Backing up and restoring virtualized Microsoft SQL Server databases
Version 8.0 of Veeam Backup & Replication provides a wide range of options for backing up and restoring virtualized SQL servers and databases, including popular methods for full virtual machine recovery, file-level granular recovery and database recovery using the Veeam Explorer tool for Microsoft SQL Server. About the last of these will be my story today.
Of course, you need to start “from the stove” - that is, from understanding how recovery options are associated with the backup settings and the virtualized SQL Server itself.
Everyone knows that Veeam creates a backup of the virtual machine at the image level - that is, in the case of SQL Server, the entire server will be backed up, including all instances and bases on them. In order for the backup to be consistent with the transaction (transactionally-consistent), when creating it, you should use image processing with regard to the operation of the application (application-aware image processing). Moreover, you can prepare a backup copy of the server to ensure that later it will restore specific databases to a state at any time or even to a selected transaction.
')
Here are a few factors to consider when planning a SQL Server backup for later recovery of databases:
In order to ensure that the database can be restored at any time or to a selected transaction, we need to create:
Let's see how Veeam Backup & Replication manages these tasks.
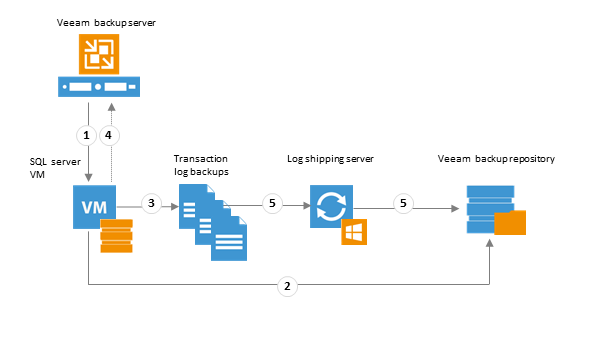
So, if we need to back up the logs (which will give us the most “targeted” recovery of the database), then the backup task of our SQL Server will, in fact, include 2 interrelated tasks:
This "bunch" of tasks works like this:
According to the schedule, Job Manager, running on the Veeam backup server, launches the “parent”, which creates a backup of the virtual machine with SQL Server and puts it into the repository.
The “child” session starts: with its beginning, Veeam Backup & Replication installs a component called Veeam Log Shipper Service inside the guest OS of our SQL server. This service will work throughout the “children's” session and be responsible for processing logs. He, in particular, collects information about which databases should be backed up during the session, and how exactly the data can be transferred to the repository (either directly or through a log shipping server - let's call it “journal proxy”). At the end of the "child" session, this component is stopped and demolished from the guest OS; with the beginning of a new session, everything repeats (installation, data collection, stop, uninstall).
A backup of the transaction log on the guest OS is created by means of the SQL Server itself; he also performs trunk logging on a guest house. The resulting copies are saved as .BAK files in a temporary folder on the guest file system (the default is % allusersprofile% \ Veeam \ Backup ).
Every 15 minutes (default frequency) Job Manager identifies which databases are available on this SQL Server, and correlates the resulting list with data about the contents of the virtual machine backup (taken from the Veeam Backup & Replication database). Thus, it turns out for which databases there are journals that should be “taken” to the repository and put next to the corresponding SQL server backup during this 15-minute interval.
Note: If there are still copies of logs that for some reason were not “taken away” to the repository during the previous intervals, Veeam will identify them by enumerating .BAK files in the temporary folder and mark them as “to be shipped”.
.BAK files are transferred from the guest to the repository (directly or through a "journal proxy"); The Veeam transport service on the source side before this also compresses them according to its default settings. On the repository side, the compression is performed according to the settings of the “parent” task (more details can be found here - in Russian).
After the data is “transported” to the repository, they are deleted from the temporary folder on the virtual machine. If something could not be “transported” during the allotted interval, then these files will not be deleted, and during the next 15-minute Veeam will try again.
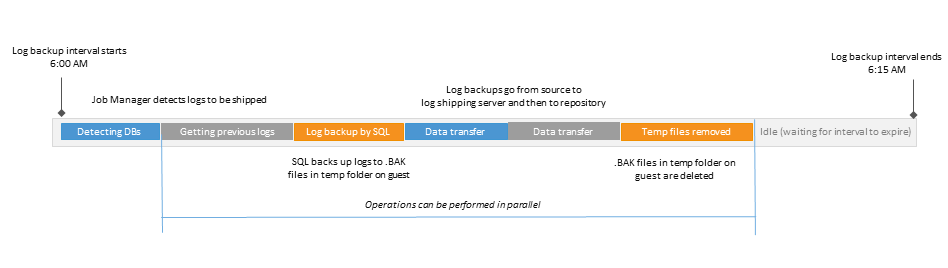
The operations that are performed during the 15-minute interval (the so-called log backup interval) are shown in the figure:
The set of such intervals (their duration, by the way, can be changed) between two consecutive launches of the “parent” task and is a “child” session.
If you draw a picture, it will look like this:
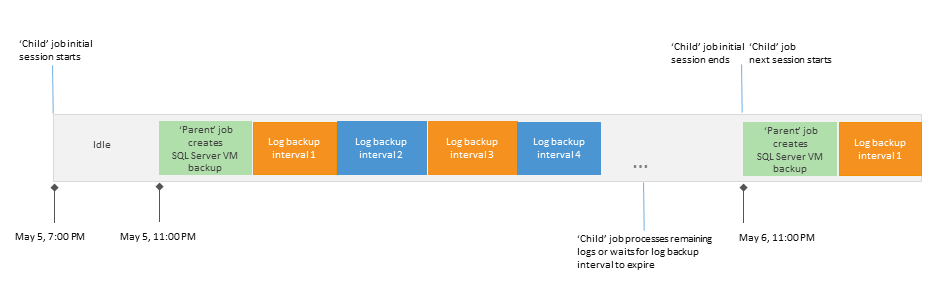
I will explain the picture with words. Suppose the parent task is set to start every day at 11 pm, starting on May 5th. Then the following sequence will take place:
Note: Since the backup logs require a backup of the corresponding database (read, server), it should be remembered that the logs for each new database will be backed up only after the backup of the server with this new database has been successfully completed.
Backup copies of transaction logs as .VLB files are saved to the repository (next to the backup of the corresponding server); By default, the path to the C: \ backup \ <SQL_server_VM_backup_job_name> folder . The metadata of the backup chain in the form of .VBM files is also put there.
By default, the .VLB file storage policy is configured to comply with the SQL server backup storage policy so that there are always logs that could be rolled onto the selected server recovery point and get the desired database state. Naturally, with the removal of the recovery point at the end of the storage period, the corresponding log backups will also be deleted.
There is one more option - to store .VLB backups for a specified number of days; it can be useful if you want to save space and plan to keep only the most recent data to restore to a recent state. However, you should make sure that the storage policies for the backup of the server and .VLB files are configured so that the server recovery point will not be deleted before the corresponding .VLB - otherwise there will be nothing to “log” the logs.
In the step of selecting objects for inclusion in the "parent" task, consider the following:
At the Guest Processing step, when setting up the processing of the guest OS, select the following options:
Here, in general, that's all. Click OK to save the settings, close the dialog, go back to the task wizard and go through it to the finish. At the same time, remember that at the Schedule step of our “parent” task, you MUST select the Run the job automatically checkbox, otherwise the “child” task will not be activated.
In the next part I will talk about how you can implement the selected recovery scenario and what points you should pay attention to when preparing and planning this process. In the meantime, you can read more:
Of course, you need to start “from the stove” - that is, from understanding how recovery options are associated with the backup settings and the virtualized SQL Server itself.
Everyone knows that Veeam creates a backup of the virtual machine at the image level - that is, in the case of SQL Server, the entire server will be backed up, including all instances and bases on them. In order for the backup to be consistent with the transaction (transactionally-consistent), when creating it, you should use image processing with regard to the operation of the application (application-aware image processing). Moreover, you can prepare a backup copy of the server to ensure that later it will restore specific databases to a state at any time or even to a selected transaction.
')
We plan resources
Here are a few factors to consider when planning a SQL Server backup for later recovery of databases:
- Infrastructure resources and backup and recovery policy requirements, namely:
- What SQL servers should be backed up?
Veeam works with Microsoft SQL Server 2005 SP4 and above; all editions are supported. For Microsoft SQL Server 2012 and above, AlwaysOn Availability Groups are supported. - What are the required RTO and RPO indicators for databases?
The frequency of backups will also depend on these values. As a rule, the more backups are made, the less time it will take to recover. - How intensively do applications access the database?
Along with the RTO indicator, this factor should be taken into account when setting up the backup window, the schedule of backup tasks and calculating the location for storing transaction log backups (if necessary, their use). - Is the backup repository sufficiently sized?
There should be enough space for backup copies of the server itself and transaction logs. It is useful to estimate how much space is approximately required for them. This can be done, for example, using a calculator, or use the VM Change Rate Estimation report from the Infrastructure Assessment Reports bundle (if you have Veeam ONE installed).
- What SQL servers should be backed up?
- Recovery model (logging and recovery model) for the required database. It determines which transaction log processing options can be used, and which recovery scenarios can be used in the future:
- If the Simple model is specified for the base, then it will be possible to restore the base only to the state it was in at the time of creating a specific restore point (backup or replica). In this scenario, SQL Server will automatically execute the trunk log.
- If the model is different ( Full or Bulk-logged ), then the automatic trunk will not occur, and you can configure the necessary log processing options.
- What tool will be used for backup and restore?
- If Veeam is used for backups of a virtual machine with SQL Server and transaction logs of the corresponding bases, then in the settings of the machine backup task, you will need to select the Process transaction logs with this job option:
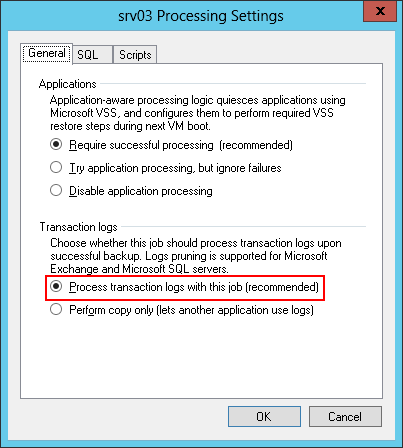
After that, the settings for processing transaction logs will be available (more on that later).
Note: If this option is selected when setting up a backup of a machine with another application (not SQL, but, say, Exchange Server), then it will turn on the automatic transaction log truncate for this application. For more information about working for Exchange, see the article on Habré . - If you plan to use Veeam only to create a backup of the entire virtual machine, and you are going to transfer transaction logs for processing, say, to a third-party application, then you need to notify Veeam Backup & Replication about it - that is, specify that the backup chain will be created by and Veeam should create its own backup with the COPY_ONLY flag (only in this case the chain will remain unchanged). This is done by selecting the option Perform copy only (lets another application use logs) :
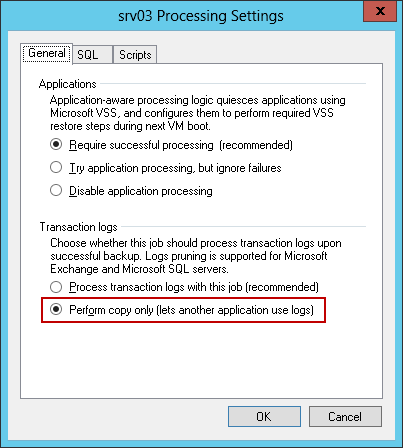
After this, the settings for processing the transaction logs will be “hidden” as unnecessary; Veeam will back up this SQL Server using the VSS_BS_COPY method to create snapshots; transaction logs will not get under way, so the database administrator will need to take care of their future.
- If Veeam is used for backups of a virtual machine with SQL Server and transaction logs of the corresponding bases, then in the settings of the machine backup task, you will need to select the Process transaction logs with this job option:
It is a little theory: we understand how processes go
In order to ensure that the database can be restored at any time or to a selected transaction, we need to create:
- Backup copy of the virtual machine, taking into account the application (that is, SQL Server)
- A backup copy of the transaction log, which will then be "rolled" on the existing backup to bring the database to the desired state
Let's see how Veeam Backup & Replication manages these tasks.
So, if we need to back up the logs (which will give us the most “targeted” recovery of the database), then the backup task of our SQL Server will, in fact, include 2 interrelated tasks:
- Backup of a virtual machine with SQL Server - it is performed at the level of the image of the machine, appears hereinafter as a “parent”, and is named after you specified it in the UI (for example, Test Job ). Created by the user in the console, run on a schedule or manually.
- Backup of transaction logs - appears here and hereinafter as “child”, bears the name of “parent” and the SQL Backup suffix (in our example we get Test Job SQL Backup ). It is created without user intervention, automatically, by the Job Manager component when both conditions are met:
- there is at least one “parent” that will run according to a schedule and create a backup, taking into account the operation of the application (in the “parent” settings, Enable application-aware image processing is selected)
- the backup logging option is enabled (also in the “parent” settings)
This "bunch" of tasks works like this:
Steps 1 and 2
According to the schedule, Job Manager, running on the Veeam backup server, launches the “parent”, which creates a backup of the virtual machine with SQL Server and puts it into the repository.
Step 3
The “child” session starts: with its beginning, Veeam Backup & Replication installs a component called Veeam Log Shipper Service inside the guest OS of our SQL server. This service will work throughout the “children's” session and be responsible for processing logs. He, in particular, collects information about which databases should be backed up during the session, and how exactly the data can be transferred to the repository (either directly or through a log shipping server - let's call it “journal proxy”). At the end of the "child" session, this component is stopped and demolished from the guest OS; with the beginning of a new session, everything repeats (installation, data collection, stop, uninstall).
A backup of the transaction log on the guest OS is created by means of the SQL Server itself; he also performs trunk logging on a guest house. The resulting copies are saved as .BAK files in a temporary folder on the guest file system (the default is % allusersprofile% \ Veeam \ Backup ).
Step 4
Every 15 minutes (default frequency) Job Manager identifies which databases are available on this SQL Server, and correlates the resulting list with data about the contents of the virtual machine backup (taken from the Veeam Backup & Replication database). Thus, it turns out for which databases there are journals that should be “taken” to the repository and put next to the corresponding SQL server backup during this 15-minute interval.
Note: If there are still copies of logs that for some reason were not “taken away” to the repository during the previous intervals, Veeam will identify them by enumerating .BAK files in the temporary folder and mark them as “to be shipped”.
Step 5
.BAK files are transferred from the guest to the repository (directly or through a "journal proxy"); The Veeam transport service on the source side before this also compresses them according to its default settings. On the repository side, the compression is performed according to the settings of the “parent” task (more details can be found here - in Russian).
After the data is “transported” to the repository, they are deleted from the temporary folder on the virtual machine. If something could not be “transported” during the allotted interval, then these files will not be deleted, and during the next 15-minute Veeam will try again.
The operations that are performed during the 15-minute interval (the so-called log backup interval) are shown in the figure:
The set of such intervals (their duration, by the way, can be changed) between two consecutive launches of the “parent” task and is a “child” session.
- The initial session starts at the moment when in the settings of the “parent” it was indicated “Activate the schedule”.
- The task "child" continues to work in the background between the launches of the "parent", performing the operations described above. With the launch of the “parent”, the current “children’s” session ends, and a new one starts right away, along with the “parent” they go through steps 1-5 (see above).
- The “child” session ends immediately before the start of the “parent”, or when the “parent” is deactivated (through the menu command or through the deactivation of the schedule).
If you draw a picture, it will look like this:
Example
I will explain the picture with words. Suppose the parent task is set to start every day at 11 pm, starting on May 5th. Then the following sequence will take place:
- The very first “children's” session starts at the moment when the automatic start schedule was activated for the “parent” (the backup of the virtual machine itself has not yet been created) - this setting was made at 7:00 pm on May 5. The task “child” is in the Idle state, waiting for the backup of the machine to be created.
- At 11 pm on May 5, the “parent” starts and creates a backup of the SQL server.
- The task “child” enters the state of Working , and the sequence of 15-minute intervals begins. If all the log backups were successfully “transferred” to the repository before the start time of the new session approaches, the “child” will go back to the Idle state and wait until the session time has expired.
- At 11 pm on May 6, the “parent” starts up again, and a new “children's” session starts.
Note: Since the backup logs require a backup of the corresponding database (read, server), it should be remembered that the logs for each new database will be backed up only after the backup of the server with this new database has been successfully completed.
What is stored in the repository?
Backup copies of transaction logs as .VLB files are saved to the repository (next to the backup of the corresponding server); By default, the path to the C: \ backup \ <SQL_server_VM_backup_job_name> folder . The metadata of the backup chain in the form of .VBM files is also put there.
By default, the .VLB file storage policy is configured to comply with the SQL server backup storage policy so that there are always logs that could be rolled onto the selected server recovery point and get the desired database state. Naturally, with the removal of the recovery point at the end of the storage period, the corresponding log backups will also be deleted.
There is one more option - to store .VLB backups for a specified number of days; it can be useful if you want to save space and plan to keep only the most recent data to restore to a recent state. However, you should make sure that the storage policies for the backup of the server and .VLB files are configured so that the server recovery point will not be deleted before the corresponding .VLB - otherwise there will be nothing to “log” the logs.
Enough theory, let's practice already! Setting up a backup task
Select objects for the job
In the step of selecting objects for inclusion in the "parent" task, consider the following:
- Databases located on the same instance will be processed sequentially.
- If you want to create transaction log backups for all databases, except for one or several specific ones, then for these exception bases you must specify the recovery model simple .
- For SQL Server 2012 and above, Veeam supports AlwaysOn Availability Groups (check that the SQL instances are on the WSFC nodes).
Setting up the processing of a virtual machine based on the running application (SQL server)
At the Guest Processing step, when setting up the processing of the guest OS, select the following options:
- Check the checkbox Enable application-aware processing so that the virtual machine processing goes according to the application's work.
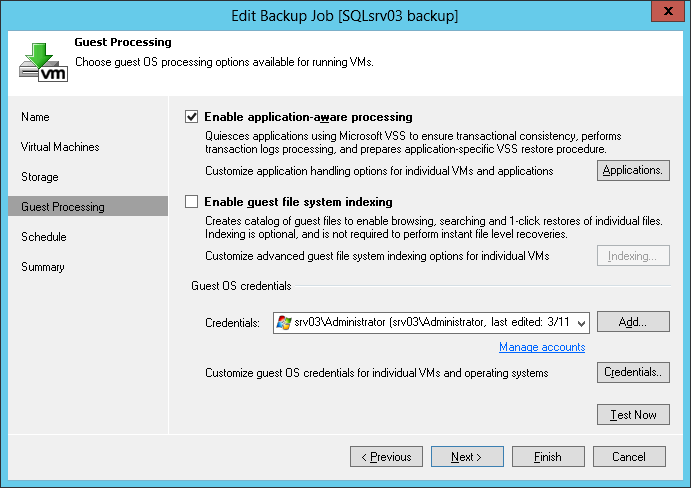
- Go to the Guest OS credentials section and specify the account under which we want to perform actions on the guest OS (including this is a backup of the logs from the guest OS to the repository and the trunk log). This account will require the following rights:
- For backup, the sysadmin fixed server role on the processed SQL Server.
- For a trunk, if you have SQL Server 2012 or SQL Server 2014, then at least the db_backupoperator role is for the required database, or again the sysadmin server role.
Important note: Beginning with Veeam Backup & Replication 8.0 Update 2 (build 8.0.0.2021), in the event of a unsuccessful trankate, another attempt will be made under the specified account under the NT AUTHORITY \ SYSTEM account.
Therefore, for SQL Server 2012 or SQL Server 2014, you should make sure that this account has sufficient rights (see http://www.veeam.com/kb1746 for more details).
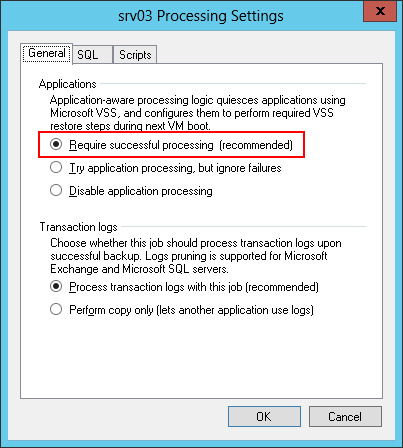
As for SQL Server 2005, 2008 and 2008 R2, the default settings for them provide the necessary rights for the local SYSTEM (however, there is always a chance that someone could change them - we recommend that you still double-check for the occasion). - Then we press the Application button, in the presented list we select the SQL Server we need and press the Edit button, after which a dialog with the settings of the guest OS processing will open.
- We go to the General tab, find the Applications section there and select the Requirementing successful processing (recommended) option — with this setting, Veeam will stop the backup process for any error received from VSS during the freezing of our application. Thus, we aim to create a backup that is consistent with respect to transactions (transactionally-consistent backup).
- Next, go to the Transaction logs section and select the Process transaction logs with this job option there - as described above, this means that both the backup of the virtual machine and the backup logs will be performed using Veeam.
- After that, the SQL tab will become available, where you need to choose what you want to do with the logs (that is, the transaction logs). Here are the options:
- Truncate logs (prevent logs from growing forever) - we want to truncate logs. Do not forget that the account that will be used to work with the guest OS must have appropriate rights. In this version, Veeam will wait for the backup of the virtual machine to finish and then give a signal to the log truncate (which will be performed using VSS). This option will allow you to restore the database only to the selected recovery point (a more “targeted” recovery will not be possible).
- Do not truncate logs (requires simple recovery model) - we want to leave the logs on the SQL server as it is, i.e. so that Veeam doesn't do anything with them (no backup, no trunk). In this version, your database administrator will have to do something with them (otherwise the logs can grow and take up a lot of space, which is why it says here - “use the simple model if you select this option”). This option will also allow you to recover only on the selected point.
- Backup logs periodically - we want to save log backups to the repository next to the SQL server backup itself. This option allows you to use any recovery script.
Choose the frequency with which we want to “transport” logs to the repository (by default, they are the same every 15 minutes); set the retention policy ( according to the corresponding image-level backup is recommended). Well, in conclusion, we specify the “journal proxy”, through which the data will “go” to the repository.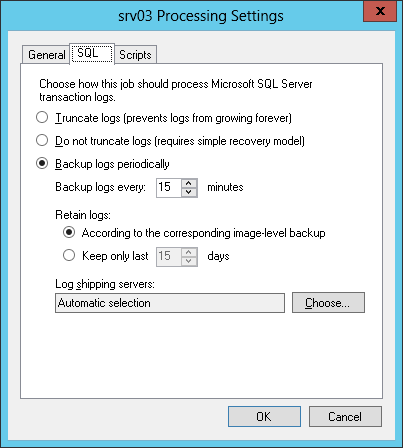
- To transfer files to the repository from the guest OS, 2 types of transport are supported:
- Directly from the guest OS to the repository is the best method, since it does not require additional resources and at the minimum loads the guest system.
- If it is impossible to establish a direct connection, then we use a log shipping server, or a “log proxy” - this can be any Windows server added to the Veeam Backup & Replication console.
You can specify that the selection of a “log proxy” should occur automatically, or select the appropriate servers from the list. Veeam will automatically assign one of the servers to the proxy role, focusing on 2 criteria - possible data transfer methods and network accessibility. It is also reasonable to have more than one proxy for this purpose (in case of failure). Read more about “journal proxies” here . - As for the schedule, it is recommended to start the “parent” task in the hours of minimum load of production. The task “child” (ie backup of logs) will by default try to “transport” logs to the repository every 15 minutes - this interval can be changed. Of course, in this case it is necessary to take into account the real time for which files are transferred to the repository (i.e. it is not necessary to set an interval of 5 minutes, if in fact the process takes all 15).
Here, in general, that's all. Click OK to save the settings, close the dialog, go back to the task wizard and go through it to the finish. At the same time, remember that at the Schedule step of our “parent” task, you MUST select the Run the job automatically checkbox, otherwise the “child” task will not be activated.
What's next?
In the next part I will talk about how you can implement the selected recovery scenario and what points you should pay attention to when preparing and planning this process. In the meantime, you can read more:
Source: https://habr.com/ru/post/257255/
All Articles