Thoughts on the ideal programming language

In this article I would like to share my thoughts on an ideal general purpose programming language. First of all - about the language that could replace C ++.
It so happens that programming languages are my hobby and my main interest in IT. Probably, any programmer sometimes wants to create his own - perfect - programming language. For me, this is more than just a dream; in fact, I have long been collecting all the information in various languages and designing my own language.
')
At various resources, I regularly speak on this subject. In this article, I tried to put the main ideas together. We will look at the main drawbacks of C ++, the features of other languages that can be compared with C ++ one way or another, and - most interestingly - the needs of programmers for language features, using the example of the Boost library.
This article does not claim to be of any technical utility (although if it is useful to someone, that’s great). This article is an invitation to a discussion.
C ++ is far from perfect. I think any C ++ programmer will agree with me.
The disadvantages of C ++ are, first of all, the heavy legacy of C: the terrible system of inclusions and the complete absence of modularity. The inclusion of the header file essentially leads to the inclusion of the entire contents of the file in the compilation unit; since the header files include each other, and modern libraries can contain tens of thousands of header files ... of course, this cannot but affect the compilation time. Sometimes various “precompiled headers” (pch) solutions help, but, as practice shows, these solutions are also far from ideal. For example, Visual C ++ does not allow creating common pch for several projects of the same solution (despite the fact that in precompiled headers, as a rule, they include really common and immutable headers - such as stl, boost, etc.).
And of course, the internal perfectionism peculiar to any programmer strongly protests against such an implementation - essentially a crutch, supports for the originally incorrect architecture.
#define true false Of course, the “lexical” preprocessor, another hello from Xi, is a heavy and tightly inherited unix-way legacy (yes, once it really was a separate program, and yes, there are alternative preprocessors, for example m4 ... but now the preprocessor is definitely perceived as part of language). But it is absolutely obvious that a certain set of possibilities is needed that solves the tasks of the preprocessor (or rather the system of syntax macros), and this should not be a non-standard third-party program that is not related to the language.
And from the relatively new - the turing-completeness of the templates, which gave rise to hellish metaprogramming constructs on these very templates. Initially it was assumed, of course, that the template functions and classes will be used exclusively for writing universal algorithms and data structures that do not depend on the type of data being processed / stored. Great application! But.
The absence of built-in syntax macros and the eternal feeling of hunger for features forced programmers to create full metalanguages on templates, with metatypes, meta-algorithms, and calculations performed by the compiler during compilation ... What's wrong with that? Nothing but the fact that these are essentially crutches.
But it is just unpleasant when, for example, the keywords (struct) are used not at all for what they are intended for. And, of course, inadequate error messages, often due to a random typo and occupying dozens (if not hundreds) of lines per error ... this is truly awful.
Of course, in C ++ there are plenty of other shortcomings - small things. Anyway, many of them are taken into account in the next generation of application programming languages - Java and C #. By the way, for my taste, C # is developing most dynamically and organically absorbs features from many other languages; This is an excellent example of a beautiful and balanced language (and, therefore, an excellent example that you can look at when designing new languages). But neither Java, nor C # all the same are not system programming languages.
It is necessary to note one more group of new (with respect to C ++) languages, to which I would refer D, Go, Rust, Swift, Nim, and at the same time relatively old Objective C (for its very interesting feature - runtime).
What is interesting about these languages?
Let's start with D. The language was developed as “improved C ++”, and indeed - many concepts are made more competently. Contract programming was carefully implemented, there is an FP, there is some implementation of metaprogramming (but you can do better!). A language is compiled into a native code, which means it can claim to be “systematic”. But I would not single out in D one particular feature that overshadows everything. However, it seems that the language has taken the C ++ path in terms of accumulating “hacks”, this is especially noticeable when studying the compiler code (which I occasionally do).
Go. Among the nice things - structural typing of interfaces. The opportunity is extremely interesting, just want to use ...
Another worth mentioning is embedding instead of inheritance. When you look at it, you think - but this must still be in C! It is so easy to implement - and, nevertheless, how elegant this solution looks. The built-in support for multithreading is also good.
Rust The main feature is a terrific system of smart pointers and checks during compilation. Yes, it is worth taking in an ideal language ... although many complain that the system is over complicated. In fact, there is nothing superfluous in it, although I would not give up classical pointers (in Rust, by the way, they are not abandoned, they are simply wrapped in unsafe). Is it possible to combine this? Can. There is nothing terrible in possibilities, their absence is terrible.
And I would also like to mention Objective C. The language is quite old, but people unfamiliar with the OSX world will find a lot of interesting things in it. This is a special implementation of OOP, in particular, sending messages instead of direct calling methods, a system of selectors and metaclasses. Coming to the language from Smalltalk, these features allow you to do many amazing things in a compiled language, which can only be achieved in interpreted scripts - in particular, adding methods to classes right during program execution! In my opinion, a great opportunity.
The next interesting question is the relationship between the features of the language and what can be brought to the libraries. It so happened that for a long time it was C ++ that was the most powerful programming language for universal use (and even now it probably remains, despite all the flaws). There were no alternatives, but C ++ itself developed for a long time rather slowly, but programmers always want more! One way or another, various libraries began to appear and develop. Despite the fact that the standard library already existed, many other libraries and frameworks often duplicated its functionality with their classes. A prime example is strings. It would seem that in C ++ there is a standard string (std :: string), but no - almost every more or less large library has its own implementation of strings. CString (MFC / ATL), QString (Qt), TString (VCL), wxString (wxWidgets).
The same fate befell various containers (dynamic arrays and lists), the base classes for different hierarchies (object - the truth must be admitted that there is nothing like this in the standard library). I'm not talking about the redefinition of simple types, found in almost every small program (not even the library). Remember all sorts of UINT, uint, u32, DWORD, uint32_t ... But the most interesting object for studying the design of a language is perhaps the Boost library (both its official part and the libraries in the Under Constuction status , found in Boost Incubator and other unofficial extensions). To her, we will return.
Now we can say that C ++ looks like this: a small language core, a small standard library, and many third-party libraries that intersect with each other and partially with the standard library and capture various areas of responsibility - from emulating language features to applied tasks. Many libraries rely only on the kernel. Like that:
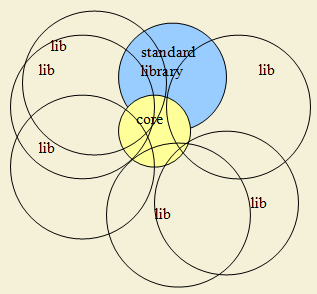
The small language core does not support many language features and provokes programmers to write "emulation of language capabilities." Since there are many programmers, there are many corresponding emulations; they are generally incompatible with each other; cumbersome (since they are built on non-standard and / or non-obvious use of existing language capabilities); difficult to compile and debug, and indeed in understanding. On the other hand, a small kernel allows the language to contain nothing superfluous and that is good (moreover, it is necessary for system programming). Contradiction? In fact, a solvable contradiction. Here is my ideal language organization chart:
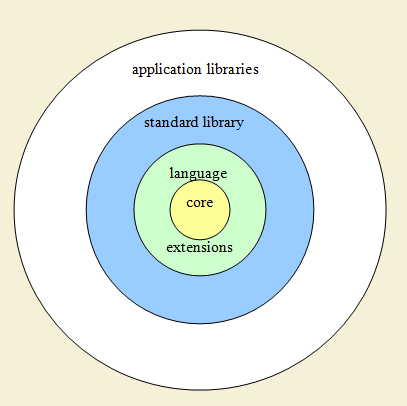
In the center - the basic language core. “Language extensions” around it, language extensions are some parts of the language that are supported syntactically, but which can be turned on and off when building a project, as well as replaced with their own implementations; next is the standard library that supports everything related to general-purpose programming; and around - application libraries that do not try to emulate kernel functions, but solve purely applied tasks. Application libraries must implement specific things. This is essential - the difference between the general and the specific. Work with graphics, with a network, with iron; specific mathematics, cryptography, applied libraries for some specific areas; working with different file formats, with databases, with various services ... all these are specific, applied areas, and they certainly should be implemented as libraries. But reflection or multithreading, higher-order functions or coroutines are fundamental things in terms of language, and they must be supported in the language (some with the possibility of replacing the default implementation with something else).
Let's go back to the Boost library. Let's talk about Buste as the clearest example of the fact that languages are developing much more slowly than programmers want. A good half of the Bust libraries are essentially an emulation of language features. Perhaps someday I will write separate articles about the Bust library ... here is just a brief overview of what is there - in the context of including these features directly into the programming language. Bust has his own library classification, with which I do not fully agree (although I have different goals for classification). Some libraries certainly belong to the “standard library” group; part - generally applied libraries; but a significant part is exactly what is missing in the language itself, in the core! I will not give here either my division, or the description of libraries (this is the topic of a separate article, or even several). Instead, I will simply give a list (incomplete!) Of those libraries of the Bust libraries, which I would refer to the language core:
- integer - meta information and traits for integer types
- multiprecision - wrapper for libraries of work with arbitrary precision numbers GMP, MPIR, MPFR
- any - universal dynamic type
- optional - an optional type, maybe; in theory should be built into the language and integrated with nullable
- variant - algebraic data type (sum-type, tagged union)
- preprocessor - metaprogramming on the preprocessor
- inentity_type - a helper for generating unique type names
- assign - multi-operations associated with filling containers
- mpl - type containers and operations on them
- fusion - containers of types and values and operations on them
- tuple tuples
- bind - functional objects created using partial application of functions
- function - functional objects
- lambda - lambda functions; by the way, something superior lambda from c ++ 11;
- local_function - emulation of nested functions
- signals2 - signals and slots
- context - saving and restoring the state of the thread (stack and registers)
- coroutine - coroutine implementation
- foreach - cycle through collections
- parameter - emulation of named functions arguments
- scope_exit is a language construct, in the D language this is called scope (exit), scope (success), scope (failure), in Go - defer
- type_erasure is an alternative implementation of polymorphism runtime
- predef - meta information about the OS, compiler, platform ...,
- typeof - emulation of the typeof / decltype operator
- endian - work with numbers with different byte order
Let me remind you that this is not a complete list (and I don’t even consider the library of Boost extensions here, and there are also a lot of interesting things - for example Contract, Hana, Introspection, Mirror, Reflection ...). I note that not all libraries should be included in the language core: in general, it is enough to include only some small (and in fact common to many libraries) part of the kernel, and it may turn out that many libraries from this list will not be needed at all. Also, inclusion in the language core will allow you to avoid the many restrictions imposed on existing artificial implementations of various features. Such excellent features as algebraic data types, the universal dynamic type any, optional types, named parameters are of course best implemented at the language level.
We now turn to the “Language Extensions”. What is it and why did I introduce it?
In fact, such “extensions” somehow or other exist in C ++, just no one identifies them into a separate group. An example is the memory allocation system in C ++. The language core interface is the new and delete operators as such; their language syntax is clearly spelled out in the language core, and their semantics (allocation and freeing of memory) is written in the documentation. In this case, the language provides a standard implementation, but if you wish, you can redefine these operators and write your own memory allocation system. The second example is type identification at runtime, RTTI. The example demonstrates another aspect - the detachability of extensions.
I have a lot of experience with microcontrollers, with a very small amount of onboard memory I had to allocate memory only statically - there was no “heap”, and even more so there was no RTTI.
The difference between Core and Extensions is that core elements cannot be redefined; so, the conditional if statement is unambiguous, its logic is embedded in the kernel and there is no way to replace its implementation with something else. Extensions are spelled out at the syntax level in the kernel , and some default implementation is provided in the language that will suit 95% of programmers; the remaining 5% are invited to write their own implementation, however corresponding to the language interfaces, or disable it altogether - for specific cases.
Other such extensions could be
- garbage collection (see Rust - Gc)
- memory management using reference counting (see Rust - Rc, Arc)
- long arithmetic (important here is that arithmetic should be integrated into the language, including at the literal level; and long constants like 128-bit numbers should be written in a natural way - in the form of numeric literals, the same for all implementations!)
- multithreading (go operator in go language)
- reflection (yes, there are a lot of ways to implement it manually - but no one can cope with this task anyway)
- virtuality and multimethods
- signals and slots
- objc style speaker
- embedded scripts
- rtti
- exception handling (there are different ways to implement it; there are cases when it is not needed at all)
- floating point (yes, some microcontrollers do not have FPU and the library emulates floating-point operation)
and probably much more that I did not remember right away.
In the end, I want to dwell on one philosophical principle that underlies my idea of an ideal programming language. Usually during the discussion on the forums, when you start saying that there is no feature Y in language X, there will definitely be someone who will say: well, then, if you take features A, B and C, and fasten the crutches D, E and F, then we get almost Y. Yes, it is. But I do not like this approach. You can imagine that such programmers will arrange some difficult way through the maze. It is possible to go through the maze, but the path is not obvious. I would like to see, instead of a labyrinth, there was a spacious area where you could walk from any point to any other one in a straight line. Just in a straight line.
Source: https://habr.com/ru/post/257875/
All Articles