Chatbot on neural networks
Recently came across such an article . As it turned out, a certain company with the speaker’s name “nanosemantics” announced a Russian chatbot contest, pompously calling it “Turing Test”. ” Personally, I take a negative attitude to such undertakings — chatbot is a program to imitate a conversation — the creation is usually not clever, based on pre-made templates, and the competition does not move their science, but the show and the attention of the public is assured. Creates the ground for various speculations about intelligent computers and great breakthroughs in artificial intelligence, which is very far from the truth. Especially in this case, when only bots written on the template matching engine are accepted, moreover, Nanosemantics itself.
However, it is always easy to scold others, but it is not so easy to do something working. I was curious whether it was possible to make a chatbot not by manually filling out response templates, but by learning the neural network on sample dialogs. A quick search on the Internet did not provide useful information, so I decided to quickly do a couple of experiments and see what happens.
Normal chatbot is limited to superficial responses that are defined by predefined patterns. A trained chatbot (there are such) searches for answers to similar questions in its database of dialogs, and sometimes even creates new templates. But still, his “mind” is usually strictly limited from above by a given algorithm. But a bot with a neural network operating on the principle of a question at the entrance — the answer at the exit — is theoretically unlimited. There are works in which it is shown that neural networks can learn the rules of logical inference by getting input into sentences in natural language, as well as answer questions relating to various texts. But we will not be so ambitious in the ways and we will just try to get something resembling the answers of a typical chatbot.
As a source of data, only a dialogue transcript in English (consisting of 3,860 replicas) was quickly found. Well, it will come down to experience, since with our approach the language has no fundamental difference. To begin with, to compare with something, I quickly collected a simple chatbot that selects ready-made answers from the transcript, based on the word matches in the interlocutor's phrases (cosine of the angle between the question and answer vectors, which are "bags of words"). The whole program fit lines on 30:
')
Here's what happened:
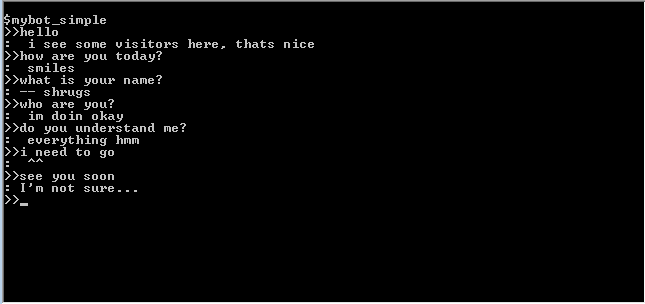
Translation (approximate) (W: - person, W: - program):
H: hello
P : I see visitors here, that's good.
D: How are you ?
P: smiles
Q: what is your name?
P: shrugs
W: Who are you?
P: I'm fine
W: do you understand me?
P: Absolutely everything, hmm ...
D: I have to go
N: ^^
H: see you later
P: I'm not sure
With a shallow survey, it answers quite well for such a simple program, it doesn’t know what its name is or who it is ... but nevertheless, a certain sense of presence is taking shape - a good illustration of the fact that we tend to over-animate really simple algorithms (or maybe just 90% of all communication - superficial?).
We now turn to more complex algorithms. I’ll say right away that it’s harder to do it right away, because template chatbots are created to “deceive” the user, and use different tricks to create the illusion of communication, and our task is to do without deception.
How to generate text using a neural network? Now the classic way to do this is the neural language model. The bottom line is that the neural network is given the task to predict the next word based on n-previous ones. The words at the output are encoded on the principle of one output neuron - one word (see figure). Input words can be encoded in the same way, or use a distributed representation of words in a vector space, where words of similar meaning are at a smaller distance than words with different meanings.
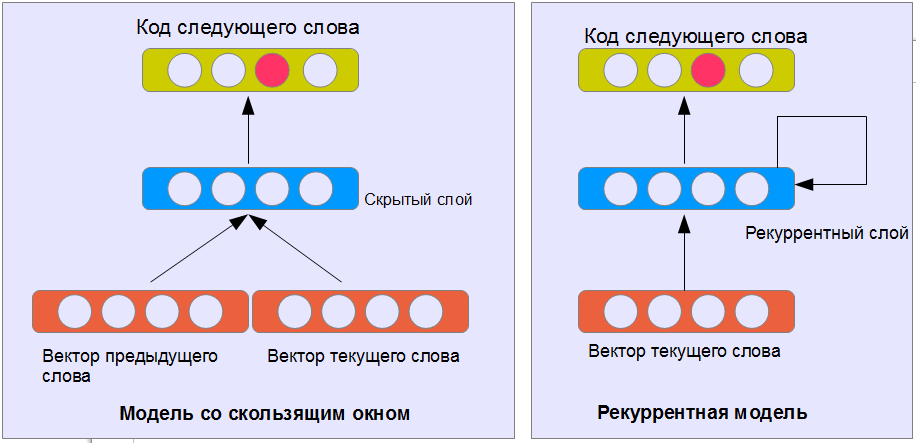
A trained neural network can give rise to a text and obtain a prediction of its ending (by adding the last predicted word to the end and applying the neural network to a new, elongated text). Thus, it is possible to create a model of answers. One problem - the answers have nothing to do with the phrases of the interlocutor.
The obvious solution to the problem is to input the presentation of the previous phrase of the dialogue. How to do it? Two of the many possible ways we discussed in the previous article about the classification of proposals. The simplest version of NBoW is to use the sum of all the word vectors of the previous phrase.
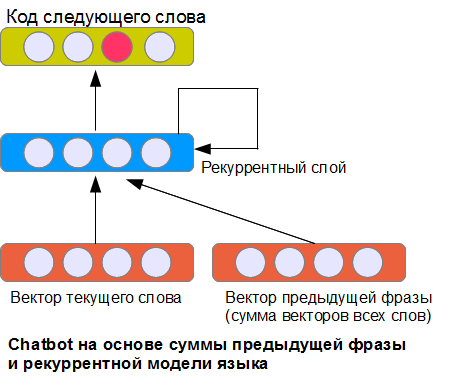
The architecture shown in the picture is far from the only one possible, but perhaps one of the simplest. The recurrent layer receives as input the data relative to the current word, the vector representing the previous phrase, and also its own states at the previous step (therefore, it is called recurrent). Due to this, a neural network (theoretically) can remember information about previous words for an unlimited phrase length (as opposed to an implementation where only words from a fixed-size window are counted). In practice, of course, such a layer presents certain difficulties in learning.
After learning the network got the following:
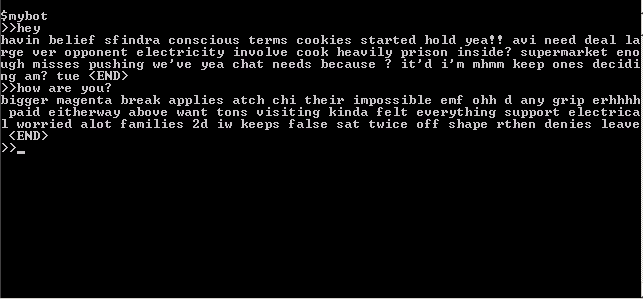
Mda ... more or less meaningless set of words. There are no connections between words and there is a logic in the construction of sentences, but there is no general sense, and there is no connection with questions either (at least I don’t see). In addition, the bot is overly talkative - words are formed into large long chains. There are many reasons for this - this is a small (about 15,000 words) training sample size, and difficulties in training a recurrent network, which actually sees the context in two or three words, and therefore easily loses the thread of the narration, and the lack of expressiveness of the previous phrase. Actually, this was expected, and I brought this option to show that the problem is not solved in the forehead. Although, in fact, correct selection of the training algorithm and network parameters can achieve more interesting options, but they will suffer such problems as repeated repetition of phrases, difficulties with choosing the end of a sentence, copying long fragments from the original training set, etc. In addition, such a network is difficult to analyze - it is unclear what exactly is learned and how it works. Therefore, we will not waste time analyzing the capabilities of this architecture and try a more interesting option.
In the second variant, I connected the convolution network described in the previous article with the recurrent language model:
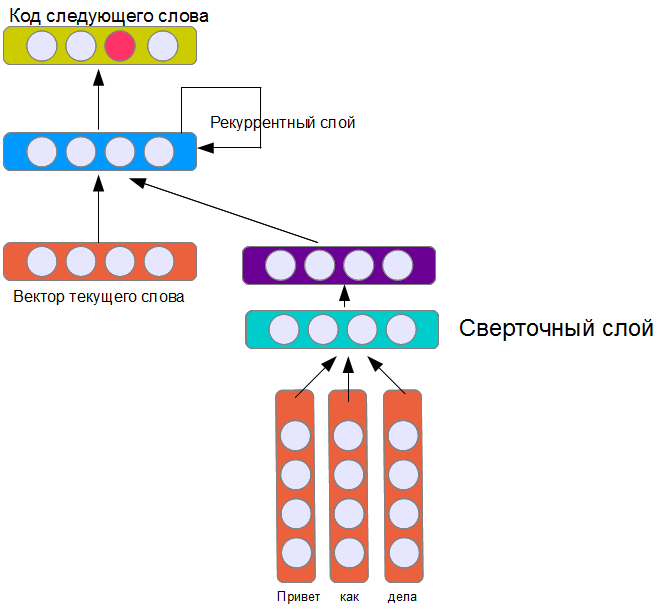
Like the network from the previous article, the convolutional layer contains 16 filters. From general considerations, it can be expected that this four-layer model will be harder and the result will be worse. In addition, 16 filters seem to be insufficient to create a model of the replica of the interlocutor. Indeed, her training takes much longer, but the result ... well, judge for yourself:
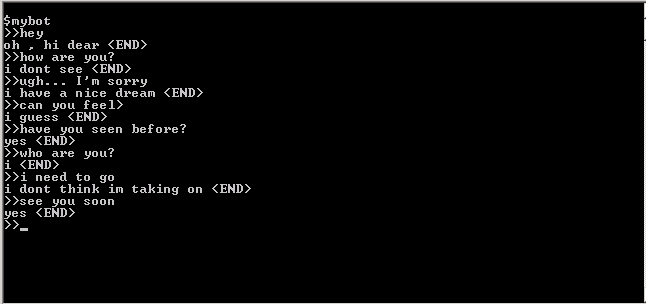
Translation (approximate) of the dialogue (R: - person, P: - program)
H: hello
P: oh, hello
H: how are you?
P: I can't see
H: oops ... well, sorry
P: it seems to me a good dream.
W: can you feel?
P: I suppose
Q: Could you see before?
P: Yes
W: Who are you?
P: I
D: I have to go
P: I'm not sure I can accept it.
H: see you later
P: Yes
In my opinion quite effectively. It resembles fragments from science fiction novels, where artificial intelligence comes to life in a computer, especially the statements of the program that it cannot see, but could see before. It is time to declare the creation of AI and the great achievement ...
In fact, of course, this neural network does not have any intelligence, which does not make it, though less interesting. The fact is that we can analyze what has actually been learned by tracing the dependence of activation of the convolutional neurons on the input phrases. Through such an analysis, a neuron that responds to the words of greeting (“hello”, “hi”, “he” y, etc.), as well as a neuron that recognizes question phrases like “have you ...?”, Was found. the question is not obligatory (they usually learn to answer “yes” to the neural network), besides, if the word “you” appears in the question, the likelihood that the answer will begin with the word “I” (“me” ).
Thus, the neural network has learned some typical conversation patterns and language tricks, which are often used when programming chatbots "manually", having well disposed of the 16 available filters. It is possible that replacing a simple convolutional network with a multilayer one, adding filters and increasing the size of the training sample, you can get chatbots, which will seem more “smart” than their counterparts, based on manual selection of patterns. But this question is already outside of our article.
However, it is always easy to scold others, but it is not so easy to do something working. I was curious whether it was possible to make a chatbot not by manually filling out response templates, but by learning the neural network on sample dialogs. A quick search on the Internet did not provide useful information, so I decided to quickly do a couple of experiments and see what happens.
Normal chatbot is limited to superficial responses that are defined by predefined patterns. A trained chatbot (there are such) searches for answers to similar questions in its database of dialogs, and sometimes even creates new templates. But still, his “mind” is usually strictly limited from above by a given algorithm. But a bot with a neural network operating on the principle of a question at the entrance — the answer at the exit — is theoretically unlimited. There are works in which it is shown that neural networks can learn the rules of logical inference by getting input into sentences in natural language, as well as answer questions relating to various texts. But we will not be so ambitious in the ways and we will just try to get something resembling the answers of a typical chatbot.
As a source of data, only a dialogue transcript in English (consisting of 3,860 replicas) was quickly found. Well, it will come down to experience, since with our approach the language has no fundamental difference. To begin with, to compare with something, I quickly collected a simple chatbot that selects ready-made answers from the transcript, based on the word matches in the interlocutor's phrases (cosine of the angle between the question and answer vectors, which are "bags of words"). The whole program fit lines on 30:
')
Here's what happened:
Translation (approximate) (W: - person, W: - program):
H: hello
P : I see visitors here, that's good.
D: How are you ?
P: smiles
Q: what is your name?
P: shrugs
W: Who are you?
P: I'm fine
W: do you understand me?
P: Absolutely everything, hmm ...
D: I have to go
N: ^^
H: see you later
P: I'm not sure
With a shallow survey, it answers quite well for such a simple program, it doesn’t know what its name is or who it is ... but nevertheless, a certain sense of presence is taking shape - a good illustration of the fact that we tend to over-animate really simple algorithms (or maybe just 90% of all communication - superficial?).
We now turn to more complex algorithms. I’ll say right away that it’s harder to do it right away, because template chatbots are created to “deceive” the user, and use different tricks to create the illusion of communication, and our task is to do without deception.
How to generate text using a neural network? Now the classic way to do this is the neural language model. The bottom line is that the neural network is given the task to predict the next word based on n-previous ones. The words at the output are encoded on the principle of one output neuron - one word (see figure). Input words can be encoded in the same way, or use a distributed representation of words in a vector space, where words of similar meaning are at a smaller distance than words with different meanings.
A trained neural network can give rise to a text and obtain a prediction of its ending (by adding the last predicted word to the end and applying the neural network to a new, elongated text). Thus, it is possible to create a model of answers. One problem - the answers have nothing to do with the phrases of the interlocutor.
The obvious solution to the problem is to input the presentation of the previous phrase of the dialogue. How to do it? Two of the many possible ways we discussed in the previous article about the classification of proposals. The simplest version of NBoW is to use the sum of all the word vectors of the previous phrase.
The architecture shown in the picture is far from the only one possible, but perhaps one of the simplest. The recurrent layer receives as input the data relative to the current word, the vector representing the previous phrase, and also its own states at the previous step (therefore, it is called recurrent). Due to this, a neural network (theoretically) can remember information about previous words for an unlimited phrase length (as opposed to an implementation where only words from a fixed-size window are counted). In practice, of course, such a layer presents certain difficulties in learning.
After learning the network got the following:
Mda ... more or less meaningless set of words. There are no connections between words and there is a logic in the construction of sentences, but there is no general sense, and there is no connection with questions either (at least I don’t see). In addition, the bot is overly talkative - words are formed into large long chains. There are many reasons for this - this is a small (about 15,000 words) training sample size, and difficulties in training a recurrent network, which actually sees the context in two or three words, and therefore easily loses the thread of the narration, and the lack of expressiveness of the previous phrase. Actually, this was expected, and I brought this option to show that the problem is not solved in the forehead. Although, in fact, correct selection of the training algorithm and network parameters can achieve more interesting options, but they will suffer such problems as repeated repetition of phrases, difficulties with choosing the end of a sentence, copying long fragments from the original training set, etc. In addition, such a network is difficult to analyze - it is unclear what exactly is learned and how it works. Therefore, we will not waste time analyzing the capabilities of this architecture and try a more interesting option.
In the second variant, I connected the convolution network described in the previous article with the recurrent language model:
Like the network from the previous article, the convolutional layer contains 16 filters. From general considerations, it can be expected that this four-layer model will be harder and the result will be worse. In addition, 16 filters seem to be insufficient to create a model of the replica of the interlocutor. Indeed, her training takes much longer, but the result ... well, judge for yourself:
Translation (approximate) of the dialogue (R: - person, P: - program)
H: hello
P: oh, hello
H: how are you?
P: I can't see
H: oops ... well, sorry
P: it seems to me a good dream.
W: can you feel?
P: I suppose
Q: Could you see before?
P: Yes
W: Who are you?
P: I
D: I have to go
P: I'm not sure I can accept it.
H: see you later
P: Yes
In my opinion quite effectively. It resembles fragments from science fiction novels, where artificial intelligence comes to life in a computer, especially the statements of the program that it cannot see, but could see before. It is time to declare the creation of AI and the great achievement ...
In fact, of course, this neural network does not have any intelligence, which does not make it, though less interesting. The fact is that we can analyze what has actually been learned by tracing the dependence of activation of the convolutional neurons on the input phrases. Through such an analysis, a neuron that responds to the words of greeting (“hello”, “hi”, “he” y, etc.), as well as a neuron that recognizes question phrases like “have you ...?”, Was found. the question is not obligatory (they usually learn to answer “yes” to the neural network), besides, if the word “you” appears in the question, the likelihood that the answer will begin with the word “I” (“me” ).
Thus, the neural network has learned some typical conversation patterns and language tricks, which are often used when programming chatbots "manually", having well disposed of the 16 available filters. It is possible that replacing a simple convolutional network with a multilayer one, adding filters and increasing the size of the training sample, you can get chatbots, which will seem more “smart” than their counterparts, based on manual selection of patterns. But this question is already outside of our article.
Source: https://habr.com/ru/post/256987/
All Articles