Testing math algorithms
This article is written for people directly or indirectly related to the industrial development of mathematical algorithms for business, as well as for professional testers from whom we want to hear criticism.
We work in a Russian company that has been developing unique software solutions in the field of data analysis, forecasting, classification and other datamining for more than 10 years. All solutions are not abstract tools, but integrated systems for solving specific problems of customers. Our key feature is our own design algorithms, sharpened by the high quality of the result.
')
Our company has a clear division of responsibilities between mathematicians and programmers. For visual arrangement of accents, I will add that the team of mathematicians is almost as good as the team of programmers.
Simply, the process of creating a new solution is as follows:
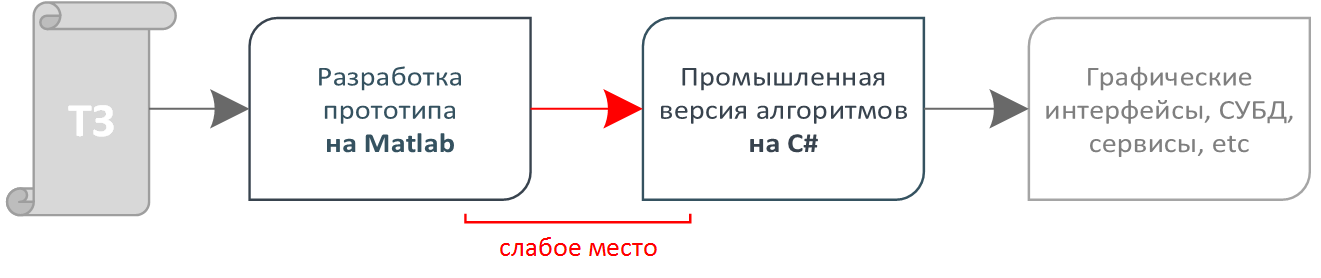
After checking the ideas, our mathematicians develop a complete analytical system and implement all the processes of the customer in it. On this system, as a rule, there is a demonstration of the work of our algorithms in conditions close to combat ones. Our mathematicians prefer to work on Matlab, so their system is very convenient for quick testing of hypotheses, but for many reasons it cannot be used for industrial purposes. It is necessary to re-implement the same thing in a suitable development environment, for example, .NET (in our case). This moment is a weak link in the process.
The developer of industrial software has before itself the documentation and source codes on Matlab, but does not have the education and experience of mathematics. However, from his pen should come out exactly the same algorithm. Here the problem arises: how to properly test the industrial version of the algorithm for compliance with the prototype math?
It should be noted that to catch an error in a mathematical algorithm and, for example, in the process of synchronizing two DBMS - two fundamentally different tasks. It is more and more clear with databases: the number of records after synchronization is the same, the checksums are the same, so the test is passed. Easy to understand and relatively easy to automate.
The prediction algorithm accepts input and outputs tens or hundreds of values — floating point numbers. One algorithm displays these numbers on the screen in Matlab, the other, industrial, writes to a variable in the C # code. How to compare them? Due to the limited accuracy of floating-point calculations, they will not coincide until the last character. How to limit the accuracy of the comparison? In our conditions, a 2-3% decline in the quality of forecasting can be significant, since sometimes it is comparable to the effect that we give to business.
The testing procedure we came to looks like this:
Taking into account the need to develop a C # -Matlab interface, a comparison function, and debugging of two systems, it takes 5-10 days to reduce the average algorithm, which is comparable in labor to the time spent on development. This time reflects the difference between an algorithm that “ in principle works and produces something normal ” and an algorithm that completely repeats what was intended by a mathematician.
Once again, the list, the difficulties that we face:
In developing the industrial code in C #, we immediately think that it will have to be “mixed” with Matlab. To make life easier, we use a number of simple techniques.
It is important to pay attention to comparison operations. It is impossible to compare for equality of a floating-point number (the resharper will tell you about this). Instead
It is less obvious, but clearly manifested in mathematical algorithms, that comparisons
It is also important to go into the details of processing with pseudo-magnitudes, such as NaN (not a number) and Infinity. For example, in Matlab:
Possible ways to make life easier with which we did not go or go, but the path has not yet been covered:
Entering this path, we did not expect that the verification of our algorithms would result in a nontrivial multi-path process. In general, we are satisfied with the quality and repeatability of the result, and we are interested to hear the opinion of people who are confronted with similar tasks.
Who are we
We work in a Russian company that has been developing unique software solutions in the field of data analysis, forecasting, classification and other datamining for more than 10 years. All solutions are not abstract tools, but integrated systems for solving specific problems of customers. Our key feature is our own design algorithms, sharpened by the high quality of the result.
')
Our company has a clear division of responsibilities between mathematicians and programmers. For visual arrangement of accents, I will add that the team of mathematicians is almost as good as the team of programmers.
What kind of problem will be discussed
Simply, the process of creating a new solution is as follows:
After checking the ideas, our mathematicians develop a complete analytical system and implement all the processes of the customer in it. On this system, as a rule, there is a demonstration of the work of our algorithms in conditions close to combat ones. Our mathematicians prefer to work on Matlab, so their system is very convenient for quick testing of hypotheses, but for many reasons it cannot be used for industrial purposes. It is necessary to re-implement the same thing in a suitable development environment, for example, .NET (in our case). This moment is a weak link in the process.
The developer of industrial software has before itself the documentation and source codes on Matlab, but does not have the education and experience of mathematics. However, from his pen should come out exactly the same algorithm. Here the problem arises: how to properly test the industrial version of the algorithm for compliance with the prototype math?
What is the difficulty of this task?
It should be noted that to catch an error in a mathematical algorithm and, for example, in the process of synchronizing two DBMS - two fundamentally different tasks. It is more and more clear with databases: the number of records after synchronization is the same, the checksums are the same, so the test is passed. Easy to understand and relatively easy to automate.
The prediction algorithm accepts input and outputs tens or hundreds of values — floating point numbers. One algorithm displays these numbers on the screen in Matlab, the other, industrial, writes to a variable in the C # code. How to compare them? Due to the limited accuracy of floating-point calculations, they will not coincide until the last character. How to limit the accuracy of the comparison? In our conditions, a 2-3% decline in the quality of forecasting can be significant, since sometimes it is comparable to the effect that we give to business.
How we solve the problem
The testing procedure we came to looks like this:
- The generation of input data sets - the so-called standards. This work is done in advance by a mathematician in a familiar environment - Matlab.
- Run a testing system that absorbs the standards and turns them into tests. This system is developed by us on Matlab, according to the standard, it understands which algorithm to run, in what order to transfer data to it and what to expect to exit.
- Run a prototype on Matlab with references as input. This procedure is easy because both the standards and the prototype are created within the same system - Matlab.
- Run the industrial .NET version, converting input and output data from Matlab to C # and back. Having tried several approaches to build such a bridge, we stopped at the C # interface implemented out of the box in the latest versions of Matlab. It allows you to instantiate virtually any type of C # data from Matlab, load assemblies, and run functions.
- The system receives the results of the work of both algorithms and starts the comparison procedure.
- The comparison procedure gives the verdict: 0 (does not match) or 1 (matches). The comparison procedure is required to be developed manually for each algorithm, since features of rounding specific values give different tolerances on the values. In addition, some algorithms include the generation of random variables.
- Steps 2-7 are automated by means of a Matlab console launch and are scheduled to run.
Taking into account the need to develop a C # -Matlab interface, a comparison function, and debugging of two systems, it takes 5-10 days to reduce the average algorithm, which is comparable in labor to the time spent on development. This time reflects the difference between an algorithm that “ in principle works and produces something normal ” and an algorithm that completely repeats what was intended by a mathematician.
Once again, the list, the difficulties that we face:
- Input data needs to be submitted to Matlab and in C # => it is necessary to develop conversions there and back.
- Comparison and the related problems of rounding and other features make it difficult to write code and mislead when debugging.
- Synchronous debugging: to understand what is wrong, you often need to simultaneously run two debuggers under two systems, it works, but it requires a certain shamanism.
- Generation of an exhaustive set of standards (math problem). There is no way to sort through the various inputs, and there may be too many branches in the algorithm to check them together in all combinations.
- Each algorithm requires its own manually developed function of comparison of results.
Coding features
In developing the industrial code in C #, we immediately think that it will have to be “mixed” with Matlab. To make life easier, we use a number of simple techniques.
It is important to pay attention to comparison operations. It is impossible to compare for equality of a floating-point number (the resharper will tell you about this). Instead
a == b Math.Abs(a – b) < eps It is less obvious, but clearly manifested in mathematical algorithms, that comparisons
<= >= < > illegal for the same reason: if(a <= b) => if(a < b + eps) if(a < b) => if(a < b - eps) It is also important to go into the details of processing with pseudo-magnitudes, such as NaN (not a number) and Infinity. For example, in Matlab:
max(0, NaN) = 0 and in C # Math.Max(0, double.NaN) = NaN Other ways
Possible ways to make life easier with which we did not go or go, but the path has not yet been covered:
- Development and prototype and production version of one person. This combination greatly simplifies life, because removes the task of understanding these people each other. In cases where the result is needed immediately, there is no other way. But people who are capable of such a diverse work, almost never occurs. Even fewer people who want to do it.
Normal mathematics turns back on the limitations and principles of industrial development, and an ordinary programmer is an engineer, by no means a mathematician (yes, we are not Yandex). - Unit testing production version (mathematician or industrial developer). Instead of the costly co-testing procedure of Matlab and C #, test only C # on the numbers that are downloaded from Matlab. In this case, all testing can be done with the help of convenient frameworks completely in C #.
It seems that this should save a lot of power, but we are losing the main thing: simultaneous comparison of two algorithms. If changes are made to the version on Matlab, we may not know about it in a timely manner or not realize how important these changes are (how many tests they ruined). - Build .NET builds right from Matlab. Unfortunately, there are no normal (for performance and reliability) frameworks for this, and most likely there will never be. Matlab is a powerful tool, but it was created for other purposes.
- Develop a C # framework that will allow you to write code in a matlab-style, with the usual processing of matrices, indexes, conditions, etc. Such developments exist: numerics.mathdotnet.com , ilnumerics.net , but are imperfect, and we gradually make our own.
Eventually
Entering this path, we did not expect that the verification of our algorithms would result in a nontrivial multi-path process. In general, we are satisfied with the quality and repeatability of the result, and we are interested to hear the opinion of people who are confronted with similar tasks.
Source: https://habr.com/ru/post/256713/
All Articles