Twelve Factor App - The Twelve-Factor App
Dear readers! I present to your attention the translation of The Twelve-Factor App web application development methodology from the developers of the Heroku platform. My comments are hidden by spoilers in the course of the article.
Nowadays, software is usually distributed in the form of services called web applications (web apps) or software-as-a-service (SaaS). An appendix of twelve factors is a methodology for creating SaaS applications that:
The methodology of the twelve factors can be applied to applications written in any programming language that use any combination of third-party services (backing services) (databases, message queues, cache memory, etc.).
Contributors to this document were directly involved in the development and deployment of hundreds of applications and indirectly witnessed the development, implementation and scaling of hundreds of thousands of applications during our work on the Heroku platform.
')
This document summarizes our entire experience of using and observing a wide variety of SaaS applications in the wild. The document is a combination of three ideal approaches to application development: focusing on the dynamics of organic growth of an application over time, the dynamics of cooperation between developers working on the application code base and the elimination of the effects of software erosion .
Our motivation is to raise awareness of some system problems that we have encountered in the practice of developing modern applications, as well as to provide common basic concepts for discussing these problems and propose a set of common conceptual solutions to these problems with associated terminology. The format is inspired by the books of Martin Fowler (Martin Fowler) Patterns of Enterprise Application Architecture and Refactoring .
Developers who create SaaS applications. Ops to engineers deploying and managing such applications.
I. Code base
One code base tracked in a version control system - multiple deployments
Ii. Dependencies
Explicitly declare and isolate dependencies
Iii. Configuration
Save the configuration in runtime
Iv. Third Party Services (Backing Services)
Consider third-party services (backing services) connected resources
V. Build, Release, Execution
Strictly separate the assembly and execution stages
Vi. Processes
Run the application as one or more non-stateless processes (stateless)
VII. Port binding
Export services through port mapping
Viii. Parallelism
Scale an application using processes
Ix. Disposability
Maximize reliability with quick startup and proper shutdown
X. Par development / application performance
Keep the development, staging and production deployment environments as similar as possible.
Xi. Logging (Logs)
View the log as a stream of events.
Xii. Admin Tasks
Perform administration / management tasks using one-time processes.
An application of twelve factors is always tracked in a version control system such as Git , Mercurial or Subversion . A copy of the database of monitored versions is called a code repository , which is often shortened to code repo or simply to repository (repo)
A codebase is one repository (in centralized version control systems, like Subvertion), or multiple repositories that have common initial commits (in decentralized version control systems, like Git).

There is always a one-to-one correspondence between the code base and the application:
There is only one code base for each application, but there can be multiple deployments of the same application. Deployed application (deploy) is a running instance of the application. As a rule, this is a working site deployment and one or more intermediate site deployments. In addition, each developer has a copy of the application running in his local development environment, each of which also qualifies as an deployed application (deploy).
The code base should be the same for all deployments, but different versions of the same code base can be executed in each of the deployments. For example, a developer may have some changes that have not yet been added to a staged deployment; intermediate deployment may have some changes that have not yet been added to the production deployment. However, all these deployments use the same code base, so they can be identified as different deployments of the same application.
Most programming languages come with a package manager for distributing libraries, such as CPAN in Perl or Rubygems in Ruby. Libraries installed by the package manager can be installed accessible to the entire system (so-called “system packages”) or available only to an application in the directory containing the application (so-called “vendoring” and “bundling”).
The application of the twelve factors never depends on implicitly existing packages available to the whole system. The application declares all its dependencies completely and accurately using the manifest of the dependency declaration . In addition, it uses the dependency isolation tool at run time to ensure that implicit dependencies do not “leak” from the surrounding system. A complete and explicit specification of dependencies applies equally to both the development and operation of the application.
For example, Gem Bundler in Ruby uses
One of the advantages of explicitly declaring dependencies is that it simplifies application customization for new developers. The new developer can copy the application code base onto his machine, the only requirements for which are the presence of the language runtime environment and the package manager. Everything you need to run the application code can be configured using a specific configuration command . For example, for Ruby / Bundler, the configuration team is
The application of the twelve factors also does not rely on the implicit existence of any system tools. An example is the launch of the ImageMagick and
Application configuration is all that can change between deployments (development environment, intermediate and production deployment). It includes:
Sometimes applications store configurations as constants in code. This is a violation of the methodology of the twelve factors, which requires a strict separation of configuration and code . The configuration can vary significantly between deployments; the code should not differ.
The litmus test of whether the configuration and application code are properly separated is the fact that the application code base can be freely available at any time without compromising any private data.
Note that this “configuration” definition does not include internal application configurations, such as 'config / routes.rb' in Rails, or how the main modules will be connected in Spring . This type of configuration does not change between deployments and therefore it is best to keep it in code.
Another approach to configuration is to use configuration files that are not saved to the version control system, for example, 'config / database.yml' in Rails. This is a huge improvement before using constants that are saved in the code, but there are still some disadvantages to this method: it is easy to save the configuration file by mistake to the repository; There is a tendency when configuration files are scattered in different places and in different formats, because of this it becomes difficult to view and manage all settings in one place. In addition, the formats of these files are usually specific for a particular language or framework.
An appendix of twelve factors stores configuration in environment variables (often abbreviated to env vars or env ). Environment variables are easy to change between deployments without changing code; unlike configuration files, it is less likely to accidentally save them to the code repository; and unlike custom configuration files or other configuration mechanisms, such as Java System Properties, they are a language and operating system independent standard.
Another approach to configuration management is grouping. Sometimes applications group configurations into named groups (often called “environments”) named for a specific deployment, such as
In the application of the twelve factors, environment variables are unrelated controls, where each environment variable is completely independent of the others. They are never grouped together in an “environment”, but instead are managed independently for each deployment. This model is scaled gradually along with the natural appearance of more application deployments during its lifetime.
A third-party service is any service that is available to an application over the network and is necessary as part of its normal operation. For example, data stores (for example, MySQL and CouchDB ), message queuing systems (for example, RabbitMQ and Beanstalkd ), SMTP services for outgoing e-mail (for example, Postfix ), and caching systems (for example, Memcached ).
Traditionally, third-party services, such as databases, are supported by the same system administrator who deploys the application. In addition to local services, an application can use services provided and managed by a third party. Examples include SMTP services (for example, Postmark ), metrics collection services (such as New Relic and Loggly ), binary data storages (eg Amazon S3 ), and the use of various services APIs (such as Twitter , Google Maps and Last.fm ) .
The application code of the twelve factors does not distinguish between local and third-party services. For an application, each of them is a pluggable resource accessible by a URL or a different location / credential pair stored in the configuration . Each deployment of an application of twelve factors should be able to replace the local MySQL database with any third-party managed (for example Amazon RDS ) without any changes to the application code. Similarly, the local SMTP server can be replaced with a third-party (for example, Postmark) without changing the code. In both cases, you only need to change the resource identifier in the configuration.
Every different third-party service is a resource . For example, a MySQL database is a resource; two MySQL databases (used for fragmentation at the application level) are qualified as two separate resources. An appendix of twelve factors considers these databases to be connected resources , indicating that they are weakly linked to the deployment in which they are connected.

Resources can optionally be connected to the deployment and disconnected from the deployment. For example, if the application database is not functioning properly due to hardware problems, the administrator can start a new database server restored from the latest backup. The current working database can be disabled, and the new database is connected - all this without any code changes.
The code base is transformed into deployment (not taking into account the deployment for development) in three stages:
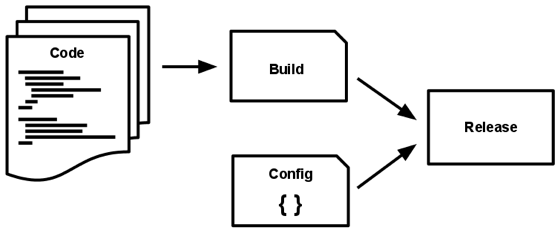
The application of the twelve factors uses a strict separation between the stages of assembly, release and execution. For example, it is not possible to make changes to the code at runtime, as there is no way to propagate these changes back to the build phase.
Deployment tools, as a rule, are release management tools, and, importantly, give the opportunity to roll back to the previous release. For example, the Capistrano deployment tool stores releases in subdirectories of a directory named
Each release must have a unique identifier, such as a release time stamp (for example
The build is initiated by the application developer every time a new code is deployed. The execution phase, on the other hand, can occur automatically in such cases as a server restart, or a process manager restarting a fallen process. Thus, the execution phase should be as technically simple as possible, since problems that can prevent an application from starting can occur in the middle of the night when there are no developers available. The build phase may be more complicated, since possible errors are always visible to the developer who launched the deployment.
An application runs in the runtime as one or more processes .
In the simplest case, the code is an independent script, the runtime is a developer’s laptop with the language runtime installed, and the process is started from the command line (for example, as
The processes of application of the twelve factors do not preserve the internal state (stateless) and do not have shared data (share-nothing) . Any data that needs to be stored must be stored in a state - storing third-party service , usually in a database.
The memory and file system of the process can be used as a temporary cache for a single transaction. For example, loading, processing and saving a large file in a database. The application of the twelve factors does not imply that something cached in memory or on disk will be available to the following requests or tasks — with a large number of diverse processes, it is highly likely that the next request will be processed by another process. Even with one process running, restarting (caused by deployment, changing configurations or transferring the process to another physical device) will result in the destruction of all local (memory, file system) states.
Asset packers (for example, Jammit or django-compressor ) use the file system as a cache for compiled resources. The application of the twelve factors prefers to do this compilation during the assembly stage , for example, as in the Rails asset pipeline , rather than at run time.
Some web systems rely on “sticky sessions” - that is, they cache user session data in the application's process memory and expect subsequent requests from the same user to be redirected to the same process. Sticky sessions are a violation of twelve factors and should never be used or relied on. User session data are good candidates for a data warehouse that provides a function to limit storage time, for example, Memcached and Redis .
Sometimes web applications run inside a web server container. For example, a PHP application can be launched as a module inside Apache HTTPD , or a Java application can be launched inside Tomcat .
The application of the twelve factors is completely self-sufficient and does not rely on the injection of a web server at run time in order to create a web service. The web application exports the HTTP service by binding to a port and listens for requests arriving at this port.
During local development, the developer follows the URL of the form
This is typically implemented using dependency declarations to add a web server library to an application such as Tornado in Python, Thin in Ruby, and Jetty in Java and other JVM-based languages. This happens entirely in user space , that is, in the application code. The contract with the runtime environment is the binding of the application to the port for processing requests.
HTTP is not the only service that can be exported via port mapping. Almost any type of server software can be run as a process associated with a port and waiting for incoming requests. Examples of this include ejabberd (provides the XMPP protocol ) and Redis (provides the Redis protocol ).
Also note that the port-binding approach means that one application can act as a third-party service for another application by providing the URL of the third-party application as a resource identifier in the configuration of the consuming application.
Any computer program after launch represents one or more running processes. Historically, web applications have taken different forms of process execution. For example, PHP processes will run as Apache child processes and run on demand in the quantity required to service incoming requests. Java processes use the opposite approach, the JVM is a single monolithic meta-process that reserves a large amount of system resources (processor and memory) at startup and manages parallelism within itself using execution threads. In both cases, the running processes are only minimally visible to the application developer.

In an appendix of twelve factors, processes are first-class entities. The processes in the appendix of twelve factors took strengths from the unix process model for running daemons . Using this model, the developer can design his application in such a way that for processing different workloads, it is necessary to assign each type of work to its own type of process . For example, HTTP requests can be processed by a web process, and lengthy background tasks are processed by a workflow.
/ , EventMachine , Twisted Node.js . ( ), .
, , , . , . (process formation) .
PID . (, Upstart , , Foreman ) , .
, , . , .
. , , , . and scaling. In addition, it is more reliable, since the process manager can freely transfer processes to new physical machines if necessary.
Processes must complete properly when they receive a SIGTERM signal from the process manager. For the web process, the correct shutdown is achieved by stopping listening to the service port (thus, abandoning any new requests), which allows you to complete current requests and then end. In this model, it is assumed that HTTP requests are short (no more than a few seconds); in the case of long requests, the client should smoothly try to reestablish the connection when the connection is lost.
, (worker), . , RabbitMQ
. ,
( ) ( ). :
An application of twelve factors is designed for continuous deployment by minimizing the differences between application development and operation. Consider the three differences described above:
Summarizing the above table:
, , , , . , , . , .
, . SQLite PostgreSQL ; Memcached .
, . , , , , . , . , .
, . , Memcached, PostgreSQL RabbitMQ , Homebrew apt-get . , , Chef Puppet , Vagrant . / .
- , . ( , ) .
Logging provides a visual representation of the behavior of a running application. Usually in a server environment, the log is written to a disk file (“logfile”), but this is only one of the output formats.
A log is a stream of aggregated, time-ordered events, collected from the output streams of all running processes and auxiliary services. The log in its raw form is usually represented by a text format with one event per line (although exception traces may take several lines). The log has no fixed start and end, the message flow is continuous while the application is running.
The application of the twelve factors never deals with the routing and storage of its output stream. .
, . , . (, Logplex and Fluent ) can be used for this purpose.
The event flow of the application can be redirected to a file or viewed in the terminal in real time. Most importantly, the event stream can be sent to an indexing and analyzing system for logs, such as Splunk , or a general purpose storage system, such as Hadoop / Hive . These systems have great capabilities and flexibility for a thorough analysis of the behavior of the application over time, which includes:
, ( -), . , , :
. , , , . , .
. , - Ruby
The methodology of the twelve factors gives preference to languages that provide a REPL shell out of the box, and which make it easy to execute one-time scripts. In a local deployment, developers perform a one-time administration process using a console command within the application directory. In a working deployment, developers can use ssh or another remote command execution mechanism provided by the runtime to start such a process.
Bug fixes and more suitable translations can be sent:
amalinin litchristina
Introduction
Nowadays, software is usually distributed in the form of services called web applications (web apps) or software-as-a-service (SaaS). An appendix of twelve factors is a methodology for creating SaaS applications that:
- Use a declarative format to describe the installation and configuration process, which minimizes the time and resources for new developers connected to the project;
- Have an agreement with the operating system that assumes maximum portability between runtime environments;
- Suitable for deployment on modern cloud platforms , eliminating the need for servers and system administration;
- Minimize discrepancies between the development environment and the runtime environment, which allows continuous deployment to maximize flexibility;
- And can scale without significant changes in the tools, architecture and development practices.
The methodology of the twelve factors can be applied to applications written in any programming language that use any combination of third-party services (backing services) (databases, message queues, cache memory, etc.).
Prerequisites
Contributors to this document were directly involved in the development and deployment of hundreds of applications and indirectly witnessed the development, implementation and scaling of hundreds of thousands of applications during our work on the Heroku platform.
')
This document summarizes our entire experience of using and observing a wide variety of SaaS applications in the wild. The document is a combination of three ideal approaches to application development: focusing on the dynamics of organic growth of an application over time, the dynamics of cooperation between developers working on the application code base and the elimination of the effects of software erosion .
Our motivation is to raise awareness of some system problems that we have encountered in the practice of developing modern applications, as well as to provide common basic concepts for discussing these problems and propose a set of common conceptual solutions to these problems with associated terminology. The format is inspired by the books of Martin Fowler (Martin Fowler) Patterns of Enterprise Application Architecture and Refactoring .
Who should read this document?
Developers who create SaaS applications. Ops to engineers deploying and managing such applications.
Twelve factors
I. Code base
One code base tracked in a version control system - multiple deployments
Ii. Dependencies
Explicitly declare and isolate dependencies
Iii. Configuration
Save the configuration in runtime
Iv. Third Party Services (Backing Services)
Consider third-party services (backing services) connected resources
V. Build, Release, Execution
Strictly separate the assembly and execution stages
Vi. Processes
Run the application as one or more non-stateless processes (stateless)
VII. Port binding
Export services through port mapping
Viii. Parallelism
Scale an application using processes
Ix. Disposability
Maximize reliability with quick startup and proper shutdown
X. Par development / application performance
Keep the development, staging and production deployment environments as similar as possible.
Xi. Logging (Logs)
View the log as a stream of events.
Xii. Admin Tasks
Perform administration / management tasks using one-time processes.
I. Code base
One code base tracked in a version control system - multiple deployments
An application of twelve factors is always tracked in a version control system such as Git , Mercurial or Subversion . A copy of the database of monitored versions is called a code repository , which is often shortened to code repo or simply to repository (repo)
A codebase is one repository (in centralized version control systems, like Subvertion), or multiple repositories that have common initial commits (in decentralized version control systems, like Git).
There is always a one-to-one correspondence between the code base and the application:
- If there are several code bases, then this is not an application - it is a distributed system. Each component in a distributed system is an application and each component can individually correspond to twelve factors.
- The fact that several applications share the same code is a violation of twelve factors. The solution in this situation is the allocation of common code in the library, which can be connected through a dependency manager .
There is only one code base for each application, but there can be multiple deployments of the same application. Deployed application (deploy) is a running instance of the application. As a rule, this is a working site deployment and one or more intermediate site deployments. In addition, each developer has a copy of the application running in his local development environment, each of which also qualifies as an deployed application (deploy).
The code base should be the same for all deployments, but different versions of the same code base can be executed in each of the deployments. For example, a developer may have some changes that have not yet been added to a staged deployment; intermediate deployment may have some changes that have not yet been added to the production deployment. However, all these deployments use the same code base, so they can be identified as different deployments of the same application.
Ii. Dependencies
Explicitly declare and isolate dependencies
Most programming languages come with a package manager for distributing libraries, such as CPAN in Perl or Rubygems in Ruby. Libraries installed by the package manager can be installed accessible to the entire system (so-called “system packages”) or available only to an application in the directory containing the application (so-called “vendoring” and “bundling”).
The application of the twelve factors never depends on implicitly existing packages available to the whole system. The application declares all its dependencies completely and accurately using the manifest of the dependency declaration . In addition, it uses the dependency isolation tool at run time to ensure that implicit dependencies do not “leak” from the surrounding system. A complete and explicit specification of dependencies applies equally to both the development and operation of the application.
For example, Gem Bundler in Ruby uses
Gemfile as a manifest format for declaring dependencies and bundle exec to isolate dependencies. Python has two different tools for these tasks: Pip is used for declarations and Virtualenv for isolation. Even C has Autoconf for declaring dependencies, and static binding can provide dependency isolation. Regardless of which toolset is used, the declaration and isolation of dependencies should always be used together — only one of them is not enough to satisfy the twelve factors.One of the advantages of explicitly declaring dependencies is that it simplifies application customization for new developers. The new developer can copy the application code base onto his machine, the only requirements for which are the presence of the language runtime environment and the package manager. Everything you need to run the application code can be configured using a specific configuration command . For example, for Ruby / Bundler, the configuration team is
bundle install , for Clojure / Leiningen this is lein deps .The application of the twelve factors also does not rely on the implicit existence of any system tools. An example is the launch of the ImageMagick and
curl programs. Although these tools may be present in many or even most systems, there is no guarantee that they will be present on all systems where the application may work in the future, or whether the version found in another system is compatible with the application. If an application needs to run a system tool, then this tool must be included in the application.Translator Comments
Iii. Configuration
Save the configuration in runtime
Application configuration is all that can change between deployments (development environment, intermediate and production deployment). It includes:
- Identifiers for connecting to database type resources, cache, and other third-party services
- Registration data for connecting to external services, such as Amazon S3 or Twitter
- Values dependent on the deployment environment such as the canonical name of the host
Sometimes applications store configurations as constants in code. This is a violation of the methodology of the twelve factors, which requires a strict separation of configuration and code . The configuration can vary significantly between deployments; the code should not differ.
The litmus test of whether the configuration and application code are properly separated is the fact that the application code base can be freely available at any time without compromising any private data.
Note that this “configuration” definition does not include internal application configurations, such as 'config / routes.rb' in Rails, or how the main modules will be connected in Spring . This type of configuration does not change between deployments and therefore it is best to keep it in code.
Another approach to configuration is to use configuration files that are not saved to the version control system, for example, 'config / database.yml' in Rails. This is a huge improvement before using constants that are saved in the code, but there are still some disadvantages to this method: it is easy to save the configuration file by mistake to the repository; There is a tendency when configuration files are scattered in different places and in different formats, because of this it becomes difficult to view and manage all settings in one place. In addition, the formats of these files are usually specific for a particular language or framework.
An appendix of twelve factors stores configuration in environment variables (often abbreviated to env vars or env ). Environment variables are easy to change between deployments without changing code; unlike configuration files, it is less likely to accidentally save them to the code repository; and unlike custom configuration files or other configuration mechanisms, such as Java System Properties, they are a language and operating system independent standard.
Another approach to configuration management is grouping. Sometimes applications group configurations into named groups (often called “environments”) named for a specific deployment, such as
development , test and production environments in Rails. This method is not scalable enough: the more different application deployments are created, the more new environment names are needed, such as staging and qa . With the further growth of the project, developers can add their own special environments, such as joes-staging , resulting in a combinatorial explosion of configurations, which makes the management of application deployments very fragile.In the application of the twelve factors, environment variables are unrelated controls, where each environment variable is completely independent of the others. They are never grouped together in an “environment”, but instead are managed independently for each deployment. This model is scaled gradually along with the natural appearance of more application deployments during its lifetime.
Translator Comments
Iv. Third Party Services (Backing Services)
Consider third-party services (backing services) connected resources
A third-party service is any service that is available to an application over the network and is necessary as part of its normal operation. For example, data stores (for example, MySQL and CouchDB ), message queuing systems (for example, RabbitMQ and Beanstalkd ), SMTP services for outgoing e-mail (for example, Postfix ), and caching systems (for example, Memcached ).
Traditionally, third-party services, such as databases, are supported by the same system administrator who deploys the application. In addition to local services, an application can use services provided and managed by a third party. Examples include SMTP services (for example, Postmark ), metrics collection services (such as New Relic and Loggly ), binary data storages (eg Amazon S3 ), and the use of various services APIs (such as Twitter , Google Maps and Last.fm ) .
The application code of the twelve factors does not distinguish between local and third-party services. For an application, each of them is a pluggable resource accessible by a URL or a different location / credential pair stored in the configuration . Each deployment of an application of twelve factors should be able to replace the local MySQL database with any third-party managed (for example Amazon RDS ) without any changes to the application code. Similarly, the local SMTP server can be replaced with a third-party (for example, Postmark) without changing the code. In both cases, you only need to change the resource identifier in the configuration.
Every different third-party service is a resource . For example, a MySQL database is a resource; two MySQL databases (used for fragmentation at the application level) are qualified as two separate resources. An appendix of twelve factors considers these databases to be connected resources , indicating that they are weakly linked to the deployment in which they are connected.
Resources can optionally be connected to the deployment and disconnected from the deployment. For example, if the application database is not functioning properly due to hardware problems, the administrator can start a new database server restored from the latest backup. The current working database can be disabled, and the new database is connected - all this without any code changes.
V. Build, Release, Execution
Strictly separate the assembly and execution stages
The code base is transformed into deployment (not taking into account the deployment for development) in three stages:
- The build phase is a transformation that converts the code repository into an executable package called an assembly . Using the code version of the commit specified by the deployment process, the build phase loads third-party dependencies and compiles binaries and assets.
- The release phase accepts the build obtained during the build phase and combines it with the current deployment configuration . The resulting release contains the build and configuration and is ready for immediate launch in the runtime environment.
- The execution phase (also known as “runtime”) launches the application in the runtime environment by running some set of application processes from a specific release.
The application of the twelve factors uses a strict separation between the stages of assembly, release and execution. For example, it is not possible to make changes to the code at runtime, as there is no way to propagate these changes back to the build phase.
Deployment tools, as a rule, are release management tools, and, importantly, give the opportunity to roll back to the previous release. For example, the Capistrano deployment tool stores releases in subdirectories of a directory named
releases , where the current release is a symbolic link to the current release directory. The Capistrano rollback command allows you to quickly roll back to the previous release.Each release must have a unique identifier, such as a release time stamp (for example
2015-04-06-15:42:17 ) or an increasing number (for example, v100 ). Releases can only be added and each release cannot be changed after its creation. Any changes are required to create a new release.The build is initiated by the application developer every time a new code is deployed. The execution phase, on the other hand, can occur automatically in such cases as a server restart, or a process manager restarting a fallen process. Thus, the execution phase should be as technically simple as possible, since problems that can prevent an application from starting can occur in the middle of the night when there are no developers available. The build phase may be more complicated, since possible errors are always visible to the developer who launched the deployment.
Vi. Processes
Run the application as one or more processes that do not save the internal state (stateless)
An application runs in the runtime as one or more processes .
In the simplest case, the code is an independent script, the runtime is a developer’s laptop with the language runtime installed, and the process is started from the command line (for example, as
python my_script.py ). Another extreme option is a working deployment of a complex application that can use many types of processes, each of which is launched in the required number of instances .The processes of application of the twelve factors do not preserve the internal state (stateless) and do not have shared data (share-nothing) . Any data that needs to be stored must be stored in a state - storing third-party service , usually in a database.
The memory and file system of the process can be used as a temporary cache for a single transaction. For example, loading, processing and saving a large file in a database. The application of the twelve factors does not imply that something cached in memory or on disk will be available to the following requests or tasks — with a large number of diverse processes, it is highly likely that the next request will be processed by another process. Even with one process running, restarting (caused by deployment, changing configurations or transferring the process to another physical device) will result in the destruction of all local (memory, file system) states.
Asset packers (for example, Jammit or django-compressor ) use the file system as a cache for compiled resources. The application of the twelve factors prefers to do this compilation during the assembly stage , for example, as in the Rails asset pipeline , rather than at run time.
Some web systems rely on “sticky sessions” - that is, they cache user session data in the application's process memory and expect subsequent requests from the same user to be redirected to the same process. Sticky sessions are a violation of twelve factors and should never be used or relied on. User session data are good candidates for a data warehouse that provides a function to limit storage time, for example, Memcached and Redis .
VII. Port binding
Export services through port mapping
Sometimes web applications run inside a web server container. For example, a PHP application can be launched as a module inside Apache HTTPD , or a Java application can be launched inside Tomcat .
The application of the twelve factors is completely self-sufficient and does not rely on the injection of a web server at run time in order to create a web service. The web application exports the HTTP service by binding to a port and listens for requests arriving at this port.
During local development, the developer follows the URL of the form
localhost:5000/ localhost:5000/ to access the service provided by its application. When deployed, the routing layer processes requests to the public host and redirects them to the port-bound web application.This is typically implemented using dependency declarations to add a web server library to an application such as Tornado in Python, Thin in Ruby, and Jetty in Java and other JVM-based languages. This happens entirely in user space , that is, in the application code. The contract with the runtime environment is the binding of the application to the port for processing requests.
HTTP is not the only service that can be exported via port mapping. Almost any type of server software can be run as a process associated with a port and waiting for incoming requests. Examples of this include ejabberd (provides the XMPP protocol ) and Redis (provides the Redis protocol ).
Also note that the port-binding approach means that one application can act as a third-party service for another application by providing the URL of the third-party application as a resource identifier in the configuration of the consuming application.
Viii. Parallelism
Scale application with processes
Any computer program after launch represents one or more running processes. Historically, web applications have taken different forms of process execution. For example, PHP processes will run as Apache child processes and run on demand in the quantity required to service incoming requests. Java processes use the opposite approach, the JVM is a single monolithic meta-process that reserves a large amount of system resources (processor and memory) at startup and manages parallelism within itself using execution threads. In both cases, the running processes are only minimally visible to the application developer.
In an appendix of twelve factors, processes are first-class entities. The processes in the appendix of twelve factors took strengths from the unix process model for running daemons . Using this model, the developer can design his application in such a way that for processing different workloads, it is necessary to assign each type of work to its own type of process . For example, HTTP requests can be processed by a web process, and lengthy background tasks are processed by a workflow.
/ , EventMachine , Twisted Node.js . ( ), .
, , , . , . (process formation) .
PID . (, Upstart , , Foreman ) , .
Ix. (Disposability)
, , . , .
. , , , . and scaling. In addition, it is more reliable, since the process manager can freely transfer processes to new physical machines if necessary.
Processes must complete properly when they receive a SIGTERM signal from the process manager. For the web process, the correct shutdown is achieved by stopping listening to the service port (thus, abandoning any new requests), which allows you to complete current requests and then end. In this model, it is assumed that HTTP requests are short (no more than a few seconds); in the case of long requests, the client should smoothly try to reestablish the connection when the connection is lost.
, (worker), . , RabbitMQ
NACK ; Beanstalkd , . , , Delayed Job , . , , .. ,
SIGTERM , . , Beanstalkd, . , . (Crash-only design) .X. /
, (staging) (production)
( ) ( ). :
- : , , .
- : , OPS .
- : , Nginx, SQLite, OS X, Apache, MySQL Linux.
An application of twelve factors is designed for continuous deployment by minimizing the differences between application development and operation. Consider the three differences described above:
- Make the time difference small: a developer can write code, and it will be deployed in a few hours or even minutes.
- Make small differences in personnel: the developer who wrote the code, actively participates in its deployment and monitors its behavior while the application is running.
- Make the differences between tools small: keep the development environment and application work as similar as possible.
Summarizing the above table:
| Traditional application | Appendix twelve factors | |
|---|---|---|
| Time between deployments | Weeks | Clock |
| The author of the code / the one who unfolds | Different people | Same people |
| / |
, , , , . , , . , .
| Type of | Tongue | ||
|---|---|---|---|
| Database | Ruby/Rails | ActiveRecord | MySQL, PostgreSQL, SQLite |
| Python/Django | Celery | RabbitMQ, Beanstalkd, Redis | |
| Cache | Ruby/Rails | ActiveSupport::Cache | , , Memcached |
, . SQLite PostgreSQL ; Memcached .
, . , , , , . , . , .
, . , Memcached, PostgreSQL RabbitMQ , Homebrew apt-get . , , Chef Puppet , Vagrant . / .
- , . ( , ) .
Xi. (Logs)
Logging provides a visual representation of the behavior of a running application. Usually in a server environment, the log is written to a disk file (“logfile”), but this is only one of the output formats.
A log is a stream of aggregated, time-ordered events, collected from the output streams of all running processes and auxiliary services. The log in its raw form is usually represented by a text format with one event per line (although exception traces may take several lines). The log has no fixed start and end, the message flow is continuous while the application is running.
The application of the twelve factors never deals with the routing and storage of its output stream. .
stdout . , ., . , . (, Logplex and Fluent ) can be used for this purpose.
The event flow of the application can be redirected to a file or viewed in the terminal in real time. Most importantly, the event stream can be sent to an indexing and analyzing system for logs, such as Splunk , or a general purpose storage system, such as Hadoop / Hive . These systems have great capabilities and flexibility for a thorough analysis of the behavior of the application over time, which includes:
- Search for specific events in the past.
- Large-scale trend charts (for example, requests per minute).
- , (, , ).
:
: Elasticsearch , Logstash , Kibana (ELK).
- Papertrail papertrailapp.com
- Loggly www.loggly.com
- Logentries logentries.com
: Elasticsearch , Logstash , Kibana (ELK).
XII. Admin Tasks
/
, ( -), . , , :
- (
manage.py migrateDjango,rake db:migrateRails). - ( REPL ), . REPL - (,
pythonorperl), (irbRuby,rails consoleRails). - , (,
php scripts/fix_bad_records.php).
. , , , . , .
. , - Ruby
bundle exec thin start , bundle exec rake db:migrate . Python Virtualenv bin/pythonboth for starting the Tornado web server, and for starting any manage.pyadministration processes.The methodology of the twelve factors gives preference to languages that provide a REPL shell out of the box, and which make it easy to execute one-time scripts. In a local deployment, developers perform a one-time administration process using a console command within the application directory. In a working deployment, developers can use ssh or another remote command execution mechanism provided by the runtime to start such a process.
Bug fixes and more suitable translations can be sent:
- Comment here
- Personal message
- Pull rekvest on GitHub
- ( )
amalinin litchristina
Source: https://habr.com/ru/post/258739/
All Articles