Open Document Document Generator (ODF) on Go
I want to share with the community my best practices on creating a library for generating documents with a programmer-friendly interface. For golang, this niche is no less important than the next web toolkit, since the availability of reports and tools for their generation increases the attractiveness of go for a bloody enterprise.
Creating a report is a multi-step process. Reporting tools can automate different stages of report creation, work with the database, control filtering criteria and counting values, output to the final document. On the last and talk.
At the moment, the results of the search query "golang odf" leave much to be desired. Of course, on request "golang pdf" everything is much more optimistic. But based on my own experience in developing business applications, which should generate certain reports in the form of office documents, I can say with confidence that often, after a beautiful PDF arrives on a user's computer, it checks the numbers, sees a mismatch, and calls in support with a request to correct the figure in the received file, because the report is needed “already yesterday”.
The solution can be the generation of a Word / RTF / ODF / etc document or PDF editing (there are ready-made tools for this, so it's more interesting for admins, not programmers). We also leave to supporters of proprietary formats the opportunity to speak in the comments, but for now I’ll tell you about the generation of ODF.
')
The Open Document format is an open editable office document format. From the well-known office packages that support it, OpenOffice and LibreOffice can be distinguished. The standard for the format of version 1.2 is now in effect, but there are few differences from version 1.0, and they are mostly of an organizational order. Given that the standard for several years, it can be considered stable and rely on it in their work. The format provides for various types of documents, text documents, spreadsheets, presentations, etc. In my experience, the priority formats for storing reports are text (odt) and tabular (ods) documents.
The standard describes the rules for structuring a document model and saving this model in XML format. Technically, a document file should be either one large XML, or a zip archive with several required files and an unlimited number of other files. This format is convenient for embedding images and other files, so I will consider only documents in the format of a zip-archive.
Also, it would not be superfluous to note that ODF is the state standard in the Russian Federation. And although Microsoft Office firmly holds positions in organizations, Open Office is often placed side by side and serves as an alternate aerodrome.
Why not? Simple language, Google support, live community, unoccupied niches. And then, it's just fun. And the ability to compile reliable code in javascript will in some cases allow to transfer the report generation mechanisms to the client, which will increase the flexibility of your web service. Besides, it’s a sin not to use fast native code for such heavy things as complex multi-level reports.
I have been working with the ODF format for quite some time, since 2008, when I needed to implement an ODF report generator and letterhead for work. Then I implemented the component in a more different language for convenient (as it seems to me) programmatic document generation. In general, the result was satisfactory, my component is still working.
After several years of use, as is usually the case, a number of observations have accumulated, which I decided to correct dramatically, rewriting the entire library from scratch. Since the time is now interesting, I chose the Go ecosystem for the realization of a creative itch. But in general, I tried to keep the interface solutions of the previous version as time tested.
Further I will tell more specific things about the format. To familiarize yourself with it, you can read the introduction to the ODF standard .
What is the main difficulty when working with ODF from a programmer's point of view? It lies in the fact that modifying the visible content of a document implicitly leads to the modification of several areas of the document model. The changes affect the content area, the style description area, the contents of the zip package. At the same time, due to the peculiarities of XML, some means to combat invisible characters were introduced into the ODF format, which imposes additional responsibilities on the generation tool.
Another important point is the reuse of styles. The component had to keep track of the styles that the user forms and save them optimally, without duplication.
To implement this whole mechanism, the Formatter concept was invented (peeped). A formatter is a kind of aggregate that contains information about the document model, the document model itself and a bunch of supporting data structures that are hidden from the client code, but allow you to monitor and verify the actions of the client code in one way or another.
For the document model in the previous version, pure DOM was used, which was redundant, so the new version uses a simplified data structure similar to DOM, which is then translated into XML by semi-manual marshalling from the standard Go library. The Carrier-Rider-Mapper (CRM) pattern is used to work with the document model. Carrier is a data carrier, in this case a tree of nodes. Rider - sliders are used to walk through the tree and its modifications, the peculiarity is that in the wooden data structure the slider becomes the node position, and runs through the list of descendants and the attributes of this node. The mapper in this scheme is a high-level mechanism, which with the help of sliders works with a document model, as it is not difficult to guess, in our scheme it is a formatter.
The content of the document itself is recorded as nodes with a specific name from the desired namespace. Node attributes also belong to special namespaces. The text editor, when opened, interprets sets of nodes and attributes in the display of beautiful text and flat labels. Therefore, the main task of the formatter is to correctly and in the right place record the node and its attributes, the name and value of which is described in the standard. For example:
At the moment, I did not set myself the task of reading and modifying an already finished document, but this allows the data model, it is only a question of implementation.
In order to increase the extensibility, the initially monolithic formatter was divided into several more narrowly-formed ones that perform the functions of recording certain sections of the document (tree nodes). ParaMapper records the contents of paragraphs, TableMapper records the tables and their contents, while ParaMapper writes text to cells. This approach allows you to implement the necessary functions of a huge standard point-like efforts, saving time and resources of the project.
Text attributes, character text, paragraph alignment on the page, and other necessary attributes are set using the generalized attribute generation mechanism.
For a particular attribute family, a special builder has been implemented that allows you to set the desired style.
An important feature of the work is that the assignment of attributes does not mean their actual entry into the document. Practically, this leads to the following scheme of work:
Until we write down new attributes or reset them, each successive content will be attributed to these attributes. Additional ability to set the default attributes of the document, which will be attributed to any content that is not assigned special user attributes.
Since the ODF standard is quite voluminous, in my work I have implemented only the minimum of features that may be needed for generating reports. Among such possibilities: text attributes (color, font, size), paragraph attributes (alignment), tables and cell attributes (border attributes, color, line thickness), image embedding.
The main efforts fell on the formation of an extensible framework, which allows you to implement the necessary attributes or even new elements in several steps, even without modifying the library code (you still have to write new code). Interestingly, the format of the spreadsheet for the programmer looks almost the same as the format of a text document. The only thing that changes is the mimetype and the fact that the root element of the document is not text. The table writing mechanism works the same way in both cases. This can be seen in the examples from the odf_test.go module.
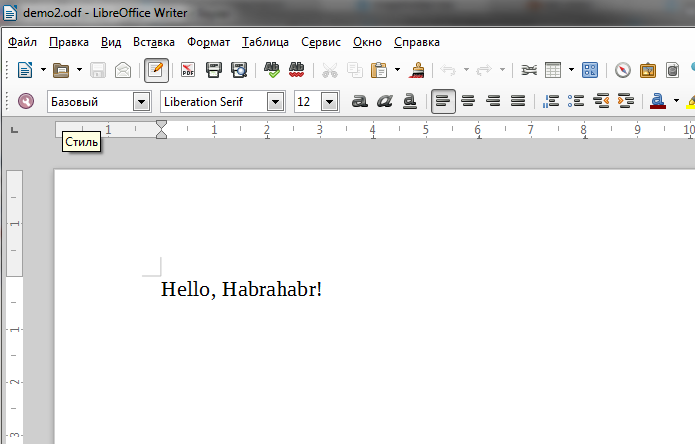
A simple example to demonstrate the health and method of use.
More complex examples can be found in the odf_test.go, demo / report.go file in the project repository.
For the full-weight example, a demo report was generated.
In the end, I would like to note that the formation of an ODF document in itself is not something difficult. The main purpose of the first and second versions of the library was to provide a convenient programmatic interface for further use in the tasks of generating reports and forms. Also, the basic level of this interface opens up possibilities for building converters from other formats, for example, simple HTML, which often generate web application reports.
One of the drawbacks of this approach is the need for tremendous manual work in translating the standard into code, in devising a convenient interface for client code. I fully admit that it probably makes sense to look at automating this work using the RelaxNG processing of the entire ODF standard schema, which describes the possibilities and limitations of the format in a convenient form for automation.
If you are writing to Go and you need reports, go here. The spirit of opensource and team development can take the library to a vast niche. And from ODF, you can get PDF in batch mode, which can significantly enhance the ability to edit tsiferok and tamping up reports.
ODF format description: docs.oasis-open.org/office/v1.2/OpenDocument-v1.2.html
Project repository: github.com/kpmy/odf
Demo: yadi.sk/i/RghkBDHIgcey2
Creating a report is a multi-step process. Reporting tools can automate different stages of report creation, work with the database, control filtering criteria and counting values, output to the final document. On the last and talk.
Introduction
At the moment, the results of the search query "golang odf" leave much to be desired. Of course, on request "golang pdf" everything is much more optimistic. But based on my own experience in developing business applications, which should generate certain reports in the form of office documents, I can say with confidence that often, after a beautiful PDF arrives on a user's computer, it checks the numbers, sees a mismatch, and calls in support with a request to correct the figure in the received file, because the report is needed “already yesterday”.
The solution can be the generation of a Word / RTF / ODF / etc document or PDF editing (there are ready-made tools for this, so it's more interesting for admins, not programmers). We also leave to supporters of proprietary formats the opportunity to speak in the comments, but for now I’ll tell you about the generation of ODF.
')
ODF format
The Open Document format is an open editable office document format. From the well-known office packages that support it, OpenOffice and LibreOffice can be distinguished. The standard for the format of version 1.2 is now in effect, but there are few differences from version 1.0, and they are mostly of an organizational order. Given that the standard for several years, it can be considered stable and rely on it in their work. The format provides for various types of documents, text documents, spreadsheets, presentations, etc. In my experience, the priority formats for storing reports are text (odt) and tabular (ods) documents.
The standard describes the rules for structuring a document model and saving this model in XML format. Technically, a document file should be either one large XML, or a zip archive with several required files and an unlimited number of other files. This format is convenient for embedding images and other files, so I will consider only documents in the format of a zip-archive.
Also, it would not be superfluous to note that ODF is the state standard in the Russian Federation. And although Microsoft Office firmly holds positions in organizations, Open Office is often placed side by side and serves as an alternate aerodrome.
Why go?
Why not? Simple language, Google support, live community, unoccupied niches. And then, it's just fun. And the ability to compile reliable code in javascript will in some cases allow to transfer the report generation mechanisms to the client, which will increase the flexibility of your web service. Besides, it’s a sin not to use fast native code for such heavy things as complex multi-level reports.
Library
I have been working with the ODF format for quite some time, since 2008, when I needed to implement an ODF report generator and letterhead for work. Then I implemented the component in a more different language for convenient (as it seems to me) programmatic document generation. In general, the result was satisfactory, my component is still working.
After several years of use, as is usually the case, a number of observations have accumulated, which I decided to correct dramatically, rewriting the entire library from scratch. Since the time is now interesting, I chose the Go ecosystem for the realization of a creative itch. But in general, I tried to keep the interface solutions of the previous version as time tested.
Further I will tell more specific things about the format. To familiarize yourself with it, you can read the introduction to the ODF standard .
What is the main difficulty when working with ODF from a programmer's point of view? It lies in the fact that modifying the visible content of a document implicitly leads to the modification of several areas of the document model. The changes affect the content area, the style description area, the contents of the zip package. At the same time, due to the peculiarities of XML, some means to combat invisible characters were introduced into the ODF format, which imposes additional responsibilities on the generation tool.
Another important point is the reuse of styles. The component had to keep track of the styles that the user forms and save them optimally, without duplication.
Implementation
To implement this whole mechanism, the Formatter concept was invented (peeped). A formatter is a kind of aggregate that contains information about the document model, the document model itself and a bunch of supporting data structures that are hidden from the client code, but allow you to monitor and verify the actions of the client code in one way or another.
For the document model in the previous version, pure DOM was used, which was redundant, so the new version uses a simplified data structure similar to DOM, which is then translated into XML by semi-manual marshalling from the standard Go library. The Carrier-Rider-Mapper (CRM) pattern is used to work with the document model. Carrier is a data carrier, in this case a tree of nodes. Rider - sliders are used to walk through the tree and its modifications, the peculiarity is that in the wooden data structure the slider becomes the node position, and runs through the list of descendants and the attributes of this node. The mapper in this scheme is a high-level mechanism, which with the help of sliders works with a document model, as it is not difficult to guess, in our scheme it is a formatter.
The content of the document itself is recorded as nodes with a specific name from the desired namespace. Node attributes also belong to special namespaces. The text editor, when opened, interprets sets of nodes and attributes in the display of beautiful text and flat labels. Therefore, the main task of the formatter is to correctly and in the right place record the node and its attributes, the name and value of which is described in the standard. For example:
The <text: p> element represents the OpenDocument file.describes the paragraph element, the contents of which will be displayed as a paragraph, to which the paragraph style will be applied: alignment on the page, line spacing, etc.
At the moment, I did not set myself the task of reading and modifying an already finished document, but this allows the data model, it is only a question of implementation.
In order to increase the extensibility, the initially monolithic formatter was divided into several more narrowly-formed ones that perform the functions of recording certain sections of the document (tree nodes). ParaMapper records the contents of paragraphs, TableMapper records the tables and their contents, while ParaMapper writes text to cells. This approach allows you to implement the necessary functions of a huge standard point-like efforts, saving time and resources of the project.
Text attributes, character text, paragraph alignment on the page, and other necessary attributes are set using the generalized attribute generation mechanism.
For a particular attribute family, a special builder has been implemented that allows you to set the desired style.
An important feature of the work is that the assignment of attributes does not mean their actual entry into the document. Practically, this leads to the following scheme of work:
- Prepared data for recording
- Set the attributes of future content
- Recorded content that gets attributes set
- Attributes written to document
Until we write down new attributes or reset them, each successive content will be attributed to these attributes. Additional ability to set the default attributes of the document, which will be attributed to any content that is not assigned special user attributes.
Since the ODF standard is quite voluminous, in my work I have implemented only the minimum of features that may be needed for generating reports. Among such possibilities: text attributes (color, font, size), paragraph attributes (alignment), tables and cell attributes (border attributes, color, line thickness), image embedding.
The main efforts fell on the formation of an extensible framework, which allows you to implement the necessary attributes or even new elements in several steps, even without modifying the library code (you still have to write new code). Interestingly, the format of the spreadsheet for the programmer looks almost the same as the format of a text document. The only thing that changes is the mimetype and the fact that the root element of the document is not text. The table writing mechanism works the same way in both cases. This can be seen in the examples from the odf_test.go module.
Example
A simple example to demonstrate the health and method of use.
package main import ( "odf/generators" "odf/mappers" "odf/model" _ "odf/model/stub" // "odf/xmlns" "os" ) func main() { if output, err := os.Create("demo2.odf"); err == nil { // defer output.Close() // m := model.ModelFactory() // fm := &mappers.Formatter{} // fm.ConnectTo(m) // , fm.MimeType = xmlns.MimeText // fm.Init() // fm.WriteString("Hello, Habrahabr!") // generators.GeneratePackage(m, nil, output, fm.MimeType) } } More complex examples can be found in the odf_test.go, demo / report.go file in the project repository.
For the full-weight example, a demo report was generated.
If the Yandex disk stops giving the file
Conclusion
In the end, I would like to note that the formation of an ODF document in itself is not something difficult. The main purpose of the first and second versions of the library was to provide a convenient programmatic interface for further use in the tasks of generating reports and forms. Also, the basic level of this interface opens up possibilities for building converters from other formats, for example, simple HTML, which often generate web application reports.
One of the drawbacks of this approach is the need for tremendous manual work in translating the standard into code, in devising a convenient interface for client code. I fully admit that it probably makes sense to look at automating this work using the RelaxNG processing of the entire ODF standard schema, which describes the possibilities and limitations of the format in a convenient form for automation.
If you are writing to Go and you need reports, go here. The spirit of opensource and team development can take the library to a vast niche. And from ODF, you can get PDF in batch mode, which can significantly enhance the ability to edit tsiferok and tamping up reports.
Links
ODF format description: docs.oasis-open.org/office/v1.2/OpenDocument-v1.2.html
Project repository: github.com/kpmy/odf
Demo: yadi.sk/i/RghkBDHIgcey2
Source: https://habr.com/ru/post/257921/
All Articles