Branch model and git module management for a large project
Almost two years ago, we began using the new model of branching and managing git submodules in the development of our flagship DBMS Linter project. Tens of thousands of commits made during this time by a group of developers make it possible to consider innovations successful with a certain degree of confidence. This article is a brief overview of the principles of organizing a source code repository in a large project based on an alternative implementation of git modules, the established branching strategy and linflow toolkit.
Previously, Linter source codes were stored in CVS. Despite the obsolescence of this version control system, it possessed certain features that we actively used (in part, this allowed the dinosaur to hold out for so long): to work on a specific task, it was possible to extract only the necessary modules with its dependencies. This is convenient, since the modules in our project are mostly mutually low and free mate.
Technically, the process of obtaining the necessary source codes was organized more simply: the server stored a set of modules in directories, but the developer had extraction tools and a file descriptor for the tree needed for a particular process. For greater clarity, here is a small fragment of such a descriptor:
')
It is easy to see that the rules determined not only which modules should be extracted, but also where to extract them, that is, the tree in the central repository and the tree in the working copy were different. These file descriptors varied for different target distributions, operating systems, and versions of the DBMS.
But as you know, git does not provide a simple mechanism for cloning a part of the repository. Therefore, when there was a question about migration from CVS to git, first of all we considered the two most obvious ways to organize it: use a single repository (mono-repository) for the entire project tree with the inevitable changes to the product assembly process or store the project in a collection of independent modules and use git-ovsky submodule / subtree to work with them.
The idea of using one repository for the entire project tree was abandoned almost immediately. And for good reason:
If there were no difficulties in terms of storing a group of modules in the main repository, then there were difficulties with their cloning into the correct working tree. Of course, git supports native submodules and subtree, however, there are enough shortcomings in their use (see http://habrahabr.ru/post/75964/ ), such are the architectural features of this version control system. But the most unpleasant moment was the need to ensure that the main repository of the module-container did not get links to non-public states of the child modules. So, after working with the experimental repository, we came to the conclusion that we need an alternative mechanism for managing modules on the client side.
To eliminate the shortcomings of the native git submodules and git subtree, we have developed our own module management mechanism, which functions above the git level. The implementation of this mechanism has become part of the toolkit we call linflow.
The scheme is quite simple: each of the project modules is stored in a separate repository with exported history, and one of the modules (in our case it has the name linter.git) is a container module that does not contain any source codes and its main task is to set tree of global branches for everyone else. Each of these global branches in the container module may have its own file descriptor (with the name .linmodules) necessary to retrieve the correct project tree.
However surprising it may sound to the reader, who was fortunate enough to not work daily with native git submodules, but this scheme turned out to be simpler and more convenient than a regular implementation.
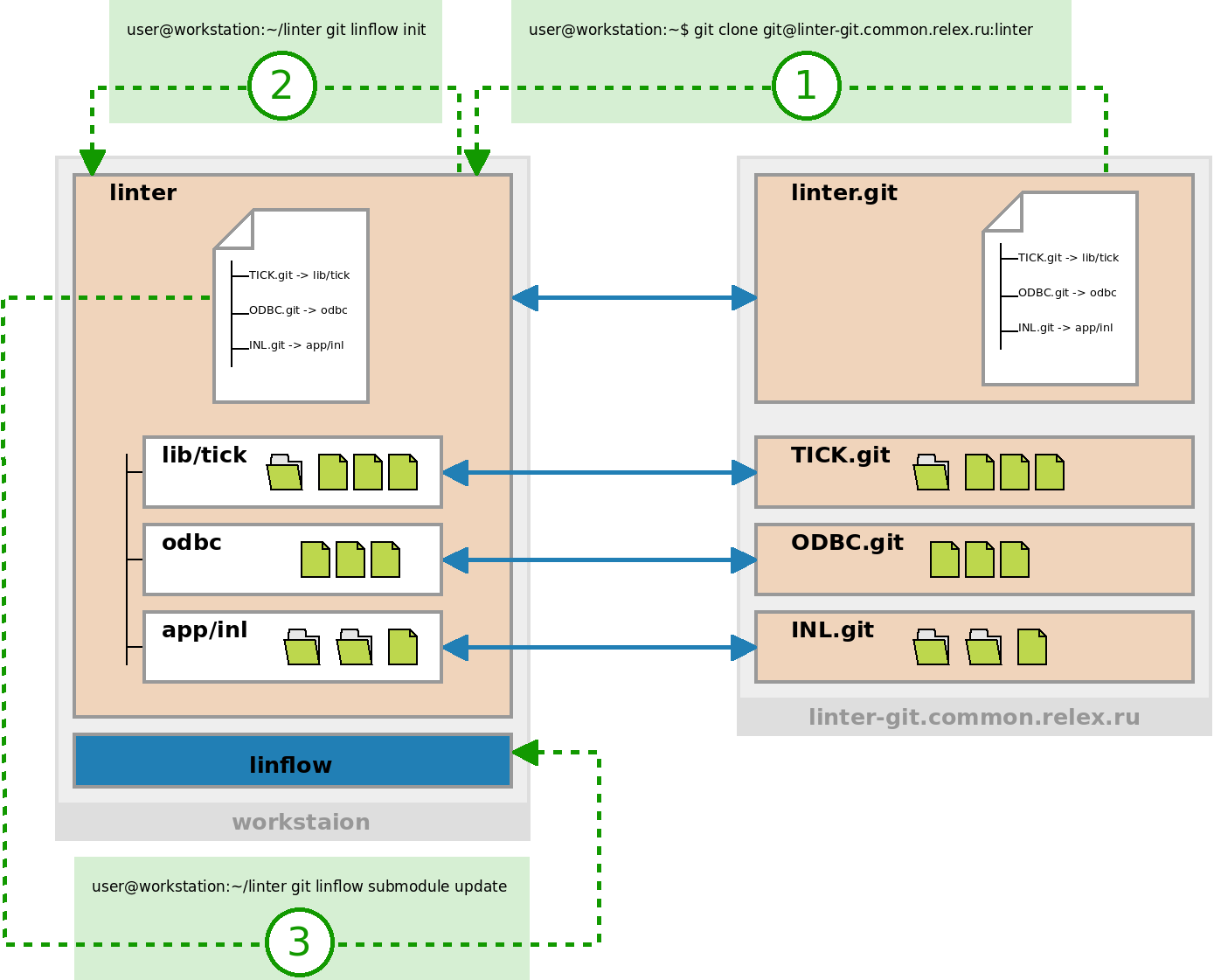
Figure 1: How to get the source tree version. 1 - cloning of a module-container with a file descriptor, 2 - initialization, 3 - cloning of registered modules into target directories.
The syntax of the template description (the .linmodules file) repeats the “native”, which is used in git for the .gitmodules file. This was done intentionally for backward compatibility.
Here is a fragment of the placement pattern from Figure 1:
Thus, we managed to keep the ability to extract modules into an arbitrary working copy structure. The initial formation of templates and their subsequent change is made by means of linflow.
It would not be a big mistake to assume that many developers looking for the optimal organization of their git-based repositories are familiar with the work of Vincent Driessen “A successful Git branching model” (those who didn’t have time to do this can always familiarize themselves with the original http: // nvie .com / posts / a-successful-git-branching-model / or by transferring to habr ( http://habrahabr.ru/post/106912/ ). We did not become an exception and, having begun testing the model, made adjustments to it, as a result we came to our own, which inherited some features of the “parent” one. And although the title of the original article is cunning (the model is really successful), but this is true exactly until it becomes necessary to apply it to a really large project with a long history.
There were several reasons why the “successful” model from Vincent Driessen demanded changes. We present only the most important for us in the order of their appearance and solution:
The result of the work on the modification of the “successful” model was the creation of its own strategy, which partly inherits some of the terms, agreements, naming and original workflows. For the sake of simplicity, we will highlight the key changes, which will be discussed in more detail below:
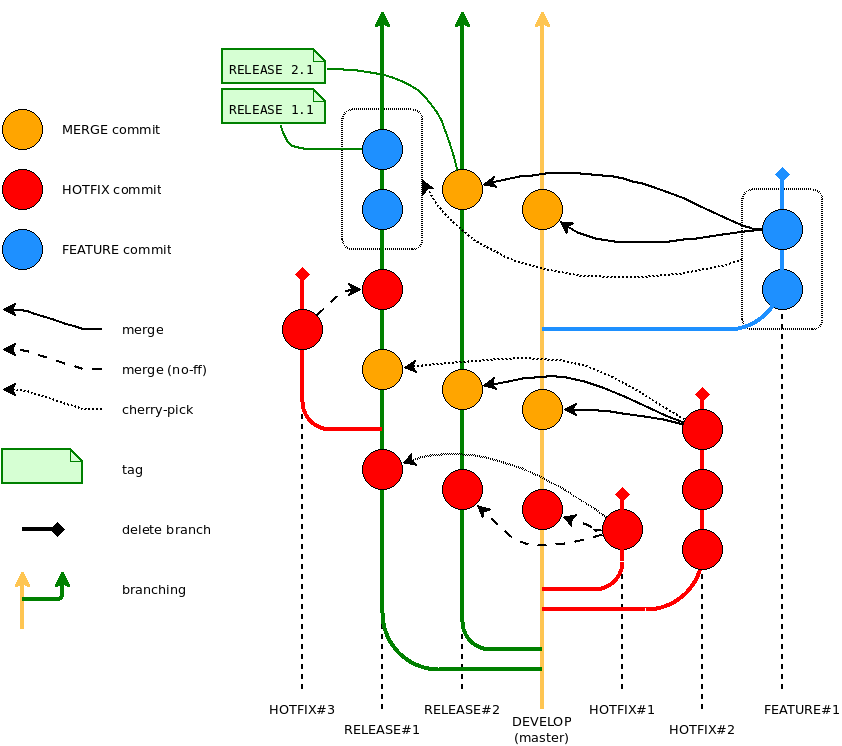
Figure 2: A variant of branching and code transfer in a module. The release branch RELEASE # 2 is the newest and allows you to transfer edits using merge, RELEASE # 1 supports the previous version and receives changes selectively.
The central repository contains a group of branches that exists all the time and in all modules :
The origin / release branches are considered to be the main production ones, i.e. the source code for them should allow to release a version or build at any time. The origin / master branch is considered the main production one, which contains all changes to the project and serves as the source for creating origin / release . When the source code in origin / master is ready for release, the changes should be transferred in a certain way to the corresponding origin / release or generate a new version, and therefore - a branch in origin / release .
In addition to the main branches, the structure of the repositories (both central and working copies) implies the presence of auxiliary branches of the following types:
Each of these types of branches has a specific purpose and a set of rules of reference, which will be described below.

Figure 3: Distribution of branches by modules: the main branches are present in all, auxiliary branches - only in the necessary ones.
General rules for maintaining branches in the central and local repositories:
The branches of releases ( release branches ) are referred to as release / Blinter_AB_C , where A is the major version, B is the minor version, and C is the release number. Release branches originate from develop, and there are all the time support for the Linter version. The branch is the recipient of the code: there is no development in it. Each fact of the release of a new build is marked with the corresponding tag of the form Blinter_AB_C_D , where D is the build number. Branches of this type can be links (from the point of view of organization to origin ) to another release branch. In this case, the publication in one of these branches will lead to an update of all related. The release branch is global, i.e., it exists in all modules if created in a module-container. Tags with build tags are set at the same time in all modules.
The branches of corrections ( fix branches ) are referred to as hotfix / * , can be generated from develop (mostly) or release, can be merged into develop (master) and release . If the fixes contain one commit, the merge is performed without creating a merge commit. The final commit in the comment body contains a reference to the number of the corresponding ticket in the bugtracker. After the edits are migrated, the repair branch closes.
The branches of the functionality are referred to as feature / * and are generated only from develop (master) .
The branches of functionality ( feature branches ) are used to develop new features that should appear in current or future releases. A branch exists for as long as the development of functionality continues. As interim results are achieved, the branch is published in the central repository. When the work in the branch is completed, the latter necessarily merges into the main branch of development (which means that the functionality will be added to the next release) and optionally into the release branches. After the code is migrated, the branch of functionality is closed.
It is worth saying a few words about the linflow toolkit, which has been mentioned several times above in the text. Linflow is intended for operations with modules of the source tree, as well as to support our branch model. The linflow client part is a fork of the git-flow project ( https://github.com/nvie/gitflow ), which has been modified for our strategy and extended to support linmodules. In addition, we developed the server part, which works as an extension for gitolite ( http://gitolite.com ).
The functional of module management in linflow allows:
The functionality of managing branches in linflow allows you to:
The functionality of the server part allows you to:
The possibility of publishing the full technical documentation on the branch model and linflow tools is currently being discussed. Not the last role in this can play responses (or lack thereof) to this publication.
Monorepository, git submodules, git subtree or ...
Previously, Linter source codes were stored in CVS. Despite the obsolescence of this version control system, it possessed certain features that we actively used (in part, this allowed the dinosaur to hold out for so long): to work on a specific task, it was possible to extract only the necessary modules with its dependencies. This is convenient, since the modules in our project are mostly mutually low and free mate.
Technically, the process of obtaining the necessary source codes was organized more simply: the server stored a set of modules in directories, but the developer had extraction tools and a file descriptor for the tree needed for a particular process. For greater clarity, here is a small fragment of such a descriptor:
')
#RepositoryDir Unix RELAPI relapi LINDESKX lindeskx KERNEL5/SQL sql KERNEL5/TSP tsp It is easy to see that the rules determined not only which modules should be extracted, but also where to extract them, that is, the tree in the central repository and the tree in the working copy were different. These file descriptors varied for different target distributions, operating systems, and versions of the DBMS.
But as you know, git does not provide a simple mechanism for cloning a part of the repository. Therefore, when there was a question about migration from CVS to git, first of all we considered the two most obvious ways to organize it: use a single repository (mono-repository) for the entire project tree with the inevitable changes to the product assembly process or store the project in a collection of independent modules and use git-ovsky submodule / subtree to work with them.
Mono-pository
The idea of using one repository for the entire project tree was abandoned almost immediately. And for good reason:
- Performance. No, we did not have 1.3 million files, as in tests from Facebook ( http://habrahabr.ru/post/137615/ ), but 114800 commits of the exported history for ~ 14000 files turned out to be enough to fix a noticeable drop in performance when working with an index.
- Story. A mono-repository has a general history of revisions: in one chain of logs, revisions of the kernel, examples, utilities, documentation, etc. can be intermixed.
- Support. The unification of the source tree would lead to a change in the assembly mechanisms for all versions of the product released since the end of the last century. Development of these releases, of course, is no longer underway, but I didn’t want to lose the opportunity to “blow off dust” from the archive version.
git submodules / git subtree
If there were no difficulties in terms of storing a group of modules in the main repository, then there were difficulties with their cloning into the correct working tree. Of course, git supports native submodules and subtree, however, there are enough shortcomings in their use (see http://habrahabr.ru/post/75964/ ), such are the architectural features of this version control system. But the most unpleasant moment was the need to ensure that the main repository of the module-container did not get links to non-public states of the child modules. So, after working with the experimental repository, we came to the conclusion that we need an alternative mechanism for managing modules on the client side.
linmodules
To eliminate the shortcomings of the native git submodules and git subtree, we have developed our own module management mechanism, which functions above the git level. The implementation of this mechanism has become part of the toolkit we call linflow.
The scheme is quite simple: each of the project modules is stored in a separate repository with exported history, and one of the modules (in our case it has the name linter.git) is a container module that does not contain any source codes and its main task is to set tree of global branches for everyone else. Each of these global branches in the container module may have its own file descriptor (with the name .linmodules) necessary to retrieve the correct project tree.
However surprising it may sound to the reader, who was fortunate enough to not work daily with native git submodules, but this scheme turned out to be simpler and more convenient than a regular implementation.
Figure 1: How to get the source tree version. 1 - cloning of a module-container with a file descriptor, 2 - initialization, 3 - cloning of registered modules into target directories.
The syntax of the template description (the .linmodules file) repeats the “native”, which is used in git for the .gitmodules file. This was done intentionally for backward compatibility.
Here is a fragment of the placement pattern from Figure 1:
[submodule "tick"] path = lib/tick url = git@linter-git.common.relex.ru:TICK [submodule "odbc"] path = odbc url = git@linter-git.common.relex.ru:ODBC [submodule "inl"] path = app/inl url = git@linter-git.common.relex.ru:INL Thus, we managed to keep the ability to extract modules into an arbitrary working copy structure. The initial formation of templates and their subsequent change is made by means of linflow.
Branching model
It would not be a big mistake to assume that many developers looking for the optimal organization of their git-based repositories are familiar with the work of Vincent Driessen “A successful Git branching model” (those who didn’t have time to do this can always familiarize themselves with the original http: // nvie .com / posts / a-successful-git-branching-model / or by transferring to habr ( http://habrahabr.ru/post/106912/ ). We did not become an exception and, having begun testing the model, made adjustments to it, as a result we came to our own, which inherited some features of the “parent” one. And although the title of the original article is cunning (the model is really successful), but this is true exactly until it becomes necessary to apply it to a really large project with a long history.
There were several reasons why the “successful” model from Vincent Driessen demanded changes. We present only the most important for us in the order of their appearance and solution:
- The original model does not specify the behavior when decomposing initial projects into submodules and modules with dependencies.
- The release branches cannot be closed while the product is being maintained, so at the time of this writing, bug fixes and part of the new functionality are being added to all versions released since the beginning of 2009. Because of this, builds of different versions of a product cannot be represented by a single sequence of commits on any branch.
- The branches of corrections and functionality can be transferred to the old versions that do not contain all the changes of the development branch, so merge is simply impossible.
- The overwhelming majority of corrections contain one commit (at the time of writing these lines from 2598 branches with corrections only 262 had two or more commit), therefore using the no-ff merge strategy, which generates an additional merge commit each time, is not very convenient.
The result of the work on the modification of the “successful” model was the creation of its own strategy, which partly inherits some of the terms, agreements, naming and original workflows. For the sake of simplicity, we will highlight the key changes, which will be discussed in more detail below:
- The rules for the maintenance of branches in the submodules of one project are stipulated;
- Changed the rules for working with the develop branch;
- Changed release rules for versions and, consequently;
- Changed release branch maintenance rules;
- Changed rules for transferring edits from branch to branch.
Figure 2: A variant of branching and code transfer in a module. The release branch RELEASE # 2 is the newest and allows you to transfer edits using merge, RELEASE # 1 supports the previous version and receives changes selectively.
Main branches
The central repository contains a group of branches that exists all the time and in all modules :
- release branches - a group of project branches, supplemented as versions are released;
- develop (master) - the main branch of development.
The origin / release branches are considered to be the main production ones, i.e. the source code for them should allow to release a version or build at any time. The origin / master branch is considered the main production one, which contains all changes to the project and serves as the source for creating origin / release . When the source code in origin / master is ready for release, the changes should be transferred in a certain way to the corresponding origin / release or generate a new version, and therefore - a branch in origin / release .
Auxiliary branches
In addition to the main branches, the structure of the repositories (both central and working copies) implies the presence of auxiliary branches of the following types:
- feature branches - branches of new functionality;
- fix branches
Each of these types of branches has a specific purpose and a set of rules of reference, which will be described below.
Figure 3: Distribution of branches by modules: the main branches are present in all, auxiliary branches - only in the necessary ones.
General rules
General rules for maintaining branches in the central and local repositories:
- develop (master) contains stable code;
- develop (master) exists in all modules;
- development on the develop (master) branch is prohibited;
- develop (master) stores the code required to release a new version or release ;
- if necessary, a new release from develop (master) branch release branches ;
- release branches store the code for the release of a new build ;
- build releases are tagged on the head commits of the corresponding release branches ;
- the creation of a branch of the type of branches in the module-container spawns the creation of a branch of the same name in each of the submodules (see Fig. 2);
- fix branches can branch from develop (master) or release branches and can join both develop (master) and release branches ;
- feature branches branch out only from develop (master) and necessarily join it;
- commits that form part of the branches , if necessary, can be transferred to one or several release branches (but this fact does not cancel the previous rule on mandatory merging with develop );
- branches feature branches and hotfix branches are regularly published in the central repository.
The branches of releases / versions (release branches)
The branches of releases ( release branches ) are referred to as release / Blinter_AB_C , where A is the major version, B is the minor version, and C is the release number. Release branches originate from develop, and there are all the time support for the Linter version. The branch is the recipient of the code: there is no development in it. Each fact of the release of a new build is marked with the corresponding tag of the form Blinter_AB_C_D , where D is the build number. Branches of this type can be links (from the point of view of organization to origin ) to another release branch. In this case, the publication in one of these branches will lead to an update of all related. The release branch is global, i.e., it exists in all modules if created in a module-container. Tags with build tags are set at the same time in all modules.
Fix branches
The branches of corrections ( fix branches ) are referred to as hotfix / * , can be generated from develop (mostly) or release, can be merged into develop (master) and release . If the fixes contain one commit, the merge is performed without creating a merge commit. The final commit in the comment body contains a reference to the number of the corresponding ticket in the bugtracker. After the edits are migrated, the repair branch closes.
Branches of functionality (feature branches)
The branches of the functionality are referred to as feature / * and are generated only from develop (master) .
The branches of functionality ( feature branches ) are used to develop new features that should appear in current or future releases. A branch exists for as long as the development of functionality continues. As interim results are achieved, the branch is published in the central repository. When the work in the branch is completed, the latter necessarily merges into the main branch of development (which means that the functionality will be added to the next release) and optionally into the release branches. After the code is migrated, the branch of functionality is closed.
linflow
It is worth saying a few words about the linflow toolkit, which has been mentioned several times above in the text. Linflow is intended for operations with modules of the source tree, as well as to support our branch model. The linflow client part is a fork of the git-flow project ( https://github.com/nvie/gitflow ), which has been modified for our strategy and extended to support linmodules. In addition, we developed the server part, which works as an extension for gitolite ( http://gitolite.com ).
The functional of module management in linflow allows:
- register / delete modules;
- edit the source and target directory of an existing module;
- initial setting of the working copy;
- monitor the status of the module-container and timely switch and update the nested modules;
- produce packaging modules;
- check the consistency of the entire project tree.
The functionality of managing branches in linflow allows you to:
- create / delete / publish branches of all allowed types;
- control over the implementation of the branch naming convention;
- consistently switch to branches and tags in all modules after the container module;
- perform bulk operations on modules;
- transfer code from branch to branch using different strategies;
- transfer code to branches with changed history;
- prevent erroneous removal of branches.
The functionality of the server part allows you to:
- to monitor compliance with the rules of naming;
- delimit the rights of users by roles;
- manage branch links;
- to send notifications of changes on a dynamically generated list of potential interested participants;
- make a full backup.
The possibility of publishing the full technical documentation on the branch model and linflow tools is currently being discussed. Not the last role in this can play responses (or lack thereof) to this publication.
Source: https://habr.com/ru/post/258505/
All Articles