24 hours PASS - review of the SQL conference reports
"24 Hours of PASS" is an annual online conference about MS SQL Server, held under the auspices of the professional association PASS, and lasting 24 hours. This is literally 24 hours: the speakers from different parts of the world replace each other in the webinar marathon (of course, this is a reference to the 24 hours of Le Mans ).
Through the efforts of Andrei Korshikov, the Russian version of “24 hours PASS” has been held for several years. The latter took place in mid-March, and if you have not had time to watch all 24 hours of video (by the way, here 's a playlist on YouTube), then I made this review just for you.

slides - video part 1 , part 2
')
Sergey Olontsev (Kaspersky Lab) at the moment, perhaps, is the main driver of the Moscow SQL User Group, organizer of several sequel events in Moscow, participant of many conferences, MVP and owner of the rare status of SQL MCM. Blog
Why look. About the new cool In-Memory engine, you probably already heard. The report also says a lot about meeting rainbow expectations with reality.

The classic engine - a family wagon, a large trunk, air conditioning, a child seat can be put ... a lot of comfort. In-Memory is a racing car that can squeeze out top speed, but the number of features and amenities is very limited. In our case, it is: the sum of the fields is no more than 8060 bytes, no more than 512 GB per database, there are no calculated columns, you cannot change the structure of already created tables, there are no filtered indexes, etc.
Size does matter: 10 ways to reduce the size of the database and improve system performance - scripts and slides - video
Dmitry Korotkevich. Also MVP and MCM. The author of the best, in my opinion, book on MS SQL - “Pro SQL Server Internals” (in English).
Why look. A good set of practical recommendations on the contraction of your data and an explanation of why this is important.
“I love working with large databases, they are very interesting. But only when I have hourly pay. ”
slides - video part 1 and part 2
Dmitry Pilyugin (TNS Gallup Media). Another MVP. Connoisseur of undocumented trace flags and unusual hints. Known for his ability to bite into the subject, assorting it to the smallest detail. I remember that I was very impressed with the depth of his Kharkov report on the mechanism of cardinality (estimates of the number of rows returned after some operation). Blogs: SomewhereSomehow.ru and QueryProcessor.com
Why look. This is one of the most difficult reports, but at the same time the most valuable. Everything about the internal kitchen of logical and physical table optimization.
From the server’s point of view, user requests are roulette:
Optimization of SSAS cubes (multidimension and tabular): is it possible to make a slow cube fast?
slides and scripts - video
Evgeny Polonichko - DWH / BI Architect, leader of SQL Server User Group Donetsk
Why look. You are already working with OLAP and want to see how other developers manage this beast.
slides - video video
Andrey Zavadsky - SQL, ASP.NET and Sharepoint developer from Krasnodar
Why look. You are akin to Management Studio, but want to see how people use the big Visual Studio for SQL development.
slides - video video
Andrei Korshikov. BI developer, an activist of PASS, which he represents in Eastern Europe, organizer of the Global Russian Virtual Chapter, winner of the rare PASSion Award.
Why look. You are developing SSIS packages, you want to take the development to a new level, you are not afraid of non-standard technologies, and you are not squeamish about code generators.

slides - video video
Sergey Lunyakin - the leader of the PASS Local Chapter in Lviv
Why look. View Azure interfaces, get acquainted with new terms (the product itself is still damp).
slides - video video
Maria Zakurdaeva - founder of PASS Virtual Chapter “Global Hebrew”
Why look. You want to know how the SQL server uses memory, how queues to resources work, what scary the word "spill" is. Yes, and the presentation is very beautifully framed.

slides - video video
Denis Reznik - MVP and, probably, the main Ukrainian organizer of the SQL community.
Why look. After a few platitudes about the levels of locks, look at the analysis of really complex and even incredible cases.
slides - video video
Konstantin Khomyakov - MVP, BI developer from Australia
Why look. Requests for data in a natural language is a new technology, not very popular yet, but, they say, some customers are impressed.
slides - video video
Kirill Panov
Why look. Make sure that you are really aware of all the topics listed. A bit of a messy report about everything.
slides - video video
Alexey Knyazev - DWH-specialist, leader of SQL User Group in Yekaterinburg
Why look. If you like to understand the essence of things. Very detailed immersion in storage structures, bitmasks, offset tables. The practical value is very limited, since there is no possibility to influence the described mechanisms in any way, although the speaker gives examples from real life.
slides - video video
Aleksey Kovalev is a Kharkiv-based SQL Code Guard (must have SSMS plugin).
Why look. If you do not control the versions of your database and do not know how to approach this task.

Do not forget the English 24 hours PASS and Global Russian Virtual Chapter. Follow Facebook announcements.
Through the efforts of Andrei Korshikov, the Russian version of “24 hours PASS” has been held for several years. The latter took place in mid-March, and if you have not had time to watch all 24 hours of video (by the way, here 's a playlist on YouTube), then I made this review just for you.
- SQL Server 2014 In-Memory OLTP - Sergey Olontsev
- Size does matter: 10 ways to reduce the size of the database - Dmitry Korotkevich
- Inside the query optimizer: Connections - Dmitry Pilyugin
- Optimization of SSAS-cubes - Evgeny Polonichko
- Tyap-bang and in production! - Alexey Kovalev
- Offline database development and testing with SSDT - Andrey Zavadsky
- Deadlocks 3.0. Final Edition - Denis Reznik
- BIML is the best friend for an SSIS developer - Andrey Korshikov
- Power BI Q & A - Konstantin Khomyakov
- Azure Data Factory - Cloud ETL - Sergey Lunyakin
- Everything you wanted to know about Workspace memory - Maria Zakurdaeva
- Fast SQL Server Performance Analysis in 1.5 hours - Kirill Panov
- Internal arrangement of pages and extents of SQL Server - Alexey Knyazev
SQL Server 2014 In-Memory OLTP
slides - video part 1 , part 2
')
Sergey Olontsev (Kaspersky Lab) at the moment, perhaps, is the main driver of the Moscow SQL User Group, organizer of several sequel events in Moscow, participant of many conferences, MVP and owner of the rare status of SQL MCM. Blog
Why look. About the new cool In-Memory engine, you probably already heard. The report also says a lot about meeting rainbow expectations with reality.
The classic engine - a family wagon, a large trunk, air conditioning, a child seat can be put ... a lot of comfort. In-Memory is a racing car that can squeeze out top speed, but the number of features and amenities is very limited. In our case, it is: the sum of the fields is no more than 8060 bytes, no more than 512 GB per database, there are no calculated columns, you cannot change the structure of already created tables, there are no filtered indexes, etc.
Report notes
- The obvious fact is: if the table is declared as Memory_Optimized, this does not mean that when turning off the electricity, the data will be lost, because they are also written to the log file. It can be turned off, and it is still noticeably add speed.
- How data storage is organized: Bw-tree, unidirectional lists. The report examines the structure of the records, shows what happens when you edit, how the indexes behave
- Multi-version model - no more locks and latches.
- New types of indexes "hash" and "range"
- Native compile is a companion technology that allows you to compile requests to InMem into machine code. Previously, query plans were also saved in a buffer and could be reused, this made it possible not to re-launch the optimizer. But all the plans were interpreted anyway. Now requests can be saved in fair machine code. This gives a huge leap in performance, but it also entails monstrous limitations. Among all, I’ll only mention: there is no CTE, LEFT JOIN cannot be used, the CASE operator does not work.
- The easiest way to start using InMem is Memory_Optimized table types. This is an analogue of temporary tables and table variables, but unlike them, they actually work in memory.
- Other scenarios where InMem will be useful: simultaneous insertion from multiple threads, staging tables for ETL, intensive reading operations.
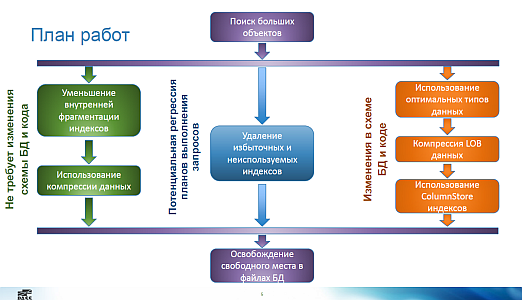
Size matters
Size does matter: 10 ways to reduce the size of the database and improve system performance - scripts and slides - video
Dmitry Korotkevich. Also MVP and MCM. The author of the best, in my opinion, book on MS SQL - “Pro SQL Server Internals” (in English).
Why look. A good set of practical recommendations on the contraction of your data and an explanation of why this is important.
“I love working with large databases, they are very interesting. But only when I have hourly pay. ”
Report notes
The report is based on the eponymous post in the author's blog (I recommend to subscribe).
Dmitry leads happy useful scripts:
- Set the parameter “Instant file Initialization”. It allows the server to avoid filling in with zeros when creating and enlarging data files.
- Internal and external fragmentation
- Types of data pages: IN_ROW, ROW_OVERFLOW (if there is a large column that does not fit on the page along with other row data), LOB (for example, for VARCHAR (MAX))
- Compression works only for pages IN_ROW
- ROW-compression almost always makes sense to include. If there is an INT column and the value 0 is stored in it, then during row-compression this value takes 1 byte, not 4.
- PAGE compression is a zip of memory pages. We change the processor resources for disk resources (faster to read, but we still need to unpack).
- LOB compression. Actually, there is no such thing. But you can implement your CLR functions. They are simple and really work.
- usually use datetime2 instead of datetime
- examples of replacing redundant indexes (they can be found automatically):
- IDX1 (A, B) & IDX2 (A) -> IDX2 can be deleted, it is part of the first index
- IDX3 (A) INCLUDE (B) & IDX4 (A) INCLUDE -> IDX5 (A) INCLUDE (B, C)
- ColumnStore-index can be considered as a special kind of compression. Order of compression efficiency: source table 10 GB, ROW compression 7 GB, PAGE compression 2 GB, COLUMNSTORE from 0.8 to 0.4 GB
- free up space: CREATE INDEX WITH (DROP_EXISTING = ON) ON [NewFileGroup]
Dmitry leads happy useful scripts:
- Detecting Space Consumers
- Monitoring splits
- LOBCompress
- Unused Indexes
- Redundant indexes
Inside the query optimizer: connections
slides - video part 1 and part 2
Dmitry Pilyugin (TNS Gallup Media). Another MVP. Connoisseur of undocumented trace flags and unusual hints. Known for his ability to bite into the subject, assorting it to the smallest detail. I remember that I was very impressed with the depth of his Kharkov report on the mechanism of cardinality (estimates of the number of rows returned after some operation). Blogs: SomewhereSomehow.ru and QueryProcessor.com
Why look. This is one of the most difficult reports, but at the same time the most valuable. Everything about the internal kitchen of logical and physical table optimization.
From the server’s point of view, user requests are roulette:
Report notes
It is impossible to retell briefly, I list them only to give an idea of the scale of the material):
In general, the picture looks like this:
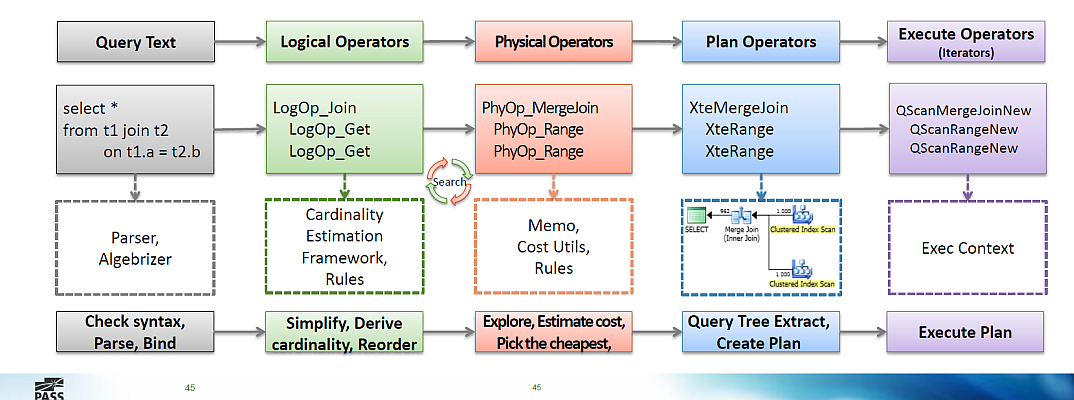
The main properties of physical compounds:
And a few practical answers:
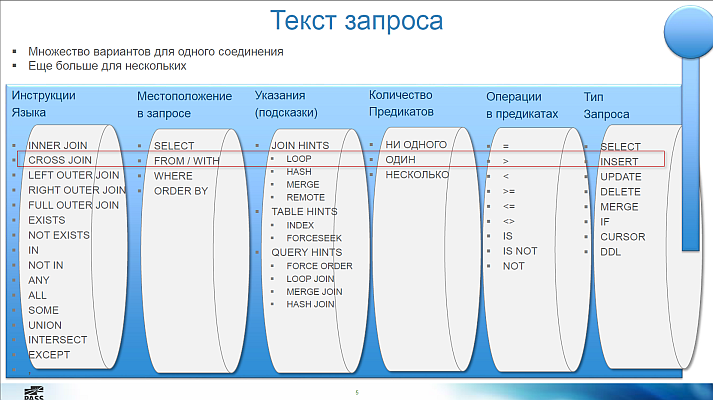
- In addition to the well-known INNER JOIN, LEFT OUTER JOIN and FULL JOIN, there are others, for example, LEFT ANTI SEMI JOIN. This join of tables is made by the optimizer in the following query:
- set operations, for example, EXCEPT - this is also a hidden connection of tables
- PREDICATE is a scalar operator. For example: CScaOp_AggFunc, CScaOp_Arithmetic, CScaOp_Assign, CScaOp_Collate ...
- PROBE is an operator for queries of the form SELECT CASE WHEN EXISTS (SELECT ..) THEN 10 ELSE 20 END ...
- PASS THROUGH is an operator for queries of the form SELECT CASE WHEN a = 1 THEN (SELECT TOP (1) ..) ELSE 0 END ...
- A tree of logical operators is built, these are objects like:
- LogOp_Get - get the table
- LogOp_Select - filter (“choose from”, where, on, having, ...)
- LogOp_LeftSemiJoin, LogOp_RightSemiJoin - semi join
- The simplification / substitution rules are applied to the tree.
- Logical optimization “Simplifying rules”: elimination of empty sets, elimination of redundancy, pushing predicates, disclosing subqueries, linearizing connections - there are about 150 of them, good examples in the report
- Examples: unused table joins are discarded, LEFT JOIN is converted to INNER JOIN, if there is a condition on it in WHERE, etc.
- Logical operators are converted to physical, in the process of applying the "implementing" rules
- Physical optimization "Explore rules": commutability of connections, grouping before connection, comparison of indexed views, Full Outer -> Left Outer + Left Anti Semi Join and others (130 rules in total)
- Physical optimization "Implementing rules": depend on the logical operator, cost, hints (for example, use LOOP JOIN or HASH JOIN)
- There is a heuristic algorithm for selecting the order of joining tables, there are too many options: for 10 tables, even the Left Deep Tree method will have 3,628,800 variants
In general, the picture looks like this:
The main properties of physical compounds:
- Nested Loops Join. Good for: universal (non-blocking)
- Nested Loops Apply (function call in a loop). Good for: a small external set and indexed internal set; fast receipt of a small portion of data (TOP, FAST N, EXISTS)
- Merge Join One-To-Many: Good for: Medium and large sets of indexed key connections and equality predicates
- Merge Join Many-To-Many: same thing, but use tempdb (therefore it is important that the optimizer knows which columns are unique)
- Hash Match. Good for: non-indexed medium and large sets; scaled by parallel execution
And a few practical answers:
- How quick is a subquery or join? - It doesn't matter, the server will reduce both requests to the same plan (if complex predicates are not used)
- Where to write conditions on or where? - For INNER JOIN it does not matter.
- Does the order of writing compounds in the query matter? - Not
- What is better, grouping after join or join of grouped values? - The optimizer itself pushes the grouping to join.
SSAS optimization cubes
Optimization of SSAS cubes (multidimension and tabular): is it possible to make a slow cube fast?
slides and scripts - video
Evgeny Polonichko - DWH / BI Architect, leader of SQL Server User Group Donetsk
Why look. You are already working with OLAP and want to see how other developers manage this beast.
Report notes
Basic monitoring mechanisms:
In practice, useful:
In a cube you can optimize:
Tips:
- Good old SQL Profiler (QueryProccesing event group)
- Extended Events (replacement technology Profiler)
- DMV - system views that you can query
In practice, useful:
- $ SYSTEM.DISCOVER_OBJECT_ACTIVITY - statistics on the use of cube objects
- $ SYSTEM.DISCOVER_OBJECT_MEMORY_USAGE
- $ SYSTEM.DISCOVER_SESSIONS - you can find the most voracious client
- $ SYSTEM.DISCOVER_LOCK
In a cube you can optimize:
- Partitions - we divide data by time periods
- Aggregates
- Cube Settings
- Measurement Setup: Relationships and Hierarchies
- setup of MDX requests (transfer of calculations to ETL, separate calculated element)
Tips:
- use of NonEmpty (), including for optimization of NON EMPTY
- AttributeHierarchyEnabled = False
- Replacing LastNonEmpty with LastChild
- script to warm up the cache after processing
- use DAX Studio
Offline database development and unit testing with SSDT
slides - video video
Andrey Zavadsky - SQL, ASP.NET and Sharepoint developer from Krasnodar
Why look. You are akin to Management Studio, but want to see how people use the big Visual Studio for SQL development.
Report notes
- separation of the concepts “save changes in the project” and “apply them on the server”
- script to insert data
- schema and data comparison tools in the project and on the server
- focus on how the code should look, not on the transformation scripts
- prepare the DACPAC file and give it to the admin (data-tier application)
- interesting interface to create tables - watch a 36 minute video
- Visual Studio is handy when you have to keep SQL and C # code nearby
- there is a static code analyzer that will warn, for example, that "SELECT *" is a bad design
- deployment on a connected base or deployment on a detached base
- post deployment script
- unit tests, for example, can check the structure of the returned dataset, the number of its rows
- negative tests checking that such an error should appear
BIML is the best friend for SSIS developer
slides - video video
Andrei Korshikov. BI developer, an activist of PASS, which he represents in Eastern Europe, organizer of the Global Russian Virtual Chapter, winner of the rare PASSion Award.
Why look. You are developing SSIS packages, you want to take the development to a new level, you are not afraid of non-standard technologies, and you are not squeamish about code generators.
Report notes
- standard SSIS package is generated from BIML file
- working with BIML happens through editing an XML file, but it is very human XML, does not look like DTSX at all
- there are hints and auto-completion when editing
- C # code inserts (like PHP was once embedded in HTML)
- for example, you can loop through tables and columns without describing each separately
- it is convenient to generate packages for similar tasks
- code reuse
- who would risk using it in production?
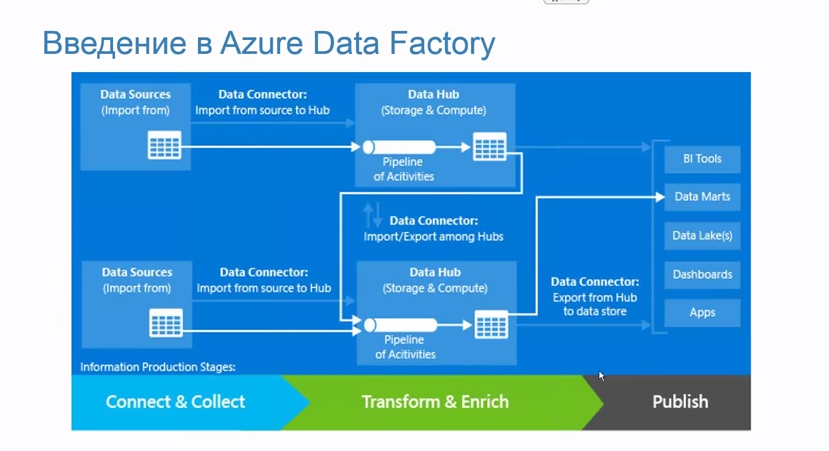
Azure Data Factory - Cloud ETL
slides - video video
Sergey Lunyakin - the leader of the PASS Local Chapter in Lviv
Why look. View Azure interfaces, get acquainted with new terms (the product itself is still damp).
Report notes
- many settings via JSON
- There are quite good tutorials and labs from Microsoft
- Convenient for sharing with Azure Machine Learning
- and indeed, useful when everything in Azure
- can install connector for your local database
- last half a year is very actively developing
- Amazon Data Pipeline equivalent
All you wanted to know about Workspace memory
slides - video video
Maria Zakurdaeva - founder of PASS Virtual Chapter “Global Hebrew”
Why look. You want to know how the SQL server uses memory, how queues to resources work, what scary the word "spill" is. Yes, and the presentation is very beautifully framed.
Report notes
- iterators requiring memory: Sort, Hash Match, Exchange
- Sorting requires 2 times more memory than the size of the data to be sorted.
- An example of how two very similar requests take 5 MB and 108 MB
- during the request the memory can not be backed up
- 2 problems: underestimation of the necessary memory and wasteful memory reservation
- recommendation to use the Resource Governor
- varchar size is estimated at half its length
- trash disposable plans can travel a large piece of the Buffer Pool
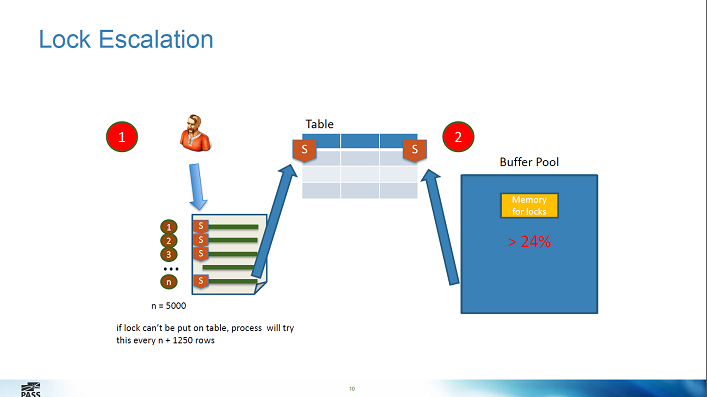
Deadlocks 3.0. Final edition
slides - video video
Denis Reznik - MVP and, probably, the main Ukrainian organizer of the SQL community.
Why look. After a few platitudes about the levels of locks, look at the analysis of really complex and even incredible cases.
Report notes
- if the changes affect more than 5000 rows, then escalation of the lock to the level of the entire table
- but you can turn off table locks
- data from the version store is not logged
- A good example of a deadlock between UPDATE and SELECT
- in applications do not forget about handling deadlocks
- stress testing helps identify problems
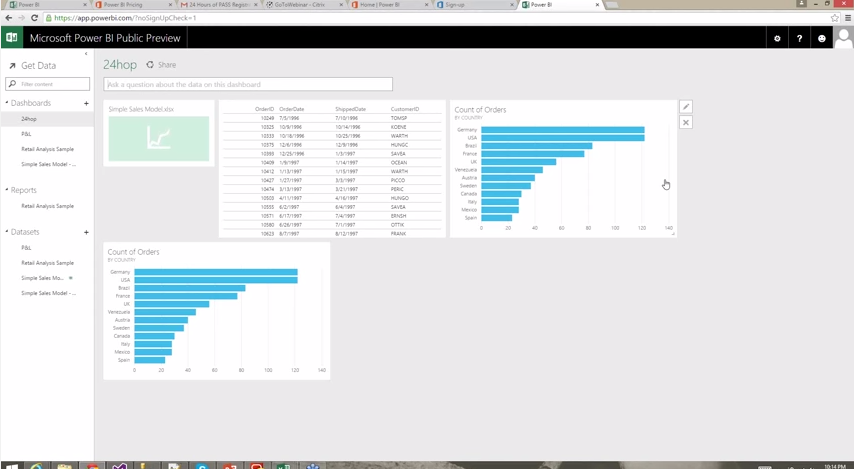
Power BI Q & A
slides - video video
Konstantin Khomyakov - MVP, BI developer from Australia
Why look. Requests for data in a natural language is a new technology, not very popular yet, but, they say, some customers are impressed.
Report notes
- need Office 365 + Power BI
- "ustomers by countries as chart"
- after displaying the result, the query can be specified in the normal interface
- connections between tables are important, good names (CustomerName vs strCustNm)
- so far only in English, but, like, do and the Chinese version
- says customers are thrilled, but something is hard to believe
- setting synonyms
- connecting to local servers from the cloud
- connectors to salesforce, google analytics
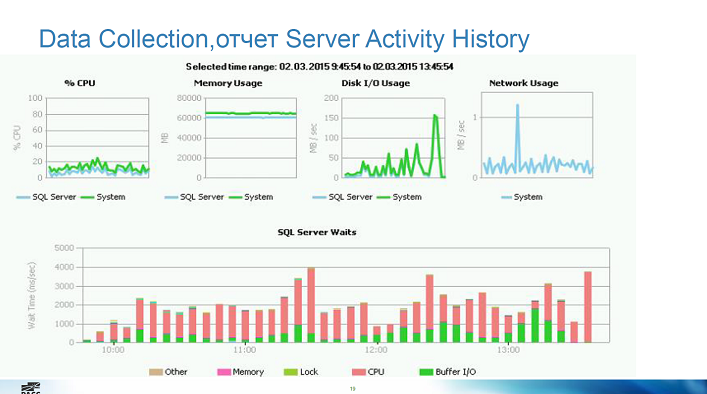
Fast SQL Server Performance Analysis in 1.5 hours
slides - video video
Kirill Panov
Why look. Make sure that you are really aware of all the topics listed. A bit of a messy report about everything.
Report notes
- SARG, clustered index, covering index, RCSI and other commonplace
- Paul Randal's wait statistics script
- Data Compression Best Practices - calculate the percentage of changes and scans
- Data collections and its standard reports
- try decomposition to UNION instead of OR in WHERE
- also try splitting large queries into several using temporary tables.
- script of Alexander Gladchenko for defragmenting indexes
- 3x performance boost when using SORT_IN_TEMPDB = ON
- SQL Server Technical Support Engineers Blog. Microsoft. Russia
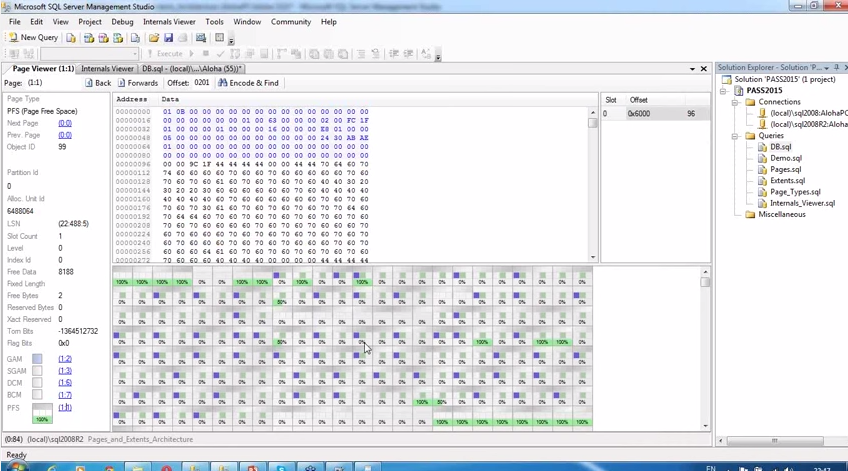
Internal arrangement of pages and extents of SQL Server
slides - video video
Alexey Knyazev - DWH-specialist, leader of SQL User Group in Yekaterinburg
Why look. If you like to understand the essence of things. Very detailed immersion in storage structures, bitmasks, offset tables. The practical value is very limited, since there is no possibility to influence the described mechanisms in any way, although the speaker gives examples from real life.
Report notes
- checksum is calculated only when writing to disk
- storing datetime as two int
- Bulk Change Map - tracks changes with incomplete logging for backup
- Internals Viewer for SQL Server - plugin for visualizing the distribution of pages in the file
- Example: what happens when a column changes from NULL to not NULL?
- Example: What happens if the regular index fields partially overlap the clustered index fields
Tyap-bang and in production!
slides - video video
Aleksey Kovalev is a Kharkiv-based SQL Code Guard (must have SSMS plugin).
Why look. If you do not control the versions of your database and do not know how to approach this task.
Report notes
- do everything on scripts, do not use magic Reg gate
- storing and loading directories as XML for flexibility
- variable substitution, for example, “create database [$ (dbname)];” and then run as “Sqlcmd -i final.sql -v dbname = MyDB”
- Try to write scripts so that they can be run without serious consequences on different historical versions of your database.
- strumming by developers or by features
And further...
Do not forget the English 24 hours PASS and Global Russian Virtual Chapter. Follow Facebook announcements.
Source: https://habr.com/ru/post/259081/
All Articles