Creating your own model for extracting information from the text using the web-API from Meanotek
Now there are many services that allow you to extract some information from texts, such as named entities, such as the names of people, organizations, places, dates, which allows you to solve some interesting problems. But much more interesting tasks are left out of the box.
What if you need the names of goods, and not all, but some specific? Or do we want to interpret commands for a mobile application? Split the address on the name of the street, home, city? How about highlighting the important facts from the client's appeal to the support service: “I am outraged by the quality of service in your company. Not so long ago, I ordered a laptop , but the manager spoke incorrectly and said that the goods had ended . ” Today I will talk about the new service that allows you to solve a wide range of tasks of extracting information from the text. This service we have just opened for public access.
What you need to work with the examples from this article : The article mainly considers the solution for the .NET Framework in C #. Any language for the .NET Framework or mono is also suitable. From other languages, you can also access the web-API, but there are no ready-made libraries yet, so you have to write the request code manually. It is not difficult, but here I will not explain in detail how to do it in order not to lose the main idea. You will also need internet access and an open port 8080. You will also need to register to receive a free key. It seems, basically everything.
How this article is organized: First, the task is explained, by the example of which the work of the API will be shown. The following is the code. Then a bit of theory is told about how the system works from the inside, and at the end it’s about the limitations of the current version, and when this system will be useful and when it will not.
')
Parse the problem : As an example, take the task of extracting the names of goods from the text. Those. “Buy a Canon I-SENSIS i6500 Laser Printer at the office supplies store.” It is necessary to find references to products to analyze information about products and prices on the Internet, or a system that displays product ads based on page content. Well, for various other purposes.
It may seem that the task is simple and it does not cost anything. For example, for some groups of goods, especially with English names, you can try to write regular expressions that distinguish the names of goods from the text. But this method does not allow to distinguish, for example, “Buy HTC One” (phone model) from „Samsung Apple Nokia phones” (just a list of manufacturers), which is often the case. Regular expressions will not help at all if you need products that are called in Russian, for example, “Atlant Atlas 500 is sold” - it’s not at all clear where the name begins.
Therefore, we will try to teach a computer to distinguish the name of a product from other text based on a number of examples. The main advantage of this approach is that you don’t have to invent an algorithm yourself, and the minus is the need to manually create examples for learning.
What should the examples look like? Suppose we have the following sentence: “Buy Samsung Galaxy S4 in the“ Our phones ”store. We divide it into separate words and present it as a column. Then, in front of the names of the goods write the word “Product”:
Thus, we formulated the task - to determine whether the word is part of the name of the product, or not. After learning by examples, we can simply send the text as a left column to the model input and get the right column at the output. It seems that everything is quite simple.
In practice, the main difficulty is to manually mark a sufficient number of examples for learning. The more examples, the better the model will work. The logical question is - how many examples are “quite a lot”? It all depends on the task - the more complex the task, the more data is needed. In general, between 400 and 4000 examples of the occurrence of the desired element are usually required. As for the time spent, in our experience, three days of annotation of examples in some cases is enough for the purposes of creating a working prototype, although in more complex situations this time may increase significantly.
For this article, we have prepared a marked up training kit here . In this case, the training set is created from web page headers, so the resulting model will work well with headers. Later I will explain how to improve the quality of recognition in other texts, but for now let's focus on the main idea.
The entire data set needs to be divided into two parts - train - the model will be trained on this part, and test - the result of the algorithm will be checked on this part (we already have two files in our training set). Both files are included, and you can open them with Notepad or another text editor to view the structure.
Next you need to register , which will allow you to get a free API key, and load the library of functions (some browsers may request confirmation, as the archive contains the dll library). For C #, you will need to create a console application and connect it to the Meanotek.NeuText.Cloud.dll project
Now we write the program. First, create a new model, giving it a name. The name must be unique among all your models, because by it the model will subsequently be identified and contain only Latin letters and numbers:
Next, load the data and put the model in the task queue:
TrainModel () suspends the program until the end of the training. In general, this is not necessary (since it can take 10-20 minutes) and the program can do other things at this time and simply check the status of the learning process. In order not to stop the program, you can use the TrainModelAsync () method. If during the work of TrainModel () the program is closed, or a network connection error occurs, the model will still be created on the server, since the program itself puts the model in a queue and does not do anything except wait at that time. The next time you start the program, you can check the status of the model with the Model.GetStatus () function.
After the training is completed, we can display the test results for the test sample:
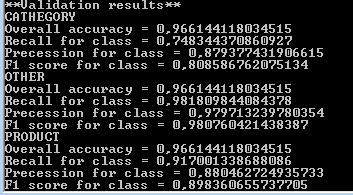
For each type of extracted expressions (category, product) a number of values characterizing the quality of the system is calculated. Recall is the ratio of the number of expressions (for example, names of goods) found by the algorithm to the total number of expressions found by man. Precession - the proportion of correctly found expressions among all detected. F1 is a collective criterion for the quality of the algorithm, which combines precession and recall together. The closer this value is to 1.0, the better. I will not explain in more detail here the meaning of all these metrics, and I suggest that the interested reader read this article , where, in my opinion, everything is considered well and in detail.
I will only note, for comparison, that the widely used method of conditionally random fields (Conditional random fields) with signs in the form of words and digrams in a 5-word window gives F1 with product names 86.2 and 79.5 categories by category.
Now let's try to submit a new example to the input:
Theory (and philosophy): The problem of extracting various expressions from a text has a long history, and there are many special tools to solve it. But we wanted to make a very simple to use solution that would not require serious special skills, did without manual tuning, worked on relatively small samples and would be suitable for a wide range of tasks. Then the creation of new models for extracting data from the text, and, consequently, new applications, would be available to individual developers and small companies who would be able to determine for themselves what analytical tools are required for their business.
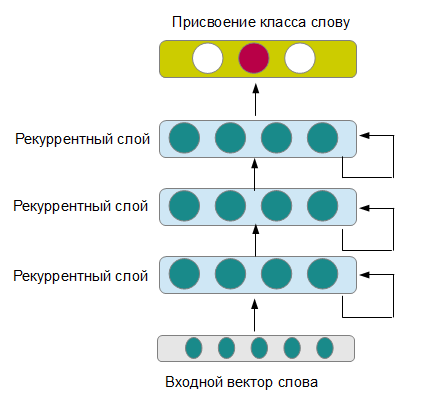
This required, first of all, to get rid of manual selection of signs, grammatical analyzers and all sorts of glossaries of terms, selected for specific tasks, without losing much in quality. One of the models that allows this is deep recurrent neural networks (see figure). The recurrent network consistently receives new words from the sentence as input, while preserving the memory of previous states. At the output, the neural network produces the class to which the word belongs. Several consecutive layers form more and more abstract understanding of the sentence, working on different time ranges (although this happens if everything is set up correctly, otherwise you can simply get a highly retrained neural network).
It is known from research that such a model can extract complex expressions from English texts, including doing semantic role marking and tonality analysis. The results are not inferior, and often even surpass the performance of all other known methods. True, each work used its slightly different architecture, and the optimal parameters were different for different tasks.
Therefore, we did a lot of work, checking several dozens of different models on 18 test collections of English and Russian texts, as a result we managed to find the most optimal neural network model and the way the input words were represented, so that the results were high on various tasks.
In the end, the model chosen for the API is a compromise between speed and accuracy of work, although its result is still quite good, they are not the best possible. But then, if necessary, the results of individual tasks can be increased due to this by connecting a slower model.
When it can be useful opportunities and limitations of implementation: We have prepared a small table that shows in which cases our API can benefit you, what results can be expected, and what - you should not.
Finally, on the limitations of the free API key. At the time of this writing, the restrictions relate to the size of the training sample (up to 240 thousand characters of the text, not including class labels), the number of simultaneously working different models (up to 2 pieces) and the number of requests (42 thousand characters per day). This should be enough for development, testing of most applications, for personal use, as well as for live work of not heavily loaded systems.
What if you need the names of goods, and not all, but some specific? Or do we want to interpret commands for a mobile application? Split the address on the name of the street, home, city? How about highlighting the important facts from the client's appeal to the support service: “I am outraged by the quality of service in your company. Not so long ago, I ordered a laptop , but the manager spoke incorrectly and said that the goods had ended . ” Today I will talk about the new service that allows you to solve a wide range of tasks of extracting information from the text. This service we have just opened for public access.
What you need to work with the examples from this article : The article mainly considers the solution for the .NET Framework in C #. Any language for the .NET Framework or mono is also suitable. From other languages, you can also access the web-API, but there are no ready-made libraries yet, so you have to write the request code manually. It is not difficult, but here I will not explain in detail how to do it in order not to lose the main idea. You will also need internet access and an open port 8080. You will also need to register to receive a free key. It seems, basically everything.
How this article is organized: First, the task is explained, by the example of which the work of the API will be shown. The following is the code. Then a bit of theory is told about how the system works from the inside, and at the end it’s about the limitations of the current version, and when this system will be useful and when it will not.
')
Parse the problem : As an example, take the task of extracting the names of goods from the text. Those. “Buy a Canon I-SENSIS i6500 Laser Printer at the office supplies store.” It is necessary to find references to products to analyze information about products and prices on the Internet, or a system that displays product ads based on page content. Well, for various other purposes.
It may seem that the task is simple and it does not cost anything. For example, for some groups of goods, especially with English names, you can try to write regular expressions that distinguish the names of goods from the text. But this method does not allow to distinguish, for example, “Buy HTC One” (phone model) from „Samsung Apple Nokia phones” (just a list of manufacturers), which is often the case. Regular expressions will not help at all if you need products that are called in Russian, for example, “Atlant Atlas 500 is sold” - it’s not at all clear where the name begins.
Therefore, we will try to teach a computer to distinguish the name of a product from other text based on a number of examples. The main advantage of this approach is that you don’t have to invent an algorithm yourself, and the minus is the need to manually create examples for learning.
What should the examples look like? Suppose we have the following sentence: “Buy Samsung Galaxy S4 in the“ Our phones ”store. We divide it into separate words and present it as a column. Then, in front of the names of the goods write the word “Product”:
| Buy | |
| Samsung | PRODUCT |
| Galaxy | PRODUCT |
| S4 | PRODUCT |
| at | |
| our | |
| the store | |
| <STOP> | |
| Also | |
| ... |
Thus, we formulated the task - to determine whether the word is part of the name of the product, or not. After learning by examples, we can simply send the text as a left column to the model input and get the right column at the output. It seems that everything is quite simple.
In practice, the main difficulty is to manually mark a sufficient number of examples for learning. The more examples, the better the model will work. The logical question is - how many examples are “quite a lot”? It all depends on the task - the more complex the task, the more data is needed. In general, between 400 and 4000 examples of the occurrence of the desired element are usually required. As for the time spent, in our experience, three days of annotation of examples in some cases is enough for the purposes of creating a working prototype, although in more complex situations this time may increase significantly.
For this article, we have prepared a marked up training kit here . In this case, the training set is created from web page headers, so the resulting model will work well with headers. Later I will explain how to improve the quality of recognition in other texts, but for now let's focus on the main idea.
The entire data set needs to be divided into two parts - train - the model will be trained on this part, and test - the result of the algorithm will be checked on this part (we already have two files in our training set). Both files are included, and you can open them with Notepad or another text editor to view the structure.
Next you need to register , which will allow you to get a free API key, and load the library of functions (some browsers may request confirmation, as the archive contains the dll library). For C #, you will need to create a console application and connect it to the Meanotek.NeuText.Cloud.dll project
Now we write the program. First, create a new model, giving it a name. The name must be unique among all your models, because by it the model will subsequently be identified and contain only Latin letters and numbers:
using Meanotek.NeuText.Cloud; Model MyModel = new Model(" api ","ProductTitles"); MyModel.CreateModel(); Next, load the data and put the model in the task queue:
System.Console.WriteLine(" "); MyModel.UploadTrainData("products_train.txt"); System.Console.WriteLine(" "); MyModel.UploadTestData ("products_dev.txt"); System.Console.WriteLine(" "); MyModel.TrainModel(); TrainModel () suspends the program until the end of the training. In general, this is not necessary (since it can take 10-20 minutes) and the program can do other things at this time and simply check the status of the learning process. In order not to stop the program, you can use the TrainModelAsync () method. If during the work of TrainModel () the program is closed, or a network connection error occurs, the model will still be created on the server, since the program itself puts the model in a queue and does not do anything except wait at that time. The next time you start the program, you can check the status of the model with the Model.GetStatus () function.
After the training is completed, we can display the test results for the test sample:
Console.WriteLine(MyModel.GetValidationResults()); For each type of extracted expressions (category, product) a number of values characterizing the quality of the system is calculated. Recall is the ratio of the number of expressions (for example, names of goods) found by the algorithm to the total number of expressions found by man. Precession - the proportion of correctly found expressions among all detected. F1 is a collective criterion for the quality of the algorithm, which combines precession and recall together. The closer this value is to 1.0, the better. I will not explain in more detail here the meaning of all these metrics, and I suggest that the interested reader read this article , where, in my opinion, everything is considered well and in detail.
I will only note, for comparison, that the widely used method of conditionally random fields (Conditional random fields) with signs in the form of words and digrams in a 5-word window gives F1 with product names 86.2 and 79.5 categories by category.
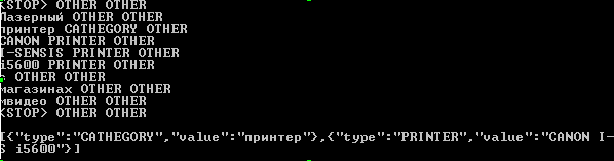
Now let's try to submit a new example to the input:
string result_raw = MyModel.GetPredictionsRaw (" CANON I-SENSIS i5600 "); string result = MyModel.GetPredictionsJson (" CANON I-SENSIS i5600 "); Console.WriteLine(result_raw); Console.WriteLine(result); Theory (and philosophy): The problem of extracting various expressions from a text has a long history, and there are many special tools to solve it. But we wanted to make a very simple to use solution that would not require serious special skills, did without manual tuning, worked on relatively small samples and would be suitable for a wide range of tasks. Then the creation of new models for extracting data from the text, and, consequently, new applications, would be available to individual developers and small companies who would be able to determine for themselves what analytical tools are required for their business.
This required, first of all, to get rid of manual selection of signs, grammatical analyzers and all sorts of glossaries of terms, selected for specific tasks, without losing much in quality. One of the models that allows this is deep recurrent neural networks (see figure). The recurrent network consistently receives new words from the sentence as input, while preserving the memory of previous states. At the output, the neural network produces the class to which the word belongs. Several consecutive layers form more and more abstract understanding of the sentence, working on different time ranges (although this happens if everything is set up correctly, otherwise you can simply get a highly retrained neural network).
It is known from research that such a model can extract complex expressions from English texts, including doing semantic role marking and tonality analysis. The results are not inferior, and often even surpass the performance of all other known methods. True, each work used its slightly different architecture, and the optimal parameters were different for different tasks.
Therefore, we did a lot of work, checking several dozens of different models on 18 test collections of English and Russian texts, as a result we managed to find the most optimal neural network model and the way the input words were represented, so that the results were high on various tasks.
In the end, the model chosen for the API is a compromise between speed and accuracy of work, although its result is still quite good, they are not the best possible. But then, if necessary, the results of individual tasks can be increased due to this by connecting a slower model.
When it can be useful opportunities and limitations of implementation: We have prepared a small table that shows in which cases our API can benefit you, what results can be expected, and what - you should not.
| When will be useful | When will not be useful |
| If you want to create applications with means of understanding texts, but are not familiar with the theory of language analyzers or have little experience . We tried to make the system create competitive models without manual configuration. | You are an expert in computer linguistics and you want to improve the quality of solving a problem that you have been working on for 5 years . We do not guarantee that the current implementation will exceed all specialized solutions. |
| You are solving a specific task of extracting information from the text, for which there is no ready-made API (that is, it is not easy to find the names of people, organizations, dates and geographical locations) . Our system can be trained for different tasks. | For your task there is already a specialized solution, for example, a ready-made named entity recognition API . Most likely you will find it easier to use a ready-made solution if you are sure that your needs are fully met. |
| You are limited in budget and available resources, and do not want to engage in further support and development of your own language analyzer. We follow the new research and introduce modern algorithms ourselves, so over time, the quality of the system designed on our API will increase at no additional cost | You have your own team of specialists, which is engaged in constant maintenance and development of the language analyzer. |
| You want to save disk space or computing resources for the final application. You can save from 5 to 100 mb of space on the target device, which may be important for mobile applications. You can easily install analysis functions in web applications that are on entry-level VPS or shared hosting. | Memory and CPU resources are available in unlimited quantities. |
Finally, on the limitations of the free API key. At the time of this writing, the restrictions relate to the size of the training sample (up to 240 thousand characters of the text, not including class labels), the number of simultaneously working different models (up to 2 pieces) and the number of requests (42 thousand characters per day). This should be enough for development, testing of most applications, for personal use, as well as for live work of not heavily loaded systems.
Source: https://habr.com/ru/post/258211/
All Articles