Uninvited guest. Why are virtual machines not the best solution for tomorrow's applications?
Hello, dear readers!
Despite the ongoing holidays, we do not cease to study foreign technical thought and from time to time to check with O'Reilly Radar. In particular, we were interested in an article by Dinesh Subhraveti published on May 4 telling about the prospects and problems of virtualization. It addresses the problems of adequate use of virtualization, performance of distributed systems, proper work with big data. The author is trying to investigate the question of whether virtual machines are indispensable, and whether they will have a place in the future. Since there are very high-ranking books on the market, one way or another connected with this colossal topic, we hope that the proposed article will seem informative and interesting to you. If you have any suggestions on the publication of such books, we will be happy to hear them.

')
Currently, the most upscale among distributed systems are operating systems for data centers. So, Hadoop is developing from the MapReduce framework in YARN - a universal platform for horizontal scaling of applications.
In order for such a rich ecosystem to work on such platforms, in which various programs normally coexist, it is absolutely necessary how to isolate these applications from each other. The isolation mechanism should ensure compliance with the limit of consumed resources, eliminate unnecessary software dependencies between applications and the host, guarantee security and privacy, localize failures, etc. This problem is easily and beautifully solved with the help of containers. However, the question often arises: why not use a virtual machine (VM)? In the end, all of these systems face the same set of problems that are solved by virtualizing traditional enterprise applications.
Why not use virtual machines?
Although YARN and similar systems face approximately the same problems that are traditionally solved in practice using virtual machines, VMs are not well suited for horizontal scaling for a number of reasons.
Costs
The resources consumed by the level of virtualization can easily become a significant factor affecting the overall costs of the system. Such overheads may not play a significant role in traditional applications, but when we deal with large distributed applications, the percentage of resource overheads quickly accumulates. Host memory shares lost at each node in a horizontally scaled cluster result in huge power waste. Moreover, the active use of resources by virtual machines prevents dense configurations. As a rule, only one or three virtual machines can work on one physical machine.
High starting delay is the main source of costs when using virtual machines. Unlike conventional applications that run and then simply continue to work, very short-term tasks are often performed in new ecosystems. If a typical task within a large, highly parallelized task is completed within a couple of minutes, then it is unacceptable to spend a serious percentage of this time only on starting the virtual machine.
Despite the extensive optimizations being made across the entire stack, from hardware to the application level, the runtime overhead due to virtual machines remains a problem. Although the hardware capabilities make it possible to cope with the costs of processor virtualization, the problem of costs remains acute with workloads associated primarily with input / output. So, in the case of Hadoop, the virtualized I / O stack consists of HDFS, a guest file system, a guest driver, a virtual device, an image format interpreter, a host file system, a host driver, and finally a physical device. The accumulated costs are quite substantial compared to the native version.
Interestingly, the results of experiments to measure the performance of tasks performed on a virtualized distributed Hadoop framework may lead to incorrect conclusions. If the task is illiterate, then it seems that in the virtual infrastructure it is sometimes performed even faster than on the native equipment. However, this is explained only by a more complete overall utilization of resources in terms of the task, and not by any acceleration of individual tasks, due to virtualization as such. After all, correctly adjusted tasks are ultimately limited by the amount of resources provided by basic equipment.
How the application hypervisor plays hide and seek
As a rule, applications and operating systems are designed to interact with each other. In the context of a virtualized application, the hypervisor plays the role of a normal operating system that manages physical hardware. In this case, the symbiosis of applications and operating systems is destroyed, since an opaque level of virtualization arises between them. In fact, both the host, the guest system, and the hypervisor perform only a subset of the functions of a normal operating system. It is not so important whether it is a type A or type B hypervisor. For example, in the case of Xen, the Xen core is the hypervisor, Dom0 is the host system, and guest systems work on DomUs. In Linux, Linux itself is a host, Qemu / KVM is a hypervisor, which, in turn, provides the work of guest kernels. A multi-level system of programs that perform low-level system functions implicitly destroys existing application interfaces.
In applications running in a virtual machine, it is impossible to consider the topology and configuration of basic physical resources. A specific component may “appear” to the application directly connected block device, and will be a file located on some distant NFS-server. Obfuscation of computer and network topologies complicates resource planning at the application level. In the case of Hadoop, the resource manager will make sub-optimal planning decisions, since it will start from the wrong ideas about physical resources. Data and information about the locality of tasks may be lost, but this is still half the problem; the main and duplicate blocks may be in the same failed domain, due to which the data loss will be irretrievable.
Similarly, the hypervisor does not allow to “look” into the application. A rough idea of resources in the absence of information about their semantics at the application level does not allow for many optimization options. For example, reading a specific config value from a file is a read operation performed by a block device at the virtual hardware level. Without semantic context, optimizations such as prefetching or caching will be ineffective. Another example: the hypervisor reserves large areas of physical memory, even if it is not used by the guest application — the fact is that the hypervisor simply cannot detect unused memory pages in the guest system.
Technical support
A large number of virtual machines and guest operating systems based on them are burdensome technical support. Timely application of security patches to each individual virtual machine in the vastly dynamic infrastructure, where virtual machines are created and deleted literally on the fly, in a large enterprise can be a very difficult task. Excessive proliferation of virtual machines is another problem. Moreover, the actual cost of licensing guest operating systems can be fabulous, especially when it comes to scaling out.
Bad pairing between application and operating system
It is believed that virtualization helps to untie applications from hardware. However, virtualization leads to the formation of new close links between applications and their guest operating systems. Applications run as add-ons to a virtual machine, which, in turn, draws the guest operating system into the “black box” of the virtualized image. You can migrate an entire virtual machine entirely — for example, for hardware repairs — but it is impossible to upgrade the operating system without disrupting the functioning of the application running in it.
Since the application is always bound to the guest operating system, those resources that are allocated to the application cannot be scaled on demand. First, resources are added to the guest operating system, and it, in turn, provides them to the application. However, guest operating systems usually require a reboot in order for them to recognize additional memory or new kernels.
Virtual Machines: Incorrect Application Abstraction
Ultimately, the customer is interested in a well-functioning application — not operating systems or virtual machines. That application is required to virtualize. However, the virtual machine cannot directly virtualize applications; to compensate for this deficiency, it needs an additional guest operating system.

Virtualization of the application requires additional machines from the guest OS.
Author's illustration.
In the course of many years of work, industrial and research committees have devoted many joint efforts to solving the problems associated with virtual machines. Numerous innovations have been proposed. Some of them even developed into independent technologies. However, on closer examination, it turns out that many of these innovations do not give progress and a transition to a qualitatively new level compared to containers. Such technologies are primarily aimed at eliminating the problems caused by the virtual machines themselves. In principle, the huge industrial development segment is oriented in the wrong direction: we optimize virtual machines, not applications. Such a fundamentally erroneous model allows achieving only relative optimization. In the following examples, only some of the widespread techniques invented to overcome inconsistencies between applications and virtual machines are considered.
Paravirtualization
Paravirtualization is one of the most pervasive ways to optimize virtual machine performance. Since the hypervisor can not directly view the guest operating system and its applications, as well as affect it or them. Instead, it relies on a guest operating system, which receives hints from it and performs the operations it prescribes. The interface between the guest system and the hypervisor is called the para-virtualization API or the hypercall interface. Of course, this technique will not work with standard unmodified operating systems. Making such changes is not easy, as well as maintaining them, adapting to changing versions of the kernel.
Dynamic memory reallocation
Operating systems are very responsive to physical memory. Due to the whole complex of techniques (lazy allocation, copying while recording, etc.), requests for memory allocation are rejected in all cases except for extreme necessity. In order to cope with the inability of the hypervisor to access the internal components of the operating system, a technique called “dynamic memory redistribution” is used, which is also called “ballooning”. On the guest system, a special driver is used to detect unused memory areas and pass this information to the hypervisor. Unused memory pages are squeezed out of the guest operating system and provided to the host system. Unfortunately, the result is an unpleasant side effect: applications periodically experience an artificial memory deficit. This technique allows a weak solution, but still significantly inferior to the native kernel mechanisms that centrally allocate memory.
Deduplication
The use of several instances of the same guest operating system and its standard services in a closed area of the address space of each virtual machine leads to the fact that some samples of content are stored on several memory pages. To reduce such costs, an online page deduplication technique has been developed, called “shared memory pages” (KSM). However, it is fraught with serious performance costs, especially on those hosts where memory limitations are not provided and configurations with NUMA (uneven memory access) are used.
Open the black box
Virtual machines regard file system data as monolithic blobs of images that the guest file system should interpret. Some work was done to clarify the opaque structure of virtual machine images for indexing, deduplication, offline competitive patching of base images, etc. However, it turned out that it is very difficult to take into account all the characteristic features of image formats, segments of devices allocated in them, file systems and changing disk structures.
Containers: Economical Virtualization for Horizontally Scalable Applications
Containers are a very unique virtualization mechanism aimed at direct virtualization of the applications themselves, and not of the operating system. While the virtual machine provides a virtual hardware interface on which the operating system can run, the container provides an interface of the virtual operating system on which applications can run. It separates an application from its ecosystem through a consistent interface of the virtual operating system, virtualizing a qualitatively defined and semantically rich interface between the application and the operating system, and not between the operating system and hardware.
A container consists of multiple namespaces, each of which projects a subset of host resources onto an application by their virtual names. Computing resources are virtualized by the process namespace, network resources are virtualized by the network namespace, the virtual file system is represented by the mount namespace, etc. Since containerized processes natively work on a host under the control of a virtualization layer, those subsystems to which container virtualization is applied can be adapted for use in a particular practical context. The extent to which a host and its resources are provided for use by a containerized process can be controlled with delicate precision. For example, a containerized application may be limited by its own private view of the file system, but it may be allowed to access the host’s network.
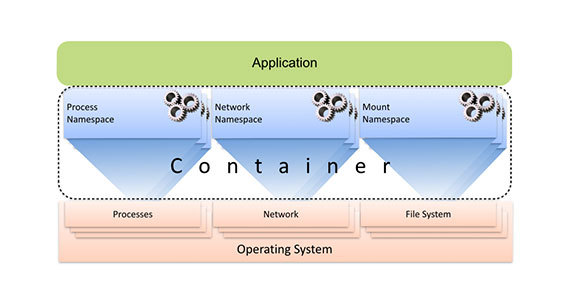
Containers project a subset of host resources onto an application using multiple namespaces. Author's illustration
Unlike working with virtual machines, there is no guest operating system level when working with containers, which makes the containers lightweight, there is no duplication of functionality, and the costs associated with intermediate levels disappear almost completely. At the same time, the launch delay also becomes negligible, the scaling capabilities increase by an order of magnitude, and the system management is simplified.
There are already the first versions of data centers using technologies such as YARN, Mesos and Kubernetes. To ensure adequate isolation in these data centers, containers are used as the main substrate. This opens the way to innovations of a new generation, that is, to true progress.
Despite the ongoing holidays, we do not cease to study foreign technical thought and from time to time to check with O'Reilly Radar. In particular, we were interested in an article by Dinesh Subhraveti published on May 4 telling about the prospects and problems of virtualization. It addresses the problems of adequate use of virtualization, performance of distributed systems, proper work with big data. The author is trying to investigate the question of whether virtual machines are indispensable, and whether they will have a place in the future. Since there are very high-ranking books on the market, one way or another connected with this colossal topic, we hope that the proposed article will seem informative and interesting to you. If you have any suggestions on the publication of such books, we will be happy to hear them.
')
Currently, the most upscale among distributed systems are operating systems for data centers. So, Hadoop is developing from the MapReduce framework in YARN - a universal platform for horizontal scaling of applications.
In order for such a rich ecosystem to work on such platforms, in which various programs normally coexist, it is absolutely necessary how to isolate these applications from each other. The isolation mechanism should ensure compliance with the limit of consumed resources, eliminate unnecessary software dependencies between applications and the host, guarantee security and privacy, localize failures, etc. This problem is easily and beautifully solved with the help of containers. However, the question often arises: why not use a virtual machine (VM)? In the end, all of these systems face the same set of problems that are solved by virtualizing traditional enterprise applications.
"Any problems in computer science are solved by adding another level of indirection - except, of course, the problem of an overabundance of levels of indirection" - David Wheeler.
Why not use virtual machines?
Although YARN and similar systems face approximately the same problems that are traditionally solved in practice using virtual machines, VMs are not well suited for horizontal scaling for a number of reasons.
Costs
The resources consumed by the level of virtualization can easily become a significant factor affecting the overall costs of the system. Such overheads may not play a significant role in traditional applications, but when we deal with large distributed applications, the percentage of resource overheads quickly accumulates. Host memory shares lost at each node in a horizontally scaled cluster result in huge power waste. Moreover, the active use of resources by virtual machines prevents dense configurations. As a rule, only one or three virtual machines can work on one physical machine.
High starting delay is the main source of costs when using virtual machines. Unlike conventional applications that run and then simply continue to work, very short-term tasks are often performed in new ecosystems. If a typical task within a large, highly parallelized task is completed within a couple of minutes, then it is unacceptable to spend a serious percentage of this time only on starting the virtual machine.
Despite the extensive optimizations being made across the entire stack, from hardware to the application level, the runtime overhead due to virtual machines remains a problem. Although the hardware capabilities make it possible to cope with the costs of processor virtualization, the problem of costs remains acute with workloads associated primarily with input / output. So, in the case of Hadoop, the virtualized I / O stack consists of HDFS, a guest file system, a guest driver, a virtual device, an image format interpreter, a host file system, a host driver, and finally a physical device. The accumulated costs are quite substantial compared to the native version.
Interestingly, the results of experiments to measure the performance of tasks performed on a virtualized distributed Hadoop framework may lead to incorrect conclusions. If the task is illiterate, then it seems that in the virtual infrastructure it is sometimes performed even faster than on the native equipment. However, this is explained only by a more complete overall utilization of resources in terms of the task, and not by any acceleration of individual tasks, due to virtualization as such. After all, correctly adjusted tasks are ultimately limited by the amount of resources provided by basic equipment.
How the application hypervisor plays hide and seek
As a rule, applications and operating systems are designed to interact with each other. In the context of a virtualized application, the hypervisor plays the role of a normal operating system that manages physical hardware. In this case, the symbiosis of applications and operating systems is destroyed, since an opaque level of virtualization arises between them. In fact, both the host, the guest system, and the hypervisor perform only a subset of the functions of a normal operating system. It is not so important whether it is a type A or type B hypervisor. For example, in the case of Xen, the Xen core is the hypervisor, Dom0 is the host system, and guest systems work on DomUs. In Linux, Linux itself is a host, Qemu / KVM is a hypervisor, which, in turn, provides the work of guest kernels. A multi-level system of programs that perform low-level system functions implicitly destroys existing application interfaces.
In applications running in a virtual machine, it is impossible to consider the topology and configuration of basic physical resources. A specific component may “appear” to the application directly connected block device, and will be a file located on some distant NFS-server. Obfuscation of computer and network topologies complicates resource planning at the application level. In the case of Hadoop, the resource manager will make sub-optimal planning decisions, since it will start from the wrong ideas about physical resources. Data and information about the locality of tasks may be lost, but this is still half the problem; the main and duplicate blocks may be in the same failed domain, due to which the data loss will be irretrievable.
Similarly, the hypervisor does not allow to “look” into the application. A rough idea of resources in the absence of information about their semantics at the application level does not allow for many optimization options. For example, reading a specific config value from a file is a read operation performed by a block device at the virtual hardware level. Without semantic context, optimizations such as prefetching or caching will be ineffective. Another example: the hypervisor reserves large areas of physical memory, even if it is not used by the guest application — the fact is that the hypervisor simply cannot detect unused memory pages in the guest system.
Technical support
A large number of virtual machines and guest operating systems based on them are burdensome technical support. Timely application of security patches to each individual virtual machine in the vastly dynamic infrastructure, where virtual machines are created and deleted literally on the fly, in a large enterprise can be a very difficult task. Excessive proliferation of virtual machines is another problem. Moreover, the actual cost of licensing guest operating systems can be fabulous, especially when it comes to scaling out.
Bad pairing between application and operating system
It is believed that virtualization helps to untie applications from hardware. However, virtualization leads to the formation of new close links between applications and their guest operating systems. Applications run as add-ons to a virtual machine, which, in turn, draws the guest operating system into the “black box” of the virtualized image. You can migrate an entire virtual machine entirely — for example, for hardware repairs — but it is impossible to upgrade the operating system without disrupting the functioning of the application running in it.
Since the application is always bound to the guest operating system, those resources that are allocated to the application cannot be scaled on demand. First, resources are added to the guest operating system, and it, in turn, provides them to the application. However, guest operating systems usually require a reboot in order for them to recognize additional memory or new kernels.
Virtual Machines: Incorrect Application Abstraction
Ultimately, the customer is interested in a well-functioning application — not operating systems or virtual machines. That application is required to virtualize. However, the virtual machine cannot directly virtualize applications; to compensate for this deficiency, it needs an additional guest operating system.
Virtualization of the application requires additional machines from the guest OS.
Author's illustration.
In the course of many years of work, industrial and research committees have devoted many joint efforts to solving the problems associated with virtual machines. Numerous innovations have been proposed. Some of them even developed into independent technologies. However, on closer examination, it turns out that many of these innovations do not give progress and a transition to a qualitatively new level compared to containers. Such technologies are primarily aimed at eliminating the problems caused by the virtual machines themselves. In principle, the huge industrial development segment is oriented in the wrong direction: we optimize virtual machines, not applications. Such a fundamentally erroneous model allows achieving only relative optimization. In the following examples, only some of the widespread techniques invented to overcome inconsistencies between applications and virtual machines are considered.
Paravirtualization
Paravirtualization is one of the most pervasive ways to optimize virtual machine performance. Since the hypervisor can not directly view the guest operating system and its applications, as well as affect it or them. Instead, it relies on a guest operating system, which receives hints from it and performs the operations it prescribes. The interface between the guest system and the hypervisor is called the para-virtualization API or the hypercall interface. Of course, this technique will not work with standard unmodified operating systems. Making such changes is not easy, as well as maintaining them, adapting to changing versions of the kernel.
Dynamic memory reallocation
Operating systems are very responsive to physical memory. Due to the whole complex of techniques (lazy allocation, copying while recording, etc.), requests for memory allocation are rejected in all cases except for extreme necessity. In order to cope with the inability of the hypervisor to access the internal components of the operating system, a technique called “dynamic memory redistribution” is used, which is also called “ballooning”. On the guest system, a special driver is used to detect unused memory areas and pass this information to the hypervisor. Unused memory pages are squeezed out of the guest operating system and provided to the host system. Unfortunately, the result is an unpleasant side effect: applications periodically experience an artificial memory deficit. This technique allows a weak solution, but still significantly inferior to the native kernel mechanisms that centrally allocate memory.
Deduplication
The use of several instances of the same guest operating system and its standard services in a closed area of the address space of each virtual machine leads to the fact that some samples of content are stored on several memory pages. To reduce such costs, an online page deduplication technique has been developed, called “shared memory pages” (KSM). However, it is fraught with serious performance costs, especially on those hosts where memory limitations are not provided and configurations with NUMA (uneven memory access) are used.
Open the black box
Virtual machines regard file system data as monolithic blobs of images that the guest file system should interpret. Some work was done to clarify the opaque structure of virtual machine images for indexing, deduplication, offline competitive patching of base images, etc. However, it turned out that it is very difficult to take into account all the characteristic features of image formats, segments of devices allocated in them, file systems and changing disk structures.
Containers: Economical Virtualization for Horizontally Scalable Applications
Containers are a very unique virtualization mechanism aimed at direct virtualization of the applications themselves, and not of the operating system. While the virtual machine provides a virtual hardware interface on which the operating system can run, the container provides an interface of the virtual operating system on which applications can run. It separates an application from its ecosystem through a consistent interface of the virtual operating system, virtualizing a qualitatively defined and semantically rich interface between the application and the operating system, and not between the operating system and hardware.
A container consists of multiple namespaces, each of which projects a subset of host resources onto an application by their virtual names. Computing resources are virtualized by the process namespace, network resources are virtualized by the network namespace, the virtual file system is represented by the mount namespace, etc. Since containerized processes natively work on a host under the control of a virtualization layer, those subsystems to which container virtualization is applied can be adapted for use in a particular practical context. The extent to which a host and its resources are provided for use by a containerized process can be controlled with delicate precision. For example, a containerized application may be limited by its own private view of the file system, but it may be allowed to access the host’s network.
Containers project a subset of host resources onto an application using multiple namespaces. Author's illustration
Unlike working with virtual machines, there is no guest operating system level when working with containers, which makes the containers lightweight, there is no duplication of functionality, and the costs associated with intermediate levels disappear almost completely. At the same time, the launch delay also becomes negligible, the scaling capabilities increase by an order of magnitude, and the system management is simplified.
There are already the first versions of data centers using technologies such as YARN, Mesos and Kubernetes. To ensure adequate isolation in these data centers, containers are used as the main substrate. This opens the way to innovations of a new generation, that is, to true progress.
Source: https://habr.com/ru/post/257541/
All Articles