Elasticsearch - sort the issue by hand
Thanks to its flexibility and scalability, today Elasticsearch finds application in an ever wider range of tasks - from search to analytics. However, there are a number of issues that Elasticsearch cannot handle alone.
For example, your search results change from user to user. And sorting based only on the data of the document itself (TF / IDF or sorting by any fields of the document) does not give the desired result. At the same time in the search results of the online store you want to show the product that the user has already looked at the first positions.
Another example. The parameter that affects the sorting changes too often: Elasticsearch is built on the basis of Lucene and uses the append-only storage, the documents are not updated. Each change of the document leads to its re-indexing and entails periodic rebuilding of the repository segments. In other words, if you want to sort the output by the number of views of the document on the site, the dumbest thing you can do is to record each view in Elasticsearch. And here, it seems, there is an urgent need to use the external storage of meta-information used to sort documents.
')

In one of our projects, we use Elasticsearch as the main repository. This allows us to scale the system for tens of millions of documents without unnecessary gestures and at the same time maintain the response, measured in tens of milliseconds. The basis of our project is the documents (pages of sites, posts in public, GIF or Youtube videos. Each document is a page with parsed content. Documents have meta-information: original url, tags, etc. Elasticsearch allows us to make very fast intersections to build feeds of interest (several sites in one feed), as well as use the Google Alert functionality, within which you can create a feed for any phrase.
The problems began when we decided to add voting and sorting documents by popularity to our application. As we have said, you should not write such frequently changing data in ES.
We store data on the voting in Redis. This is a very fast storage, ideal for this kind of tasks. We need to sort the documents stored in Elasticsearch (sample by request), according to the data stored in Redis (user voices, number of document views).
Starting from version 0.90.4, Elasticsearch provides the Function Score Query mechanism (hereafter FSQ). This is quite a flexible solution. In general, FSQ allows "manually" to calculate the weight of the document used when sorting the issue .
It’s enough for us that FSQ allows:
It should be noted that to install callback, you need to write an Elasticsearch plugin. Here I will give a simplified plugin code that makes it easier to understand the basic idea:
What makes this plugin?
Scheme explaining the decision:
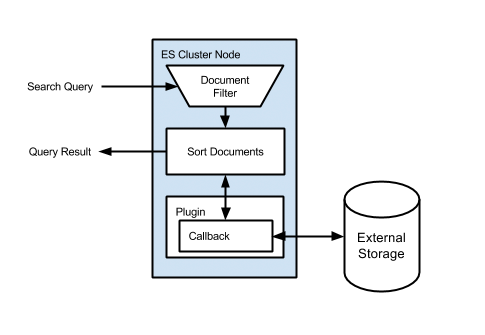
As you can see, any standard ElastiSearch query is executed first, then a Custom Score script is executed for each document. Here is the query:
It seems to be quite simple. The request came to one of the ES nodes, went to shards and other nodes. Each shard counted and executed the query, ran for additional data to Redis and returned the results to the node to the initiator. But there are pitfalls. Let's pay attention to “for each document the Custom Score script is executed” . What does it mean? For example, your query in Elasticsearch found one million documents. After that, for each such document it is necessary to go to Redis and take from there the number of votes. Even if we have time to turn around for 1ms, it turns out 16 minutes . In fact, of course, less, because the request went in parallel from several shards, but still the figure will be impressive.
For each case, the solution to this problem will be different. For example, if we are talking about custom sorting and output for a specific user, then once we have received all the meta-information about the user, for each of the following documents we already take it from memory locally. This will work very quickly.
But in our case, each document has its own meta-information (number of votes). This is where the approach will work when we distribute hot and cold data. Hot data is stored in Redis, cold data is reset to ES. Here's how it works: after 3 days have passed since the publication of the article, the article practically ceases to receive votes, and you can reset them in ES and re-index the document with the value of the accumulated votes. And for fresh articles, we take votes from Redis.
Moreover, if the old document still receives new votes, they are not lost, but they accumulate in the cache and from time to time go to ES for indexing. In this scheme, there is a small moment in time when old documents are sorted with non-updated votes, but this suits us.
Also, if you looked at the code of the plug-in for calculating score, then you noticed that it is synchronous, and is executed one at a time (you cannot form a batch request in redis). However, there are quite complex techniques, when you can consider score batch, and make a request in redis not for each document, but forming packages, for example, 1000 documents.
The solution described is, of course, much more complicated than what can be obtained with a single query to MySQL. However, we use Elasticsearch as the main repository due to the required search functionality and large scale, and in this case, such approaches are justified and work.
You can see how the system works here:
https://play.google.com/store/apps/details?id=com.indxreader
For example, your search results change from user to user. And sorting based only on the data of the document itself (TF / IDF or sorting by any fields of the document) does not give the desired result. At the same time in the search results of the online store you want to show the product that the user has already looked at the first positions.
Another example. The parameter that affects the sorting changes too often: Elasticsearch is built on the basis of Lucene and uses the append-only storage, the documents are not updated. Each change of the document leads to its re-indexing and entails periodic rebuilding of the repository segments. In other words, if you want to sort the output by the number of views of the document on the site, the dumbest thing you can do is to record each view in Elasticsearch. And here, it seems, there is an urgent need to use the external storage of meta-information used to sort documents.
')
In one of our projects, we use Elasticsearch as the main repository. This allows us to scale the system for tens of millions of documents without unnecessary gestures and at the same time maintain the response, measured in tens of milliseconds. The basis of our project is the documents (pages of sites, posts in public, GIF or Youtube videos. Each document is a page with parsed content. Documents have meta-information: original url, tags, etc. Elasticsearch allows us to make very fast intersections to build feeds of interest (several sites in one feed), as well as use the Google Alert functionality, within which you can create a feed for any phrase.
The problems began when we decided to add voting and sorting documents by popularity to our application. As we have said, you should not write such frequently changing data in ES.
Task
We store data on the voting in Redis. This is a very fast storage, ideal for this kind of tasks. We need to sort the documents stored in Elasticsearch (sample by request), according to the data stored in Redis (user voices, number of document views).
FUNCTION_SCORE_QUERY Solution
Starting from version 0.90.4, Elasticsearch provides the Function Score Query mechanism (hereafter FSQ). This is quite a flexible solution. In general, FSQ allows "manually" to calculate the weight of the document used when sorting the issue .
It’s enough for us that FSQ allows:
- set the callback (java), to the input of which the next document from the selection is received;
- assign the weight to the input document (_score field) equal to the result calculated in the callback.
It should be noted that to install callback, you need to write an Elasticsearch plugin. Here I will give a simplified plugin code that makes it easier to understand the basic idea:
public class AbacusPlugin extends AbstractPlugin { @Override public String name() { return "myScore.plugin"; } @Override public String description() { return "My Score Plugin"; } // called by Elasticsearch in a initialization phase(reflection magic) public void onModule(ScriptModule module) { module.registerScript( "myScore", // NOTE: script name MyScriptFactory.class ); } /* * Script Factory should implement NativeScriptFactory */ public static class MyScriptFactory implements NativeScriptFactory { // Some Score Calculation Service private final MyScoreService service; public MyScriptFactory() { service = new MyScoreService(); } @Override public ExecutableScript newScript( @Nullable Map<String, Object> params // script params ) { return new AbstractDoubleSearchScript() { /* * called for every filtered document */ @Override public double runAsDouble() { // extract document ID final String id = docFieldStrings("_uid").getValue(); // extract some other document`s field final String field = docFieldStrings("someField").getValue(); // calc score by ID and some other field return service.calcScore(id, field); } }; } } } What makes this plugin?
- registers a sorting script in the onModule function;
- implements a script factory in the MyScriptFactory class, which implements the NativeScriptFactory interface;
- creates the sorting class itself, inheriting from the abstract class: AbstractDoubleSearchScript ;
- the sorting class implements the runAsDouble function (it is assumed that the returned calculated score will be double);
- The runAsDouble function is called for each document that is selected in the query. Access to the contents of the document provides the abstract class function AbstractDoubleSearchScript.docFieldStrings ;
- In the plugin code, you also see the service FlashScoreService () , which, in fact, is responsible for assigning new scores to the documents. This service goes to Redis for the values of the number of votes. In your case, it can be any other service that goes anywhere.
Scheme explaining the decision:
As you can see, any standard ElastiSearch query is executed first, then a Custom Score script is executed for each document. Here is the query:
{ "function_score": { "boost_mode": "replace", // to ignore score "query": ..., // some query "script_score": { "lang": "native", "script": "myScore" // script name "params": { // script params(optional) "param1": 3.14, "param2": "foo" }, }, } } Problems
It seems to be quite simple. The request came to one of the ES nodes, went to shards and other nodes. Each shard counted and executed the query, ran for additional data to Redis and returned the results to the node to the initiator. But there are pitfalls. Let's pay attention to “for each document the Custom Score script is executed” . What does it mean? For example, your query in Elasticsearch found one million documents. After that, for each such document it is necessary to go to Redis and take from there the number of votes. Even if we have time to turn around for 1ms, it turns out 16 minutes . In fact, of course, less, because the request went in parallel from several shards, but still the figure will be impressive.
Solution to the problem
For each case, the solution to this problem will be different. For example, if we are talking about custom sorting and output for a specific user, then once we have received all the meta-information about the user, for each of the following documents we already take it from memory locally. This will work very quickly.
But in our case, each document has its own meta-information (number of votes). This is where the approach will work when we distribute hot and cold data. Hot data is stored in Redis, cold data is reset to ES. Here's how it works: after 3 days have passed since the publication of the article, the article practically ceases to receive votes, and you can reset them in ES and re-index the document with the value of the accumulated votes. And for fresh articles, we take votes from Redis.
Moreover, if the old document still receives new votes, they are not lost, but they accumulate in the cache and from time to time go to ES for indexing. In this scheme, there is a small moment in time when old documents are sorted with non-updated votes, but this suits us.
Also, if you looked at the code of the plug-in for calculating score, then you noticed that it is synchronous, and is executed one at a time (you cannot form a batch request in redis). However, there are quite complex techniques, when you can consider score batch, and make a request in redis not for each document, but forming packages, for example, 1000 documents.
findings
The solution described is, of course, much more complicated than what can be obtained with a single query to MySQL. However, we use Elasticsearch as the main repository due to the required search functionality and large scale, and in this case, such approaches are justified and work.
You can see how the system works here:
https://play.google.com/store/apps/details?id=com.indxreader
Source: https://habr.com/ru/post/258205/
All Articles