Development for Microsoft SQL Server (and not only): version control, continuous integration and procedures - as we do
Good day, dear Habrovchane.
As a brief background: a year ago, having come to a new job as a head of the database development department (based on Microsoft SQL Server), I experienced the deepest shock of what I saw. A large company, a complex web application, multimillion-dollar contracts, and development is carried out in the production-database, bug reports are received and processed according to the method of “who will shout louder” or “must be done right yesterday.” Naturally, there was no talk about the version control system, continuous integration, procedures and workflow.
Today the situation has changed a lot ( although whom I’m fooling is just starting to change ) and I would like to share both technical and procedural details of the solutions that we use now. Technical details for 90% relate directly to the development for Microsoft SQL Server, but the procedural changes we have touched and web developers, and engineers, and analysts, and testers.
')
Immediately make a reservation, I am not a representative of companies / advertiser of software products, which I will mention in the article. The choice of software used was best suited for our tasks in terms of functionality, price, and also satisfied my personal preferences.
Who are interested in the details - welcome under cat.
Warning: a lot of text, descriptions of procedures and processes ( which, perhaps, are not interesting to anyone ).
The solution based on Atlassian JIRA was chosen as the accounting system for applications. The main reasons were: tight integration with other products that will be mentioned in the article; extremely convenient work on agile-development methodology; ample opportunities for customization and process automation.
We decided to stick with a two-week Agile sprint with planning development and testing for 3 sprints (i.e. 1.5 months) ahead. On the details of the process below.
Frankly, I am a fan of Atlassian products. For the version control system I chose Atlassian Stash (Git). However, we didn’t find any applications for branching, merging and other Git merits in the process of developing the database code. All commits occur in the master branch.
For commits, we use the product RedGate Source Control (plugin for SSMS). Here we are confronted with the first technical difficulty: I wanted the code not only to commit by clicking on the “Commit” button in SSMS, and also push to the repository. This is justified in terms of development on a shared-database. While the development is underway (changes in the code of the stored procedure, changes in the structure of the tables) - the changes are stored in the database itself. As soon as the development is complete, the code needs to be seen in the source control. Working with Git is known to work with a local repository, changes from which are then pushed into the repository. Unfortunately, RedGate SC can't push out of the box.
To circumvent this restriction, 2 bat-scripts for RedGate were written, which are used as pull and commit hooks. When the developer updates the list of changes in the plug-in window, a pull is performed, at which the repository at the developer’s station becomes identical to the current state of the repository. So, in the commit list, there are only changes that are present in the database, but not in the version control system.
After selecting the changes (for example, the stored procedure and the table), which should be committed and pressing the Commit button, the changes go to the local repository, and after that, push to Git automatically occurs.
I attach the RedGate Source Control configuration file, as well as the pull.bat and commit.bat sources used in it:
As you can see, working with Stash / Git is done via SSH with authorization by keys. The initial configuration of Red-Gate is documented and in fact has 2 steps: install the plugin and run the initial configuration script (which will create the necessary folders in the user profile and make the first clone of the repository).
I think, here it is necessary to interrupt on how workflow for developers is built. I’ll draw your attention to the fact that all the steps of the process are enforced using JIRA, where various conditions are also checked to determine whether or not a transition can be performed from one status to another.
As usual, the process begins with the creation of an Issue in JIRA. This could be a bug-report, a request for a new feature, a modification of an existing feature or an idea. Depending on the selected component, the type of issue and due date, this ticket is given priority. After that, he enters the planning queue. Issue with a high priority in the planning queue are reviewed and planned within 24-48 hours, all the rest - once a week at team meetings.
By “planning,” I mean defining the complexity and stages of the task, the amount of documentation required, communicating with the person from whom the application came in (for clarification) and deciding which Agile Sprint should place the solution to this problem.
Such a process requires mandatory prior estimates of the time needed to complete the task. We try to build sprints in such a way that each developer is busy 33 hours a week. The remaining 7 hours are left as a buffer for responding to urgent tasks, meetings and situations when another developer went on sick leave / went on vacation.
In the event of an “overflow” of the current / future sprint, it is necessary to decide which tasks we can postpone to a later date. Similarly, if the developer was left without work during the sprint, you can move and take on the task scheduled for the next window.
Tasks can be in the following statuses:
Moving tasks between statuses are possible only according to the following scheme:
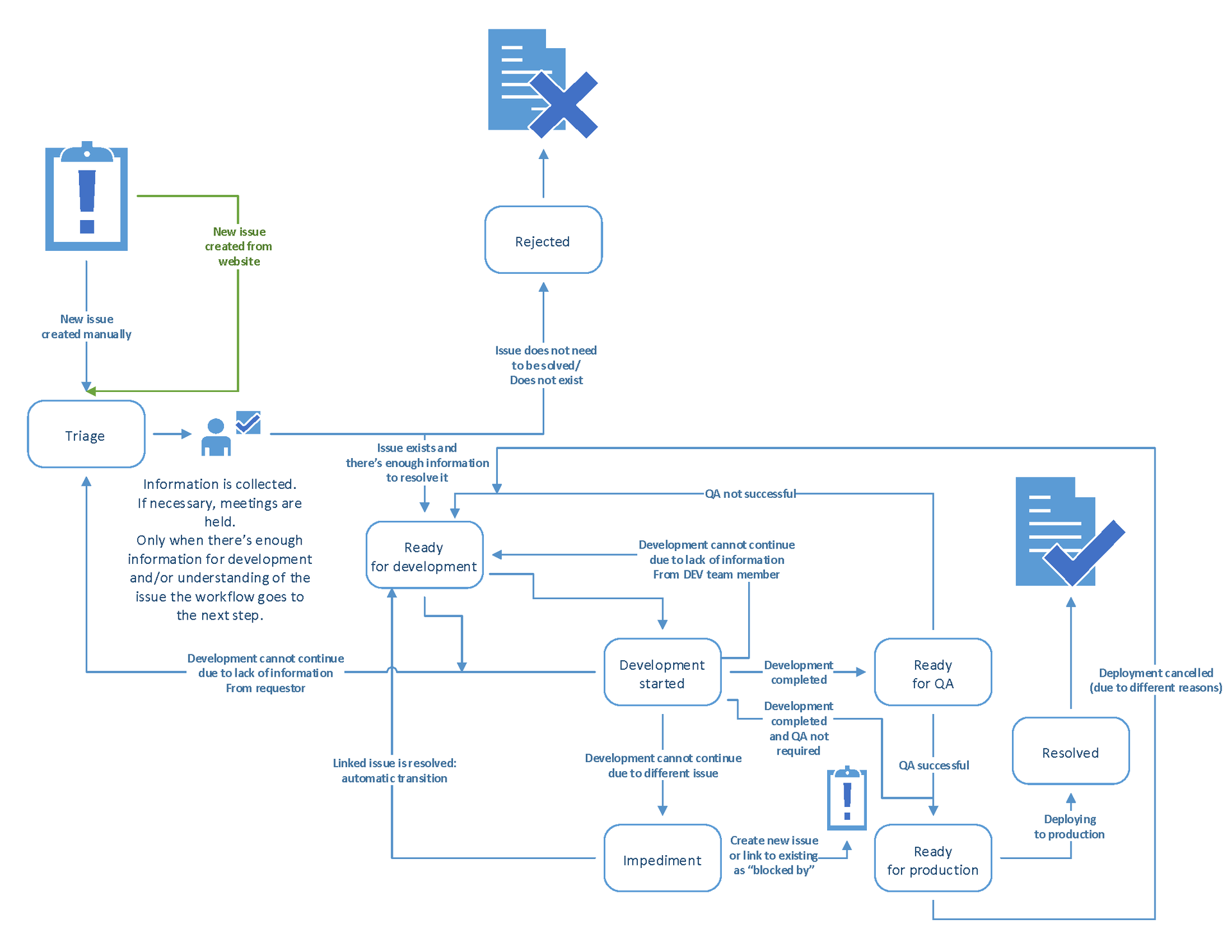
The situations in which the movement should take place are described in the diagram (although in English, but I think understanding will not be a problem for readers), so I will not repeat. Better talk about what is not visible on the diagram:
Brief digression: the processes described are compatible with IEEE development standards.
As a solution for reviewing code changes, we use Atlassian (really ?!) Fisheye / Crucible. Full integration with JIRA and Stash allows you to quickly navigate from the issue page to viewing related commits and code reviews. There are no tricks with JIRA + Stash + Crucible / Fisheye integration, so there is nothing more to tell me about this topic.
In my opinion, this is the most interesting part of our process (relative to the database). As mentioned earlier, we work with a shared database, all using three separated environments: Development, Test / QA and Production.
Development database always has the latest version, because Developers are constantly changing the code and scheme in it. The front-end application that accesses this database is also constantly updated (as soon as the web developers have a local build (without errors), the build with a new feature / fix will be published immediately).
All changes in DEV are published in QA. However, saying “all” - I am cunning. Only those changes that are committed to the source control are published (we don’t want to publish anything that is still “under development”). So instead of the banal synchronization of the scheme, we use the capabilities of RedGate SQL CI and our build server - Atlassian Bamboo.
Bamboo has an MSBuild plan created that calls SQL CI. As soon as the commit occurs, the SQL CI generates the ALTER and CREATE commands, and rolls them onto the QA database.
Although I know that "real" continuous integration should be considered the same publication of changes in production, but I do not have the courage to do so. Instead, we use RedGate SQL Compare to synchronize the schema with QA when closing the sprint. Accordingly, if you look from the point of view of the process - QA base for us is production. However, this does not change the approach that should be taken when developing a database using this process - no change should be fatal. In the world of Microsoft SQL Server as a database for web applications, this means that when publishing a version of a procedure, it must correctly terminate and not call deadlocks. Of course, this requires the appropriate architecture of the web application - all requests are performed through stored procedures, classes must support the absence of the expected parameters of the procedure or a greater number of them. Procedures should support NULL parameters and respond accordingly to such situations without creating security threats. In our case, this seems possible.
I understand that the scenario described by me can be extremely specific, and its use is impossible in other conditions. However, I wrote this in order to share experience with the community, and hope that maybe I will introduce someone to new tools or give a chance to look at someone else’s development process - maybe you will see where you can improve your own procedures, or you can see moments in which your The approach is more intelligent and logical. I wanted to tell a lot more about how automated unit testing and integration testing are arranged and integrated into this process, how we use Microsoft Data Quality Services for the QA process, how documentation is organized, but the text turned out to be too much. Maybe I'll do it in a separate article. In the meantime, I will be glad to questions and constructive criticism.
As a brief background: a year ago, having come to a new job as a head of the database development department (based on Microsoft SQL Server), I experienced the deepest shock of what I saw. A large company, a complex web application, multimillion-dollar contracts, and development is carried out in the production-database, bug reports are received and processed according to the method of “who will shout louder” or “must be done right yesterday.” Naturally, there was no talk about the version control system, continuous integration, procedures and workflow.
Today the situation has changed a lot ( although whom I’m fooling is just starting to change ) and I would like to share both technical and procedural details of the solutions that we use now. Technical details for 90% relate directly to the development for Microsoft SQL Server, but the procedural changes we have touched and web developers, and engineers, and analysts, and testers.
')
Immediately make a reservation, I am not a representative of companies / advertiser of software products, which I will mention in the article. The choice of software used was best suited for our tasks in terms of functionality, price, and also satisfied my personal preferences.
Who are interested in the details - welcome under cat.
Warning: a lot of text, descriptions of procedures and processes ( which, perhaps, are not interesting to anyone ).
Bug tracking, project planning and tracking
The solution based on Atlassian JIRA was chosen as the accounting system for applications. The main reasons were: tight integration with other products that will be mentioned in the article; extremely convenient work on agile-development methodology; ample opportunities for customization and process automation.
We decided to stick with a two-week Agile sprint with planning development and testing for 3 sprints (i.e. 1.5 months) ahead. On the details of the process below.
Version Control System
Frankly, I am a fan of Atlassian products. For the version control system I chose Atlassian Stash (Git). However, we didn’t find any applications for branching, merging and other Git merits in the process of developing the database code. All commits occur in the master branch.
For commits, we use the product RedGate Source Control (plugin for SSMS). Here we are confronted with the first technical difficulty: I wanted the code not only to commit by clicking on the “Commit” button in SSMS, and also push to the repository. This is justified in terms of development on a shared-database. While the development is underway (changes in the code of the stored procedure, changes in the structure of the tables) - the changes are stored in the database itself. As soon as the development is complete, the code needs to be seen in the source control. Working with Git is known to work with a local repository, changes from which are then pushed into the repository. Unfortunately, RedGate SC can't push out of the box.
To circumvent this restriction, 2 bat-scripts for RedGate were written, which are used as pull and commit hooks. When the developer updates the list of changes in the plug-in window, a pull is performed, at which the repository at the developer’s station becomes identical to the current state of the repository. So, in the commit list, there are only changes that are present in the database, but not in the version control system.
After selecting the changes (for example, the stored procedure and the table), which should be committed and pressing the Commit button, the changes go to the local repository, and after that, push to Git automatically occurs.
I attach the RedGate Source Control configuration file, as well as the pull.bat and commit.bat sources used in it:
CommandLineHooks.xml
<?xml version="1.0" encoding="utf-8" standalone="yes"?> <!----> <HooksConfig version="1" type="HooksConfig"> <!-- The name of the config file that will be displayed in the SQL Source Control user interface --> <Name>Git_CompanyName</Name> <Commands type="Commands" version="2"> <element> <key type="string">GetLatest</key> <!-- Updates the local working folder with latest version in source control. --> <!-- Valid macros: ($ScriptsFolder) ($Message) --> <value version="1" type="GenericHookCommand"> <CommandLine>%UserProfile%\Documents\SQLSourceControl\projectname\Pull.bat</CommandLine> <Verify>exitCode == 0</Verify> </value> </element> <element> <key type="string">Add</key> <!-- Adds new files to the local working copy. Changes can then be committed to source control using the Commit command. --> <!-- Valid macros: ($ScriptsFolder) ($Message) ($Files) ($Folders) --> <value version="1" type="GenericHookCommand"> <CommandLine>"C:\Program Files (x86)\Git\bin\git" add ($Files)</CommandLine> <Verify>exitCode == 0</Verify> </value> </element> <element> <key type="string">Edit</key> <!-- Makes the local working copy of the file(s) available for editing. Changes can then be committed to source control using the Commit command. --> <!-- Valid macros: ($ScriptsFolder) ($Message) ($Files) ($Folders) --> <value version="1" type="GenericHookCommand"> <CommandLine></CommandLine> <Verify>exitCode == 0</Verify> </value> </element> <element> <key type="string">Delete</key> <!-- Deletes the file(s) from the local working copy. Changes can then be committed to source control using the Commit command. --> <!-- Valid macros: ($ScriptsFolder) ($Message) ($Files) ($Folders) --> <value version="1" type="GenericHookCommand"> <CommandLine>"C:\Program Files (x86)\Git\bin\git" rm ($Files)</CommandLine> <Verify>exitCode == 0</Verify> </value> </element> <element> <key type="string">Commit</key> <!-- Commits all changes in the local working folder to source control. --> <!-- Valid macros: ($ScriptsFolder) ($Message) --> <value version="1" type="GenericHookCommand"> <CommandLine>%UserProfile%\Documents\SQLSourceControl\projectname\Commit.bat "($Message)"</CommandLine> <Verify>exitCode == 0</Verify> </value> </element> <element> <key type="string">Revert</key> <!-- Undoes changes if an error occurs during a commit --> <!-- Valid macros: ($ScriptsFolder) --> <value version="1" type="GenericHookCommand"> <CommandLine>"C:\Program Files (x86)\Git\bin\git" checkout "($ScriptsFolder)\"</CommandLine> <Verify>exitCode == 0</Verify> </value> </element> </Commands> </HooksConfig> Pull.bat
@echo off set HOME=%USERPROFILE% cd %UserProfile%\Documents\SQLSourceControl\projectname "C:\Program Files (x86)\Git\bin\git" remote add origin ssh://git@stash.companyname.com:7999/projectname/projectname-sql.git "C:\Program Files (x86)\Git\bin\git" pull --force origin master Commit.bat
@echo off set HOME=%USERPROFILE% set comment=%1 cd %UserProfile%\Documents\SQLSourceControl\projectname "C:\Program Files (x86)\Git\bin\git" remote add origin ssh://git@stash.companyname.com:7999/projectname/projectname-sql.git "C:\Program Files (x86)\Git\bin\git" pull origin master "C:\Program Files (x86)\Git\bin\git" commit -m %comment% -o %UserProfile%\Documents\SQLSourceControl\projectname-sql "C:\Program Files (x86)\Git\bin\git" push origin master As you can see, working with Stash / Git is done via SSH with authorization by keys. The initial configuration of Red-Gate is documented and in fact has 2 steps: install the plugin and run the initial configuration script (which will create the necessary folders in the user profile and make the first clone of the repository).
Development and testing process
I think, here it is necessary to interrupt on how workflow for developers is built. I’ll draw your attention to the fact that all the steps of the process are enforced using JIRA, where various conditions are also checked to determine whether or not a transition can be performed from one status to another.
As usual, the process begins with the creation of an Issue in JIRA. This could be a bug-report, a request for a new feature, a modification of an existing feature or an idea. Depending on the selected component, the type of issue and due date, this ticket is given priority. After that, he enters the planning queue. Issue with a high priority in the planning queue are reviewed and planned within 24-48 hours, all the rest - once a week at team meetings.
By “planning,” I mean defining the complexity and stages of the task, the amount of documentation required, communicating with the person from whom the application came in (for clarification) and deciding which Agile Sprint should place the solution to this problem.
Such a process requires mandatory prior estimates of the time needed to complete the task. We try to build sprints in such a way that each developer is busy 33 hours a week. The remaining 7 hours are left as a buffer for responding to urgent tasks, meetings and situations when another developer went on sick leave / went on vacation.
In the event of an “overflow” of the current / future sprint, it is necessary to decide which tasks we can postpone to a later date. Similarly, if the developer was left without work during the sprint, you can move and take on the task scheduled for the next window.
Tasks can be in the following statuses:
- Planning (triage);
- Disclaimer (Rejected);
- Ready to develop (Development started);
- Development in process (In development);
- Waiting (Impediment - an obstacle for the continuation of development );
- Ready for testing (Ready for QA);
- Ready for release (Ready for production);
- Closed (Resolved);
Moving tasks between statuses are possible only according to the following scheme:
The situations in which the movement should take place are described in the diagram (although in English, but I think understanding will not be a problem for readers), so I will not repeat. Better talk about what is not visible on the diagram:
- Large tasks are divided into sub-tasks. Parent issue cannot be in any of the statuses except “Ready for development”, “Development started” and “Impediment”;
- As soon as the developer implements commit, a code-review is created for this commit ( on how this happens, below );
- You can make a commit only if there is a link to the JIRA ticket in the comments, so that the commit, and after the review, are automatically linked to the issue;
- We decided to consider the code-review as part of the development process, so while the review is underway - the ticket is in the “Ready for development / Development started. It is impossible to move the ticket to “Ready for QA” and more so close it while the review is open;
- If the solution of the problem is impossible due to the fact that there is a “blocking” task, the corresponding link in JIRA is used. As long as the blocking ticket is not closed - the issue will be in the status of "Impediment" and it will be impossible to close it;
- Yes, you all correctly understood, the tasks do not open again. In case of detection of a bug / problem after release, a new issue is created, which is linked to the previous one;
- After the issue has been closed - changes for it will be automatically applied to the combat base when the sprint is closed ( how it happens - also below );
Brief digression: the processes described are compatible with IEEE development standards.
Code-review
As a solution for reviewing code changes, we use Atlassian (really ?!) Fisheye / Crucible. Full integration with JIRA and Stash allows you to quickly navigate from the issue page to viewing related commits and code reviews. There are no tricks with JIRA + Stash + Crucible / Fisheye integration, so there is nothing more to tell me about this topic.
Continuous integration (continuous integration)
In my opinion, this is the most interesting part of our process (relative to the database). As mentioned earlier, we work with a shared database, all using three separated environments: Development, Test / QA and Production.
Development database always has the latest version, because Developers are constantly changing the code and scheme in it. The front-end application that accesses this database is also constantly updated (as soon as the web developers have a local build (without errors), the build with a new feature / fix will be published immediately).
All changes in DEV are published in QA. However, saying “all” - I am cunning. Only those changes that are committed to the source control are published (we don’t want to publish anything that is still “under development”). So instead of the banal synchronization of the scheme, we use the capabilities of RedGate SQL CI and our build server - Atlassian Bamboo.
Bamboo has an MSBuild plan created that calls SQL CI. As soon as the commit occurs, the SQL CI generates the ALTER and CREATE commands, and rolls them onto the QA database.
Although I know that "real" continuous integration should be considered the same publication of changes in production, but I do not have the courage to do so. Instead, we use RedGate SQL Compare to synchronize the schema with QA when closing the sprint. Accordingly, if you look from the point of view of the process - QA base for us is production. However, this does not change the approach that should be taken when developing a database using this process - no change should be fatal. In the world of Microsoft SQL Server as a database for web applications, this means that when publishing a version of a procedure, it must correctly terminate and not call deadlocks. Of course, this requires the appropriate architecture of the web application - all requests are performed through stored procedures, classes must support the absence of the expected parameters of the procedure or a greater number of them. Procedures should support NULL parameters and respond accordingly to such situations without creating security threats. In our case, this seems possible.
Conclusion
I understand that the scenario described by me can be extremely specific, and its use is impossible in other conditions. However, I wrote this in order to share experience with the community, and hope that maybe I will introduce someone to new tools or give a chance to look at someone else’s development process - maybe you will see where you can improve your own procedures, or you can see moments in which your The approach is more intelligent and logical. I wanted to tell a lot more about how automated unit testing and integration testing are arranged and integrated into this process, how we use Microsoft Data Quality Services for the QA process, how documentation is organized, but the text turned out to be too much. Maybe I'll do it in a separate article. In the meantime, I will be glad to questions and constructive criticism.
Source: https://habr.com/ru/post/258005/
All Articles