Data Lake - from theory to practice. Tale about how we build ETL on Hadoop
In this article I want to tell about the next stage of development of DWH in Tinkoff Bank and about the transition from the paradigm of the classical DWH to the paradigm of Data Lake .
I want to start my story with such a funny picture:

')
Yes, a few years ago the picture was relevant. But now, with the development of technologies that are part of the Hadoop eco-system and the development of ETL platforms, it is legitimate to assert that ETL on Hadoop does not just exist, but that ETL on Hadoop has a great future. Further in article I will tell about how we build ETL on Hadoop in Tinkoff Bank.
Before DWH management a big task was set - to analyze the interests and behavior of the Internet visitors of the bank site. DWH has two new data sources; big data is clickstream from the portal ( www.tinkoff.ru ) and the RTB (Real-Time Bidding) platform of the bank. Two sources generate a huge amount of textual semi-structured data, which of course does not suit the traditional DWH built in a bank on the massively parallel DBMS Greenplum . The Hadoop cluster was deployed in the bank, based on the Cloudera distribution, which then formed the basis of the target data warehouse, or rather the data lake, for external data.
It was important at the initial stages to think over and fixed the conceptual architecture, which will need to be followed during the modeling of new structures for data storage and data loading work. We really didn’t want to turn our lake into a data swamp :) As in the classic DWH, we have identified the main conceptual data layers (see Fig. 1).
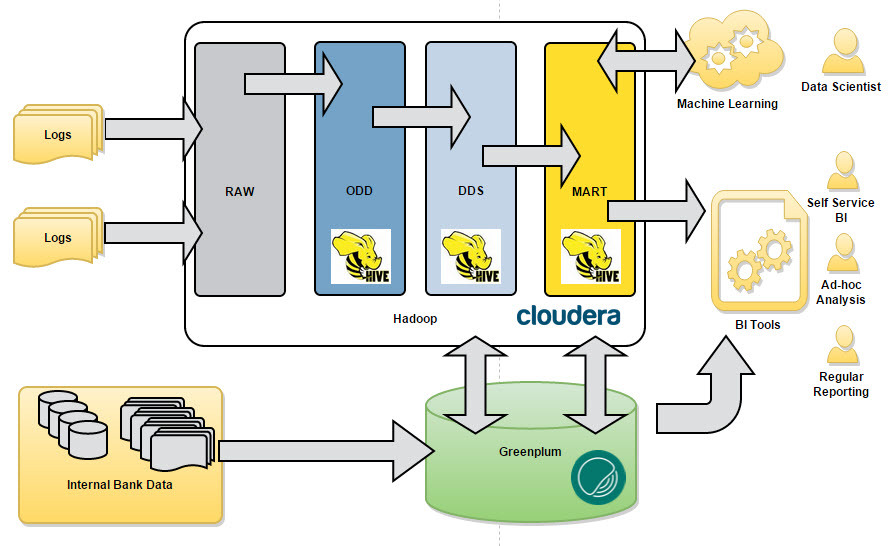
Fig.1 Concept
Why Data Vault? This approach has its pluses and minuses.
Pros:
Minuses:
After analyzing the trends in the development of Hadoop technologies, we decided to use this approach and, rolling up our sleeves, began to model the Data Vault for the above stated task.
Actually, I want to tell a few concepts that we use. For example, in downloading Internet user visits through pages, we do not save the visit URL every time. We have allocated all URLs, in terms of the Data Vault, into a separate hub (see Figure 2). This approach allows you to save space in HDFS and more flexibly work with URLs at the stage of loading and further processing of data.
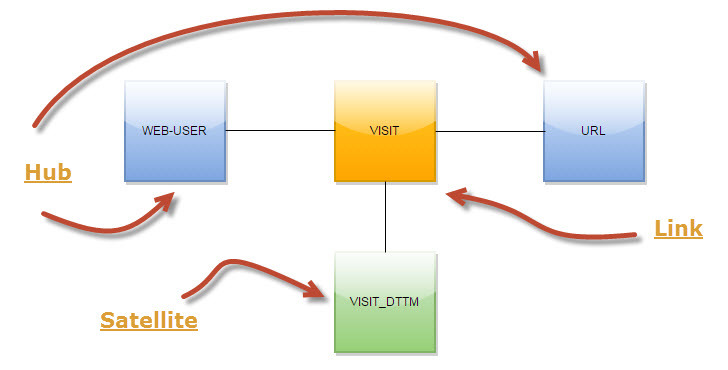
Fig.2 Data Vault for visits
Another concept relates to the field of Internet user downloads. We do not receive a single Internet user at the stage of loading into DDS, but load data in the context of source systems. Thus, downloads to the Data Vault from different sources are independent of each other.
It was important to immediately provide for the physical structure of data storage in Hadoop, i.e. Immediately think over the DDL tables in Hive. At this stage, we recorded two agreements:
As a result, each object (table) Data Vault in its DDL contains:
and
That came to the most interesting. The concept was thought out, modeling was carried out, data structures were created, now it would be good to fill all this with data.
In order to provide a steady stream of data (files) to the RAW layer, we use Apache Flume . To ensure fault tolerance and independence from the Hadoop cluster, we placed Flume on a separate server - we got a File Gate, as it were, in front of the Hadoop cluster. Below is an example of setting up the Flume agent to transfer portal syslog:
Thus, we got a stable data flow to the RAW layer. Next, you need to decompose this data into a model, fill the Data Vault, well, in short, you need ETL on Hadoop.
Drum roll, the lights go out, On the scene goes Informatica Big Data Edition . I will not be in colors and talk a lot about this ETL tool, I will try to briefly and to the point.
Lyrical digression. I would like to note right away that the Informatica Platform (which includes the BDE) is not the familiar Informatica PowerCenter. This is a fundamentally new data integration platform from Informatica corporation, to which all that great set of useful functions from the old and well-loved PowerCenter are now being transferred.
Now in the case. Informatica BDE allows you to quickly develop ETL procedures (mappings), the environment is very convenient and does not require long training. Mapping is broadcast in HiveQL and performed on a Hadoop cluster, Informatica provides convenient monitoring, the sequence of starting ETL processes, the processing of branches and exceptions.
For example, this is the mapping that fills the hub of the Internet users of our portal (see. Fig. 3).
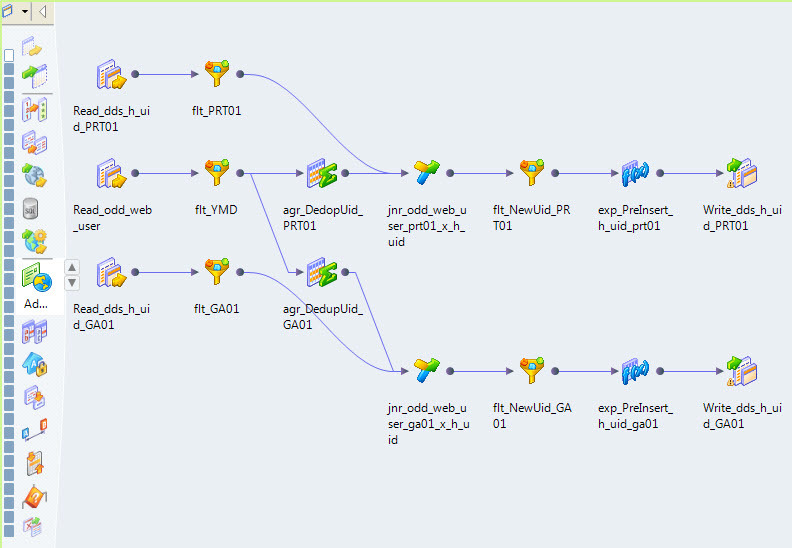
Fig.3 Mapping
The Informatica BDE optimizer translates this mapping into HiveQL and determines the execution steps itself (see Fig. 4).

Fig.4 Execution Plan
Informatica BDE allows you to flexibly manage runtime parameters. For example, we set up the following parameters:
Mappings can be streamed. For example, we have data from separate source systems loaded in separate streams (see Fig. 5).
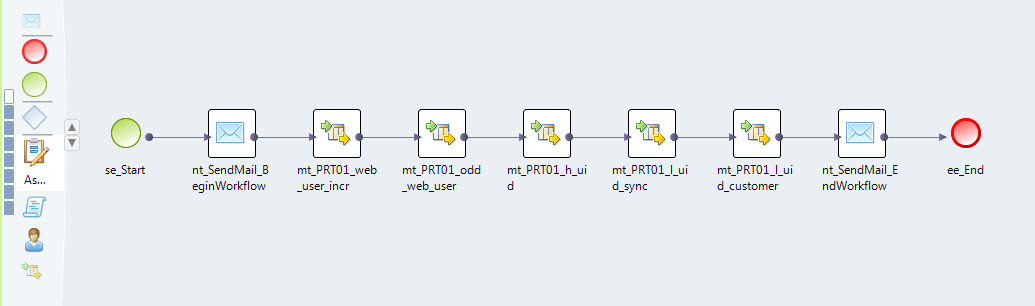
Fig.5 Data Download Stream
Informatica BDE has a convenient administration and monitoring tool (see Fig. 6).
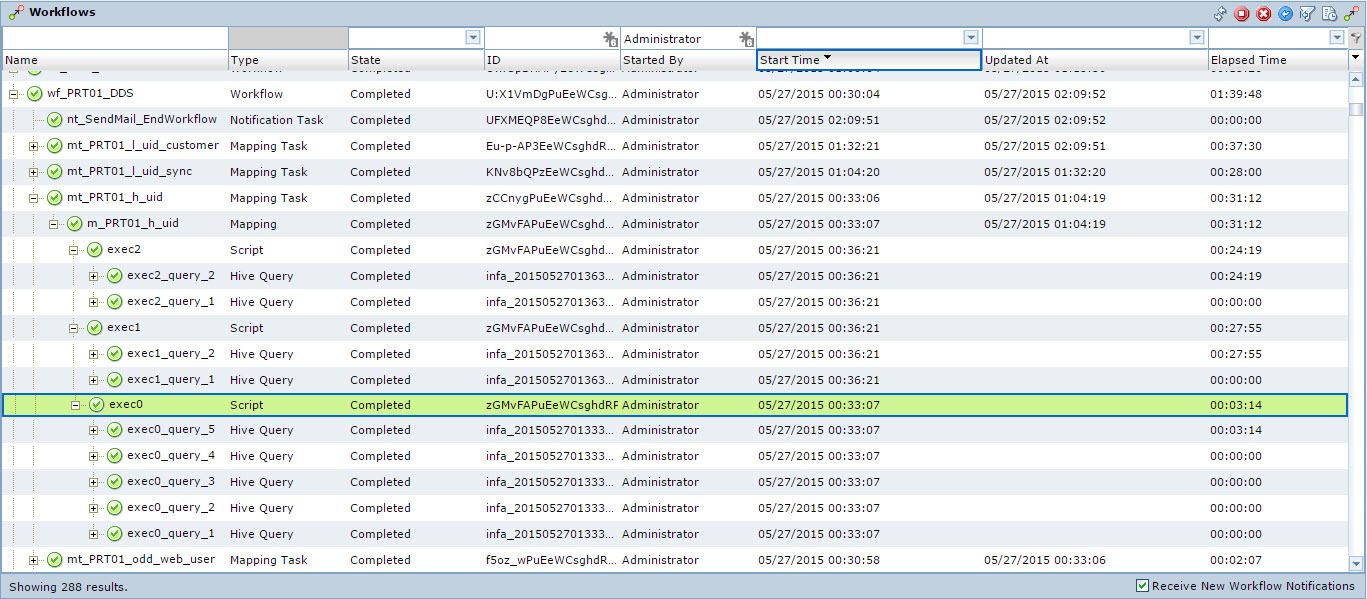
Fig.6 Monitoring of data flow execution
The advantages of Informatica BDE are the following:
Among the disadvantages are the following:
In general, the Informatica BDE tool has shown itself very well when working with Hadoop and we have very big plans for it in the ETL part of Hadoop. I think soon we will write more substantive articles about the implementation of ETL on Hadoop on Informatica BDE.
The main result we obtained at this stage is a stable ETL that fills the DDS. The result was obtained in two months by a team of two ETL developers and an architect. Now we are daily running ETL on Hadoop ~ 100Gb text logs and we get about an order of magnitude less data in the Data Vault, on the basis of which data marts are collected. Loading into the model occurs on the nightly schedule, the daily increment of data is loaded. Download duration is ~ 2 hours. With this data, performing Ad-hoc requests, analysts work through Hue and IPython.
I want to start my story with such a funny picture:
')
Yes, a few years ago the picture was relevant. But now, with the development of technologies that are part of the Hadoop eco-system and the development of ETL platforms, it is legitimate to assert that ETL on Hadoop does not just exist, but that ETL on Hadoop has a great future. Further in article I will tell about how we build ETL on Hadoop in Tinkoff Bank.
From task to implementation
Before DWH management a big task was set - to analyze the interests and behavior of the Internet visitors of the bank site. DWH has two new data sources; big data is clickstream from the portal ( www.tinkoff.ru ) and the RTB (Real-Time Bidding) platform of the bank. Two sources generate a huge amount of textual semi-structured data, which of course does not suit the traditional DWH built in a bank on the massively parallel DBMS Greenplum . The Hadoop cluster was deployed in the bank, based on the Cloudera distribution, which then formed the basis of the target data warehouse, or rather the data lake, for external data.
Lake building concept
It was important at the initial stages to think over and fixed the conceptual architecture, which will need to be followed during the modeling of new structures for data storage and data loading work. We really didn’t want to turn our lake into a data swamp :) As in the classic DWH, we have identified the main conceptual data layers (see Fig. 1).
Fig.1 Concept
- RAW - a layer of raw data, here we load files, logs, archives. Formats can be completely different: tsv, csv, xml, syslog, json, etc. etc.;
- ODD - Operational Data Definition. Here we load data in a format close to the relational. The data here can be the result of preprocessing data from RAW before loading it into DDS;
- DDS - Detail Data Store. Here we collect a consolidated detailed data model. To store the data in this layer, we chose the concept of a Data Vault ;
- MART - data marts. Here we collect application data marts.
Data Vault and how we prepare it
Why Data Vault? This approach has its pluses and minuses.
Pros:
- Modeling flexibility
- Quick and easy development of ETL processes
- No data redundancy, and for big data this is a very important argument.
Minuses:
- The main disadvantage for us was due to the storage environment (and more precisely, processing) of data and, as a consequence, the performance of join operations. As it is known, Hive doesn’t like join operations very much, due to the fact that in the end everything turns into a slow map reduce.
After analyzing the trends in the development of Hadoop technologies, we decided to use this approach and, rolling up our sleeves, began to model the Data Vault for the above stated task.
Actually, I want to tell a few concepts that we use. For example, in downloading Internet user visits through pages, we do not save the visit URL every time. We have allocated all URLs, in terms of the Data Vault, into a separate hub (see Figure 2). This approach allows you to save space in HDFS and more flexibly work with URLs at the stage of loading and further processing of data.
Fig.2 Data Vault for visits
Another concept relates to the field of Internet user downloads. We do not receive a single Internet user at the stage of loading into DDS, but load data in the context of source systems. Thus, downloads to the Data Vault from different sources are independent of each other.
It was important to immediately provide for the physical structure of data storage in Hadoop, i.e. Immediately think over the DDL tables in Hive. At this stage, we recorded two agreements:
- Using Partitioning in HDFS;
- Distribution emulation by key in HDFS.
As a result, each object (table) Data Vault in its DDL contains:
PARTITIONED BY (ymd string, load_src string) and
CLUSTERED BY (l_visit_rk) INTO 64 BUCKETS ETL Rivers in Data Lake
That came to the most interesting. The concept was thought out, modeling was carried out, data structures were created, now it would be good to fill all this with data.
In order to provide a steady stream of data (files) to the RAW layer, we use Apache Flume . To ensure fault tolerance and independence from the Hadoop cluster, we placed Flume on a separate server - we got a File Gate, as it were, in front of the Hadoop cluster. Below is an example of setting up the Flume agent to transfer portal syslog:
# *** Clickstream PROD syslog source *** a3.sources = r1 r2 a3.channels = c1 a3.sinks = k1 a3.sources.r1.type = syslogtcp a3.sources.r2.type = syslogudp a3.sources.r1.port = 5141 a3.sources.r2.port = 5141 a3.sources.r1.host = 0.0.0.0 a3.sources.r2.host = 0.0.0.0 a3.sources.r1.channels = c1 a3.sources.r2.channels = c1 # channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 # sink a3.sinks.k1.type = hdfs a3.sinks.k1.channel = c1 a3.sinks.k1.hdfs.path = /prod_raw/portal/clickstream/ymd=%Y-%m-%d a3.sinks.k1.hdfs.useLocalTimeStamp = true a3.sinks.k1.hdfs.filePrefix = clickstream a3.sinks.k1.hdfs.rollCount = 100000 a3.sinks.k1.hdfs.rollSize = 0 a3.sinks.k1.hdfs.rollInterval = 600 a3.sinks.k1.hdfs.idleTimeout = 0 a3.sinks.k1.hdfs.fileType = CompressedStream a3.sinks.k1.hdfs.codeC = bzip2 # *** END *** Thus, we got a stable data flow to the RAW layer. Next, you need to decompose this data into a model, fill the Data Vault, well, in short, you need ETL on Hadoop.
Drum roll, the lights go out, On the scene goes Informatica Big Data Edition . I will not be in colors and talk a lot about this ETL tool, I will try to briefly and to the point.
Lyrical digression. I would like to note right away that the Informatica Platform (which includes the BDE) is not the familiar Informatica PowerCenter. This is a fundamentally new data integration platform from Informatica corporation, to which all that great set of useful functions from the old and well-loved PowerCenter are now being transferred.
Now in the case. Informatica BDE allows you to quickly develop ETL procedures (mappings), the environment is very convenient and does not require long training. Mapping is broadcast in HiveQL and performed on a Hadoop cluster, Informatica provides convenient monitoring, the sequence of starting ETL processes, the processing of branches and exceptions.
For example, this is the mapping that fills the hub of the Internet users of our portal (see. Fig. 3).
Fig.3 Mapping
The Informatica BDE optimizer translates this mapping into HiveQL and determines the execution steps itself (see Fig. 4).
Fig.4 Execution Plan
Informatica BDE allows you to flexibly manage runtime parameters. For example, we set up the following parameters:
mapreduce.input.fileinputformat.split.minsize = 256000000 mapred.java.child.opts = -Xmx1g mapred.child.ulimit = 2 mapred.tasktracker.map.tasks.maximum = 100 mapred.tasktracker.reduce.tasks.maximum = 150 io.sort.mb = 100 hive.exec.dynamic.partition.mode = nonstrict hive.optimize.ppd = true hive.exec.max.dynamic.partitions = 100000 hive.exec.max.dynamic.partitions.pernode = 10000 Mappings can be streamed. For example, we have data from separate source systems loaded in separate streams (see Fig. 5).
Fig.5 Data Download Stream
Informatica BDE has a convenient administration and monitoring tool (see Fig. 6).
Fig.6 Monitoring of data flow execution
The advantages of Informatica BDE are the following:
- Support for many Hadoop distributions: Cloudera, Hortonworks, MapR, PivotalHD, IBM Biginsights;
- Rapid implementation of new features developed in Hadoop into the product: support for new distributions, support for new versions of Hive, support for new data types in Hive, support for partitioned tables in Hive, support for new data storage formats;
- Rapid development of mappings;
- And one more very important argument in favor of Informatica is a very close cooperation and partnership with the market leader of Hadoop distributions, Cloudera . This argument allows you to determine the strategic choice in favor of these two platforms, if you decide to build Data Lake.
Among the disadvantages are the following:
- One big, but not so significant, but still a drawback - it lacks all the many useful features that are in the old PowerCenter. This is flexible work with variables and parameters both within the mapping and at the stage of interaction between workflow-> mapping-> workflow. But, the new platform Informatica is developing and with each new version it becomes more convenient.
In general, the Informatica BDE tool has shown itself very well when working with Hadoop and we have very big plans for it in the ETL part of Hadoop. I think soon we will write more substantive articles about the implementation of ETL on Hadoop on Informatica BDE.
results
The main result we obtained at this stage is a stable ETL that fills the DDS. The result was obtained in two months by a team of two ETL developers and an architect. Now we are daily running ETL on Hadoop ~ 100Gb text logs and we get about an order of magnitude less data in the Data Vault, on the basis of which data marts are collected. Loading into the model occurs on the nightly schedule, the daily increment of data is loaded. Download duration is ~ 2 hours. With this data, performing Ad-hoc requests, analysts work through Hue and IPython.
Future plans
- Switching to CDH 5.4 (currently working on 5.2) and piloting Hive 0.14 and Hive on Spark technology;
- Update Informatica 9.6.1 Hotfix2 to Hotfix3. And of course we are waiting for Informatica 10;
- Development of mappings that collect showcases for machine learning and data scientist;
- The development of ILM in Hadoop / HDFS.
Source: https://habr.com/ru/post/259173/
All Articles