceive it simply as a set of signs, each of which can be anywhere without any connection with the others. Using convolutional nets, we immediately refuse to distinguish between a cat sitting on the floor and an inverted cat sitting on the ceiling. This is good and great when recognizing individual pictures somewhere on the Internet, but if such computer vision coordinates your behavior in real life, it will not be great at all.
If this argument does not sound very convincing to you, take a look at Hinton’s article , which has been around for several years, and where the phrase “convolutional networks are doomed” sounds distinctly - for this very reason. The main part of the article is devoted to the development of an alternative concept - “capsule theory” (on which he is working right now ), and is also very worthwhile to read.
Total
Think about it for a while (and not very seriously) - we are doing everything wrong.
Stuffing huge datasets with pictures, annual competitions, even deeper networks, even more GPUs. We improved the recognition of MNIST digits from an error of 0.87 to 0.23 ( proof ) - in three years (no one still knows exactly what kind of mistake a person can make). In ImageNet Challenges, the competitors' account goes to tenths of a percent - it seems, here is a little bit more, and we will definitely win, and we will get real computer vision. And yet at the same time - no. All that we are doing is trying to scatter a bunch of pictures into categories as accurately as possible, without understanding this (I realize that the word “understand” is dangerous to use here, but) what is depicted on them. Something must be different. Our algorithms should be able to determine the spatial position of the object, and still rotated on the side of the sofa still recognize as a sofa, but with a slight warning on the topic "owner, you take out the furniture." They should be able to learn quickly, with just a few examples - like you and me - and not require multi-class sampling while extracting the necessary attributes from the objects themselves.
In general, we clearly have something to do.
Source: https://habr.com/ru/post/259191/
All Articles