Forget the SAR theorem as no longer relevant.
or “Stop characterizing data stores as CP or AP”
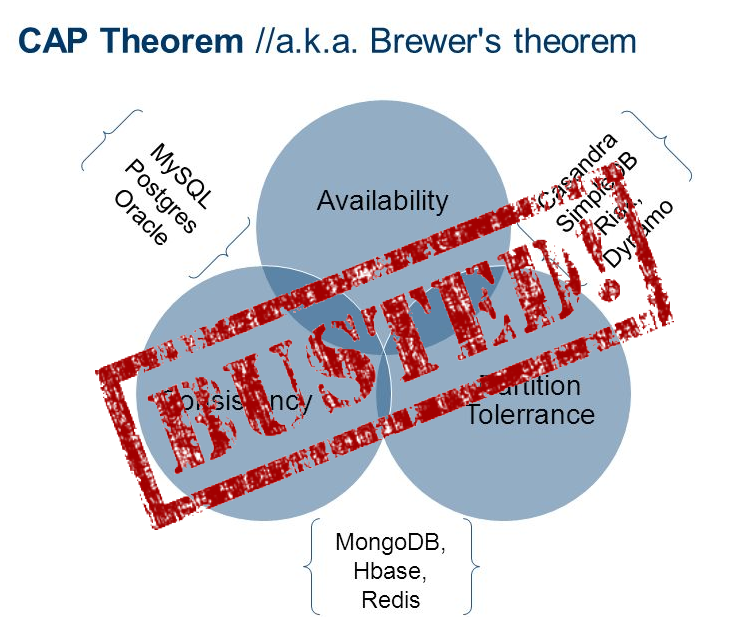 Jeff Hodges in his excellent post “ Notes on Distributed Systems for Beginners ” recommends using the CAP theorem to criticize the solutions found. Many seem to have taken this advice too close to heart, describing their systems as “CP” (data consistency, but without constant availability with network distribution), “AP” (availability without a consistent state with network distribution), or sometimes “CA” (means "I still have not read the article Coda (Coda Hale) almost 5 years ago ").
Jeff Hodges in his excellent post “ Notes on Distributed Systems for Beginners ” recommends using the CAP theorem to criticize the solutions found. Many seem to have taken this advice too close to heart, describing their systems as “CP” (data consistency, but without constant availability with network distribution), “AP” (availability without a consistent state with network distribution), or sometimes “CA” (means "I still have not read the article Coda (Coda Hale) almost 5 years ago ").
I agree with all points of the article except for the SAR theorem. It simplifies too much and too many people misunderstand it in order to use it to determine the characteristics of a system. So I ask you to stop referring to the SAR theorem, talk about it and give it to her to calmly go to rest. Instead, we must use more accurate terminology to discuss the various trade-offs.
')
(Yes, I understand the irony of writing an entire article on the topic of what I urge not to write others at all. But at least I will have a link that I can give to people interested when they ask me why I do not approve of the discussion of the CAP theorem Also, I want to apologize if the article seems too pompous to you, but this bombast relies on many references.)
If you want to refer to CAP as a theorem (and not a vague concept in the marketing materials for your database), you must be accurate. Mathematics requires accuracy. Proof is preserved only if you embed in words, the same meaning that was used in the proof. And it relies on very precise definitions:
I also want to note that the SAR theorem describes not just any old system, but a system of a very specific model:
If your definition coincides with the formal meaning of terms in the CAP theorem, then it fits you. But if you give a different definition of the terms consistency and accessibility, then you cannot expect the SAR theorem to apply to you. Of course, this does not mean that by redefining the values you can suddenly do impossible things! You just can not follow the CAP theorem and use it for argumentation in support of your point of view.
In case you are not familiar with linearizability (in the sense of "integrity" in the context of ATS), let me briefly tell about it. The formal definition is not that very understandable, but the key idea, if in a simple way, is:
If operation B started after successful completion of operation A, then operation B should see the state of the system at the moment A is completed or in the new state.
For greater clarity, you can imagine the following situation in which the system will not be linearized. See the diagram below (some kind of preview of my book that hasn't been released yet):
The diagram illustrates the following situation: Bob and Alice are in the same room, both are checking their phones to check the results of the final game at the 2014 World Cup. Immediately after the bill has been announced, Alice refreshes the page, sees the winner and happily informs Bob of this. He immediately presses Update on his phone, but his request falls on a replicated database that lags slightly, so his phone says that the game is still running.
If Alice and Bob had updated the page on the phone at the same time, it would not be surprising that they got different results, because they don’t know at what time their requests were processed. However, Bob knows that he is updating the page (initiates a request) after he heard Alice’s exclamation about the final account and, thus, he expects his data to be at least the same old as Alice’s. The fact that he got a rotten query result is a violation of linearization.
The knowledge that Bob’s request occurred strictly after Alice’s request (that they were not simultaneous) is based on the fact that Bob heard the result of a request from Alice through another communication channel (verbally, in our case). If Bob had not heard the result from Alice that the game was over, then he would not know that his result was outdated.
When you are designing a database, you cannot know what types of communication channels the client will have. It turns out that if you want to provide linearization (CAP-consistency) in your database, you have to make everyone think that there is only a single copy of the data, even if there may be a lot of it (replicated data, cache) in various places .
It is very expensive and problematic to provide guarantees of linearizability, because it requires a large number of coordination operations. Even the CPU in your computer does not provide linearized access to the RAM ! To obtain linearizability in modern CPUs, you must use the memory barrier instructions . And even to test the linearizability of the system is not very easy .
Let's talk a little bit about whether to sacrifice linearization or accessibility in the case of network sharing.
Suppose we have copies of the database in two different data centers. The specific replication method is unimportant in this case — it can be single-leader (master / slave), multi-leader (master / master), or quorum-based replication ( Dynamo-style ). The general meaning of replication is that when data changes in one data center, they are displayed in another. Imagine that clients are connected with only one data center and there must be another connection between data centers for replicating data.
Now let the connection between the DCs be interrupted - this is what we mean by network sharing. What happens then?
Obviously, you can choose one of two options:
By the way, this is essentially a proof of the CAP theorem. In the example, two DCs are used, but everything can be applied to one DC, as the network problems can be inside too. I just thought that the example of the two DCs is more simple and clear.
Note that in our conditionally “inaccessible” situation in the second version, we can quite successfully process requests in one of the DCs. So if the system is built with an emphasis on linearizability (i.e., not CAP is available), then this does not necessarily mean that network separation automatically leads to application downtime. If you can transfer all clients to the use of a lead DC, customers will not notice a drop at all.
Availability in practice doesn’t exactly refer to CAP accessibility. The availability of your application is most likely measured in the SLA (for example, 99.9% of the correct queries should return a result within 1 second), but such an agreement can be implemented in CAP-accessible and CAP-inaccessible systems.
In practice, systems located in many DCs are often designed taking into account asynchronous replication and it turns out that they are nonlinearized. However, the reason for this choice is often the network latency itself, and not just because of the increased stability of the data centers and the network falling.
How to create systems with strict definitions in the CAP-theorem for integrity (linearization) and accessibility?
For example, take any database with replication and one leader (single leader), which is the standard setting for most relational databases. In this configuration, the client can not write to the database if it is separated from the master. Even if a client can read from copies (read-only recplica), the fact that he cannot write data means that any setting with a single master is not CAP-accessible. It does not matter that such systems are often positioned as "systems with high availability."
If replication with one master is not CAP-available, then does it make it "CP"? Wait, not so fast! If you allow an application to read from replicas, and asynchronous replicas (the default for most databases), then the dependent database may be slightly outdated during reading. In this case, the reading will not be linearized, i.e. not cap-consistent.
Moreover, databases with an isolation level of snapshot / MVCC are deliberately non-linearized, because the linearization requirement will reduce the number of concurrency operations simultaneously. For example, PostgreSQL SSI gives serializability, but not linearizability, with Oracle the same situation . Just because a database is marked as ACID does not mean that the database satisfies the definition of consistency / consistency in the CAP theorem.
It turns out that these systems are neither CAP-agreed, nor CAP-accessible. They are neither “SR” nor “AR”, they are simply “P”, whatever that means. Yes, the wording “two out of three” allows you to choose only one option out of three, or even none!
What about NoSQL? For example, you can take MongoDB: it has one lead per shard (at least so it is assumed, if it is not split-brain mode), so given all the above, there is no longer CAP availability. And Kyle (Kyle) recently showed that this allows non-linearized reading to be done even with the highest level of consistency settings, so CAP-consistency is not the same.
Dynamo derivatives like Riak, Cassandra and Voldemort are often called “AR” because they are optimized for high availability? Well, it depends on your settings. If you can write and read data in replicas (R = W = 1), they are really CAP-available. However, if reading and writing are performed by a quorum (R + W> N) and you have network sharing, clients on the minority side cannot reach the quorum, it turns out that the quorum operation is also not ATS-available (at least temporarily, until the base data will not raise additional cues on the minority side).
Sometimes you can meet people who claim that quorum-based reading and writing guarantees linearization, but I think it will not be very clever to rely on it - a fragile combination of features such as sloppy quorums and reading repair can lead to fragile face , when thedead will recover deleted records will be restored, or the number of replicas will fall less than the original number of writers (violation of quorum conditions), or the number of replicas will exceed the original N (again violation of quorum conditions). All this leads to non-linearized data acquisition.
All the systems mentioned are not bad: people successfully use them in combat environments. However, so far we have not been able to strictly define it as “AP” or “CP”, including because it depends on a specific operation or configuration, or because the system does not meet the strict definition of consistency or availability in the CAP theorem.
What about ZooKeeper? This system uses an agreement algorithm , so many agree that this is a pure example of preference for consistency over accessibility (i.e., the “CP system”).
However, if you look in the documentation , it clearly states that ZooKeeper does not provide a linearized reading by default. Each client is connected to one of the nodes, and when you want to start reading, you see data only from your node, even if there is updated data on the neighboring nodes. This allows you to read data much faster than if you need to collect a quorum or poll the leader for each read, but it also means that ZooKeeper by default does not meet the requirements of the CAP theorem on consistency.
In general, it is possible to do a linearized reading in ZooKeeper using sync before the read command . This is not the default behavior, because we get a performance drop. The sync command is used, but not all the time.
What about availability in ZooKeeper? Well, the ZK requires a majority decision to reach an agreement to record the data. If you have a division into a majority and a minority of nodes, then the majority will function as before, but the nodes remaining in the minority will not be able to process write requests, despite the fact that they are all working. It turns out that the recording function in ZK is not CAP-available in the partitioned mode of operation (even taking into account the fact that most nodes can write data).
To add even more fun to all this, ZooKeeper version 3.4.0 added a read-only mode in which nodes remaining in the minority can continue to serve read requests — a quorum is not required! Those. read mode is CAP-accessible. Thus, the default ZK is neither CAP-negotiated (“CP”) or CAP-accessible (“AR”) - it is really just “P”. However, you can make the system "CP" using the sync method, and only for the read operation system "AP", if you enable the correct options.
But what's annoying: calling ZooKeeper a “non-consistent” system, simply because it is non-linearizable by default — a truly horrible interpretation of features. ZK actually gives you a great degree of consistency! It supports atomic broadcast in conjunction with guaranteed casual consistency — which is a stronger condition than monotonic reads and consistent prefix reads put together. Documentation says that the system gives consistent consistency , but this is an underestimation of themselves, because ZooKeeper guarantees a stronger definition than consistent consistency.
The fact that we could not unambiguously classify even one repository as “AR” or “SR” should lead to certain thoughts: these are simply inappropriate definitions for the described systems.
I am sure that we should stop trying to identify the various repositories in the category “AR” or “SR” because:
If “SR” and “AR” are not suitable for describing and criticizing systems, what should be used instead? I do not think that I have the only correct answer. Many people spent a lot of time thinking about the problems of distributed systems, and offered terminology and models that now help us understand the problems. To learn more about these ideas, you need to delve into the literature yourself:
No matter what path of study you choose, I urge you to maintain curiosity and patience - this is not easy. But you will be rewarded, because you will understand the reasons for the compromises and will be able to determine what type of architecture is needed in your particular case. But whatever you do, stop talking about “SR” and “AR”, because it does not make sense.
Jeff Hodges in his excellent post “ Notes on Distributed Systems for Beginners ” recommends using the CAP theorem to criticize the solutions found. Many seem to have taken this advice too close to heart, describing their systems as “CP” (data consistency, but without constant availability with network distribution), “AP” (availability without a consistent state with network distribution), or sometimes “CA” (means "I still have not read the article Coda (Coda Hale) almost 5 years ago ").I agree with all points of the article except for the SAR theorem. It simplifies too much and too many people misunderstand it in order to use it to determine the characteristics of a system. So I ask you to stop referring to the SAR theorem, talk about it and give it to her to calmly go to rest. Instead, we must use more accurate terminology to discuss the various trade-offs.
')
(Yes, I understand the irony of writing an entire article on the topic of what I urge not to write others at all. But at least I will have a link that I can give to people interested when they ask me why I do not approve of the discussion of the CAP theorem Also, I want to apologize if the article seems too pompous to you, but this bombast relies on many references.)
ATS uses too narrow a definition
If you want to refer to CAP as a theorem (and not a vague concept in the marketing materials for your database), you must be accurate. Mathematics requires accuracy. Proof is preserved only if you embed in words, the same meaning that was used in the proof. And it relies on very precise definitions:
- Consistency in ATS actually means linearizability , which is (and very strong) the principle of consistency. In particular, this has nothing to do with the "C" of ACID, even if this C also means "consistency." I'll explain on fingers what linearizability is a bit later.
- Availability in the RAA is defined as “every request received by a working node [database] in the system should result in a response [not containing errors]”. It is not enough for some nodes to process the request: any working node must be able to process the request. A lot of so-called “high abailability”, i.e. with low downtime, systems in reality do not meet the definition of accessibility.
- Resistance to separation (Partition tolerance ) is a terrible name - in general terms it means that you use an asynchronous network for communication, which can lose or delay messages. The Internet and all data centers have this property , so in reality you have no choice in this context.
I also want to note that the SAR theorem describes not just any old system, but a system of a very specific model:
- A system model in SAR space is a single node / counter (register) of read-write - that's all. For example, nothing is said about transactions that affect multiple objects. They are simply outside the conditions of the theorem, as long as you don’t somehow cut those objects down to a single object.
- The only type of failure mentioned by the CAP theorem is network separation, i.e. the nodes remain active, but the network between some of them is down. This kind of error somehow happens , but this is not the only thing that can go wrong: the nodes can be broken or reloaded, the disk can run out, you can catch a bug in the software, etc., etc. In the process of creating a distributed system, you need to keep in mind a much larger range of possible errors and compromises to which they lead. Focusing too much on the SAR theorem leads to ignoring other important problems.
- Moreover, the CAP theorem says nothing about latency, which worries most developers much more than accessibility. In fact, CAP-compatible systems can be arbitrarily slow and still be called "affordable." If you take everything to the extreme, I am sure that your users will not be inclined to call your system “accessible” if it takes 2 minutes to get a web page.
If your definition coincides with the formal meaning of terms in the CAP theorem, then it fits you. But if you give a different definition of the terms consistency and accessibility, then you cannot expect the SAR theorem to apply to you. Of course, this does not mean that by redefining the values you can suddenly do impossible things! You just can not follow the CAP theorem and use it for argumentation in support of your point of view.
Linearizability
In case you are not familiar with linearizability (in the sense of "integrity" in the context of ATS), let me briefly tell about it. The formal definition is not that very understandable, but the key idea, if in a simple way, is:
If operation B started after successful completion of operation A, then operation B should see the state of the system at the moment A is completed or in the new state.
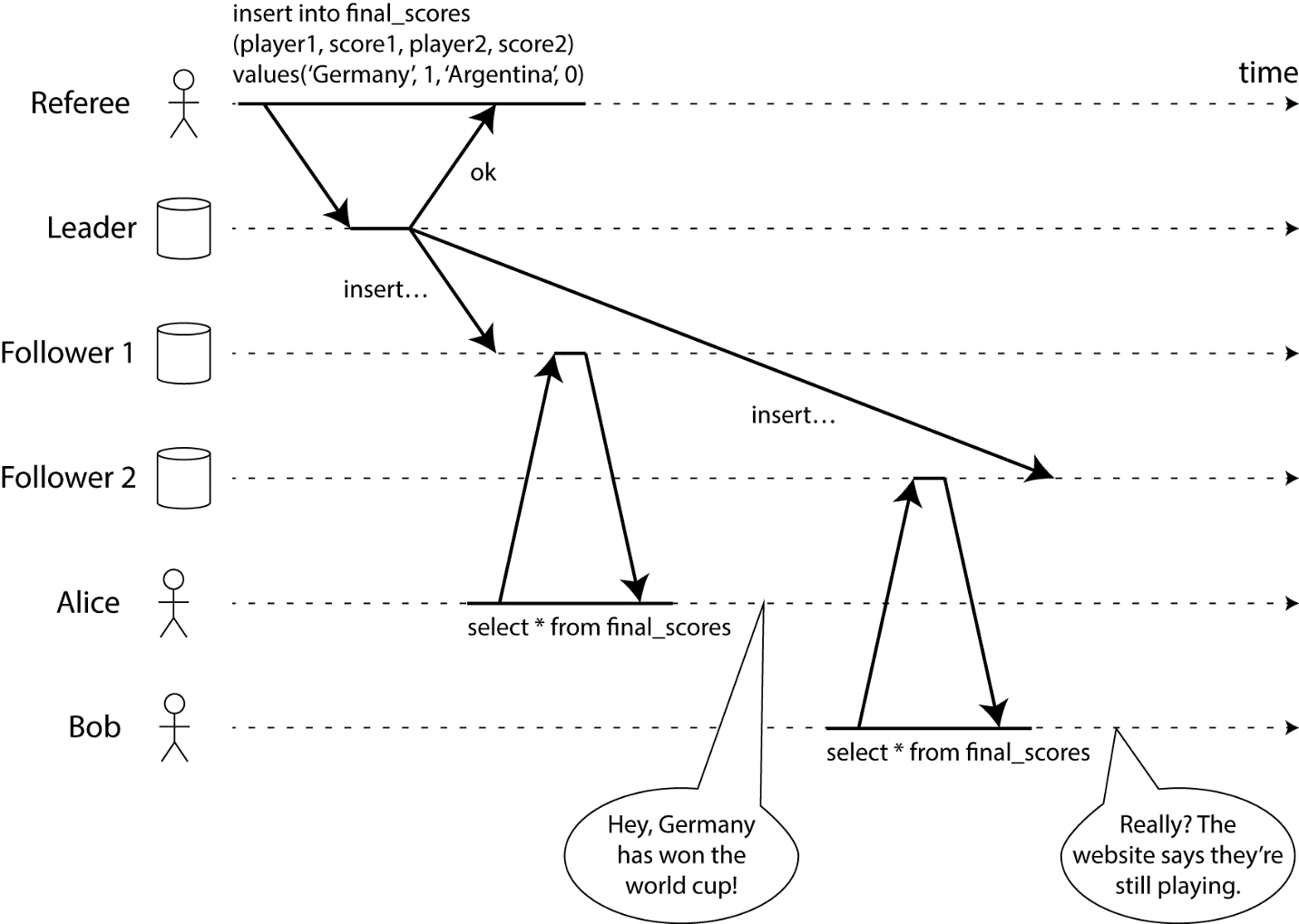
For greater clarity, you can imagine the following situation in which the system will not be linearized. See the diagram below (some kind of preview of my book that hasn't been released yet):
The diagram illustrates the following situation: Bob and Alice are in the same room, both are checking their phones to check the results of the final game at the 2014 World Cup. Immediately after the bill has been announced, Alice refreshes the page, sees the winner and happily informs Bob of this. He immediately presses Update on his phone, but his request falls on a replicated database that lags slightly, so his phone says that the game is still running.
If Alice and Bob had updated the page on the phone at the same time, it would not be surprising that they got different results, because they don’t know at what time their requests were processed. However, Bob knows that he is updating the page (initiates a request) after he heard Alice’s exclamation about the final account and, thus, he expects his data to be at least the same old as Alice’s. The fact that he got a rotten query result is a violation of linearization.
The knowledge that Bob’s request occurred strictly after Alice’s request (that they were not simultaneous) is based on the fact that Bob heard the result of a request from Alice through another communication channel (verbally, in our case). If Bob had not heard the result from Alice that the game was over, then he would not know that his result was outdated.
When you are designing a database, you cannot know what types of communication channels the client will have. It turns out that if you want to provide linearization (CAP-consistency) in your database, you have to make everyone think that there is only a single copy of the data, even if there may be a lot of it (replicated data, cache) in various places .
It is very expensive and problematic to provide guarantees of linearizability, because it requires a large number of coordination operations. Even the CPU in your computer does not provide linearized access to the RAM ! To obtain linearizability in modern CPUs, you must use the memory barrier instructions . And even to test the linearizability of the system is not very easy .
CAP availability
Let's talk a little bit about whether to sacrifice linearization or accessibility in the case of network sharing.
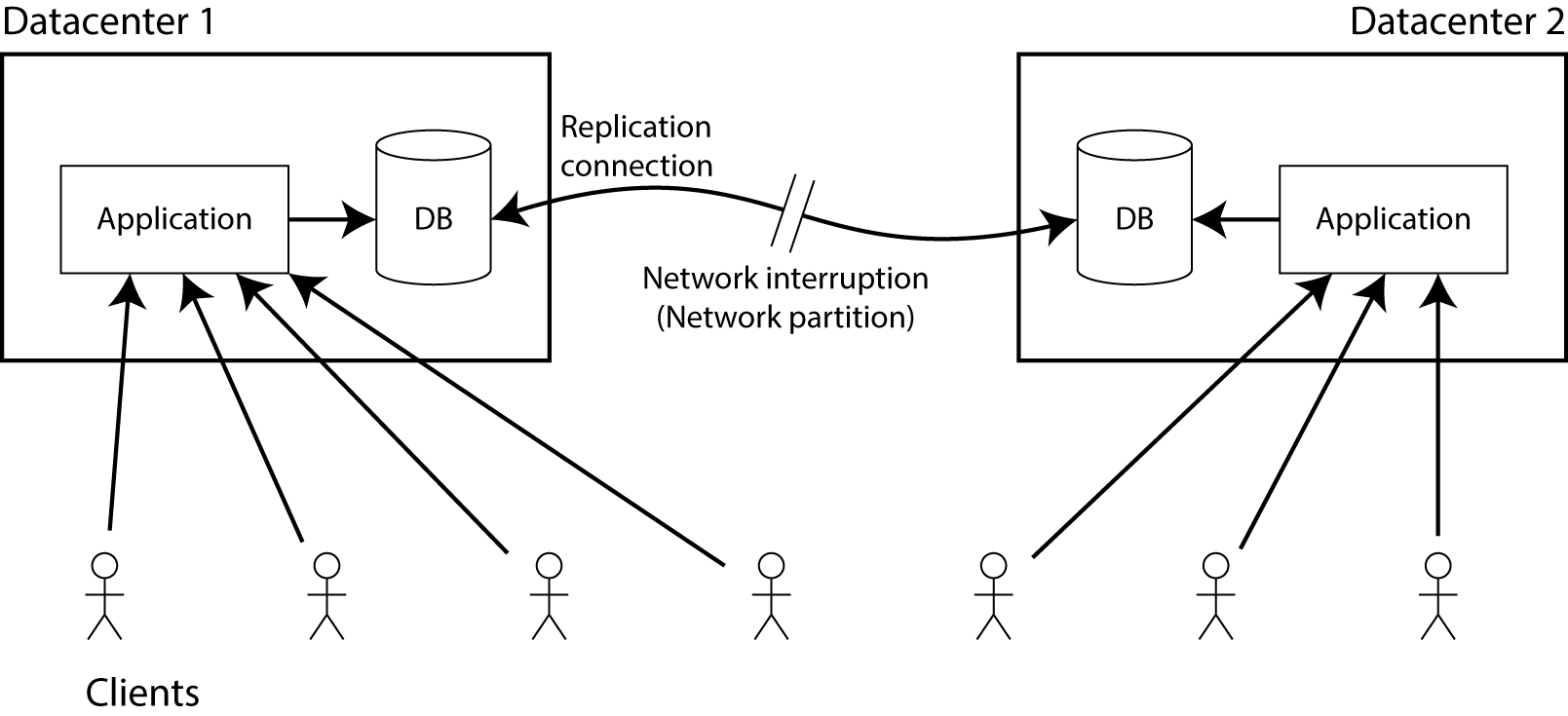
Suppose we have copies of the database in two different data centers. The specific replication method is unimportant in this case — it can be single-leader (master / slave), multi-leader (master / master), or quorum-based replication ( Dynamo-style ). The general meaning of replication is that when data changes in one data center, they are displayed in another. Imagine that clients are connected with only one data center and there must be another connection between data centers for replicating data.
Now let the connection between the DCs be interrupted - this is what we mean by network sharing. What happens then?
Obviously, you can choose one of two options:
- The application continues to work and allows writing to the database, it is fully accessible to both data centers. But since the connection between the DCs is interrupted, all changes in one DC will not be available in the other. This violates the linearizability (in terms of the previous example, Alice can be assigned to DC1, and Bob to DC2).
- If you do not want to lose linearizability, you must be sure that you are doing all the reading and writing in one data center, which you can call the master. In another DC, the data of which cannot be up to date due to the loss of connection, the database should stop servicing clients for reading and writing until the synchronization is restored. Since the dependent database in the second DC cannot process requests, it is not CAP-accessible.
By the way, this is essentially a proof of the CAP theorem. In the example, two DCs are used, but everything can be applied to one DC, as the network problems can be inside too. I just thought that the example of the two DCs is more simple and clear.
Note that in our conditionally “inaccessible” situation in the second version, we can quite successfully process requests in one of the DCs. So if the system is built with an emphasis on linearizability (i.e., not CAP is available), then this does not necessarily mean that network separation automatically leads to application downtime. If you can transfer all clients to the use of a lead DC, customers will not notice a drop at all.
Availability in practice doesn’t exactly refer to CAP accessibility. The availability of your application is most likely measured in the SLA (for example, 99.9% of the correct queries should return a result within 1 second), but such an agreement can be implemented in CAP-accessible and CAP-inaccessible systems.
In practice, systems located in many DCs are often designed taking into account asynchronous replication and it turns out that they are nonlinearized. However, the reason for this choice is often the network latency itself, and not just because of the increased stability of the data centers and the network falling.
Many systems are neither linearizable nor CAP-accessible.
How to create systems with strict definitions in the CAP-theorem for integrity (linearization) and accessibility?
For example, take any database with replication and one leader (single leader), which is the standard setting for most relational databases. In this configuration, the client can not write to the database if it is separated from the master. Even if a client can read from copies (read-only recplica), the fact that he cannot write data means that any setting with a single master is not CAP-accessible. It does not matter that such systems are often positioned as "systems with high availability."
If replication with one master is not CAP-available, then does it make it "CP"? Wait, not so fast! If you allow an application to read from replicas, and asynchronous replicas (the default for most databases), then the dependent database may be slightly outdated during reading. In this case, the reading will not be linearized, i.e. not cap-consistent.
Moreover, databases with an isolation level of snapshot / MVCC are deliberately non-linearized, because the linearization requirement will reduce the number of concurrency operations simultaneously. For example, PostgreSQL SSI gives serializability, but not linearizability, with Oracle the same situation . Just because a database is marked as ACID does not mean that the database satisfies the definition of consistency / consistency in the CAP theorem.
It turns out that these systems are neither CAP-agreed, nor CAP-accessible. They are neither “SR” nor “AR”, they are simply “P”, whatever that means. Yes, the wording “two out of three” allows you to choose only one option out of three, or even none!
What about NoSQL? For example, you can take MongoDB: it has one lead per shard (at least so it is assumed, if it is not split-brain mode), so given all the above, there is no longer CAP availability. And Kyle (Kyle) recently showed that this allows non-linearized reading to be done even with the highest level of consistency settings, so CAP-consistency is not the same.
Dynamo derivatives like Riak, Cassandra and Voldemort are often called “AR” because they are optimized for high availability? Well, it depends on your settings. If you can write and read data in replicas (R = W = 1), they are really CAP-available. However, if reading and writing are performed by a quorum (R + W> N) and you have network sharing, clients on the minority side cannot reach the quorum, it turns out that the quorum operation is also not ATS-available (at least temporarily, until the base data will not raise additional cues on the minority side).
Sometimes you can meet people who claim that quorum-based reading and writing guarantees linearization, but I think it will not be very clever to rely on it - a fragile combination of features such as sloppy quorums and reading repair can lead to fragile face , when the
All the systems mentioned are not bad: people successfully use them in combat environments. However, so far we have not been able to strictly define it as “AP” or “CP”, including because it depends on a specific operation or configuration, or because the system does not meet the strict definition of consistency or availability in the CAP theorem.
Real-life example: ZooKeeper
What about ZooKeeper? This system uses an agreement algorithm , so many agree that this is a pure example of preference for consistency over accessibility (i.e., the “CP system”).
However, if you look in the documentation , it clearly states that ZooKeeper does not provide a linearized reading by default. Each client is connected to one of the nodes, and when you want to start reading, you see data only from your node, even if there is updated data on the neighboring nodes. This allows you to read data much faster than if you need to collect a quorum or poll the leader for each read, but it also means that ZooKeeper by default does not meet the requirements of the CAP theorem on consistency.
In general, it is possible to do a linearized reading in ZooKeeper using sync before the read command . This is not the default behavior, because we get a performance drop. The sync command is used, but not all the time.
What about availability in ZooKeeper? Well, the ZK requires a majority decision to reach an agreement to record the data. If you have a division into a majority and a minority of nodes, then the majority will function as before, but the nodes remaining in the minority will not be able to process write requests, despite the fact that they are all working. It turns out that the recording function in ZK is not CAP-available in the partitioned mode of operation (even taking into account the fact that most nodes can write data).
To add even more fun to all this, ZooKeeper version 3.4.0 added a read-only mode in which nodes remaining in the minority can continue to serve read requests — a quorum is not required! Those. read mode is CAP-accessible. Thus, the default ZK is neither CAP-negotiated (“CP”) or CAP-accessible (“AR”) - it is really just “P”. However, you can make the system "CP" using the sync method, and only for the read operation system "AP", if you enable the correct options.
But what's annoying: calling ZooKeeper a “non-consistent” system, simply because it is non-linearizable by default — a truly horrible interpretation of features. ZK actually gives you a great degree of consistency! It supports atomic broadcast in conjunction with guaranteed casual consistency — which is a stronger condition than monotonic reads and consistent prefix reads put together. Documentation says that the system gives consistent consistency , but this is an underestimation of themselves, because ZooKeeper guarantees a stronger definition than consistent consistency.
SR / AR: False Dichotomy
The fact that we could not unambiguously classify even one repository as “AR” or “SR” should lead to certain thoughts: these are simply inappropriate definitions for the described systems.
I am sure that we should stop trying to identify the various repositories in the category “AR” or “SR” because:
- Within one application, there may be several different operations with different data consistency characteristics .
- Many systems do not meet the definition of consistency and accessibility within the framework of the CAP-theorem. However, I have never heard that someone called his system simply “P”, probably because it sounds bad. But this is not bad - it can be a perfectly planned architecture that simply does not fall into the category of CP / AR.
- Even if the majority of software does not fall precisely into the mentioned categories, people still try to squeeze it into one of the categories, and it turns out that the meaning of “consistency” or “accessibility” inevitably changes to what they want to mean by that. Unfortunately, if the meaning of words changes - the CAP theorem can no longer be applied, and the division into CP / AP does not matter.
- A huge amount of nuances is lost when trying to cram a system into one of two categories. There are a huge number of aspects regarding fault tolerance, latency, simplicity of the programming model, interaction, and so on, which can be used in the design of distributed systems. It is physically impossible to encode all these nuances in one bit of information. For example, even ZooKeeper supports “AP” in read-only mode, and this mode allows you to read entries in the same order as they were written - it is much stronger than “AP” in systems like Riak or Cassandra - so it was would be ridiculous to put them in one pile.
- Even Eric Brewer admits that ATS is misleading and simplifies too much. In 2000, it was important to start a discussion of trade-offs in distributed systems, and it worked. There was no intention to create some kind of breakthrough formal document or strict classification schemes for data warehouses. 15 years later, we had a much richer set of tools with different approaches to ensuring data integrity and error protection. ATS has done its task and now is the time to move on.
Learn to think for yourself
If “SR” and “AR” are not suitable for describing and criticizing systems, what should be used instead? I do not think that I have the only correct answer. Many people spent a lot of time thinking about the problems of distributed systems, and offered terminology and models that now help us understand the problems. To learn more about these ideas, you need to delve into the literature yourself:
- A good starting point would be Doug Terry's article where he explains the differences between different levels of partial consistency using baseball for example . It is very easy to read and understand, even if you (just like me) are not American and do not understand anything about baseball.
- If you want to learn more about transaction isolation models (which is not the same as consistency in distributed replicas, but close), my little Hermitage project can help.
- The relationship between replica consistency, transactions, and availability has been investigated by Peter Bailis. The document also explains the significance of the hierarchy of levels of consistency that Kyle Kingsbury likes to show so much .
- When you read all this, you will be ready to dig deeper. I shoveled a bunch of links and documents for this post - read them, the experts have already perfectly described many things for you.
- As a final argument, if you cannot read the original sources, I suggest you take a look at my book, which contains and summarizes the most important ideas in a convenient way. You see, I tried very hard not to make an advertising speech out of the post.
- If you are interested in the ZooKeeper theme and you want to draw a more detailed look at it, then Flavio Junqueira and Benjamin Reed have written a good book.
No matter what path of study you choose, I urge you to maintain curiosity and patience - this is not easy. But you will be rewarded, because you will understand the reasons for the compromises and will be able to determine what type of architecture is needed in your particular case. But whatever you do, stop talking about “SR” and “AR”, because it does not make sense.
Source: https://habr.com/ru/post/258145/
All Articles